Elasticsearch提供了一个非常全面和强大的REST API,可以使用它与集群进行交互。咱们来玩一下。
环境搭建

搭建好es和kinaba,可以访问通过ip:9200查看es的信息,ip:5601打开kinaba。
集群相关
健康检查
curl localhost:9200/_cat/health?v

集群的健康状态有绿色(green)、黄色(yellow),红色(red)三种:
- 绿色:一切正常(集群功能全部可用)。
- 黄色:所有数据都可用,但某些副本尚未分配(集群完全正常工作)。
- 红色:由于某些原因,某些数据不可用(集群只有部分功能正常工作)。
节点列表
curl localhost:9200/_cat/nodes?v

可以看到一个名为442a880a3b43的节点,它是当前集群中唯一的节点。
集群的索引列表

- health:索引的状态;
- index:索引名;
- docs.count:文档的个数;
ES数据操作
ES是面向文档的,这意味着它可以存储整个对象或文档。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在ES中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。ES使用JSON作为文档序列化格式。
以kinaba的为例,索引的CURD
索引
- 创建索引
- 格式: PUT /索引名称
- 举例: PUT /es_db
- 查询索引所有文档
- 格式: GET /索引名称
- 举例: GET /es_db
- 删除索引
- 格式: DELETE /索引名称
- 举例: DELETE /es_db
添加文档
- 格式: PUT /索引名称/类型/id

修改文档
- 格式: PUT /索引名称/类型/id

可以看到添加和修改的指令是一样,添加一个存在的id文档,则是修改。
删除文档
- 格式: DELETE /索引名称/类型/id
- 举例: DELETE /es_db/_doc/1
查询某条文档
- 格式: GET /索引名称/类型/id
- 举例: GET /es_db/_doc/2
查询某条文档
- 格式: GET /索引名称/类型/id
- 举例: GET /es_db/_doc/2
query string seach
- 查询当前类型中的所有文档
_search, 类型可以写可不写。- 格式: GET /索引名称/[/类型]/_search
- 举例: GET /es_db/_doc/_search 相当于
sql:SQL: select * from _doc
- 条件查询, 如要查询等于22岁的
_search?q=age:22- 格式: GET /索引名称/[/类型]/_search?q=条件属性:值
- GET es_db/_doc/_search?q=age:22
- 范围查询 :如要查询age在25至26岁之间的
- 格式: GET /索引名称[/类型]/_search?q=条件属性[值1 TO 值2] 注意: TO 必须为大写
- 举例: GET /es_db/_doc/_search?q=age[22 TO 26]
- 分页查询
from=*&size=*- 格式: GET /索引名称[/类型]/_search?q=条件属性[值1 TO 值2]&from=0&size=1
- 举例: GET /es_db/_doc/_search?q=age[25 TO 26]&from=0&size=1相当于
select * from _doc where age between 22 and 26 limit 0, 1
- 对查询结果排序
sort=字段:desc/asc- 格式: GET /索引名称[/类型]/_search?sort=条件属性:desc/asc
- GET /es_db/_search?sort=age:desc
- 对查询结果只输出某些字段
_source=字段,字段- 格式: GET /索引名称[/类型]/_search?_source=属性
- GET /es_db/_search?_source=name&sort=age:desc
注意:查询的时候带上类型会出现Deprecation: [types removal] Specifying types in search requests is deprecated.,es7版本将type弃用导致的。
query DSL
DSL由叶子查询子句和复合查询子句两种子句组成。
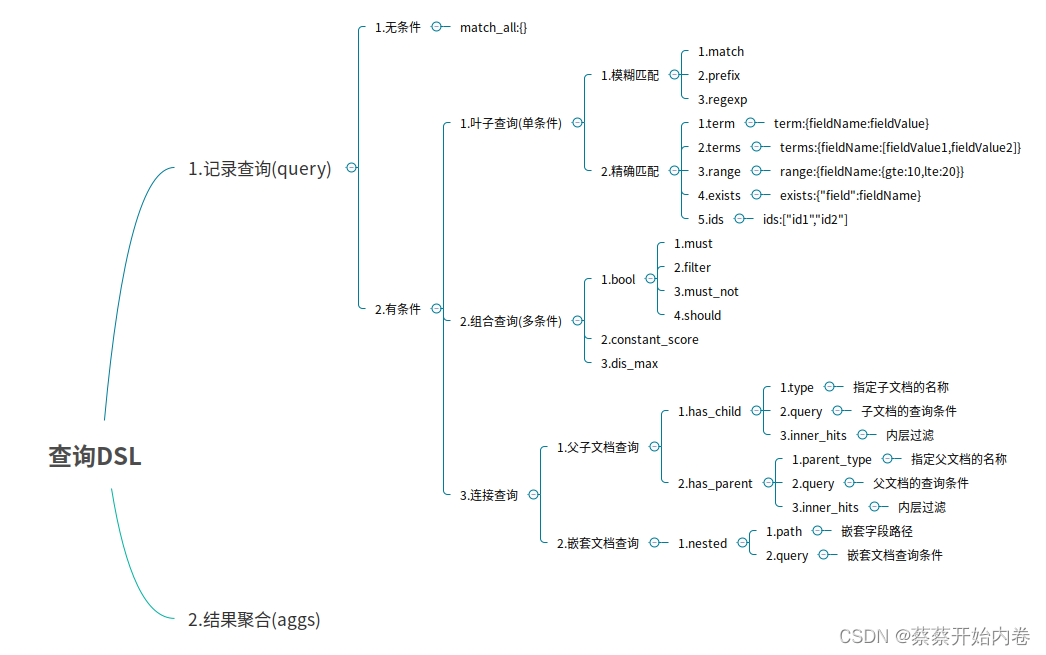
无查询条件:无查询条件是查询所有,默认是查询所有的,或者使用match_all表示所有。
GET /es_db/_search
{
"query": {
"match_all": {}
}
}
模糊查询
主要是针对文本类型的字段,文本类型的字段会对内容进行分词,对查询时,也会对搜索条件进行分词,然后通过倒排索引查找到匹配的数据。
match: 通过match关键词模糊匹配条件内容prefix: 前缀匹配regexp: 通过正则表达式来匹配数据
#模糊查询 单字段
GET /es_db/_search
{
"query": {
"match": {
"address": "中国"
}
},
"from":0,
"size": 1,
"_source":["name","age","sex"]
}
#查询address和name中包含caicai 多字段
GET /es_db/_search
{
"query":{
"multi_match":{
"query":"caicai",
"fields":["address","name"]
}
}
}
# 前缀类型
GET /es_db/_search
{
"query": {
"prefix": {
"name": {
"value": "a"
}
}
}
}
# match_phrase 完全匹配
GET /es_db/_search
{
"query":{
"match_phrase":{
"address":"中国人"
}
}
}
精确匹配
term: 单个条件相等terms: 单个字段属于某个值数组内的值range: 字段属于某个范围内的值exists: 某个字段的值是否存在ids: 通过ID批量查询
match和term的区别
match:模糊匹配,需要指定字段名,但是输入会进行分词,比如"hello world"会进行拆分为hello和world,然后匹配,如果字段中包含hello或者world,或者都包含的结果都会被查询出来,也就是说match是一个部分匹配的模糊查询。查询条件相对来说比较宽松。term: 这种查询和match在有些时候是等价的,比如我们查询单个的词hello,那么会和match查询结果一样,但是如果查询"hello world",结果就相差很大,因为这个输入不会进行分词,就是说查询的时候,是查询字段分词结果中是否有"hello world"的字样,而不是查询字段中包含"hello world"的字样。当保存
数据"hello world"时,elasticsearch会对字段内容进行分词,"hello world"会被分成hello和world,不存在"hello world",因此这里的查询结果会为空。这也是term查询和match的区别。
## 根据sex精准匹配
GET /es_db/_search
{
"query": {
"term": {
"sex": {
"value": "0"
}
}
}
}
# 年龄10-25之间
GET /es_db/_search
{
"query": {
"range": {
"age": {
"gte": 10,
"lte": 25
}
}
}
}
# 年龄name叫caicai或者admin的人
GET /es_db/_search
{
"query": {
"terms": {
"name": [
"caicai",
"admin"
]
}
}
}
组合条件查询
组合条件查询是将叶子条件查询语句进行组合而形成的一个完整的查询条件。
- bool : 各条件之间有and,or或not的关系。
must: 各个条件都必须满足,即各条件是and的关系。
should: 各个条件有一个满足即可,即各条件是or的关系。must_not: 不满足所有条件,即各条件是not的。
关系filter: 不计算相关度评分,它不计算_score。即相关度评分,效率更高。
constant_score : 不计算相关度评分
must/filter/shoud/must_not等的子条件是通过term/terms/range/ids/exists/match等叶子条件为参数的。
# 查询地址包含中国,而且年龄在10-25之间的人
GET /es_db/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "中国"
}
},
{
"range": {
"age": {
"gte": 10,
"lte": 25
}
}
}
]
}
}
}
#查询address有中国的
GET /es_db/_search
{
"query":{
"match":{
"address":"中"
}
}
}
##高亮
GET /es_db/_search
{
"query":{
"bool":{
"filter":{
"match":{
"address":"中"
}
}
}
},
"highlight": {
"fields": {"address": {}}
}
}
查询DSL(query DSL)和过滤DSL(filter DSL)
- query DSL:在查询上下文中,查询会回答这个问题——“这个文档匹不匹配这个查询,它的相关度高么?”如何验证匹配很好理解,如何计算相关度呢?
ES中索引的数据都会存储一个_score分值,分值越高就代表越匹配。另外关于某个搜索的分值计算还是很复杂的,因此也需要一定的时间。 - filter DSL:在过滤器上下文中,查询会回答这个问题——“这个文档匹不匹配?”答案很简单,是或者不是。它不会去计算任何分值,也不会关心返回的排序问题,因此效率会高一点。过滤上下文 是在使用
filter参数时候的执行环境,比如在bool查询中使用must_not或者filter另外,经常使用过滤器,ES会自动的缓存过滤器的内容,这对于查询来说,会提高很多性能。
es搜索相关参数
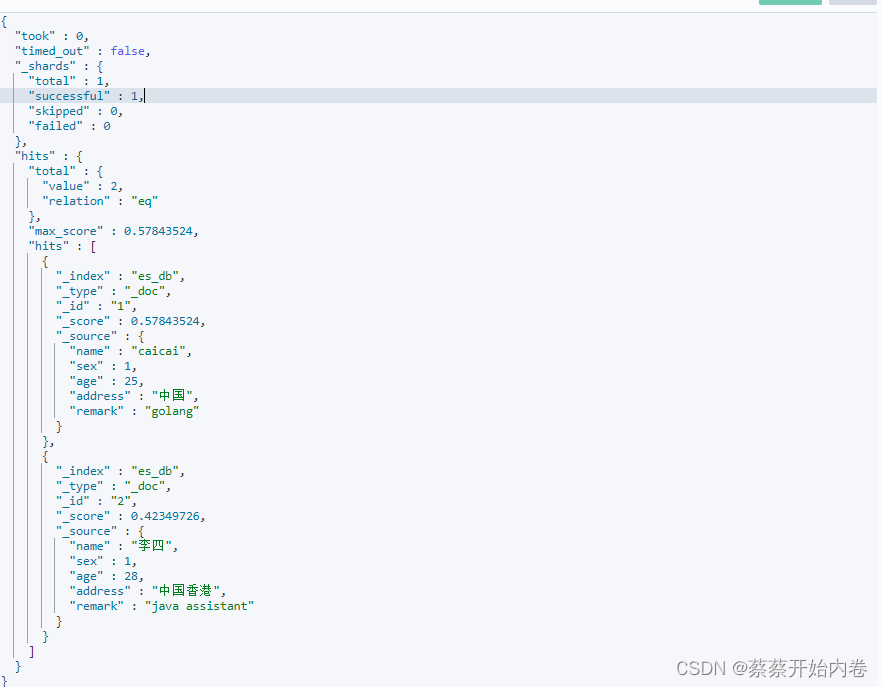
took:耗费的时间,单位毫秒。- ·time_out·:是否超时。
_shards:几个分片。hit.total:查询结果的数量。hit.max_score:匹配的分数。hit.hits:具体结果
最后
实操笔记
#创建索引
PUT /es_db
# 删除索引
DELETE /es_db
# 查询索引
GET /es_db
PUT /es_db/_doc/1
{
"name":"张三",
"sex":1,
"age":25,
"address":"中国",
"remark":"java developer"
}
# 修改id为1的数据
PUT /es_db/_doc/1
{
"name":"caicai",
"sex":1,
"age":25,
"address":"中国",
"remark":"golang"
}
# 删除文档
DELETE /es_db/_doc/1
PUT /es_db/_doc/2
{
"name":"李四",
"sex":1,
"age":28,
"address":"中国香港",
"remark":"java assistant"
}
PUT /es_db/_doc/3
{
"name":"rod",
"sex":0,
"age":26,
"address":"北京",
"remark":"php developer"
}
PUT /es_db/5
{
"name":"admin",
"sex":0,
"age":22,
"address":"长沙",
"remark":"pythonassistant"
}
# 查询文档
GET /es_db/_doc/2
GET es_db/_doc/_search?q=age:22
# 同上 GET es_db/_search?q=age:22
GET /es_db/_doc/_search?q=age[22 TO 26]
# 同上 GET /es_db/_search?q=age[22 TO 26]
GET /es_db/_doc/_search?q=age[22 TO 26]&from=0&size=1
# 同上 GET /es_db/_search?q=age[22 TO 26]&from=0&size=1
GET /es_db/_search?sort=age:desc
GET /es_db/_search?_source=name&sort=age:desc
###########################################
# 索引的信息 包含字段的类型等
GET /es_db/
# 全部
GET /es_db/_search
{
"query": {
"match_all": {}
}
}
#模糊查询 单字段
GET /es_db/_search
{
"query": {
"match": {
"address": "中国"
}
},
"from":0,
"size": 1,
"_source":["name","age","sex"]
}
#查询address和name中包含caicai
GET /es_db/_search
{
"query":{
"multi_match":{
"query":"caicai",
"fields":["address","name"]
}
}
}
# 前缀类型
GET /es_db/_search
{
"query": {
"prefix": {
"name": {
"value": "a"
}
}
}
}
GET /es_db/_search
{
"query":{
"match_phrase":{
"address":"中国人"
}
}
}
## 根据sex精准匹配
GET /es_db/_search
{
"query": {
"term": {
"sex": {
"value": "0"
}
}
}
}
# 年龄10-25之间
GET /es_db/_search
{
"query": {
"range": {
"age": {
"gte": 10,
"lte": 25
}
}
}
}
# 年龄name叫caicai或者admin的人
GET /es_db/_search
{
"query": {
"terms": {
"name": [
"caicai",
"admin"
]
}
}
}
# 查询地址包含中国,而且年龄在10-25之间的人
GET /es_db/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "中国"
}
},
{
"range": {
"age": {
"gte": 10,
"lte": 25
}
}
}
]
}
}
}
GET /es_db/_search
{
"query":{
"match":{
"address":"中"
}
}
}
## 高亮
GET /es_db/_search
{
"query":{
"bool":{
"filter":{
"match":{
"address":"中"
}
}
}
},
"highlight": {
"fields": {"address": {}}
}
}


![[前端基础] CSS3 篇](https://img-blog.csdnimg.cn/9e5bb277a5b746d0a3c7848840da9b02.png#pic_center)