我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107
#CCA-Attention
全局池化+局部保留,CCA-Attention为LLM长文本建模带来突破性进展
琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),实现超长文本的高效上下文建模。在 128K 超长序列上下文建模任务中,CCA-Attention 的推理速度是标准自注意力机制的 7.9 倍,同时键值缓存(KV Cache)显存占用减少 93%,性能全面优于现有高效注意力方法。
论文标题:Core Context Aware Transformers for Long Context Language Modeling
论文链接:https://arxiv.org/pdf/2412.12465
代码链接:https://github.com/chenyaofo/CCA-Attention
发布时间:2024年12月17日
该成果已被 ICML 2025 接收,最早于 2024 年 12 月 17 日提交至 ArXiv,早于 DeepSeek NSA 和 Kimi MoBA 公开。CCA-Attention 不仅速度快、资源占用低,更在上下文建模的精准度和效率上树立了新标杆,为长文本处理注入全新动力。
引言
近期研究 [1, 2, 3] 发现,LLMs 中的大多数层的注意力权重主要集中在少数 token 上,表现出显著的稀疏性(见图 1)。这一发现启示我们可以借助这种稀疏特性,降低注意力机制的计算复杂度。

图 1: LLaMA2-7B 模型中注意力权重的可视化,阴影越深表示注意力权重越高。最后一个 token 仅对上下文少数几个 token 有着较高的注意力权重,即注意力权重具有显著的稀疏性。
现有稀疏注意力方法 [5, 6, 7] 通常通过预定义的稀疏模式来降低计算成本。然而,在问答任务中,关键信息可能分布在上下文的不同位置,模型需要能够访问任意位置的信息,作者称这一特性为「可达性」。已有方法往往忽视了保持 token 之间可达性的重要性,可能导致信息传递受限,从而影响模型在长序列和复杂任务中的表现。
为解决这一问题,作者提出了一种即插即用的高效长文本上下文建模方法——关键上下文感知注意力机制(CCA-Attention),其特点如下:
- 高效长文本建模: 通过全局池化注意力与局部保留注意力的协同设计,在显著降低计算量的同时保持对长距离依赖的建模能力。
- 线性计算复杂度: 通过引入 core token 聚焦关键上下文,大幅提高计算效率。
- 可即插即用集成:无需修改模型结构和从头训练,可以轻松集成到预训练的 LLM 中,仅需少量微调即可实现性能优化。
对比 DeepSeek 发布的 NSA [8] 需引入额外的压缩模块并从头训练 LLMs,CCA-Attention 无需引入额外参数和修改模型结构,可以无缝替换现有 LLMs 中的标准自注意力模块。对比月之暗面发布的 MoBA [9] 通过门控机制丢弃不相关块,CCA-Attention 通过动态聚合关键上下文为核心 token 的方式,在降低计算量的同时,确保所有 token 的信息交互,保留了完整的全局建模能力。
CCA-Attention:革新性的解决方案

图 2: CCA-Attention 示意图
全局感知池化:降低计算维度的智慧之举
标准自注意力计算量随序列长度呈平方级增长,长序列处理计算开销极大。大量研究发现注意力权重的分布并不均匀,绝大部分注意力权重被分配给了少数重要 token,其余部分贡献有限,属于冗余上下文。
受此启发,作者提出全局感知池化模块。具体而言,将输入序列

,分成互不重叠的

个组,g 为分组大小。对于第 i 组

,使用该组最后一个 token
![]()
的 query 向量与组内所有 token 的 key 向量计算重要性分数,并获得该组核心
![]()
:

其中,
![]()
是第 i 组
![]()
的最后一个 token 对应的 query 向量,

是第 i 组的 key 矩阵,
![]()
和
![]()
是可学习的参数。将各组 core token 拼接起来得到 core token 序列
![]()
。
为减少冗余,作者使用 core token 序列
![]()
代替原始 token 进行注意力计算,将维度从
![]()
降至
![]()
,从而降低了计算和存储复杂度。通过 core token 序列计算得到的键值矩阵表示为:

其中
![]()
和
![]()
是可学习参数。
局部保留模块:捕捉局部依赖的关键
尽管全局感知池化模块能有效捕捉长距离依赖,但由于其压缩特性,可能会忽略细粒度的局部上下文,而这些局部语义对于语言建模同样至关重要。为此,作者进一步提出局部保留模块(Locality-preserving Module),为全局模块提供有效互补信息。
具体来说,该模块会确保每个 token 都能至少关注前面 w 个原始 token,以此来捕捉局部上下文信息,保留连续性语义信息:

为了应对生成过程中标记数量难以维持为组大小 g 的整数倍的问题,作者将局部窗口大小设置为

,确保注意力窗口与组大小对齐,避免信息遗漏;
![]()
是原始 token 序列经过线性变换后的键值矩阵。
局部保留模块与全局池化模块共享线性变换参数
![]()
,不会引入额外参数开销。在实际推理中,局部模块提供精细语义支持,弥补全局压缩带来的信息损失,共同构成完整的上下文建模体系。
全局-局部模块可微融合:打造全面可达性的桥梁
全局感知池化模块和局部保留模块在计算时都只涉及部分 token,导致注意力的可达性有限。为解决这个问题,作者采用全局-局部模块可微融合策略。具体而言,该策略将两种注意力模块中的键值矩阵进行组合,形成统一的键矩阵

和值矩阵

。由此,CCA-Attention 的最终输出表示为:

其中,每个位置的输出计算表达式如下:

基于 Triton 的底层加速:提升效率的强大动力
为了在训练、预填充、解码期间实现 FlashAttention 级别的加速,作者基于 Triton 实现了硬件对齐的 CCA-Attention 内核。作者借鉴 FlashAttention 的设计思路,利用 Triton 进行底层算子融合,将全局池化注意力和局部保留注意力整合为一个独立且缓存友好的算子,有效消除冗余计算,并原生支持 KV 缓存技术,进一步提升训练、预填充、解码阶段的计算效率。相比标准自注意力机制,CCA-Attention 在计算复杂度和 KV 缓存内存占用方面具有显著优势,从而在整体上实现了更快的运行速度与更高的内存利用效率。
实验结果
实验设置
作者将 CCA-Attention 应用于 LLaMA2-7B-32K 和 LLaMA2-7B-80K 模型,并在 SlimPajama 数据集上微调 1,000 步。对比方法包括 StreamingLLM、LM-Infinite 和 MInference 等高效注意力方法。评估指标涵盖 LongBench 基准测试和多文档问答准确匹配得分(EM Score)等,全面衡量模型在长文本任务中的性能表现。
长序列语言建模
在 LongBench-E 基准测试中,CCA-LLM 取得了最高的平均得分。以 LLaMA2-7B-32K 模型为例,其得分显著优于 LM-Infinite 和 MInference;在 LLaMA2-7B-80K 模型上,CCA-Attention 依然表现出色,平均分数与标准自注意力相当,同时推理延迟和显存占用大幅降低,展现出更强的长序列处理效率优势。

表 1: 长序列语言建模实验
长文档问答任务
在多文档问答任务的 EM Score 评估中,CCA-LLM 在不同序列长度下均展现出优异的表现,且其性能优势随着上下文长度的增加而愈加明显。在处理超长上下文(如 64K 和 128K)任务时,CCA-LLM 的 EM 得分超越了标准自注意力机制,同时推理速度也显著提升——在 128K 上下文长度下,推理速度达到标准自注意力方法的 7.9 倍,展现出其在高效长文本建模方面的突出优势。

表 2: 长文档问答实验
计算和存储效率对比
相比标准自注意力及其他高效注意力方法(如 MInference),CCA-Attention 在推理速度与内存占用方面展现出显著优势。不同于 MInference 等仅关注预填充(prefilling)阶段加速的方法,CCA-Attention 能够同时优化预填充和解码(decoding)两个阶段,实现端到端的全流程高效推理。
在 64K 上下文长度下,CCA-Attention 的推理速度达到标准自注意力的 5.7 倍,KV Cache 显存占用也大幅降低;在 128K 上下文任务中,推理速度提升更是达到 7.9 倍,同时 KV Cache 显存使用减少高达 93%,充分体现了其在长序列建模中的高效性与实用性。

图 3: 内存与计算效率对比
总结
作者提出了一种面向长序列建模的关键上下文感知注意力机制(CCA-Attention)。相比标准自注意力,在保持模型性能的前提下,CCA-Attention 显著降低了计算开销。
该方法由两个互补模块构成:
- 全局感知池化模块:基于输入 token 的重要性提取核心 token(core token),用于后续注意力计算,从而高效捕捉全局粗粒度的信息;
- 局部保留模块:聚焦于邻近 token 的细粒度上下文信息,作为对全局池化模块的有效补充。
实验结果表明,CCA-Attention 在多种长文本任务中表现出色,同时显著提升了计算效率,具备良好的实用性与可集成性。
#Segment Policy Optimization (SPO)
大模型强化学习新突破——SPO新范式助力大模型推理能力提升!
当前,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。DeepSeek R1、Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。
然而,要实现有效的强化学习,需要解决一个根本性的挑战,即信用分配问题(credit assignment):在大语言模型的场景下,如何将整个序列(LLM 的回复)最终的评估结果,归因到序列中具体的决策动作(token)上。
这一问题的困难在于奖励信号非常稀疏 — 只能在序列结束时才能获得明确的成功或失败反馈。
当前主要方法
在强化学习中,通常采用优势值估计(advantage estimation)的方法来解决信用分配问题。目前针对大语言模型的强化学习方法主要分为两类,它们之间的区别在于优势值估计的粒度不同。
粗粒度的轨迹级 (trajectory-level) 方法,如 DeepSeek R1 使用的 GRPO,只根据最终的奖励为整个序列计算一个优势值。这种方法虽然高效但反馈信号过于粗糙,LLM 无法对错误回答中正确的部分进行奖励,也无法对正确回答中冗余的部分进行惩罚。
另一种极端是细粒度的 token 级(token-level)方法,如经典的 PPO。这类方法为每个 token 估计优势值,需要依赖额外的 critic 模型来预测每个 token 的状态价值(V 值)。然而,在大语言模型的强化学习任务中,不同 prompt 对应的轨迹分布差异很大,而且在训练过程中每个 prompt 采样出来的模型回复数量非常有限,critic 模型难以训练好,造成 token 级的优势值估计误差很大。
新的 SPO 框架
为突破这一瓶颈,来自中科院软件所和香港城市大学的的研究团队创新性提出了 Segment Policy Optimization (SPO) 框架。
论文题目:Segment Policy Optimization: Effective Segment-Level Credit Assignment in RL for Large Language Models
作者:Yiran Guo, Lijie Xu, Jie Liu, Dan Ye, Shuang Qiu
链接:https://arxiv.org/abs/2505.23564
代码链接:https://github.com/AIFrameResearch/SPO
SPO 使用了一种中等粒度的段级(segment-level)优势值估计方式。它不像轨迹级方法只在最后一步计算优势,也不像 token 级方法每步都计算优势,而是将生成的序列划分为若干相连的段,计算每个段的优势值。
这种段级的优势值估计方式具有几个明显的优势:
(1) 更优的信用分配:相比轨迹级方法,段级方法能够提供更局部化的优势反馈,让模型能够奖励错误回答中仍然有价值的部分,同时也能惩罚正确回答中冗余和无效的片段。
(2) 更准确的优势值估计:相比 token 级方法,段级方法所需的估计点数量更少,从而能够有效利用蒙特卡洛(Monte Carlo, MC)采样得到更加准确且无偏的优势值估计,而无需再依赖额外且不稳定的 critic 模型。
(3) 更灵活、更易调整:段级的划分方式可以任意定义,并不要求语义上的完整性,因此可以灵活地在 token 级与轨迹级之间自由调整粒度,并且可以适应不同的任务和应用场景。
SPO 框架主要包含三个核心部分:(1) 灵活的段级划分策略;(2) 基于蒙特卡洛采样的段级优势值估计;(3) 利用段级优势值进行策略优化。
这种模块化的设计使框架具备高度的灵活性,不同的部分可以有不同的实现策略,以适用不同的应用场景。
该团队进一步针对不同的推理场景提出 SPO 框架的两个具体实例:对于短的思维链(chain-of-thought, CoT)场景,提出了 SPO-chain,该方法使用基于切分点(cutpoint-based)的段划分和链式优势值估计;对于长 CoT 场景,提出极大提升 MC 采样效率的树形结构优势值估计方法。
此外,该团队还提出了一种 token 概率掩码(token probability-mask)策略优化方法,选择性的对段内的低概率 token 计算损失而非段内的所有 token。作者认为这些 token 是模型推理轨迹可能发生分叉的地方,是段级优势值产生的主要原因。这种方法可以用于 SPO-chain 和 SPO-tree,从而进一步强化信用分配。
框架及核心技术
SPO 框架主要围绕以下三个具有挑战性的问题进行设计:(1) 如何将生成的序列划分为多个段?(2) 如何准确且高效地估计每个段对应的优势值?(3) 如何利用段级优势值来更新策略?SPO 的三个核心模块分别解答上面三个问题,每个模块包含多种可选策略,来适用于不同的场景:

1. 段划分 (Segment Partition):
a) 基于切分点的段划分 (Cutpoint-based Partition): 为短思维链场景设计,将段划分点放置在状态值(V 值)更有可能发生变化的地方。根据 token 概率动态确定段边界,优先在模型 “犹豫” 或可能改变推理路径的关键点(cutpoints)进行划分,使信用分配更精确。比如,在下图例子中,标记为红色的 token 是关键点,而标记为蓝色的竖杠是分段结果。

b) 固定 token 数量段划分 (Fixed Token Count Partition): 将序列划分为固定长度的段,便于树形结构的组织和优势值估计,为 SPO-tree 设计。
2. 段级优势值估计(Segment Advantage Estimation):

a) 链式优势值估计 (Chain-based) 方法:在短思维链场景下,MC 采样的成本不高,该团队采用一种直接的段级优势值估计方式,独立估计每个段边界的状态值(V 值),然后计算段级优势值。以下公式展示了链式优势值的估计方法。

![]()
b) 树形优势值估计 (Tree-based): 在长思维链场景下,MC 估计的代价很高,团队提出了一种高效的树形估计方法:将采样轨迹组织成树形结构,通过自底向上的奖励聚合计算状态价值(V 值),同一个父节点的子节点形成一个组,在组内计算每个段的优势值。这种方式将用于 V 值估计的样本同时用于策略优化,极大提高了样本效率。以下公式展示了树形优势值估计方法。

3. 基于段级优势值 token 概率掩码策略优化(Policy Optimization Using Segment Advantages with Token Probability-mask):
在得到段级优势值以后,为了进一步提高信用分配,团队创新性地提出 token 概率掩码策略优化方法,在策略更新仅将段级优势值分配给该段内的低概率(关键)token,而非所有 token。这种方法能更精确地将奖励 / 惩罚赋予关键的决策点,提升学习效率和效果。下面分别展示了 SPO-chain 和 SPO-tree 的优化目标。
a) SPO-chain 优化目标:


b) SPO-tree 优化目标:


对比基线方法
如下图所示,在短思维链场景,使用 RhoMath1.1B 作为基座模型,使用 GSM8K 训练集进行训练,对比各种训练算法,使用 SPO 训练得到的模型测试集正确率更高。

对于长思维链场景,如下图所示,使用 DeepSeek-R1-Distill-Qwen-1.5B 作为基座模型,使用 MATH 数据集进行训练,在相同的训练时间下,测试集正确率比 GRPO 更高。

下表展示了在长思维链场景下的更多对比结果:与同期基于相同基座模型(DeepSeek-R1-Distill-Qwen-1.5B)并使用 GRPO 方法训练得到的模型(DeepScaleR、STILL-3)相比,尽管 SPO 仅使用 MATH 数据集且仅使用 4K 的最大上下文长度进行训练,SPO-tree 在各个上下文长度评测下表现优秀。值得注意的是,尽管 DeepScaleR 在 32K 上下文长度评测下表现最佳,但它在较短上下文长度(2K 与 4K)下却表现最差,甚至不及原始基座模型。这表明,GRPO 训练方法可能未有效优化模型的 token 效率,导致输出存在较多冗余,从而在上下文长度有限的情形下出现正确率下降的问题。

分段粒度的影响

通过实验发现,很细的粒度 (int2,每个两个切分点进行分段),相比于中等粒度 (int5),仅有微小提升,但是过粗的粒度 (int100),相比于中等粒度 (int5),正确率下降很大。证明了 SPO 采用中等粒度优势值的有效性。
段划分方式的影响

实验表明,在短思维链场景下,采用提出的基于切分点的段划分方式效果最好,优于采用换行符进行划分(VinePPO)以及固定 token 数量划分(Fixed-token-count)。
Token 概率掩码消融

实验表明,将 token 概率掩码去除会导致 SPO-chain 正确率下降,更值得注意的是:将 token 概率掩码应用到 GRPO 上,会让其正确率有明显上升。
不同树结构的影响

实验表明,更小的树结构在早期正确率更高,可能因为更快扫过更多的数据样本。然而随着训练的进行,更大的树结构会有更好的正确率,因为更大的树结构对于段级优势值的估计更加准确。
总结
该工作提出了一种基于中间粒度段级优势值的 RL 训练框架 SPO,在 token 级和轨迹级之间更好的平衡,具有比轨迹级更好的信用分配,同时仅需要少量优势值估计点,可以使用有效无偏的 MC 方式进行估计,不需要额外的 critic 模型。
文章同时提出了 SPO 的两个实例,为短思维链场景设计的 SPO-chain 以及为长思维链场景设计的 SPO-tree,通过实验证明了 SPO 框架和两个实例的有效性。
#从量产角度谈谈BEV感知
LSS和Transformer如何选择?1 前言人工智能技术的蓬勃发展已经引起了各行各业的技术革命,而智能驾驶技术,作为AI落地历程的一大里程碑,已经成为近年产业界和学术界关注的重点。经过了智驾技术的数年沿革,BEV(Bird's Eye View)已成为了其感知系统的一种基本范式。基于BEV的相关技术给了车辆“上帝视角”的全局感知能力,不仅打破了多模态数据融合的壁垒,更让智驾系统实现了从“被动拼接”到“主动认知”的跃迁。下面,本文将对应用于智驾的视觉BEV感知方案发展情况做简要综述,并从硬件架构设计的角度分析高效部署BEV面临的挑战。
2 BEV是什么?我们为什么需要BEV?
自动驾驶向L3+的持续演进,驱动着任务应用场景更加广泛和复杂。从较简单的ACC、LCC到更为复杂的APA、NOA,智能驾驶算法的发展态势更加趋向于大算力、多模态。
本质上,基于神经网络的智驾方案与其他很多CV领域的AI算法一样,也是一个通过对“图像”(这里我们暂且把Radar、Lidar也称为一种“图”)的分析处理来得到理想输出的单一解问题。一套传统的自动驾驶系统完成工作主要经过三步:通过面向外部世界的传感器获得各种信息,结合自车运行态的数据实现动作决策,最终控制车辆实现转向制动等实际操作。现如今随着行业任务需求的发展,单传感器已经很难完成任务,为了应对更加复杂的驾驶场景和任务,也为了保证智驾系统管理下的车辆安全性,多摄像头甚至Lidar的加入已经成为了客观趋势,而这种多模态的输入一定程度上更优于人类司机单一视角,在感知部分已基本实现了完备性。
图1 ADAS系统中传感器部署示例(图源:[14])
但同时,就算已经有不同种类足够多数量的输入,如何将这么多的输入利用起来呢?以环视多摄像头的输入为例,如图2所示,对于车身周围两个不同位置的摄像头,其拍到的路况信息在现实世界的几何位置上大部分是不会重叠的,也就是说,我们在感知处理时无法通过把某个输入映射到另一个输入相应位置的形式实现特征图的导出(这通常是单摄像头多模态融合问题的常用处理策略)。因此最直观的方法就是使用一种“能放的下所有位置的特征图”,那么BEV就应运而生了。
图2 车身环视摄像头作用域示例
BEV主要用于在智驾系统中解决感知问题,其实际上是指以俯视视角构建的中间特征图,感知部分的神经网络输入多摄像头图像或Lidar点云,输出映射到一个固定宽高的俯视网格上,每一个输入都有其对于BEV图的映射关系,就实现了对多模态输入信息的有效表征。通过BEV,多加的传感器就实现了应用意义。综合来看,以BEV作为感知方案的优势有以下几点:
- 统一的特征图形式:多摄像头图像、Lidar图像可以统一在BEV空间投影,消除透视畸变带来的距离估计误差,有利于多模态场景下scalable。
- 便于时序建模:BEV特征图可作为时间序列的载体,更好支持实际智驾场景中多帧视频流的输入,支持长时序运动预测。
- 决策友好性:俯视视角与规划控制模块的思考维度天然对齐,简化下游任务处理。
图3 BEVFormer中的camera输入和其在BEV视角实现的识别任务
3 视觉BEV:从LSS到Transformer
BEV感知是一个较为宽泛的领域,其网络输入主要有点云和视觉图像两种,传感器不同,所对应的算法网络结构思想也是完全不同的。这部分我们将讨论视觉感知的经典算法,通过了解BEV感知算法的基本框架,对其运算方式的特异性进行分析。
首先,从任务端到端的角度来看,如图4,BEV感知任务的对应网络实现主要分为三大部分:前端的特征提取网络,用于将相机输入图片处理为特征图,通常使用SwinT或ResNet等成熟的特征提取方法;中间的视角转换模块(VTM,View Transformation Module),用于将Camera域的特征图转换到俯视角度下的BEV特征图,也是模型中最为复杂的部分;后端的task head,根据具体的任务场景要求处理BEV特征图,实现诸如识别、分割、轨迹规划等后端任务,这一部分也同样可以使用成熟的替换插件。对于前后端的部分,卷积和Transformer的硬件实现方案已经基本成熟,因此,如果想要设计一款高吞吐的BEV感知处理器,最为需要关注的就是如何高效实现VTM。
图4 BEVDet[7]的网络各部分
算法上,对于VTM的实现方法已经有了两种基本范式,我们这里延续[3]的命名法:
- Forward Projection:以LSS(Lift Splat Shoot)为代表,通过对每张图的深度进行估计,以此得到camera中某位置特征点映射到俯视角度的直接映射关系,通过投影和BEV pooling的方式将其映射到网格上。
- Backward Projection:以BEVFormer为代表,通过Attention机制构建BEV网格特征与特征图之间的相互关系,以此得到dense的BEV特征图。
针对这两种方案的算法结构介绍相信论坛里的帖子已经有了很详细的讲解,因此这里我们不再赘述,只以一个硬件架构设计者的角度简要分析这两种算法中有趣的部分。
LSS
LSS是NVIDIA在2020 ECCV上发布的BEV感知算法,实现较早也较简单,其VTM部分利用深度估计结合相机内外参矩阵进行几何映射实现,是即插即用的设计。由于LSS的深度估计部分并不精确,且很难应用具体场景中的时序信息,因此现在并不在各大刷分网站上居于SOTA地位,但仍不失为一种容易部署的,较为轻量化的经典VTM方案。
Splat pooling导致随机存取
从算法本身角度上,LSS中实际用于Camera到BEV的视角转换的部分是Splat。在该步骤中,先要通过内外参矩阵的运算得到转换矩阵,矩阵中存放着输入视锥点云(通过前序的深度估计得到)中某像素位置某深度的点对应在BEV坐标下的位置,接下来LSS通过该映射关系矩阵从对应视锥中取相应坐标的点,并将其放置到BEV对应网格点上,并采用pillar pooling的trick加速这一得到BEV特征的过程(当然,这种算法编程上的trick在专用硬件的构建中意义不大)。
这一过程并不涉及对运算的需求,但需要在单次处理中对整个视锥点云中的点做Gather/Scatter的操作,且每次读取的数据并不能重用,对于硬件带宽提出了很高的需求。而这种随机读写操作的方式取决于相机内外参,因此常常是设备特异的,很难利用常规并行计算硬件,如NPU、GPU等在运算阵列上的优势。针对这一问题,算法界也提出了一些改进方案,如[4]利用矩阵运算完成VTM,以避开带宽受限的Splat操作。
图5 LSS流程:输入图像→视锥点云→BEV
Transformer
BEV+Transformer的范式首先由Tesla AI Day中首先提出,基于其纯视觉方案实现,现如今已经成为部署最广落地应用最多的BEV感知方案。当然,现在Tesla力推端到端且并未开源,我们并不知道其如何得到BEV,但该范式仍被国内各大厂家follow,transformer(或者说是attention)方案现在仍是最稳定的BEV感知方案之一。
BEVFormer[2]在2022 ECCV上被发布,其采用了Deformable DETR中的attention方案,实现了类似Tesla的BEV感知效果,使得视觉BEV方案的精度有了大幅提高(基于原始的纯视觉实现,BEVFormer近几个月新发布了多模态的版本[5])。目前,BEVFormer已经作为一项经典的BEV实现算法,在地平线[6]、NVIDIA等一众硬件上实现了部署。其提出的attention机制也可以单独作为backbone被直接应用在其他网络上。下面,我们以BEVFormer为例,对BEV+Transformer范式进行分析。
多层Transformer架构导致大算力需求
首先,相比于LSS直接映射的单层设计,BEVFormer方案中采用堆叠Attention层的方法进行BEV特征的提取。每个子模块包含两个不同机制的Attention层:1. Temporal self attention:相邻帧的BEV特征之间做Attention,用于融合前后帧之间的时序信息;2. Spatial cross attention:当前帧BEV特征维度上做Attention,用于整合空间信息;由于BEV的特征维度很高(如典型值:BEVFormer_tiny为50×50×256),多层Attention的VTM设计会极大提高网络需要的硬件计算量和存储参数量的需求,例如对于BEVFormer-S预计每帧需要1.3T的算力,单网络对于车载SoC的算力需求是非常大的。
图6 BEV+Transformer架构工作流
特殊算子Deformable Attention
其次,对于BEV感知的优化点,集中在如何简单高效地从原始2D特征中筛选处理特征到新的3D维度上。BEVFormer在此采用的方案是Deformable DETR中采用的Deformable attention,在具体计算过程中,该方案需要使用grid_sample算子,双线性插值的方法从Value矩阵中根据坐标取值并赋以权重,不同于传统Self-attention机制对于全局做Attention,这一方案优势是可以极大减少对大Tensor的处理计算量,缺点是无重用的随机存取过程同样导致对于硬件带宽的需求。
另外,在实际的智驾场景中,由于自车运行状态变化会导致输入参数变化,时序Attention中的旋转角、空间Attention中的mask等是要进行动态运算的,这也就给硬件部署的支持造成了额外的压力。
图7 Deformable Attention
BEV in nuScenes
nuScenes是一个大规模自动驾驶公开数据集,由Motional团队于2019年发布,其中包含3D目标识别、多传感器融合、轨迹预测等算法的开环训练和验证数据集。nuScenes现已成为智驾算法的一大跑分平台,业内各大公司、研究机构均常用其检验自家算法的运行情况,其上的网络情况一定程度上也能表征某任务主流SOTA网络形态的发展趋势。
以3D目标识别任务为例,截至数据整理的2024年12月,其上已有不少视觉BEV方案实现了SOTA的效果,例如:HoP[8]对于BEV网络的时序信息整合方案进行了优化,生成伪BEV,且可以直接整合进现有的BEV backbone中;VCD[9]在训练中加入了Lidar信息进行辅助蒸馏;VideoBEV[10]关注长时间序列的BEV时序信息处理等等。现在的BEV识别算法也更倾向于对VTM部分进行优化,大多采用Attention的方案,更关注于充分利用Attention优势对于时序信息做更好的处理,或者引入更多的监督信息以规避纯视觉方案在推理状态下缺乏信息的弊端。
现有的硬件BEV解决方案
目前,硬件领域公开论文中对于BEV感知的讨论并不多,其中值得follow的有清华在2024年CICC、JSSC[11]上发布的工作,其核心关注点主要在特殊映射算子和大算力需求两方面。
这项工作的内容更多倾向于是将视觉BEV作为点云3D感知硬件的拓展,文章采用了BEVFusion[12]作为验证算法,将点云和图像两个不同域的输入统一到了一个BEV的表征框架下。文章主要关注的算子中,对于点云部分,其提取了SCONV作为基本算子,而视觉部分则对于LSS mapping进行了实现。为了实现SCONV和LSS中的动态映射,该工作采用了可重构CAM阵列进行index的存储,实现了算法感知的CAM调度方案进行加速。并且设计了可拓展的chip-level拓扑以在单芯片算力不足的情况下实现大规模BEV算法的部署。
对于业界的实际应用上,由于BEV的相关算法往往存在大批量的高带宽索引操作或与Attention机制相关的element-wise算子,这与传统意义的并行计算硬件很难兼容。各家对于这种形式运算的直接支持并不是太好,因此更倾向于采用软硬件协同优化的方式进行规避。例如采用MatrixVT[4]、FastBEV[13]等兼容性好的,或通过修改算法的方式实现BEVFormer。现在的智驾应用场景也对算法复杂度提出了更高的需求,因此,车载芯片的发展趋势更倾向于大算力,且可能需要涵盖座舱和智驾两方面的AI运算需求,例如地平线的J6算力最高560T,NV的Thor预期算力甚至达2000T。
图8 MatrixVT(下)采用矩阵运算替代复杂的LSS pooling(上)
5 总结与展望
随着近年智驾技术的飞速发展,BEV+Transformer范式已经成为了视觉3D感知的一个经过实践检验的“标准解”。其相关应用的算子独特性和运算复杂性也已经对智驾相关的硬件提出了更高的要求。受AI智驾方案本身的限制,其在车端的部署某种程度上可以说已经超越了边缘侧的一般需求,更倾向于要求大算力甚至分布式调度。BEV感知在实践中很有效,但算法过“大”,这也逼迫着算法和硬件设计者去做特殊算子的设计,而这在某种程度上又提高了对带宽和专用硬件的需求,可以说,不仅仅是BEV感知,很多AI相关的算法与硬件就是在这种trade-off中前进的。
而对于视觉BEV感知方面(1)如何解决BEV映射问题和(2)大算力大存储带宽需求问题,已经成为当前BEV+Transformer硬件SoC架构和设计的两个重要难点。
诚然,跟随着Tesla这一行业风向标,目前工业界智驾SOTA或已由BEV、Occupancy等显式环境建模技术,逐步过渡到端到端神经架构(这类“黑箱”系统通过海量数据驱动,直接从传感器输入映射到控制信号,以追求更高的场景泛化性与决策流畅性)。然而,BEV框架仍展现出不可替代的工程实践价值与可解释性优势,尤其在对安全性要求严苛的自动驾驶领域。
参考文献
[1] Philion, Jonah, and Sanja Fidler. "Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d." Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV 16. Springer International Publishing, 2020.
[2]Li, Z., et al. "BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers. arXiv 2022." arXiv preprint arXiv:2203.17270.
[3] Li, Zhiqi, et al. "Fb-bev: Bev representation from forward-backward view transformations." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
[4] Zhou, Hongyu, et al. "Matrixvt: Efficient multi-camera to bev transformation for 3d perception." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
[5] Li, Zhiqi, et al. "Bevformer: learning bird's-eye-view representation from lidar-camera via spatiotemporal transformers." IEEE Transactions on Pattern Analysis and Machine Intelligence (2024).
[6] 地平线 3D 目标检测 Bevformer 参考算法 V2.0
[7] Huang, Junjie, et al. "Bevdet: High-performance multi-camera 3d object detection in bird-eye-view." arXiv preprint arXiv:2112.11790 (2021).
[8] Zong, Zhuofan, et al. "Temporal enhanced training of multi-view 3d object detector via historical object prediction." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
[9] Huang, Linyan, et al. "Leveraging vision-centric multi-modal expertise for 3d object detection." Advances in Neural Information Processing Systems 36 (2023): 38504-38519.
[10] Han, Chunrui, et al. "Exploring recurrent long-term temporal fusion for multi-view 3d perception." IEEE Robotics and Automation Letters (2024).
[11] Feng, Xiaoyu, et al. "A Scalable BEV Perception Processor for Image/Point Cloud Fusion Applications Using CAM-Based Universal Mapping Unit." IEEE Journal of Solid-State Circuits (2024).
[12] Liu, Zhijian, et al. "Bevfusion: Multi-task multi-sensor fusion with unified bird's-eye view representation." 2023 IEEE international conference on robotics and automation (ICRA). IEEE, 2023.
[13] Huang, Bin, et al. "Fast-BEV: Towards real-time on-vehicle bird's-eye view perception." arXiv preprint arXiv:2301.07870 (2023).
[14] ADAS系统传感器应该如何布置_adas 传感器-CSDN博客
#新的端到端闭环仿真系统终于用上了
随着神经场景表征的发展,之前出现了一些方法尝试用神经辐射场重建街道场景,像Block-NeRF 。但是它无法处理街道上的动态车辆,而这是自动驾驶环境仿真中的关键方面。最近一些方法提出将动态驾驶场景表示为由前景移动汽车和静态背景组成的组合神经表示。为了处理动态汽车,这些方法利用跟踪的车辆姿态来建立观察空间和规范空间之间的映射,在那里他们使用 NeRF 网络来模拟汽车的几何形状和外观。虽然这些方法产生了合理的结果,但它们仍然局限于高训练成本和低渲染速度。基于这些前述工作,浙大提出了Street Gaussians。笔者有幸参与了公司新一代闭环仿真系统的开发,花了几个月的时间,终于把基于Street Gaussians的算法落地。今天就分享下自己的一些看法~
下图是在Waymo数据集上的渲染结果。street gaussians的方法在训练半小时内以 135 FPS的速度产生高质量的分辨率为1066×1600渲染视角。这两个基于NeRF的方法存在训练和渲染成本高的问题。
以前的方法通常面临训练和渲染速度慢以及车辆姿态跟踪不准确的挑战。给定从城市街道场景中的移动车辆捕获的一系列图像,street gaussians的目标是开发一个能够生成逼真图像以进行视图合成的高效模型。为了实现这一目标,street gaussians基于3DGS,提出了一种新颖的场景表示,专门用于建模动态街道场景。
动态城市街道场景表示为一组基于点的背景和前景物体,具有可优化的跟踪车辆姿势。每个点都分配有一个 3D 高斯,包括位置、不透明度和由旋转和缩放组成的协方差,以表示几何形状。为了表示外观,street gaussians为每个背景点分配一个球面谐波模型,而前景点与动态球面谐波模型相关联。显式的基于点的表示允许轻松组合单独的模型,从而实现高质量图像和语义图的实时渲染(如果在训练期间提供 2D 语义信息),以及分解前景对象来进行场景编辑。
Street Gaussians用单独的神经点云表示静态背景和每个移动车辆对象。
接下来,我将首先介绍它的背景模型,详细说明与对象模型共享的几个常见属性。随后,我将深入讲解它的动态物体模型设计。
背景模型表示为世界坐标系中的一组点。每个点都分配有一个 3D 高斯,来表示连续场景的几何形状和颜色。高斯参数由协方差矩阵 Σb 和位置向量 µb ∈ R3组成。为了避免优化过程中出现无效值,每个协方差矩阵进一步简化为缩放矩阵 Sb 和旋转矩阵 Rb,其中 Sb 以其对角线元素为特征,Rb 转换为单位四元数。协方差矩阵 Σb 可以从 Sb 和 Rb 中恢复。
除了位置和协方差矩阵之外,每个高斯还被分配一个不透明度值和一组球面谐波系数来表示场景几何和外观。为了获得与视图相关的颜色,球面谐波系数进一步乘以从视图方向投影的球面谐波基函数。为了表示3D语义信息,每个点都添加了一个语义的概率。
对于物体模型,考虑一个包含 N 个移动前景物体车辆的场景。每个物体都用一组可优化的跟踪车辆姿态和点云表示,其中每个点都分配有一个 3D 高斯、语义概率和动态外观模型。物体和背景的高斯属性相似,不透明度 αo 和比例矩阵 So 具有相同的含义。然而,它们的位置、旋转和外观模型与背景模型不同。位置 µo 和旋转 Ro 在物体局部坐标系中定义。为了将它们转换为世界坐标系(背景的坐标系),我们引入了物体跟踪姿势的定义。具体而言,车辆的跟踪姿势定义为一组旋转矩阵 {Rt} Nt t=1 和平移向量 {Tt} Nt t=1,其中 Nt 表示帧数。转换可以定义为:xxx。
其中 µw 和 Rw 分别是世界坐标系中相应物体的高斯分布的位置和旋转。经过变换后,物体的协方差矩阵 Σw 可以通过前面的公式 和 Rw 以及 So 得到。需要注意的是,street gaussians还发现现成跟踪器的跟踪车辆姿态有很多噪声。为了解决这个问题,street gaussians将跟踪车辆姿态视为可学习的参数。
但是仅用球谐函数系数表示物体外观不足以对移动车辆的外观进行建模,因为移动车辆的外观受其在全局坐标系场景中的位置影响。一种直接的解决方案是使用单独的球谐函数来建模每个时间点的物体。但是,这种建模会显著增加存储成本。相反,street gaussians引入 4D 球谐函数模型,用一组傅里叶变换系数 f ∈ R k 替换每个 SH 系数 zm,l,其中 k 是傅里叶系数的数量。给定时间点t,通过执行逆离散傅里叶变换来得到渲染特征:xxx。
利用所提出的模型,street gaussians将时间信息编码到外观中,而无需高存储成本。物体模型的语义表示与背景的语义表示不同。主要区别在于,物体模型的语义是一个可学习的一维标量,它表示来自跟踪器的车辆语义类别。
4D球谐函数的效果。第一行显示输入的序列图像,展示不同的外观。第二行演示了利用所提出的4D球谐函数对渲染结果的影响。如果没有4D球谐函数,则可以观察到明显的伪影。
3D Gaussian 中使用的 SfM 点云适用于以物体为中心的场景。然而,它不能为具有许多观察不足或无纹理区域的城市街道场景提供良好的初始化。street gaussians使用自车捕获的聚合 LiDAR 点云作为初始化。LiDAR 点云的颜色是通过投影到相应的图像平面并搜索像素值获得的。为了初始化物体模型,street gaussians首先收集 3D 边界框内的聚合点并将它们转换为局部坐标系。对于 LiDAR 点少于 2K 的对象,street gaussians改为在 3D 边界框内随机采样 8K 点作为初始化。对于背景模型,street gaussians对剩余的点云执行体素下采样并过滤掉训练相机不可见的点,并且结合 SfM 点云来弥补 LiDAR 在大面积上的有限覆盖范围。
#DiffVLA
π0如何用于自动驾驶:CVPR'25端到端亚军方案解读
🏆 亮眼成果: 博世中国研究院与清华大学AIR团队的最新研究 DiffVLA,首次将通用机器人控制框架π0的"视觉-语言-动作"范式,成功改造为适应自动驾驶严苛要求的专用系统。该成果在Autonomous Grand Challenge 2025的navsim-v2 public leaderboard中,DiffVLA以45.0 EPDMS的优异成绩,展现了在真实与合成复杂场景下的强大鲁棒性与泛化能力。无论是无责碰撞率(95.71%阶段一,81.27%阶段二)、可行驶区域合规性(99.29%阶段一,88.84%阶段二),还是车道保持与舒适性指标,DiffVLA均表现出色! 传统端到端自动驾驶方法常受限于昂贵的BEV计算、动作多样性不足及复杂场景决策次优等问题。DiffVLA通过稀疏表示、扩散模型与VLM的深度融合,突破这些瓶颈,为自动驾驶的闭环性能树立了新标杆。
- 论文链接:https://arxiv.org/abs/2505.19381

架构传承:通用机器人控制的自动驾驶进化
π0证明了生成式VLA(Vision-Language-Action)框架在通用机器人控制的潜力,而DiffVLA首次实现了该范式在动态交通场景中的安全落地。 “如果说π0是‘会思考的机器人’,DiffVLA则是‘懂交规的老司机’:它继承了前者的多模态理解能力,但每一步决策都戴着安全的镣铐跳舞。”
- 改造难点 :
- 挑战1:语言指令与物理世界的割裂 :通用机器人环境下的“避开障碍物”指令 → 生成机械臂绕行动作",生成无视人类体感的车速与偏移量的自由轨迹。
- 挑战2:开放环境与规则约束的冲突:π0依赖纯视觉特征感知世界,这种开放环境下的“自由探索”逻辑,在交通系统中引发事故造成致命事故。
- 挑战3:生成模型的动作风险失控 在π0框架中,扩散模型生成的机械臂轨迹即使存在抖动(如±5cm偏移),也仅导致抓取失败;但自动驾驶在高对抗场景中,同等自由度的轨迹扩散会引发致命横摆
核心创新点:
通用机器人领域的的应用和自动驾驶领域的应用人有巨大的gap,为了将我们将从π0架构运用到自动驾驶领域,我们对编码器、解码器、数据、损失函数四大支柱展在自动驾驶领域的应用开深度剖析和深度改进,揭示从通用机器人智能体到自动驾驶智能体的底层逻辑。

- Encoder模块:我们采用了VLM Encoder 以及Perception Encoder模块,利用多视角图像与基础导航指令生成高级驾驶决策(减速,避让,绕行,变道),全面捕捉交通场景的显式与隐式特征,提升障碍物理解与道路结构分析能力,为后续扩散规划提供精准语义引导,减少语言指令和物理世界的割裂,降低生成模型的动作风险失控。
- Decoder模块:采用截断扩散策略与多模态锚点设计,优化多模态驾驶行为建模,显著提升复杂场景下的决策能力。
- 训练数据:和π0 采用类似策略,在pre-training阶段使用大规模数据对Encoder模块进行pre-training. 在post fine-tuning阶段采用了更多难例采样对action模型进行轨迹优化。
- Loss:我们的方案中为了更加直接的生成轨迹使用了diffusion policy 并对轨迹进行L2的监督,其中 表示对轨迹点的reconstruction loss, BCE则是对于轨迹类别的交叉熵损 失。
总体架构
端到端自动驾驶已成为一个重要且快速发展的研究领域。得益于大量人类驾驶示范数据的可用性,从大规模数据集中学习类人驾驶策略具有巨大潜力。现有方法如UniAD、VAD 以传感器数据为输入,通过单一可优化模型回归单模轨迹。进一步探索稀疏表示,提出对称稀疏感知模块和平行运动规划器。然而,这些方法忽略了驾驶行为的内在不确定性和多模态特性。利用生成领域的强大扩散概念,方法能够建模多模态动作分布。通过锚定高斯分布设计加速扩散过程。将VLM与端到端模型结合,提高轨迹规划精度。
尽管现有方法在nuScenes、navsim-v1、nuPlan等知名基准测试上表现稳健,但在闭环评估中实现鲁棒性能并超越记录状态仍是一大挑战。本文重新审视稀疏性、扩散和VLM的概念,提出了一种更全面的方法,并在闭环评估中验证了其性能。我们的框架采用Encoder-Decoder架构,分为三个关键组件:VLM Encoder、稀疏-密集混合Perception Encoder和基于扩散的Planner Decoder。我们在navsim-v2数据集上训练和评估我们的方法,该数据集通过引入反应性背景交通参与者和逼真的合成多视角相机图像,提供了全面的闭环鲁棒性和泛化能力评估。我们的方法在navsim v2竞赛的私有测试集上取得了45.0的EPDMS评分。

Encoder
π0 采用多模态Transformer统一处理RGB图像与语言指令, 实时融合视觉特征与文本语义。我们认为这个方案具有非常好的基础架构优势,但是对于自动驾驶的更复杂场景,更多元的规则约束,在π0的VLM Encoder架构中我们额外在encoder部分引入了Perception Encoder增强模型对环境的基础理解更好利用encoder进一步对场景结构进行细化。具体而言,我们引入了两个并行两大Encoder模块, VLM Encoder 以及 Perception Encoder:
VLM Encoder: 为实现自动驾驶场景中多模态信息的有效处理和融合,我们提出VLM命令引导模块。该模块基于Senna-VLM框架[7],利用多图像编码策略和多视角提示机制实现高效、全面的场景理解。Senna-VLM架构包括四个主要组件:视觉编码器、驾驶视觉适配器、文本编码器和大型语言模型(LLM)。视觉编码器处理来自Navsim [13]的多视角图像序列,提取图像特征。驾驶视觉适配器进一步编码和压缩这些特征,生成图像令牌,其中为图像数量,为每张图像的令牌数,为LLM的特征维度,和分别为图像高度和宽度。文本编码器将用户指令和导航命令编码为文本令牌,其中为文本令牌数。图像和文本令牌随后输入大型语言模型,生成高层次驾驶决策。在我们的实现中,视觉编码器采用CLIP的ViT-L/14 [14],LLM为Vicuna-v1.5-7B [15]。我们遵循标准Senna-VLM配置,处理所有车载相机传感器的图像。VLM命令引导模块生成高层次规划决策,分解为横向控制(例如换道、转弯)和纵向控制(例如加速、刹车)。这些决策通过单热编码机制编码,并与外部驾驶信号(如导航指令)整合。生成的命令通过命令编码器模块处理,为下游基于扩散的规划过程提供语义指导。
Perception Encoder:为了实现对结构化场景的更好理解,我们的encoder模块包含稀疏感知模块和密集感知模块。稀疏感知模块采用的采样策略进行3D物体检测和在线地图生成,而密集模块利用[11]的BEV特征投影方法生成BEV特征空间。稀疏模块输出3D边界框和地图向量,密集模块生成BEV特征向量,两者均被整合到后续轨迹头部。这两个模块的目的是同时利用代理和环境的隐式特征以及显式的物体和地图信息,克服仅使用基于投影或采样的方法构建BEV特征空间的局限性。显式3D边界框包含姿态、尺寸、航向角和速度等标准信息。地图向量以每个元素20个地图点表示。显式物体和地图信息通过多层感知机(MLP)编码生成嵌入。对于隐式分支,BEV网格大小设为128×128,覆盖以自我坐标系为中心的64×64米感知范围。我们聚合同30个代理和一个自车的信息,为后续轨迹扩散过程提供隐式指导。此外,显式物体和地图输出使规划器能够执行碰撞检测和可行驶区域检查,增强了基于特征的轨迹选择。感知模块的训练分为两个阶段。稀疏分支使用3D物体和地图元素的检测损失进行训练。随后,密集分支与轨迹头部一同训练,在稀疏分支训练完成后进行。所有感知分支均采用VoV-99骨干网络。
Decoder
π0 采用了基于score based的生成式模型作为轨迹生成方式,以前缀动作序列为条件自回归预测下一步操作(如关节扭矩或末端位移)。在自动驾驶运行场景更复杂,同事我们考虑到自动驾驶的轨迹预测其实是可以进行分层分解的。人类开车时首先受到high level的信息影响,比如我需要去哪里,下个路口左转还是右转,其次关注周围环境,如果环境复杂则需要降低车速增加注意力,最后是确保车辆遵守车道以及防止和其他车辆发生碰撞。的受到人开车的认知行为规范的启发,我门设计了分层的Transformer对上游的Encoder的信息进行分层输入接入Diffusion Decoder网络。同样为了进一步使模型获得更好的多样性,我们使用了diffusion,就diffuison policy而言,我们使用了截断扩散策略,其去噪过程不再从标准高斯分布开始,而是从一个锚定高斯分布(anchored Gaussian distribution)开始。为了让模型能够学习如何从锚定高斯分布去噪到目标驾驶策略,我们在训练阶段截断了扩散调度(diffusion schedule),仅向锚点添加少量的高斯噪声。用更“接近真实轨迹”的锚点来替代完全随机的起点,从而降低训练和推理过程中的复杂度,并提升生成的轨迹质量。
Data
π0 采用了pre-training+post fine-tuning的方式,其中pre-training阶段最重要的就是diversity,用了一个10000小时规模的数据集训练,其中数据集大部分是自采的(采集方式下一节介绍),仅9.1% 是开源的(Open-emb-x, droid 等),并且其中普遍都是比较复杂的符合任务,所以实质上包含的任务更多。在post fine-tuning阶段数据的要点是动作质量高,即动作要完成地一致且高效。我们采取了和π0类似的策略,同样进行了pre-training和post fine-tuning部分。其中VLM Encoder模块的pre-training使用了一个大规模自动驾驶预训练数据集driveX,Perception Encoder模块则在nuplan数据集上进行大规模预训练。但是我们发现大规模的高质量数据进行训练并不能教会模型如何克服复杂场景下的行为决策问题,因为即使在navsim数据集下具有挑战性的驾驶场景任然使稀少的。为此在post fine-tuning过程中,我们除了主要对关注对轨迹精度的优化以及困难场景的训练,为此我们从openscene以及nuplan数据集中额外挑选了一部分难例添加到数据集中。
Loss
π0 采用了Score base的生成式模型,其中连续动作预测使用flow matching loss监督。形式上讲,其对数据分布 进行建模其中,,,,,,,对应于未来动作的ation chunk(就是连续的动作块,一个块代表当下的动作。

我们的方案中为了更加直接的生成轨迹使用了diffusion policy 并对轨迹进行L2的监督,其中 表示对轨迹点的reconstruction loss, BCE则是对于轨迹类别的交叉熵损失。

实验结果

可视化

结论和展望
尽管相比于π0,DiffVLA在自动驾驶领域取得了显著进展,以下方向仍需深入探索:
- VLM轻量化与实时部署:当前VLM的计算开销难以满足车载平台严苛的延时与能效约束。未来需探索模型压缩(知识蒸馏、稀疏量化)、硬件感知编译(Transformer算子加速)及车-云协同推理架构,以实现VLM在嵌入式芯片的高效部署。
- LLM驱动的闭环决策范式革新:DiffVLA中VLM仅提供开环语义指令,尚未参与实时控制闭环。亟需研究LLM在决策-规划-控制层级的深度耦合机制
- 安全与评估体系升级:设计动态安全边界(如形式化验证模块过滤风险指令,对抗样本防御机制),构建融合物理约束与语言描述的闭环评测基准,并引入VLM决策合理性量化指标
#Waymo S4-Driver
告别监督,海量无标注数据解锁3D时空推理能力~
虽然端到端自动驾驶,近两年被炒的火热,但是其实探索端到端自动驾驶的历史可以追溯到20世纪80年代。当时的运动规划模型直接根据原始传感器输入预测控制信号,不过由于鲁棒性的问题,早期的一些尝试,在复杂的城市环境难以泛化。最近风靡一时的多模态大语言模型(MLLMs)恰好具有强大的泛化能力,将这两者结合,似乎成了势不可挡的趋势。然而,将MLLMs直接应用于端到端运动规划很难发挥其强大的视觉理解和推理能力,因为运动规划和MLLM预训练任务之间存在显著差异,导致规划性能较差。

为了缩小这一差距,如图1b所示,以往的方法使用多任务学习,将多种感知和预测任务纳入训练和推理中,或者采用监督感知预训练,利用预训练的自动驾驶感知模型作为视觉token。然而,人类标注成为了这两种策略的瓶颈。相比之下,纯自监督方法虽然能够直接从传感器输入学习并利用大量未标注的驾驶数据,但通常表现不如现有的最先进方法。
论文题目: S4-Driver: Scalable Self-Supervised Driving Multimodal Large Language Model with Spatio-Temporal Visual Representation
论文链接:https://arxiv.org/pdf/2505.24139
首先,作者确定了以下两个主要障碍:
- 非最优的表达形式:MLLMs通常为2D图像平面中的任务设计。这种图像空间表示限制了它们从多视图图像组合中进行3D推理的能力。
- 数据规模有限:尽管nuScenes是端到端规划非常广泛的数据集,但它也仅包含不到1k个序列,缺乏驾驶行为的多样性。这种有限的规模导致在微调具有十亿参数规模的MLLMs时出现严重的过拟合问题。
在本文中,作者提出了S4-Driver,这是一个简单而有效的可扩展自监督运动规划方法,具有时空视觉表示。基于通用多模态大语言模型,作者直接从相机图像预测自身车辆的航点,消除了对中间感知和预测任务的需求,从而促进了利用大量未标注驾驶数据进行模型预训练的规模化(图1a)。为了解决非最优的表达形式的障碍,作者提出了一种新颖的稀疏体积表示,能够聚合来自多视图和多帧图像的视觉信息,提升了模型在运动规划上的3D时空推理能力,并无损的保留了MLLMs预训练视觉嵌入中的世界知识。
其次,为了严格评估法并提供足够的训练数据,作者还利用了大规模的WOMD-Planning-ADE benchmark,并结合了内部相机传感器数据。该 benchmark 大约比nuScenes大100倍,因此它可以作为一个更全面的基准。
相关工作
多模态大语言模型 (MLLMs)
多模态大语言模型(MLLMs)同时包含语言和图像模态,以往的研究主要集中在将强大的大型语言模型(LLMs)与先进的图像编码器(例如LLaVA、PaLI、PaliGemma以及InstructBLIP)进行整合。通过指令微调或多模态微调,这些模型在多模态理解和推理方面展现出了不错的性能。当前的发展趋势是利用越来越大的多模态数据集来进一步提升它们在复杂感知和泛化任务中的能力。然而,尽管这些模型具有诸多优势,但它们在3D空间推理方面仍存在局限性,这给它们在自动驾驶领域的应用带来了一些挑战。
端到端自动驾驶
为了减少传统的感知、预测、规划的各模块间的信息丢失和误差累积,端到端驾驶系统利用统一的模型直接从原始传感器输入预测自身车辆未来的航点或控制信号。尽管这些系统优先考虑规划,但它们通常仍会整合感知和预测模块,还是需要对每个模块进行明确的监督。尽管一些早期的工作已经探索了无需任何中间任务的纯运动规划,但由于建模能力有限,它们在复杂的城市场景中表现不佳。
自动驾驶中的 MLLMs
大型模型的卓越推理和泛化能力正是自动驾驶领域应用需要的能力。一些研究将驾驶场景转化为大型语言模型的文本提示,或者直接用视觉语言模型处理相机图像。然而,它们的潜力受到现有benchmark数据量的限制,仅允许进行部分微调。同时,闭环模拟器在为端到端任务提供逼真的传感器数据方面也面临挑战。因此,多任务联合微调或思维链推理(CoT)被广泛采用,来简化推理过程。另一种思路,一些工作整合了预训练的感知模型,以提取鸟瞰图特征,并将其作为视觉token发送给语言模型。最近,EMMA利用强大的Gemini进行自监督运动规划。此外,它们还开发了一组训练任务,包括运动规划、3D目标检测和道路元素识别,以及用于轨迹生成的一些推理过程。相比之下,作者的工作专注于在无需额外人类标签的情况下增强自监督运动规划。
具体工作
Vanilla PaLI as Planner

端到端运动规划模型根据多视图相机图像 和高级行为指令 来确定自身车辆的未来轨迹 。未来轨迹包括自身车辆在鸟瞰图坐标系中每个未来时刻的位置,即 。高级行为指令可以理解为导航系统,对于蔚来轨迹的规划是非常重要的,至少要知道车往哪里开。此外,自身车辆的历史状态 对于获得平滑且可行的规划结果也很重要,其中作者将历史位置、速度和加速度视为 ,即
其中 就是规划模型。作者将自身车辆的历史状态和高级指令作为文本提示提供给模型。位置、速度和加速度直接以两位小数的浮点数表示。预测的未来轨迹随后从模型解码的文本输出中提取。在没有前面的感知和预测任务的情况下,以自监督方式微调的原始 PaLI 在运动规划中的表现还可以,但并不理想(见图 3)。

Hierarchical Planning with Meta-Decision
直接输出未来轨迹而不进行任何推理对于 MLLMs 来说,是一个具有挑战的任务。为了解决这个问题,作者借鉴了链式思考(Chain-of-Thought, CoT) 的灵感,采用了一种从粗到细的思路,采用分层规划方法,从语义决策到数值规划。
作者首先给模型提供一个关于未来加速度状态 的估计的prompt,有效地将运动规划任务分解为两个步骤:
作者定义 包括四个元决策:保持静止、保持速度、加速和减速。与以往在基于 VLM 的规划中需要人类标注进行训练的 CoT 应用不同(例如 DriveVLM 中的场景分析),作者将这些元决策作为“free lunch”引入其中,以简化运动规划过程,而无需任何额外的标注。基于未来自身车辆速度和加速度的启发式规则生成真实决策。图 3 展示了这种简单的设计在规划性能上带来了的较大改进。
Scene Representation in 3D Space
高质量的运动规划需要对周围 3D 场景有一个稳健的理解,包括静态和动态元素。虽然传统上是通过单独的感知和预测模块来实现的,但作者的自监督端到端框架依赖于 MLLM 来隐式地学习这种理解,而无需明确的监督。然而,尽管具有强大的 2D 推理能力,MLLMs 在 3D 空间推理方面存在困难。
3D Visual Representation with Dense Volumes
为了克服上述限制,作者借鉴了以往成功的感知任务的经验,采用3D体积表示。MLLM的视觉编码器提取多视图特征图,其中是视图的数量。作者基于多视图图像特征构建一个以自身车辆为中心的3D特征体积。为了避免引入的模块过于复杂,破坏预训练MLLM并使后续多模态编码器 - 解码器与视觉特征错位,作者采用了一种轻量级的投影方法,类似于SimpleBEV,对于3D体积中的每个体素,作者将它的坐标投影到每个视角视图,得到对应的2D坐标。然后作者在这些投影位置从每个视图中双线性采样局部特征。最后,体素的特征表示计算为所有视图中局部语义特征的平均值,其中体素投影在图像范围内。这个过程有效地整合了3D空间信息,同时保持了与后续多模态编码器 - 解码器的兼容性。
这种简单高效的投影策略确保了3D体积特征与原始多视图特征具有相似的分布。这种相似性有助于无缝整合到MLLM的后续多模态编码器 - 解码器中。如图3所示,这种3D体积表示在运动规划性能上有所提升。另外,作者发现使用全连接层减少轴以获得鸟瞰图表示会略微降低性能,因为这种降维操作可能会给场景表示带来一些歧义。
Sparse Volume Representation
尽管3D体积表示有效地捕捉了空间信息,但周围的3D空间大部分是空的。另外,对于运动规划来说,远离道路的物体(如建筑物和树木)的详细信息并不那么重要。基于此,作者提出了一种稀疏体积表示,以减少体素的数量,在给定的内存限制下实现更高的分辨率,并提高效率。为了确定每个场景中有用的体积及其位置和语义,作者为每个体积坐标定义了一个门控值。为了获得这个门控值,作者从多视图图像特征开始,通过一个全连接(FC)层降低其维度:
然后作者从构建一个降低维度的体积特征。较小的通道数允许更大的体积分辨率,并且足以表明体积是否与运动规划相关。之后,通过一个小型的MLP模块从中得出门控值:
因此,作者可以轻松地选择个体积(),使其门控值最大,坐标为。由于作者无法获得真实占据状态,作者提出隐式地学习门控值。作者假设门控值较小的区域应该是空的或与规划无关。对于这些空白空间,作者分配一个可学习的特征。作者期望模型可以通过在每个3D位置权衡语义特征和这个空白特征来学习门控值,因此作者为选定的稀疏体积获取特征:
其中是具有较大门控值的选定体积。当稀疏体积特征被输入到后续的多模态编码器中时,它们显著提升了规划性能(见图3)。
Local Feature Aggregation in 3D Space
由于缺乏深度信息,上述过程会导致沿每个相机光线的重复体积特征。这种空间歧义可以通过3D局部操作(如卷积或可变形注意力)来缓解,所以,作者通过定制自注意力来注入一些相对位置偏差,如下所示:
给定个稀疏体积,其坐标为,距离矩阵是每对稀疏体积沿轴的距离,即。偏差通过函数计算,其中被划分为多个bins,并通过、、映射到每个bin的可学习偏差值。作者还对具有1维位置的文本标记之间应用了单独的偏差。这种相对位置偏差优雅地将局部归纳偏差插入到预训练的全局自注意力模块中,几乎不需要额外成本。这可以促进3D空间中局部信息的聚合,增强了场景理解和空间推理能力,性能提升的收益可见图3。
Multi-frame Temporal Fusion
多帧输入组合有助于补偿相机图像中缺乏深度信息的问题。作者将稀疏体积表示扩展到聚合多帧时间信息,通过纳入T帧历史图像,时间间隔为0.5秒。给定总共T+1帧的图像,分别对每帧应用上述公式来获得多视图图像特征,其中,。在进行自身运动补偿后,作者基于当前自身车辆坐标和每帧图像特征构建门控特征体积。将多帧体积特征沿通道维度拼接以生成门控值。
作者根据门控值选择M个体积。分别从每帧图像特征图中获取体积特征,,然后通过全连接层将它们融合为具有时间感知能力的稀疏体积特征。
如图3所示,时间融合通过促进对环境的理解,有助于提升运动规划性能。
Voting for Planning via Multi-Decoding
MLLMs倾向于为运动规划中的比较简单的行为分配高置信度,比如直接保持静止。为了缓解这种偏差,作者聚合多个输出,并通过投票获得最终的规划输出。作者采用核采样(nucleus sampling)来为自身车辆生成K条未来轨迹,记为。它们通过简单平均来产生唯一的规划结果,如下所示:
这种无权重平均方法减轻了MLLM对简单行为的偏好。如图3所示,这种简单的多解码聚合方法也带来了显著的性能提升。
Scaling to Large-scale Raw Driving Logs
自监督训练使得作者提出的S4-Driver能够扩展到大规模驾驶logs,无需人工标注。为了发挥基于MLLM的规划器的潜力,作者在内部数据集上对模型进行预训练。图3中的结果表明,由于大规模预训练,S4-Driver在具有挑战性的尾部行为上取得了显著的性能提升。
Waymo Open Motion Dataset for Planning
为了大规模训练和评估具有大型模型的规划算法,作者基于WOMD数据集设计了一个WOMD-Planning-ADE基准。

该数据集包含10.3万个真实世界的驾驶场景,涵盖了多样化城市和郊区场景。这些场景进一步被划分为9秒样本,包含1秒历史和8秒未来。为了端到端规划评估,除了每个样本中自身车辆的轨迹作为真值外,该数据集中还有以下关键项目:
- 相机数据:大多数端到端规划方法依赖于相机图像作为模型输入。在作者的数据集中,每个帧包含由八个多视图相机捕获的图像。
- 高级行为指令:像导航系统一样,端到端规划系统也需要导航信号来指示行驶方向。作者考虑了六个高级行为指令(见图4),即直行、左转、右转、左转调头等。这些指令可以覆盖现实世界中的多样化驾驶情况,例如“直行右转”描述了驶离高速公路的情况。作者根据长期未来轨迹来决定行为指令,而不是仅仅考虑最后一步的位置,这样可以处理低速或停车的情况。
- 评估指标:驾驶场景中数据分布的不平衡是不可避免的。例如,在WOMD-Planning-ADE基准测试中,直行和停车占所有样本的70%以上,如图5所示。在这种情况下,作者认为当前广泛使用的样本平均位移误差和碰撞率无法全面反映运动规划算法的性能,因为具有挑战性但频率较低的行为(如转弯)被简单的直行移动场景所淹没。因此,作者提出了类似预测中的mAP指标的行为指标。例如,作者将行为平均位移误差表示为bADE,定义如下:
其中是特定行为的ADE指标。具体来说,种行为被考虑在内——包括六个高级指令(见图4)和一个额外的停车行为。

实验及结论实验细节模型和微调:作者的模型基于预训练的 PaLI3-5B 模型构建,该模型包括一个 ViT-G(2B)视觉编码器和一个 3B 的多模态编码器 - 解码器。作者冻结了 ViT 编码器,仅对插入的模块和多模态编码器 - 解码器进行微调。
数据集:作者在 nuScenes 和 上述 WOMD-Planning-ADE 基准测试上评估 S4-Driver。
主要结果及对比
nuScenes 数据集:表 2 显示,S4-Driver 显著优于所有先前的算法。与现有方法不同,S4-Driver 不需要任何感知预训练或人类标注。这种自监督特性使得 S4-Driver 能够利用所有可获取的原始轨迹数据。

WOMD-Planning-ADE 基准测试:在表 3 中,作者主要将 S4-Driver 与原始 PaLI3-5B 基线和模块化算法 MotionLM 进行了比较。与原始 PaLI3-5B 相比,样本指标和行为指标之间存在显著差距。为了对比,作者还将最新运动预测算法 MotionLM(内部增强的复现版本)适应于规划任务,仅预测自身车辆的未来轨迹,并将高级指令注入模型中。因为它使用了高质量的对象、轨迹和道路图信号作为模型输入,所以直接与作者的端到端方法进行比较并不公平。然而,如表 3 所示,即使 S4-Driver 仅使用原始相机图像作为输入,与 MotionLM 相比,S4-Driver 仍然取得了有利的性能,尤其是在行为指标方面。

一些分析
定性结果:图 6 可视化了在多样化场景中的规划结果。作者提出的 S4-Driver 能够根据交通灯和道路车道确定未来自身行为,可以应对不同的光照条件。

元决策可靠性:图 7 展示了在 WOMDPlanning-ADE 验证集上元决策预测的准确性。在所有行为中,模型提供了可靠的元决策估计。在没有任何人类标注的情况下,这一初步预测可以简化数值运动规划的推导。

稀疏体积分布:作者在图 8 中可视化了沿 x 轴和 y 轴的自监督学习稀疏体积的分布。从后到前,稀疏体积集中在前面区域。从左到右,稀疏体积覆盖了所有区域,因为存在转弯场景,但大多数体积集中在中间区域。这些分布与人类驾驶经验一致。
消融实验
MLLM 输入:在表 5 中,作者分别对比分析了相机图像和历史自身状态的作用。作者假设 WOMD-Planning-ADE 涵盖了更多多样化的驾驶场景,包括许多比较大的速度和方向变化,这使得传感器数据变得重要。这也展示了 WOMDPlanning-ADE 在全面评估方面的优势。表 5 还显示,如果没有 MLLM 预训练,随机初始化的模型无法收敛。说明:尽管领域不同,S4Driver 仍可从大规模 MLLM 在一般任务上的预训练中受益。

MLLM 能力:除了在其他部分中使用的 PaLI3-5B 外,作者还针对运动规划使用了 PaLI2-3B。如表 4 所示,基于 PaLI2-3B 的 S4Driver 表现明显不如基于 PaLI3-5B 的 S4Driver。作者在 WOMD-Planning-ADE 上进行了两个不同规模的训练数据实验,即 20k(nuScenes 规模)对比 400k(完整 WOMD-Planning-ADE)。在有足够的训练数据时,差距尤为明显。这也证明了在大规模数据集上进行实验的必要性,这可以充分发挥强大 MLLMs 的潜力。
稀疏体积分辨率:表 6 显示了具有相同数量的稀疏体积(M = 6000)的不同稀疏体积分辨率的结果。与图 3 一致,低分辨率导致相对较差的性能,因为它限制了 3D 空间推理的精度。有趣的是,沿 z 轴的更高分辨率并不一定能提高模型性能,因为运动规划主要在 xy 平面上工作,而太低的稀疏比率往往会使优化不稳定。
结论和展望
本文介绍了 S4-Driver,这是一个利用多模态大语言模型(MLLMs)用于自动驾驶的可扩展自监督运动规划框架。为了增强 MLLMs 中的 3D 推理能力,作者提出了一种新颖的稀疏体积表示,通过聚合多视图和多帧图像输入,实现了有帮助的时空推理。此外,作者还为大规模 WOMD-Planning-ADE 基准设计了行为指标,用于做全面评估。S4-Driver 不需要任何人为标注的情况下,在 nuScenes 和 WOMD-Planning-ADE 基准测试中均取得了最先进的性能。这证明了自监督学习在端到端自动驾驶中的潜力。
未来的工作将持续探索应用其他强大的 MLLM 架构。将作者的大规模自监督学习方法与针对小规模标记数据的监督微调相结合,可能会进一步提升系统的性能和可解释性。
#Plan-R1
将安全且可行的轨迹规划作为语言建模
- 论文链接:https://arxiv.org/pdf/2505.17659
摘要
本文介绍了Plan-R1:将安全且可行的轨迹规划作为语言建模。安全且可行的轨迹规划对于现实世界自动驾驶系统是至关重要的。然而,现有的基于学习的规划方法往往依赖于专家演示,这不仅缺乏显式的安全感知,还有可能从次优的人类驾驶数据中继承不安全的行为,例如超速。受到大型语言模型成功的启发,本文提出了Plan-R1,这是一种新的两阶段轨迹规划框架,它将轨迹规划作为顺序预测任务,并且由显式的规划原则(例如,安全性、舒适度和交通规则合规性)来引导。在第一阶段中,本文通过专家数据的下一个运动token预测来训练自回归轨迹预测器。在第二阶段中,本文设计了基于规则的奖励(例如,避障、速度限制),并且使用一种强化学习策略组相对策略优化(GRPO)来微调模型,使其预测结果与这些规划原则保持一致。在nuPlan基准上的实验表明,本文所提出的Plan-R1显著提高了规划的安全性和可行性,从而实现了最先进的性能。
主要贡献
本文的主要贡献总结如下:
1)本文提出了一种新的视角,将轨迹规划问题转化为原则对齐的序列预测任务,实现了行为学习和规划原则对齐的解耦;
2)本文引入了Plan-R1,这是一种两阶段轨迹规划框架,它将自回归预训练与强化学习微调相结合,以符合规划原则;
3)本文设计了一组可解释的、基于规则的奖励函数来捕获基本的规划原则(而没有依赖偏好数据进行微调),包括但不限于可行驶区域合规性、避障、速度限制合规性和驾驶舒适性;
4)本文所提出的Plan-R1显著提高了规划轨迹的安全性和可行性,在nuPlan基准上实现了SOTA性能,特别是在反应式闭环仿真环境中优于现有的规划器。
论文图片和表格
总结
本项工作引入了Plan-R1,这是一种用于安全且可行轨迹规划的新型两阶段框架。受到LLMs成功应用的启发,本文将轨迹规划问题重新表述为原则对齐的顺序生成任务,将行为学习与规划原则对齐解耦。具体而言,本文首先预训练一个自回归模型来捕获专家演示的多模态分布,然后通过由可解释的、基于规则的奖励引导的强化学习来微调自车策略。在nuPlan基准上的实验表明,Plan-R1实现了SOTA性能,特别是在反应式仿真中。本文实验结果突出了通过强化学习使规划轨迹与安全且可行的目标保持一致的有效性。
#Navigation is nearly done?
导航 vs. 空间智能两面观
Navigation is nearly done?空间智能是 AI 发展北极星?——我们到底应该怎么看待当前 AI 模型在空间理解、推理、想象、执行方面的进展和预期。
VLA 是否是xx大模型终极形态?——大语言模型到底在机器人任务中带来了什么,而又解决不了什么。
本文对上述问题,就导航这一机器人领域核心下游任务做各维度两面观的简要分析。
“两面观”的立意也是希望在这个充满希望又有些浮躁的 AI 快速发展时代,提醒自己多换个角度看看,例如 scaling 很重要,但相信 scaling 远不是一切。
结构化固定场景中建图-目标定位-路径规划接近解决了,导航找到某个类别等基础目标指令的问题接近解决了。
动态场景、根据复杂指令导航、陌生环境导航远未被解决,大模型空间智能的各方面能力仍有巨大空间。
大模型为复杂指令理解和感知的 Sim2Real 带来了重要基础,但解决不了复杂任务如操作的底层技能控制问题。
基于上述观察,我们基于纯仿真场景合成一批高质量数据,训练了一个可在楼层/建筑范围、实现超长程指令跟随、零样本泛化的双系统导航大模型。High-level 规划上:让大模型在理解复杂指令的同时,以同构的流式推理范式灵活处理上下文并学会如何执行;Low-level 执行上:让策略网络在仿真中同时学习轨迹生成和轨迹评估,可以在动态杂乱场景中无需建图,即可避障到达目标点。更重要的是,这样一套架构和训练范式使得跨本体(人形、轮式、四足)、零样本(拿到任意场景开箱即用)泛化变为可能。
附相关工作传送门,欢迎 star 和提出宝贵意见:
论文:StreamVLN: Streaming Vision-and-Language Navigation via SlowFast Context Modeling (Coming Soon)
项目:https://streamvln.github.io/
ps: 代码随后连同双系统进展一同 release。
纯仿真数据训练 StreamVLN 在实验室环境等各种真实环境中直接部署效果(无微调、全自主)
论文:https://arxiv.org/abs/2505.08712
项目:https://wzcai99.github.io/navigation-diffusion-policy.github.io/
代码:https://github.com/wzcai99/NavDP9
纯仿真数据训练 NavDP 在实验室环境等各种真实环境中直接部署效果(无微调、全自主)
预期两面观:聊聊各种“饼”和“暴论”
作为一个从之前做计算机视觉(当时研究自动驾驶中三维感知问题)转到当前xx智能领域的研究人员,深知一些基础的三维感知范式已经被充分探究:不管是基于 LiDAR 点云的检测分割框架,还是基于 BEV 的纯视觉感知规划一体化架构,都在自动驾驶这样一个充满数据、快速迭代的领域内快速演进收敛。转向室内和通用场景后,最直观感受就是这领域缺高质量数据、缺基础模型、缺好的基准,于是开始了重要但又枯燥的基建期,有了 EmbodiedScan/MMScan 的初始数据、PointLLM/LLaVA-3D 的初始模型、最近做的一些比如 MMSI-Bench 等空间推理基准。在这种大背景下,有时自己也会产生片刻的疑问,难道这领域就只剩下 scaling 需要做了吗?此时,看着大模型们在 MMSI-Bench 等 benchmark 上和人类远远的距离,看着机器人简单一条指令都找不到北,又坚定:应该不是搞搞数据就能解决的事。
图1:MMSI-Bench leaderboard
坦率地讲,“Navigation is nearly done”和“空间智能的重要和挑战性”就代表着这样一类问题的两面性。一方面,在固定环境中,传统的建图-定位-规划方案十分成熟;简单找某类物体的指令通过一些 learning-based 的方法也可以表现得很好;看起来这个领域真的只剩工程和落地了,至少只剩下 scaling 数据了。另一方面,大模型在空间理解推理方面似乎显得一窍不通,三维大模型领域刷点刷的飞起,但没有一个真正落地和使用的。问题到底出在哪?
Navigation is nearly done?
很早开始做导航的时候就在内部或外部被很多朋友问到 Jitendra Malik 的此番言论,大家笑称需要准备一份详尽的 rebuttal :) 为此,我专门找了下这段话出处,详细了解了此番“暴论”的上下文。
图2:Jitendra Malik “暴论”现场
简单来说,Jitendra 作为一个也算是视觉跨界过来的学者,在5年左右探索这个领域的时间里,在三大核心任务上有诸多的尝试探索:Locomotion,Navigation,Manipulation。在展示了四足/人形泛化行走、任意目标导航(GOAT: GO to Any Thing)和灵巧手操作三个 demo 后,Jitendra 本人和听众一致认为最接近解决的是导航任务。
图3:GOAT Demo gif
在此放上 GOAT 的展示 demo,结合它能够实现的效果以及这样的上下文背景下,毫无疑问,我也完全认同导航是最接近解决的那一个。就像 Jitendra 自己说的,导航这个机器人任务在某种程度上是最像计算机视觉的,毕竟我们在自动驾驶里也早已遇见了 planning 这个问题(那个背景下大家常提 perception, prediction, planning)。而相比自动驾驶,显然核心区别就像 EmbodiedScan 当时分析的,语义更丰富、在密闭空间可能建图和感知结合更为重要,因此问题变为——这个复杂语义理解和感知的问题解决了吗?
像上面 GOAT demo 展示的,通过一个系统的解决方案其实面向简单语义的导航问题已经被解得比较好了,比如找一类物体,甚至是给语言、图像等各种模态的目标,它都可以比较好完成;同样,假设我们有一个十分准确的语义地图,路径规划和走过去简直是太“小儿科”的事情(虽然这里面也还有一些定位的工程优化问题)。从这个视角看,显然 Navigation is nearly done,剩下的就是上述复杂语义理解和感知的问题。
PS:同样的问题在操作则非常不同。操作里的执行涉及不同的夹爪和构型,需要执行的行为也涉及不同的力控和运动轨迹,而当前比较多 benchmark 关注的都是桌面上的操作问题,因此涉及到的感知问题甚至相对较少,甚至有时可以说相对容易。虽然这里面涉及的精细感知、推理、工具使用也还有巨大空间,但显然和导航是完全不同的情况。而这些问题的解决显然需要依赖大量的机器人数据,当前这部分数据的严重匮乏也就引发了上述“Manipulation has a long way to go”的观点。
空间智能(Spatial Intelligence)很难实现么?还有多远?
在解耦了导航这个任务之后,我们发现问题最终转移到了复杂语义理解和感知,如果还有别的问题那也是这部分和下游行为的映射/对齐如何实现。于是自然而然到了第二个问题,现在的大模型是否具备比较好的语义理解和感知能力了呢?显然,二维不是太大的问题。因此,给定一个基于视频就能执行的指令,导航大模型通常能做的还不错,后面我们会介绍这方面一个初步尝试;然而,大模型的原生空间理解能力仍然十分缺乏,通过下述简单的例子就能测试出来:
Q: When I took the second image, where was the black door in relation to me?
Options:
A: Behind me, B: On my left, C: In front of me, D: On my right
测试效果:
A: To determine the position of the black door in relation to you when you took the second image, let us analyze the images step by step:
1. First Image Analysis:
- The black door is visible on the left side of the image.
- The staircase is on the right side of the image.
- The framed artwork is on the right wall.
2. Second Image Analysis:
- The living room and kitchen area are visible.
- The staircase is not visible in this image.
- The framed artwork is still visible on the left wall.
Given that the staircase is not visible in the second image and the framed artwork is on the left wall, it suggests that you have moved further into the living room area.
The black door, which was on the left side in the first image, would now be behind you as you face the kitchen area. (错误的推理)
Therefore, the black door is: A: Behind me图4:MMSI-Bench 中目前大模型难以处理的例子
这其中涉及很多方面的问题,包括我们前期做的各种数据、模型的基础尝试,以及远没有解决的:3D 模态如何加入和对齐,如何在有限的数据下训练模型的空间理解和推理能力,这其中是否需要把理解和想象的训练加进来,以及如何将这些能力最终应用到导航这种下游任务上。好的一点是目前我们看到社区已经都开始关注这方面,但同时也可以看到各种现有方案都有数据、对齐、训练等各种方面的问题,这个方向仍然有不小的研究空间。从这个角度讲,广义导航这个任务还远没有达到接近解决的状态。
VLA 是否是终极方案?
最后简单提一下这个可能已经被业内外各种人士讨论过的问题。虽然 VLA 的定义当今也已经被不可避免地扩大,假设用一个我个人认为相对宽松的定义方式,即 VLA 是指基于多模态大模型微调实现行为输出(无需强求 VLA 三种模态的对齐),我认为在短期内还是必需的。就像上述说的,它是目前解决xx任务中涉及复杂语义理解和识别的最佳方法和不二选择,同时可以使得xx大模型的“Sim2Real”更容易实现(基于大模型通用泛化先验+仿真合成的机器人数据实现 Sim2Real)。但同时,它解决不了一些复杂的底层控制问题,那些问题的解决需要新的数据、新的网络、新的训练方式,并最终和多模态大模型实现良好融合,才能到达我们最终的目的地。
方法两面观:导航的 High-level 和 Low-level
谈了很多观点,再简单介绍下我们基于上述认知最近做的一些尝试。从最早大家提“大小脑”,以及上面关于高层理解规划和底层控制之间的分析,众所周知现在很多机构都会推进双系统的实现方案。同样,我们也基于这套思路从去年开始推进两方面的研究,这篇文章先简单介绍两部分各自的阶段性进展,不久的未来再系统性介绍整体的情况。
High-level: LLM 先验+纯仿真数据实现流式 VLA Sim2Real
在开始做导航大模型之前,也关注到了领域内一些大面上的进展和问题,例如:VLN 和 Object Goal 早些就有了 Habitat 那些 benchmark,但一直都在仿真里玩,没人做到真机,刷点也略显随机,都是各种隐藏 trick 的堆叠;后来有了大模型后这两年有了一些初步泛化到真实场景的不错的进展,比如 NaVid 和 NaVILA 等,但总感觉实现得像一个“A”而不是“VLA”。
细品后发觉这个也和多模态大模型早期的进展有关,早些时候多模态大模型特别是视频大模型的工作很多也是先解决单轮图文交互,直到近一年才出现一些研究在线多轮交互的工作去处理长视频理解和长时记忆。类似的,大家在刚开始用多模态 encoder 解决导航问题时还是每步收集前面所有 video 重新提特征、单步推理,因此基于不同的视频帧采样也自然而然丢失了很多信息;同样的问题在 EmbodiedScan/LLaVA-3D 的实现中也同样存在;而操作的 VLA 里面甚至是基于单帧图像和指令在进行推理。
于是很自然想尝试下做个优雅同构的流式 VLA。虽然当前大模型的长上下文已经卷出了新高度,但不可避免长程导航任务里视频的输入还是带来了很多信息冗余,并且持续加长的视觉输入如果不做任何压缩也难以处理。因此我们设计了 SlowFast Context Modeling,即 Long-term Memory 会有时空两维度 token pruning,而近距离的 tokens 则自然作为 Short-term Context 用于推理,所有历史 tokens 通过 KV-Cache 可以高效复用,由此实现了 VLA 的流式版本。优雅的好处也是非常自然,再也不用切分各种导航片段训练了,直接一个长程 VLA 序列喂进去,模型既能处理够长序列,又能在线推理,还有一定长时记忆。
图5:StreamVLN 的双轨上下文流处理设计
稍微提下其中的时空 token pruning。除了常用的时间维度上采样之外,我们也曾想过把 3D 表征更好加进来。但就像之前提及,加进来 3D 表征并实现很好对齐并不是一件容易的事:加多了设计会难以对齐,加少了又没什么太大用。加上当前 VLN 的这些指令大多都是基于视频理解就能较好解决的问题,我们先基于空间做了进一步的 pruning 初步提升了 Long-term Memory 中 token 的有效性,而至于剩下的,则需要更复杂空间推理的导航问题定义和基础模型的范式突破。
图6:StreamVLN 的时空剪枝设计
训练方面也相对简单,我们收集了导航常用的一些演示数据、结合 DAgger 增强的数据和部分多模态图文数据,在一个相对合适的配比下完成了纯合成导航数据+多模态数据的混合训练。得益于多模态大模型基础具备的开放世界感知和复杂指令理解能力,这个只用合成导航数据训练的大模型也具备良好的真实世界泛化能力,详见实验结果。
图7:StreamVLN 的数据配方
由此我们初步得到了一个具备不错泛化性的流式导航 VLA 模型。但同时需要关注到,这样一个模型的训练虽然简单,但在动作空间仍然延续之前工作采用了离散的动作空间(类似直行、向左前/右前之类的选项)且只是局部的动作输出,本质上虽然能理解复杂语义,但输出并非一个 long-horizon 的推理/规划目标,而后者是通常大家理解双系统中 System2 应当给予 System1 的输入。这部分如何实现就是另外一个故事了,且留一个悬念做下回分解。
Low-level: Sim2Real 学习轨迹生成/选择实现无需建图动态避障
下面再简单介绍下早些就 release 的 low-level 这边的一些进展。其实在 VLN 和近期大模型这些工作出来之前,原本面向狭义的导航任务,社区中有相当一部分人比较关注近距离导航的一些问题,涉及的目标模态也有二维/三维点、图像、语言等,基于 learning 端到端训练的也有 ViPlanner、NoMad 这些优秀的工作,整体这部分研究其实也和自动驾驶所谓 FSD 重点关注的事情更加接近。
结合上面的大背景,当我们有了 High-level 负责复杂语义理解和规划的大模型后,low-level 部分其实主要也就是做两件事:(1) 执行输入的规划、到达目标点;(2) 动态避障。而这两者又和典型的控制问题有种类似的感觉,前者涉及到定位等自身状态认知,后者则涉及更多环境几何估计和路径规划。在静态环境中,这个问题其实并不困难,通过简单的建图+路径规划就能实现,在我们后续的实验比较中也发现其实传统方法在陌生的静态环境中也有很好的性能。然而面向动态场景,SLAM 常常会出现问题从而影响上述方法的适用性。
于是借鉴 locomotion 中 Sim2Real 的成功经验,我们也在仿真环境中构造了一批数据尝试解决这一问题。简化模型和假设的同时,发现由此带来了相比传统方法在实时性以及涌现出的动态避障方面的一些能力,并且初步实现了跨本体、跨场景的部署,相信很快也能作为机器人可以打包出厂的一部分能力。
具体来讲,相比真机数据,在仿真环境中合成数据可以天然拿到全局地图和几何信息,由此我们可以 (1) 通过传统运控方法生成一批平滑且安全的轨迹,用于训练模型生成轨迹的能力;(2) 基于全局地图(具体采用 ESDF 表示)和机器人位置给出不同轨迹的安全性指标,用于训练模型选择最优轨迹的能力。由此,我们可以让机器人在仿真环境中基于局部、有限的第一视角和历史观察,学习到视野外具备一定全局观的轨迹规划能力,从而用最少的观察(无需很多相机)和模块(无需建图定位)实现鲁棒的真机部署效果。
图8:NavDP 主体思想示意图
想法很简单,模型实现也比较简单:用一个 transformer 堆叠的 diffusion policy 只要 100M 的参数就能训出想要的这两方面能力。同时伴随数据特别是场景上的 scale up,现在这个模型也在逐渐变好;相应利用仿真环境构造的测试环境也大大节省了真机评测的负担,提升了整体迭代效率。之前推文提到过的 15k 条轨迹数据/台天的生成效率也真正让这个任务的数据不再是瓶颈问题,这些进展也更进一步强化了我们对于 Sim2Real 的信心。
基准和实验结果
最后象征性放一些为了论文完整性的数值结果,细节的消融实验等可以移步论文具体了解。
常规性量化基准测试
首先是常规性的一些量化基准测试,这往往是之前计算机视觉工作的重头戏,不过鉴于当前xx基准能评测出的东西有限在这里相对弱化介绍一下,最后再针对这个领域实验和评测的问题做些简单讨论。
图9:StreamVLN 在 VLN-CE R2R 和 RxR 上测试结果
StreamVLN 主要在 VLN-CE 的 R2R 和 RxR 评测上做了些比较,受益于高效的训练和推理架构,整体大概 1500 GPU hours 实现了一版目前评测上领先的水平。这部分整体迭代下来的核心感受还是数据和细节比较重要,后面总结时会再详细提及一下。
图10:NavDP 在 NoGoal 和 PointGoal 上测试结果
NavDP 则是在自己搭建的仿真环境中先做了不同本体的测试。无论在 NoGoal 纯避障情况下还是 PointGoal 设置下,NavDP 都还是展现出了比较明显领先的效果。值得一提的是,传统方法比较中我们也尝试实现了一版高飞老师经典的 EgoPlanner,可以看出 NavDP 除了一些固有可以实时处理动态避障情况的优势外,在仿真静态环境中的评测也体现出了一定优势。另外,Real2Sim 场景测试是对应到实验室六楼环境下的结果,这部分是比较有意思的初步尝试,最早想的是用 GS 做重建是否能实现一个和真机测试更加对齐的评测结果。不过目前迭代下来感觉还是仿真测试场景的多样性比较重要,也请大家继续关注后续我们的相关进展。
开放场景测试:“是骡子是马,拉出来溜溜”
Jitendra 在报告中还提到一个观点我记得比较有意思。他提到刚进入这个领域的时候曾经试图猛烈构建 benchmark,想让这个领域像计算机视觉一样可以快速迭代。后来发现一方面这个事情很难,另一方面其实只要对自己的实验结果“be honest”,很多进展也可以推动。因此我们也对这两个算法做了比较多的真机测试,其中优化了很多部署和工程细节,但整体确实感受到这些模型泛化的还不错,也有一定领先性,后面也会提到诚邀产学界的合作伙伴们一同测试使用,我们相信有更多的反馈才能更好地推动这个领域的发展。 首先,StreamVLN 的主要特点其实是会发现它的长程指令跟随能力比较出众,特别是中间有一些参照物能够给足指示的情况下,比如下面这个例子做了一个比较有趣的测试游戏(之所以叫游戏是因为显然大家不太会这么给指令,但确实体现了它在很大空间范围内的长程指令跟随能力):
图11: 楼层范围超长指令跟随能力测试游戏
另外一些常规指令的测试我们也拉它到商场里、草地上、室外公园、石子地等各种场景测试了一番,也都体现了比较好的泛化性,这还要得益于多模态大模型比较强的感知理解基底,不然纯靠仿真是远远不能实现这些能力的。这有点类似于 RL 在有了预训练之后逐渐就 work 了,Sim2Real 可能也是如此。
图12:StreamVLN 优秀的零样本场景泛化能力
最后我们也测试了其视觉推理能力和问答能力,也都有较好的先验保留。总体上述 demo 的拍摄都还比较顺利,根据拍摄同学们的反馈目前这些类似的例子都还是能实现零样本泛化有 50% 左右成功率,这也和仿真里目前的测试成功率相对比较接近,某种程度上确实可以说是实现了 Sim2Real。 NavDP 则专注测试其在密集障碍物、动态避障方面的能力极限,像下面两个例子能比较好展示这方面能力:
图13:NavDP 密集障碍物和动态避障能力
另外就是其真正通过一个策略网络一套参数实现了跨本体能力(“一脑多形”),以及自主探索/长时导航能力:
图14:NavDP 跨本体部署 & 自主探索/长时导航能力
这部分在测试时我们也发现再往后推进可能重点在于如何实现更敏捷地避障和更精准的目标导航。当前测试比较困难的一个例子是在密集木桩环境中,整体能实现以 1m/s 80% 左右成功率,虽然能够满足大部分日常需求,但也仍有改进空间。
落地/致谢两面观:研究 & 工程
这半年多首次探索算法上真机的过程中深刻体会到了工程的力量。能够实现上述模型效果离不开组里同学们每个人的不同贡献:从数据生成就开始充满着工程优化问题,例如如何利用传统规控和优化方法让生成的轨迹不贴墙且平滑;到模型训练,如何配比数据和调参;再到工程部署,如何打通云上/端侧推理最终实现真机部署测试,如何做模型加速优化,甚至细到换一个 realsense 通过让视觉模糊少一点从而提升真机部署效果。总之相信未来大模型和xx的成功都离不开这种系统级实现能力,也欢迎希望研究成果落地的研究员/博士生和希望接触最前沿算法的工程师加入实验室,共同搞一些大新闻~
#数据闭环的核心
静态元素自动标注方案分享4D标注之静态元素自轻图方案成为业内共识以来,业内很多公司都在铺开人力推进轻图算法量产。从整个算法落地的流程上看,首先需要依赖一定的标注数据训练模型,推进云端模型训练进而生产自动化轻图数据,进而在反哺车端模型更新,通过迭代的方式泛化车端模型。车端模型一般是时序6v输入的,只能感知局部区域,而云端模型需要做全场景的静态元素标注。
首先我们先回答一个问题:传统2D图像静态元素标注有什么缺陷?
以往2D空间标注,需要每个时间戳下都需要再图像上进行标注,模型做语义分割+深度预测。这样非常耗时费力,需要大量的重复工作。实际上我们只需要重建出3D静态场景,在重建3D场景中静态元素只需标注一次。
基于此,业内开始重视基于重建图或者说3D场景的静态元素标注。
现有的方法,会先将3D场景转换为BEV视图,这样不会损失路面上的静态元素信息,但是整个BEV视图非常大,不适合模型直接训练使用。因此实际中会根据自车位姿滑动窗口截取局部地面重建图,再去训练云端的自动标注大模型,这是和车端模型最大的区别。总结来说,云端的pipeline主要有以下几个步骤:
- 输入3D重建结果
- 裁剪+转换为bev图
- 根据自车位姿滑动窗口截取局部地面重建图
- 利用maptr模型输出矢量车道线
- 局部矢量地图拼接refine
自动标注难在哪里?
自动驾驶数据闭环中的4D自动标注(即3D空间+时间维度的动态标注)难点主要体现在以下几个方面:
- 时空一致性要求极高:需在连续帧中精准追踪动态目标(如车辆、行人)的运动轨迹,确保跨帧标注的连贯性,而复杂场景下的遮挡、形变或交互行为易导致标注断裂;
- 多模态数据融合复杂:需同步融合激光雷达、相机、雷达等多源传感器的时空数据,解决坐标对齐、语义统一和时延补偿问题;
- 动态场景泛化难度大:交通参与者的行为不确定性(如突然变道、急刹)及环境干扰(光照变化、恶劣天气)显著增加标注模型的适应性挑战;
- 标注效率与成本矛盾:高精度4D自动标注依赖人工校验,但海量数据导致标注周期长、成本高,而自动化算法面对复杂场景仍然精度不足;
- 量产场景泛化要求高:自动驾驶量产算法功能验证可行后,下一步就需要推进场景泛化,不同城市、道路、天气、交通状况的数据如何挖掘,又如何保证标注算法的性能,仍然是当前业内量产的痛点;
#PM-Loss
即插即用!PM-Loss显著改善前馈3DGS质量~
全新训练损失
新视角合成(Novel View Synthesis, NVS)是计算机视觉和图形学中长期研究的课题,近年来随着神经渲染技术的进步,尤其是3D高斯泼溅(3D Gaussian Splatting, 3DGS)的发展,这一领域受到越来越多的关注。虽然NVS模型的输入和输出都是2D图像,但其核心目标是恢复场景的3D结构。因此,平滑且精确的几何表示对于生成高质量的新视角至关重要,这也促使了一系列研究致力于通过学习更准确、更一致的几何表示来提升视觉质量。
尽管3DGS模型具有超快的渲染速度,但为未见过的场景重建它们需要耗时的逐场景优化过程,这限制了其在实际应用中的可用性。这一挑战推动了前馈式3DGS方法的发展,这也是我们工作的主要关注点。与通过优化几何来提升视觉质量的逐场景调优方法不同,前馈式3DGS模型通常在几何质量上有所不足,尽管在提升外观表现方面取得了显著进展。核心问题在于前馈方法所使用的表示方式——它们依赖于深度图。大多数前馈模型预测深度图,然后将其反投影以形成3D高斯分布。由于深度图在物体边界附近往往存在不连续性,直接反投影会将这些伪影传递到3D表示中,导致几何质量下降。
近年来,3D重建领域出现了一种新的研究方向,采用称为“点图”(pointmap)的表示方法。与深度图在相机空间中表示标量值不同,点图在世界空间中编码一组3D点,能够更平滑、更准确地建模几何。此外,点图通过神经网络直接回归的方式简化了传统的多视角立体(Multi-View Stereo, MVS)流程。这些优势使得点图方法在3D重建任务中取得了显著成功。
点图在基于回归的3D重建中的成功启发我们将其作为强先验,以减少基于深度图的前馈式3DGS中的伪影。然而,这一思路并非直接可行,因为点图隐式编码了粗略的相机位姿,而前馈式3DGS在显式提供精确位姿时表现最佳,这使得有效利用几何先验变得具有挑战性。现有的在无位姿设定下采用点图先验的方法要么依赖于特定数据集(如ScanNet),要么需要耗时的测试时位姿对齐,这都限制了实际应用。虽然可以通过嵌入相机位姿来调整点图模型,但这种方法需要昂贵的重新训练,且无法提升场景细节的质量。
本文介绍一种新方法,通过将点图先验转化为简单而有效的训练损失,将其几何知识迁移到前馈式3DGS中。与先前方法不同,我们的PM-Loss[1]是即插即用的,完全避免了位姿问题。具体而言,PM-Loss利用大规模3D重建模型(如Fast3R、VGGT)预测的全局点图作为伪真值,指导从预测深度反投影的点云学习。这种监督要求源点和目标点处于同一空间,并且能够高效计算。对于前者,我们发现Umeyama算法可以利用深度图与点图之间的一一对应关系高效对齐两个点云;对于后者,我们使用Chamfer损失直接在3D空间中进行正则化,相比2D空间的正则化能显著提升几何质量。通过从预训练的3D重建模型中提取点图所嵌入的几何先验,我们的方法能够缓解由反投影深度引起的不连续性,并显著提升前馈式3DGS模型的3D点云质量和渲染新视角的效果。
为了验证PM-Loss的有效性,我们在两个代表性前馈式3DGS模型(MVSplat和DepthSplat)和两个大规模数据集(RealEstate10K和DL3DV-10K)上进行了实验。结果表明,PM-Loss在所有评估指标上均提升了3D高斯分布和渲染新视角的质量。广泛的消融实验和分析进一步验证了我们的架构设计选择,以及PM-Loss在内存和运行效率上的优势。由于其即插即用、高效且有效的特性,我们相信PM-Loss将在未来前馈式3DGS的训练中发挥重要作用。
项目链接:https://aim-uofa.github.io/PMLoss/
主要贡献包括以下三点:
- 我们揭示了一个未被充分探讨但关键的问题,即深度不连续性导致前馈式3DGS模型预测的3D高斯分布质量较低。
- 我们提出了一种新的训练损失PM-Loss,通过利用预训练3D重建模型生成的点图几何先验来提升3D高斯分布的质量。
- 在现有前馈式3DGS模型和两个大规模数据集上的广泛实验证明了PM-Loss在提升3D高斯分布和渲染新视角质量方面的有效性。
具体方法
我们的目标是训练一个神经网络,使其能够直接从一张或多张输入图像预测出3D高斯泼溅(3DGS)模型,用于新视角合成,从而避免逐场景优化的需求。为了提升预测的3D高斯分布的质量,我们提出了一种新颖的点图损失(PointMap Loss, PM-Loss),用于对预测的3D结构进行正则化。PM-Loss利用点图——一种通过预训练的视觉Transformer从输入图像回归得到的结构化2D到3D表示——为几何学习提供图像对齐的监督。我们首先介绍必要的背景知识,然后详细描述PM-Loss的设计。
背景
前馈式3D高斯泼溅
该方法旨在通过单次前向传播,从一张或多张输入图像直接重建一组3D高斯分布。其通用架构采用编码器-解码器结构:首先,编码器网络处理输入图像以提取高级特征;这些特征随后通常与相机位姿信息以及其他辅助信息通过融合模块结合;接着,高斯头部网络预测N个3D高斯分布的参数,包括均值(中心点)、协方差(通常用尺度和旋转表示)、不透明度以及颜色(或球谐系数)。
在典型的前馈式3DGS流程中,高斯均值通过反投影预测的深度图得到。具体来说,对于输入图像中的每个像素,预测一个深度值,并结合相机内参矩阵和相机到世界的变换矩阵,计算对应高斯中心的3D位置。尽管这种方法高效,但由于深度图在物体边界处存在固有的不连续性,反投影后会导致高斯分布破碎或错位,从而降低3D场景表示的几何质量,并进一步影响新视角合成的效果。
点图回归
点图是一种结构化的3D表示,其中输入2D图像的每个像素关联一个世界坐标系中的3D点。与仅提供每像素Z值的深度图不同,点图直接表示完整的3D坐标(XYZ)。点图通常通过预训练的深度神经网络(如基于视觉Transformer的架构)从图像中以回归方式生成。
给定一个点图回归模型,对于每张输入图像及其相机位姿,该模型输出一组3D点。这些逐图像的点图被聚合形成全局参考点云,从而提供密集的3D几何先验,供我们的PM-Loss利用。
PM-Loss
为了应对前馈式3DGS中的几何不准确性问题,现有方法(如DepthSplat)通常引入单目深度先验。然而,这些先验通常在2D图像空间中进行监督,可能无法有效转化为一致的3D几何。相反,我们主张直接在3D空间中对几何学习进行正则化。
给定一批输入图像,前馈式3DGS模型直接预测一组3D高斯中心。我们将这些预测的中心点集合记为X_3DGS,其中每个点代表世界坐标系中一个3D高斯的中心。为了指导模型学习准确且一致的几何,我们引入了一种基于预训练点图回归模型的3D监督信号。该模型为每个像素预测一个3D点,形成参考点云X_PM。
高效点云对齐
尽管X_3DGS和X_PM都表示世界坐标系中的场景3D结构,但直接使用X_PM监督X_3DGS并非易事。实际上,这两个点云可能由于尺度、旋转或平移的差异而错位——这些差异源于位姿不准确或生成X_PM的预训练模型所使用的隐式坐标系。如果不解决这些差异,逐点监督可能会引入误导性梯度。因此,精确对齐对于有效从X_PM中提取几何先验并注入X_3DGS至关重要。
传统的对齐方法(如迭代最近点算法,ICP)计算成本高昂,尤其对于密集点云,难以集成到训练循环中。然而,在我们的设定中,高斯中心X_3DGS(来自逐像素深度预测)和点图输出X_PM与输入图像像素存在一一对应的关系。这种自然对应性允许我们使用Umeyama算法——一种闭式且高效的解决方案——来估计两个点集之间的最优相似变换(尺度、旋转和平移)。
给定N个对应点,Umeyama算法通过最小化目标函数来估计最优尺度因子、旋转矩阵和平移向量。估计出的变换随后应用于原始点图X_PM中的每个点,得到对齐后的点图X_PM',从而在一致的坐标系中计算提出的监督损失。
单向Chamfer损失
给定对齐后的点云X_3DGS和X_PM',我们将PM-Loss定义为从X_3DGS到X_PM'的单向Chamfer距离。这种形式确保对于X_3DGS中的每个点,我们都能高效地找到其在X_PM'中的最近邻,从而提供可靠的几何监督。

PM-Loss的设计核心在于在3D空间中重新计算最近邻以进行监督,而非直接依赖自然的一对一像素对应关系(后者会退化为深度损失)。这一设计使得监督对位姿错位和预测噪声更具鲁棒性。我们通过消融实验验证了这一点,并在表格中报告了定量结果。
实验效果
总结一下
我们提出了 PM-Loss,一种简单而有效的训练损失,它利用点图的几何先验来改进前馈式 3DGS。通过使用全局点图作为伪真值在 3D 空间中进行正则化,PM-Loss 缓解了物体边界附近由深度引起的不连续性,从而显著提高了几何和渲染质量。我们的 PM-Loss 可以无缝集成到现有的训练流程中,并且不会引入推理开销。在多个主干网络和大规模数据集上的广泛实验和分析证明了其广泛的适用性和高效性。我们相信 PM-Loss 为训练更鲁棒、更准确的前馈式 3DGS 模型提供了一种实用的解决方案。
局限性:PM-Loss 的有效性受限于预训练点图模型的质量,因为点图中的错误可能通过我们的损失传播到前馈式 3DGS 模型中。利用未来 3D 重建进展中更强大的点图模型是一个有前景的方向。
参考
[1] Revisiting Depth Representations for Feed-Forward 3D Gaussian Splatting
#GeoDrive
新一代世界模型!显式注入空间结构信息,问鼎SOTA(北大&理想)
由北京大学、伯克利人工智能研究院(BAIR)与理想汽车(Li Auto)联合出品,GeoDrive 是一款面向自动驾驶的新一代世界模型系统。针对现有方法普遍依赖二维建模、缺乏三维空间感知,从而导致轨迹不合理、动态交互失真的问题,GeoDrive 首创性地将三维点云渲染过程纳入生成范式,在每一帧生成中显式注入空间结构信息,显著提升了模型的空间一致性与可控性。
🚘 GeoDrive 的三项关键技术创新:
1️⃣ 几何驱动的时序条件生成 系统以单帧 RGB 图像为输入,借助 MonST3R 网络精准估计点云和相机位姿; 结合用户提供的轨迹信息,逐帧进行投影生成,构建具有三维一致性的条件序列,确保场景结构连贯真实。
2️⃣ 动态编辑模块:突破静态渲染局限 通过融合 2D 边界框注释,GeoDrive 支持对可移动物体的灵活位置调整,解决传统渲染中“场景冻结”的假设; 在训练阶段显著提升多车交互场景的动态合理性和模拟真实度。
3️⃣ 结构增强的视频扩散生成架构 将渲染生成的条件序列与噪声特征拼接输入冻结的 Video Diffusion Transformer(DiT), 在保持光学生成质量的同时,引入结构上下文以增强三维几何保真度,实现内容与物理一致性的统一。
- 论文链接:https://arxiv.org/abs/2505.22421
世界模型的最新进展彻底改变了动态环境的仿真,使系统能够预见未来状态并评估潜在动作。在自动驾驶中,这些能力有助于车辆预测其他道路使用者的行为、进行风险感知规划、加速仿真中的训练,并适应新场景,从而提高安全性与可靠性。当前的方法在保持 鲁棒的 3D 几何一致性或处理遮挡时存在缺陷,这在自动驾驶任务的安全评估中至关重要。为了解决这些问题,本文提出了 GeoDrive,该方法将 鲁棒的 3D 几何条件显式地整合到驾驶世界模型中,以增强空间理解能力和动作可控性。具体来说,我们首先从输入帧中提取 3D 表示,然后基于用户指定的自车轨迹获得其 2D 渲染结果。为了实现动态建模,我们在训练过程中提出了一种动态编辑模块,通过编辑车辆的位置来增强渲染效果。大量实验表明,我们的方法在动作准确性和 3D 空间感知方面显著优于现有模型,实现了更加真实、可适应和可靠的场景建模,从而提高了自动驾驶的安全性。此外,我们的模型能够泛化到新的轨迹,并提供交互式的场景编辑功能,例如目标编辑和目标轨迹控制。

自动驾驶世界模型通过模拟三维动态环境,使以下关键能力成为可能:轨迹一致的视角合成、符合物理规律的运动预测,以及安全感知的场景重建和生成。特别是,生成视频模型已成为自运动预测和动态场景重建的有效工具。它们能够合成忠实于轨迹的视觉序列,这对于开发能够预见环境交互同时保持物理合理性的自主系统至关重要。
尽管取得了这些进展,但大多数现有方法由于依赖于二维空间优化,缺乏足够的三维几何感知能力。这一缺陷导致在新视角下出现结构性不连贯现象,以及物理上不合理的物体交互,这在密集交通中的避障等安全关键任务中尤其有害。此外,现有方法通常依赖密集标注(例如高精地图序列和三维边界框轨迹)来实现可控性,只能重复预设动作,而无法理解车辆动力学。
一种更灵活的方法是从单张(或少量)图像中推断动态先验信息,并以期望的自车轨迹为条件。然而,当前基于数值相机参数进行微调的方法缺乏对三维几何结构的理解,从而影响了其动作可控性和一致性。
一个可靠的驾驶世界模型应满足三个标准:
- 静态基础设施与动态代理之间具有严格的时空一致性;
- 对自车轨迹具有三维可控性;
- 对非自车代理的运动模式施加运动学约束。
我们通过一个混合神经-几何框架实现了这些需求,该框架显式地在整个生成序列中强制执行三维几何一致性。首先,我们从单目输入中构建三维结构先验,然后沿着用户指定的相机轨迹进行投影渲染,以生成基于几何条件的引导信号。我们进一步采用级联视频扩散模型,通过三维注意力去噪机制细化这些投影,在优化光度质量的同时提高几何保真度。对于动态目标,我们引入了一个物理引导编辑模块,该模块在明确的运动约束下变换代理外观,以确保物理上合理的交互。
我们的实验表明,GeoDrive显著提升了可控驾驶世界模型的性能。具体而言,我们的方法改善了自车动作的可控性,将轨迹跟踪误差降低了 42%,相较于 Vista模型。此外,我们在视频质量指标方面也取得了显著提升,包括 LPIPS、PSNR、SSIM、FID 和 FVD。此外,我们的模型能够有效泛化到新的视角合成任务,在生成视频质量上超越了 StreetGaussian。除了轨迹控制外,GeoDrive 还提供了交互式场景编辑功能,如动态目标插入、替换和运动控制。此外,通过整合实时视觉输入与预测建模,我们增强了视觉语言模型的决策过程,提供了一个交互式仿真环境,使路径规划更加安全和高效。
相关工作回顾
自动驾驶世界模型
世界模型已成为使智能体能够在复杂动态环境中预见和行动的基石,在自动驾驶领域提出了独特的挑战,包括大视野、高度动态的场景以及对鲁棒泛化能力的需求。近年来的研究探索了多种用于未来预测的生成框架,利用点云、占据网格和图像等表示方法。
基于点云的方法利用激光雷达捕捉到的详细几何信息来预测未来状态,并实现空间几何和动态交互的精确建模。基于占据网格的方法进一步将环境离散化为体素网格,以更细粒度和几何一致性的方式建模场景演变。
基于图像的世界模型因其传感器灵活性和数据可访问性而展现出更大的扩展潜力。它们通常利用强大的生成模型来捕捉真实世界环境的复杂视觉动态,使其在感知和规划任务中特别有价值。
尽管现有的生成模型(如 DriveDreamer和 DrivingDiffusion)通过依赖密集标注(例如高精地图序列和长期的 3D 边界框轨迹)实现了准确的场景控制,但它们只能重复预设动作,而无法真正理解车辆动力学。一种更灵活的方法是直接从单张(或少量)图像中推断动态先验信息,同时结合所需的自车轨迹进行条件设定。最近的系统如 Vista、Terra和 GAIA 1&2通过将原始数值控制向量直接注入生成主干网络,实现了基于动作的生成。然而,由于控制向量并未显式地与视觉潜在空间对齐,导致生成的动作信号较弱,常常导致控制不稳定,需要更大的训练数据集才能收敛。
相比之下,我们的方法将动作命令作为视觉条件输入进行渲染,这与生成潜在空间自然对齐,从而提供了更强的控制信号,并显著提高了生成结果的稳定性和可靠性。
视频生成的条件控制
扩散生成模型已经从文本到图像系统演变为完全多模态的引擎,能够按需合成整个视频序列。在这个过程中,研究重点稳步转向条件生成——为用户提供明确的控制手段来引导输出。ControlNet、T2I-Adapter 和 GLIGEN等里程碑首次将条件信号嵌入文本到图像的流程中;后续研究将其扩展到视频领域,允许使用 RGB 关键帧、深度图、目标轨迹 或语义掩码进行控制。然而,6 自由度相机路径的控制仍然困难。基于 LoRA 的粗略运动类别、数值矩阵条件、深度变形方案和 Plücker 坐标编码各有不足——要么控制不精确,要么覆盖域有限,或者从数字到像素的映射间接。
规划器和安全模块需要帧级别的精度,因此诸如 DriveDreamer和DrivingDiffusion等生成器依赖密集的高清地图序列和长期的 3D 框轨迹来锁定场景到预定路线。其他系统如 Vista、GAIA 1&2 将控制向量直接注入主干特征,但数值命令与视觉特征之间的不匹配削弱了信息,减缓了优化过程,并经常产生漂移。在本工作中,我们提出使用显式的视觉条件来进行精确的自车轨迹控制。
算法详解
给定一个初始参考图像 和自车轨迹 ,我们的框架合成遵循输入轨迹的真实感未来帧。我们利用参考图像中的 3D 几何信息来指导世界建模。首先,我们重建一个 3D 表示,然后沿着用户指定的轨迹渲染视频序列,并处理动态目标。渲染的视频提供几何引导,用于生成时空一致、符合输入轨迹的视频。图 2 展示了整个训练流程。

从参考图像中提取 3D 表示
为了利用 3D 信息进行 3D 一致的生成,我们首先从单张输入图像 构建一个 3D 表示。我们采用 MonST3R,这是一个现成的密集立体模型,能够同时预测 3D 几何和相机姿态,与我们的训练范式相匹配。在推理过程中,我们复制参考图像以满足 MonST3R 的跨视图匹配需求。
给定 RGB 帧 ,MonST3R 通过帧间的跨视图特征匹配预测每个像素的 3D 坐标 和置信度得分 :
其中 表示第 个参考帧中像素 在度量空间中的位置, 表示重建的可靠性。通过对 设置阈值 (通常为 ),第 个参考帧的彩色点云为:
为了对抗序列中有效匹配与无效匹配之间的不平衡,置信图 使用 focal loss 进行训练。此外,为了将静态场景几何与移动物体分离,MonST3R 使用了一个基于 Transformer 的解耦模块。该模块处理参考帧的初始特征(通过跨视图上下文增强),并将它们分为静态和动态两部分。解耦模块使用可学习的提示 token 来分割注意力图:静态 token 关注大平面区域,动态 token 关注紧凑且运动丰富的区域。通过排除动态对应关系,我们获得了一个鲁棒的相机姿态估计:
其中 表示透视投影算子,仅使用静态特征匹配进行计算。
相比传统的 Structure-from-Motion,这种策略在动态城市场景中减少了 38% 的姿态误差。最终得到的点云 将作为我们的几何支架。
带动态编辑的 3D 视频渲染
为了实现精确的输入轨迹跟随,我们的模型渲染了一段视频作为生成过程的视觉引导。我们使用标准的投影几何技术,将参考点云 投影到每个用户提供的相机配置 上。每个 3D 点 经过刚体变换进入相机坐标系 ,然后使用相机内参矩阵 进行透视投影,得到图像坐标:
我们只考虑深度范围在 米内的有效投影,并使用 z-buffering 处理遮挡,最终生成每个相机位置的渲染视图 。

静态渲染的局限性:由于我们只使用第一帧的点云,渲染的场景在整个序列中保持静态。这与真实的自动驾驶场景存在显著差异,因为在真实场景中车辆和其他动态目标始终在移动。静态渲染无法捕捉区分自动驾驶数据集与传统静态场景的动态本质。
动态编辑:为了解决这一限制,我们提出动态编辑,以生成具有静态背景和移动车辆的渲染结果 。具体来说,当用户提供场景中移动车辆的一系列 2D 边界框信息时,我们动态调整它们的位置,以在渲染中创建运动的错觉。这种方法不仅在生成过程中引导自车轨迹,还控制场景中其他车辆的运动。图 3 展示了这一过程。这种设计显著减少了静态渲染与真实动态场景之间的差异,同时实现了对其他车辆的灵活控制——这是现有方法如 Vista和 GAIA所不具备的能力。
双分支控制以实现时空一致性
虽然基于点云的渲染准确地保留了视图之间的几何关系,但它在视觉质量方面仍存在一些问题。渲染的视图通常包含大量遮挡、因传感器覆盖有限而缺失的区域,以及相比真实相机图像降低的视觉保真度。为了提升质量,我们采用了一个潜视频扩散模型来细化投影视图,同时通过特定的条件设置保持 3D 结构保真度。
在此基础上,我们进一步优化了将上下文特征集成到预训练扩散Transformer(DiT)中的方式,借鉴了 VideoPainter提出的方法。然而,我们引入了针对特定需求的关键区别。我们使用动态渲染来捕捉时间与上下文细节,为生成过程提供更适应性的表示。设 表示我们修改后的 DiT 主干层 的特征输出,其中 表示通过 VAE 编码器 得到的动态渲染潜变量, 是时间步 的噪声潜变量。
这些渲染结果通过一个轻量级的条件编码器处理,该编码器提取关键背景线索,而不重复主干架构的大部分结构。将条件编码器的特征集成到冻结的 DiT 中的方式如下:
其中 表示处理噪声潜变量 和渲染潜变量 拼接输入的条件编码器, 表示 DiT 主干中的总层数。 是一个可学习的线性变换,初始化为零,以防止训练初期出现噪声崩溃。这些提取的特征以结构化方式选择性融合进冻结的 DiT,确保只有相关的上下文信息引导生成过程。最终视频序列通过冻结的 VAE 解码器 解码为 。
实验结果








结论
我们提出了 GeoDrive,这是一种用于自动驾驶的视频扩散世界模型,通过显式的米级轨迹控制和直接的视觉条件输入增强了动作可控性和空间准确性。我们的方法重建了三维场景,沿着期望的轨迹进行渲染,并使用视频扩散优化输出。评估表明,我们的模型在视觉真实感和动作一致性方面显著优于现有模型,支持诸如非自车视角生成和场景编辑等应用,从而设定了新的基准。
然而,我们的性能依赖于 MonST3R 对深度和姿态估计的准确性,仅依靠图像和轨迹输入进行世界预测仍具有挑战性。未来的工作将探索结合文本条件和 VLA 理解以进一步提高真实感和一致性。
#车道线论文
Maptr v1/LaneGAP/Maptr v2/Map QR
高清地图(HD Map)对于自动驾驶非常重要,它提供了关于驾驶环境的详细信息,如车道标记、人行横道和道路边界等。传统的高清地图通常通过基于SLAM(即时定位与地图构建)的方法离线构建,这些方法主要的缺点如下
- 成本高,有相关资质的公司少
- 更新不及时,路况可能随时变化
- 容易与自车位置信息不一致,产生误差。
所以实时的地图生成成为了研究的重点,下面主要介绍几篇这个方向上的经典论文。
MapTR v1
过去传统车道线检测算法一般是基于分割,得到一系列散点,再利用模型进行后处理,将散点组成不同的车道线,通常需要聚类,匹配等算法,这个过程后处理一般比较重,往往需要2-3个全职的工程师维护这个过程,还伴随着很多的超参数,通常需要很大的维护量。
MapTR最大的贡献就是由模型直接出分割散点,变成了模型直接出车道线,减少了中间的后处理过程。
创新点
- 等价排列建模->解决GT歧义问题;
- 分层查询嵌入机制->更好的学习GT,先匹配车道线,再匹配车道线里面的点,降低学习难度;
等价排列建模
MapTR的核心在于将车道线离散化成点集(论文中取的20个点),如点(p1,p2,...p20),用来表征一条完整的车道线,这样产生了两个问题
- 车道线(Polyline):它是开放形状的元素,可以从任意一端开始定义,这样会产生两种等价的排列方式。对于没有方向的车道线,p1->p20是正确的GT,p20->p1也应该是正确的GT,解不唯一;
- 行人过道(Polygon):它是闭合形状的元素,每个点都可以作为起点,并且多边形可以沿顺时针或逆时针方向排列,这会导致多个等价的排列组合。

等价排序建模的核心思想是:对于每个地图元素,不强制使用唯一的排列顺序,而是允许所有等价排列。通过这种方式,模型可以在学习过程中处理不同排列方式的点集,而不会引入不必要的歧义。

等价排序建模
作用与效果
- 稳定的学习过程:由于不再强制模型使用唯一的排列,模型在训练过程中对点集排列方式的选择更加灵活,能够适应不同形状的地图元素,避免了不必要的学习难度。
- 显著的性能提升:通过消除排列歧义,MapTR 在实验中表现出比使用固定排列的模型更高的性能。例如,文章提到使用等价排序建模后,模型的 mAP 提高了 5.9%,对行人过道的 AP 提升了 11.9%。
分层查询嵌入机制
在自动驾驶场景中,构建矢量化高清地图需要同时关注地图元素的整体结构(如行人过道的轮廓、车道线的走向)以及组成这些结构的精确点集(例如每个地图元素的关键点)。传统方法往往处理不够高效,或是只能逐步预测点集(如使用自回归解码器的逐点生成方法),导致推理速度较慢。
为了解决这一问题,MapTR 提出了一个分层查询嵌入机制,能够通过分层的方式同时处理实例级别和点级别的信息,提升了效率和准确性。
分层查询嵌入机制将地图元素的表示分为两层:
- 实例级别查询(Instance-level Queries):用于表示每个地图元素的整体结构。
- 点级别查询(Point-level Queries):用于表示组成地图元素的各个点的信息。
这两类查询结合起来,能够有效编码一个地图元素的全局信息和局部细节。具体的公式化如下:

分层查询嵌入机制
LaneGAP
Lane Graph as Path:https://arxiv.org/pdf/2303.08815
主要贡献:
- 提出了一种基于路径的车道图建模方式:与传统的像素或片段级别的车道建模不同,作者提出了一种基于路径(Path-wise)的建模方式。该方法通过保持车道的连续性,更好地捕捉了道路拓扑结构,为自动驾驶中的轨迹规划提供了更有效的信息。
- LaneGAP框架的设计:作者提出了一个名为LaneGAP的在线车道图构建方法。LaneGAP框架是端到端的,通过车载传感器(如摄像头和激光雷达)输入数据来学习路径,然后通过Path2Graph算法将路径恢复成完整的车道图。该方法保持了车道的连续性,并编码了交通信息,以便为后续的规划任务提供指导。
- 设计了新的图形评估指标:为了公平地比较不同建模方法,作者提出了一个新的图形中心评估指标,称为TOPO metric,专门评估车道图的连接性、方向性及其在交叉口等复杂区域的处理情况。该指标与不同的建模方法(像素级、片段级和路径级)兼容。
- 实验验证了路径级建模的优越性:作者通过在多个数据集(包括nuScenes和Argoverse2)上的定量和定性实验,证明了LaneGAP方法在精度和推理速度上优于现有的基于像素和片段的车道图建模方法。此外,LaneGAP还在OpenLane-V2数据集上击败了最新的片段建模方法TopoNet,在mIoU指标上提升了1.6,进一步证明了路径级建模的有效性。
基于路径的车道图建模方式
传统的车道图构建方法大致可以分为像素级(Pixel-wise)和片段级(Piece-wise)两类:
- 像素级方法(Pixel-wise Modeling):
- 流程:首先通过鸟瞰图视角(BEV)的像素级特征图来预测车道的分割图和方向图。然后,通过一些启发式的后处理步骤(如细化算法)从分割图中提取车道的骨架,最后将这些细化后的像素骨架连接成车道图。
- 优点:这种方法可以直接处理图像的每一个像素,适用于简单的车道环境,在某些场景下可以得到较高分辨率的结果。
- 缺点:由于像素级方法依赖于复杂的后处理步骤,这些步骤非常耗时,且在处理复杂路口或拓扑结构时容易失效(如连接点丢失、骨架不完整)。此外,生成的车道容易出现破碎和不连续的现象。
- 片段级方法(Piece-wise Modeling):
- 流程:车道首先被划分为多个小段(例如在车道分叉点或汇合点处进行分割),然后预测这些车道片段之间的连接关系。最后,基于这些片段和它们之间的连接关系,通过后处理步骤(Piece2Graph算法)将它们拼接成完整的车道图。
- 优点:这种方法试图捕捉车道的拓扑结构,特别是在处理交叉路口时,它可以通过片段连接的方式构建较为复杂的车道图。
- 缺点:该方法的核心问题是车道片段之间的连接预测困难,特别是在复杂的道路环境中,片段容易丢失,导致片段间的连接性不好。由此生成的车道图通常是不完整或碎片化的,车道连续性难以保证。
基于路径的建模方式(Path-wise Modeling)- 高效的图构建:由于不需要复杂的后处理步骤(如像素细化或片段连接),路径建模方法可以更快地生成车道图,同时减少了不连续性或连接失败的问题。
- 适用于复杂场景:路径级方法特别适合处理复杂的路口和车道拓扑,因为它通过完整路径的方式捕捉了交通流动的连续性。
- 流程:首先,车道图通过一个新的算法Graph2Path被分解为一系列连续的路径,而不是分割成小的片段。然后,通过路径检测模型来检测完整的路径,并通过Path2Graph算法将这些路径还原为完整的车道图。
- 优点:保持车道的连续性:这种方法能够保持车道的全局连续性,不像像素级和片段级方法那样容易破碎或丢失片段。
- 缺点:路径级建模的挑战在于精确检测完整路径的难度,特别是在复杂的交通场景或环境不确定时,可能会对路径的检测提出更高要求。

三种车道线建模方式对比

总结
MapTR v2

算法结构图
主要贡献:
- 解耦自注意力机制:大大降低了内存消耗并带来了收益,为了降低计算和内存成本,MapTRv2引入了分离的自注意力机制,在实例维度和点维度上分别进行注意力计算,显著减少了内存消耗,同时提高了性能。
- 一对多匹配:在训练过程中,除了基本的单一匹配外,MapTRv2还引入了一对多匹配分支,增加正样本比例,进一步提高了模型的学习效率。
- 辅助loss:对透视图和鸟瞰图都采用了辅助稠密监督,显著提高了性能。
- 拓展到中心线学习:MapTRv2将MapTR扩展到中心线建模和学习,这对于下游运动规划非常重要。
- 支持3D车道线检测:将框架扩展到3D地图构建(会议版本学习2D地图),并在Argoverse2数据集上提供额外的实验。
1.解耦自注意力机制
在标准自注意力机制中,计算复杂度是 ,如下图1所示:
其中
- 是实例查询(instance queries)的数量;
- 是每个实例中点查询(point queries)的数量。
通过解耦自注意力机制,计算复杂度降低为 ,如下图3所示。

解耦自注意力机制
2.一对多匹配(One-to-Many Matching)
是为了加速训练收敛而引入的一种技术。在这种机制下,通过为每个真实的地图元素分配多个预测元素,可以提高正样本的比例,从而提高模型训练的效率。
在标准的一对一匹配(One-to-One Matching)中,每个真实地图元素(Ground Truth, GT)被分配给一个预测元素。这种方法虽然有效,但在实际训练过程中,由于数据稀疏,正样本的数量较少,导致模型收敛较慢。为了增加正样本数量,加速模型的收敛过程,作者引入了一对多匹配机制。
一对多匹配的核心思想是为每个真实的地图元素生成多个预测元素,并通过与多个预测结果进行匹配,增加正样本的比例。这种方式在Transformer架构中非常适合,因为模型可以并行地处理大量查询(queries)。
具体实现
- 第一步: 使用一对一匹配组进行标准的匈牙利匹配,生成一对一的匹配结果。
- 第二步: 将真实地图元素重复 K 次,形成一对多匹配组,并对这些副本与预测实例进行匹配。
- 第三步: 使用一对一和一对多匹配的结果计算总损失,并优化模型。
一对多匹配通过为每个真实地图元素生成多个预测副本,增加了正样本的比例,从而加快了模型的训练收敛。这种技术特别适合于在线地图构建任务中,因为它能够显著提高模型的训练效率,同时保持甚至提升模型的性能。
辅助loss
本文提出了三种辅助损失,分别是:
- 深度预测损失(Depth Prediction Loss)
- 鸟瞰图分割损失(BEV Segmentation Loss)
- 透视视图分割损失(PV Segmentation Loss)

辅助loss
剥离分析结果

Map QR
《Leveraging Enhanced Queries of Point Sets for Vectorized Map Construction》2024 ECCV
https://arxiv.org/pdf/2402.17430
主要贡献:
- 创新的查询设计:提出了散射-聚合查询(Scatter-and-Gather Query),将查询显式地分为内容部分和位置部分。不同于传统方法对每个点分别进行位置预测,MapQR通过实例查询一次性预测多个点位置,利用位置信息加强对地图实例的构建。降低了运算复杂度。
- 性能提升:在多个在线地图构建基准数据集(如nuScenes和Argoverse 2)上,MapQR在保持高效的同时,达到了最佳的平均精度(mAP),超越了现有的最新方法。
散射-聚集查询机制(Scatter-and-Gather Query)
查询类型的区别
- MapTR:每个点查询只负责预测一个位置,它们独立于其他点进行信息探测和预测。虽然所有点最后被组合成一个完整的地图元素,但点查询之间没有共享信息,导致每个点的内容信息较为分散,缺乏全局性。
- MapQR(SGQ):散射-聚合查询通过实例查询将整个地图元素的点信息统一管理,所有点共享相同的内容信息但具有不同的位置信息。这种设计确保了地图元素的全局一致性,使得预测的每个点可以更好地捕捉到整个地图元素的特性。
计算复杂度的区别
- MapTR:由于MapTR使用独立的点查询,计算自注意力(Self-Attention)的复杂度是,其中 N 是地图元素的数量,n 是每个元素中的点数量。随着查询数量的增加,计算复杂度会大幅上升。
- MapQR(SGQ):散射-聚合查询的设计减少了点查询的数量,仅需对实例查询进行自注意力计算,计算复杂度为。因此,相比MapTR,SGQ在处理大规模查询时更加高效,计算成本和内存消耗更低。
位置信息建模的区别
- MapTR:位置信息是通过每个点的查询独立学习的。这种方式容易导致同一个地图元素内的不同点预测出现不一致的情况,尤其在复杂几何结构中,点预测可能会缺乏整体性。
- MapQR(SGQ):SGQ通过参考点(Reference Points)显式建模位置信息,所有子查询的位置信息由这些参考点生成并嵌入。这种位置信息的显式建模不仅提升了每个点的准确性,还确保了整个地图元素的几何形状更加完整和准确。


1.实例查询的定义
每个地图元素(如车道线、道路边界)被一个实例查询(Instance Query,)表示。这个查询包含:
- 内容信息(Content Information):用于描述地图元素的几何和语义属性。
- 位置信息(Positional Information):用于定位地图元素的具体点位。
2. 散射操作(Scatter Operation)
在散射阶段,实例查询被复制为多个子查询 qscai,, 这些子查询共享相同的内容信息,但具有不同的位置信息:
其中:
- i表示第 i个地图元素。
- j表示第 j 个点位。
- n是地图元素中的点的数量。
3. 位置嵌入(Positional Embedding)
每个子查询 通过参考点(Reference Points,)生成位置信息。位置信息是通过参考点的坐标(,)生成并嵌入查询中:
![]()
其中:
- PE(x)是位置信息x的正弦嵌入。
- LP是线性变换,用于对位置嵌入进一步处理。
4. 信息交互(Cross-Attention)
散射的子查询 和输入特征图(BEV特征图,)进行交互,提取位置信息相关的特征:

5. 聚合操作(Gather Operation)
在聚合阶段,散射的子查询被重新聚合成一个完整的实例查询。通过将所有子查询的结果拼接,并通过MLP进行处理:
其中:
- concat 是将所有子查询的结果拼接。
- MLP 是多层感知机,用于聚合子查询。
6. 完整计算流程
完整的散射-聚合查询过程可以表示为:

与其他方法比较

与其他方案比较

#GVPO
港科技GVPO:理解GRPO,超越GRPO
TL;DR: 我们提出了GVPO,优势:(1)唯一最优解恰好是KL约束的reward最大化最优解(2)支持多样化采样分布,避免on-policy和重要性采样带来的各种问题
随着Deepseek的火爆,其中用到的强化学习算法GRPO也引起了广泛关注。GRPO通过对每一个prompt多次采样,避免了额外训练value model的开销。尽管如此,实践中复现GRPO经常表现出训练不稳定、效果表现不佳等症状。为此我们提出了GVPO(Group Variance Policy Optimization), 可以无缝适配现有GRPO框架并取得更好的表现、更稳定的训练并支持更丰富的数据来源。
动机
受到DPO的启发,我们也希望在GRPO场景(每个prompt多次采样)下利用KL约束的reward最大化

的解析解形式:

然而这里有一个问题在于公式里的Z(x)是对所有可能y的期望,在实践中难以计算。为此,我们发现当一个prompt内所有采样的梯度系数加和为0时,Z(x)可以被消掉。
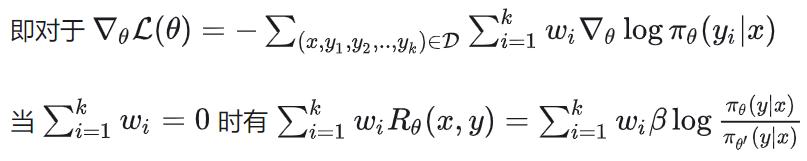
GVPO
受此启发,我们提出了GVPO:

我们证明GVPO具有非常好的物理性质。具体来说

第一步是因为 可以被消掉。第二步是因为 。第三步是因为 。
由此可见,GVPO 居然本质是一个 MSE loss!(喜) 其中 是 MSE 的预测值, 是 MSE 的真实值。
理论保证
基于这个变形,我们很容易(注意到.jpg)证明GVPO的理论最优解恰好是KL约束的reward最大化的最优解,即, 。。

这个定理保证了GVPO实践中的有效性和稳定性。
上式中 是依惯例从要对齐的 policy 中采样,在实践中即 或 。我们接下来可以证明,GVPO 支持从更广泛的分布中采样,且依然保持最优解性质。

在实践中由softmax decoding的policy都满足这个定理的要求。这意味着,GVPO支持非常广泛的采样分布:

GVPO支持非常广泛的采样分布
接下来我们正式展示GVPO的算法流程:

注意到GVPO的每个step中,对齐的都是上一个step的policy。我们还证明了,GVPO在n步结束后,依然能够对齐最初的policy:

定理3可以保证GVPO的每一步更新都是稳定的(因为具有一个大约束 ),且最终优化可以“走得更远”(最终对齐的是 )。
除此之外,文章中还证明了采样得到的loss是 的无偏一致估计量,进一步保证了算法的性能。
与DPO的比较
GVPO与DPO一样,都利用到了KL约束的reward最大化的解析解。DPO是利用BT模型,两两相减消去了不可计算的 。而GVPO则是利用了 的性质而适用于多response的情况。这两个算法利用解析解带来了两个好处: (1)保证了算法优化过程的稳定性, 不会过分偏离 (2)将一个同时有policy 和reward 的复杂优化,简化成了只有reward 和 的简单优化。
除此之外,GVPO和DPO相比还有一个重要的理论优势。DPO其实不一定具有唯一的最优解,换句话说KL约束的reward最大化的解可能只是DPO众多最优解中的一个。这源于DPO依赖的BT模型的内生缺陷。这个问题会导致,优化DPO目标不一定会随之优化我们真实想要的目标(即KL约束的reward最大化)。而GVPO则由定理1证明了其唯一解的性质。
与GRPO及Policy Gradient Methods比较
我们先比较GVPO与其余算法的结构相似性。为了简洁我们在这一节假设=1。我们将展开并稍作变换可以得到其在梯度上等价于


可以发现GVPO的loss里一共有三项:


GVPO里隐含的正则项
我们进一步比较GVPO和Policy Gradient Methods更深层次的区别。实践中,Policy Gradient Methods为了保证更新的稳定性,会在最大化reward的过程中使用KL散度的惩罚限制偏离的程度,即:

这带来一个问题,即必须从当前的policy中采样,带来低采样效率的问题。作为一种解决方式,可以引入重要性采样:

重要性采用使得可以从之前的policy中采样。然而其中带来了重要性采样系数
,当和差别较大时会带来梯度爆炸或者梯度消失等问题。PPO和GRPO等算法在实践中采用了clip技术,强制限制重要性采样系数不要过大或过小。但因此,clip会导致无偏性消失并带来各种各样的问题。
作为对比,GVPO就没有这些问题,因为GVPO从一开始就不需要on- policy采样。将上述Policy Gradient Methods内减去一个常数可以得到:

作为对比,GVPO的梯度是:

由此可见带KL约束的Policy Gradient Methods其实是GVPO当 = 的一种特例!这也体现出GVPO能将采样分布解耦带来的优势:一方面避免了on-policy样本利用率低的缺点,另一方面也避免了现有off-policy方法的重要性采样带来的缺点。
总结
本文的封面概括了GVPO的核心内容:
- 蓝色部分。我们从梯度权重w出发设计了GVPO loss,通过与policy gradient对比,体现了GVPO具有采样丰富性的优势。
- 红色部分。GVPO可以表示成真实reward和隐式reward的MSE形式。从MSE形式可以进一步推导出GVPO理论唯一最优解的优良性质。
- 黄色部分。通过拆解GVPO loss,可以从正则项的角度说明GVPO的稳定性。
此外,GVPO的实现十分简单,文章中展示了在verl框架下如何只修改几行代码实现GVPO。
这篇论文的标题是: GVPO: Group Variance Policy Optimization for Large Language Model Post-Training
arxiv链接:GVPO: Group Variance Policy Optimization for Large Language Model Post-Training



















