
- 作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao
- 单位:中南大学地球科学与信息物理学院
- 论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs
- 论文链接:https://arxiv.org/pdf/2505.18229
- 代码链接:https://github.com/lostwolves/BEDI
主要贡献
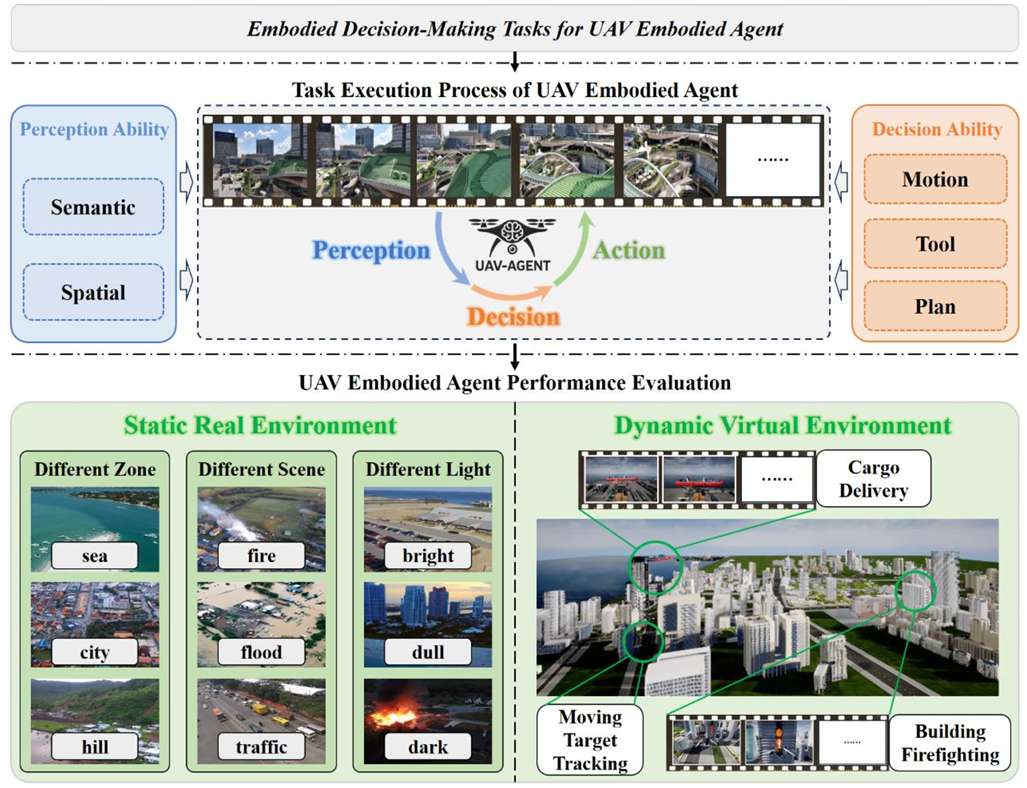
- 提出了系统化、标准化的基准测试框架BEDI(Benchmark for Embodied Drone Intelligence),用于评估无人机(UAV)上的具身智能体(UAV-EAs)。
- 引入了动态具身任务链(Dynamic Chain-of-Embodied-Task)范式,将复杂的无人机任务分解为标准化、可测量的子任务,确保了任务定义的一致性,并支持标准化的性能评估。
- 构建了包含静态真实世界环境和动态虚拟场景的混合测试平台,能够全面评估UAV-EAs在不同场景下的性能,并提供开放、标准化的接口,增强了评估过程的灵活性和可扩展性。
- 通过实证评估几种最先进的视觉语言模型(VLMs),揭示了它们在具身无人机任务中的局限性,强调了BEDI基准测试在推动具身智能研究和模型优化中的关键作用。
背景介绍
- 无人机(UAV)因其效率高、灵活性强、机动性好和运营成本低等优点,在灾害救援、环境监测、农业监测等领域得到了广泛应用。
- 然而,大多数无人机仍然依赖于远程人工控制,在复杂动态环境中效率低下,因此迫切需要开发能够独立执行环境感知、任务决策和执行的无人机具身智能体(UAV-EAs)。
- 目前,用于评估UAV-EAs的方法存在局限性,如缺乏标准化的基准测试、多样化的测试场景和开放的系统接口。这使得对UAV-EAs的评估不够准确和全面,限制了该领域的研究进展。
无人机具身智能体核心能力
态具身任务链范式
- 感知-决策-行动循环:UAV-EAs的任务执行过程被建模为一个感知-决策-行动循环,类似于人类在物理世界中的交互方式。具体来说,UAV-EAs通过传感器获取环境信息(感知),根据任务目标和感知信息做出决策,然后执行相应的动作,这些动作反过来又影响后续的感知,形成一个连续的闭环系统。
- 任务分解:基于上述范式,复杂的UAV任务被分解为多个标准化的子任务,每个子任务都包含感知、决策和行动三个基本步骤。这种分解方式确保了任务定义的一致性,并支持对UAV-EAs的标准化评估。
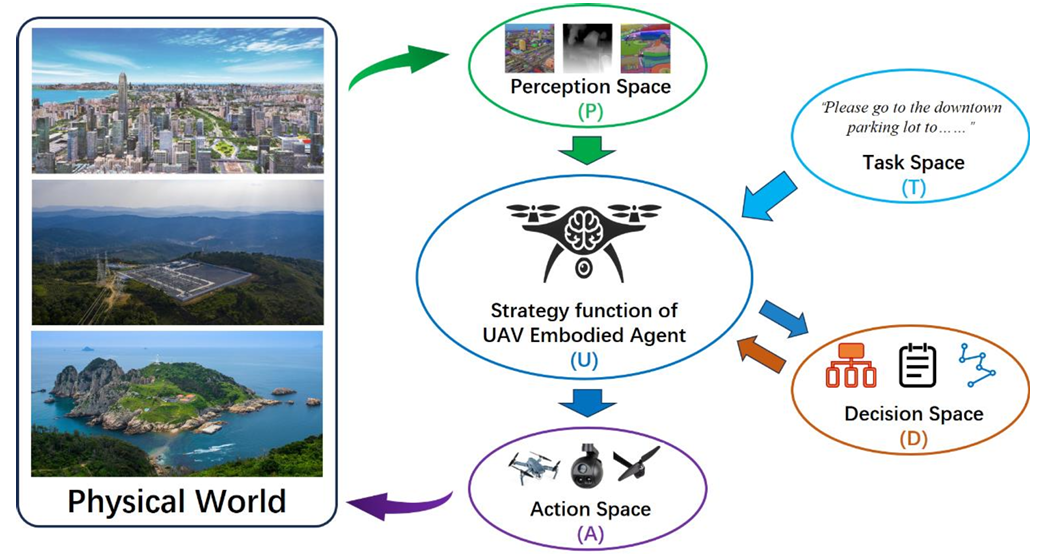
- 马尔可夫决策过程(MDP):UAV-EAs的任务执行过程可以形式化为一个马尔可夫决策过程(MDP),其中包含任务描述空间(T)、感知空间(P)、决策空间(D)和动作空间(A)。策略函数(U)则将这些空间的信息整合起来,生成适当的控制命令。
核心能力1:感知
- 语义感知:UAV-EAs需要能够识别和分类环境中的目标对象,并提取其语义属性(如类别、颜色、大小等)。这涉及到从原始感知数据中提取高级信息,将其转化为可用于更高层次决策的知识。
- 传统方法:基于图像监督学习的方法在理想条件下表现良好,但在开放世界场景中存在局限性。例如,当目标被遮挡或图像质量较差时,这些方法的性能会显著下降。
- 多模态学习方法:通过结合自然语言描述等额外模态信息,可以显著提高模型在复杂环境中的语义感知能力。例如,Maria(Liang et al., 2021)利用大规模图像-文本对和外部常识知识,构建了一个强大的文本到图像检索框架。
- 空间感知:UAV-EAs还需要能够感知和推理对象在空间中的位置、方向和相对距离。这包括方向感知(确定目标相对于自身的位置)和距离感知(评估目标之间的相对距离)。
- 方向感知:基于深度学习的方法在目标定位和方向推理方面取得了进展,但仍然存在挑战,尤其是在细粒度的方向推理(如钟面方向)方面。
- 距离感知:从立体视觉到单目深度估计,多种方法被提出用于估计三维空间中的相对深度。近年来,基于大型语言模型(LLMs)的方法通过生成目标深度的自然语言描述来提高距离感知的准确性。
核心能力2:决策
- 运动控制:UAV-EAs需要能够根据任务需求调整自身的姿态和动态状态,包括飞行方向、高度、速度和视角等。传统的运动控制方法基于经典控制理论,如PID控制器和LQR,但这些方法在非线性和多变量环境中表现不佳。近年来,深度强化学习(DRL)和模仿学习被广泛应用于运动控制,显著提高了UAV-EAs在复杂环境中的适应性。
- 工具利用:UAV-EAs需要能够灵活地操作机载工具或辅助设备,以完成任务目标。这包括释放机械臂、激活灭火器等物理操作,以及调用检测或跟踪模型等算法工具。基于DRL的方法和基于LLMs的方法在工具利用方面取得了进展,但大多数模型仍然存在跨任务泛化能力不足的问题。
- 任务规划:UAV-EAs需要能够分析任务目标,将其分解为可执行的子任务,并评估自身是否具备完成每个步骤的能力。任务规划涉及高层次的推理、目标抽象和感知-决策-行动的动态协调。早期的符号规则框架(如STRIPS和HTNs)在确定性环境中表现出色,但缺乏对动态环境的适应性。近年来,基于DRL和LLMs的方法在任务规划方面取得了进展,但仍存在理想化假设和缺乏实际可执行性的问题。
核心能力的评估
- 能力解耦:为了独立评估每个核心能力,BEDI基准测试框架设计了独立的任务和指标,允许对感知、决策和行动能力进行细粒度评估。
- 能力组合:为了评估UAV-EAs在复杂任务中的综合表现,BEDI还设计了包含多个能力组合的任务,这些任务反映了真实世界中的复杂场景,并将任务阶段映射到各个核心能力。
- 评估指标:BEDI为每个核心能力定义了具体的评估指标,包括语义感知的准确性、空间感知的方向和距离误差、运动控制的调整精度、工具利用的决策正确性以及任务规划的效率等。
无人机具身智能体通用评估框架
现有评估框架的局限性
- 任务导向设计:现有的UAV-EA评估框架通常基于特定任务设计,强调高级任务成功率,但忽视了对核心子能力(如空间感知和工具利用)的细粒度评估。这使得在复杂任务失败时难以确定具体的能力缺陷,降低了评估结果的可解释性。
- 缺乏能力驱动框架:现有基准测试的结构分散,缺乏能力驱动的评估框架。测试任务通常是孤立列举的,没有明确映射到底层智能体能力,导致场景冗余,无法系统覆盖不同能力组合,影响了基准测试的全面性。
开发通用评估框架的可行性
动态具身任务链的形式化描述
- UAV-EA的任务执行过程被形式化为一个由多个顺序循环组成的迭代过程,每个循环包含感知(Perception)、决策(Decision)和行动(Action)三个基本步骤。任务的完成可能需要多个循环,具体数量取决于UAV-EA的任务分解能力。
- 每个循环 $ C_i $ 可以表示为 $ C_i = (P_i, D_i, A_i) $,其中 $ P_i $ 是感知步骤,$ D_i $ 是决策步骤,$ A_i $ 是行动步骤。某些循环可能只包含感知步骤,而不涉及决策或行动。
评估结果的可组合性
- 通过在每个循环的感知、决策和行动步骤中评估UAV-EA的性能,可以量化其在每个阶段的能力。
- 通过聚合单个循环的评估结果,可以得到任务级别的综合评估。具体来说,每个循环的性能评分 $ C_{\text{eval}}(C_i) $ 可以通过加权平均的方式计算:
C eval ( C i ) = α P ⋅ C eval ( P i ) + α D ⋅ C eval ( D i ) + α A ⋅ C eval ( A i ) C_{\text{eval}}(C_i) = \alpha_P \cdot C_{\text{eval}}(P_i) + \alpha_D \cdot C_{\text{eval}}(D_i) + \alpha_A \cdot C_{\text{eval}}(A_i) Ceval(Ci)=αP⋅Ceval(Pi)+αD⋅Ceval(Di)+αA⋅Ceval(Ai)
其中,$ \alpha_P 、 、 、 \alpha_D $ 和 $ \alpha_A $ 分别是感知、决策和行动步骤的权重。 - 任务级别的性能评分 $ C_{\text{eval}}§ $ 可以通过聚合所有循环的评分来计算:
C eval ( P ) = ∑ α i ⋅ C eval ( C i ) C_{\text{eval}}(P) = \sum \alpha_i \cdot C_{\text{eval}}(C_i) Ceval(P)=∑αi⋅Ceval(Ci)
其中,$ \alpha_i $ 是第 $ i $ 个循环的权重。
通用评估框架的可行性分析
- 任务执行的可分解性:UAV-EA的行为可以分解为一系列感知-决策-行动循环,每个循环都是与环境交互的基本单位。这种分解与具身任务的内在结构一致,为框架设计提供了模块化基础。
- 评估结果的可组合性:通过在不同级别聚合评估结果,可以获得UAV-EA性能的全面评估。通过整合感知准确性、决策质量和行动成功率等指标,框架能够提供具身能力的全面可靠评估。
- 适应性和灵活性:基于循环的框架具有内在的适应性,可以根据任务的具体要求调整评估重点,无论是强调感知还是决策。这种灵活性使得框架能够应用于各种场景和任务,显著增强了其适应性和灵活性。
如何系统评估UAV-EA的能力
- 任务设计:基于UAV-EA的核心能力(如感知、决策和行动),设计任务并开发相应的评估指标。每个任务被分解为感知-决策-行动循环,每个步骤代表一个不同的能力。
- 独立任务评估:设计独立的任务和指标,分别评估每个核心能力,实现对感知、决策和行动能力的细粒度评估。
- 多循环测试和动态任务:结合多循环测试和动态任务,评估UAV-EA在真实世界场景中应用多种能力的协调能力。这些任务模拟了UAV-EA必须在协调中应用多种能力的复杂任务,测量了单个循环内的性能以及循环之间的交互。
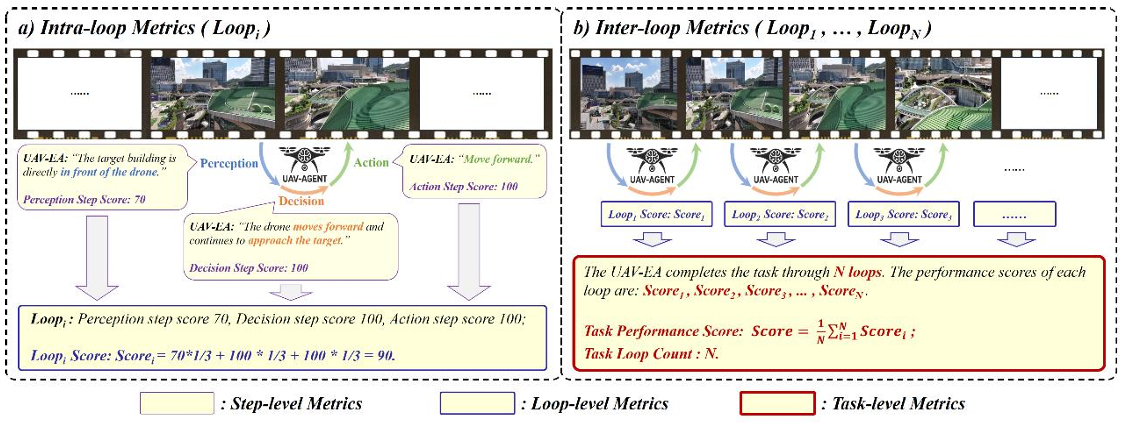
- 评估指标设计:设计了两级评估指标体系,包括循环内指标和循环间指标。
- 循环内指标(Intra-loop metrics):关注UAV-EA在单个循环内的性能,包括步骤级指标(分别评估感知、决策和行动)和循环级指标(评估感知、决策和行动的综合性能)。
- 循环间指标(Inter-loop metrics):关注任务级别的评估,跨越多个循环,评估UAV-EA在整个任务中协调其能力的能力。这些指标聚合了所有单个循环的结果,并考虑了连续步骤中能力整合的一致性和时间连贯性。
评估指标的具体设计
- 步骤级指标(Step-level metrics):
- 感知:基于准确性评估,例如,如果UAV-EA正确识别了目标类别,则感知评分为100,否则为0。
- 决策:基于所选策略的正确性进行评估。
- 行动:通过执行成功率来衡量。
- 循环级指标(Loop-level metrics):
- 评估单个循环中感知、决策和行动的综合性能。如果循环中包含所有三个步骤,则可以将权重设置为相等以简化计算。例如,如果UAV-EA在某个循环中感知得分为100,决策得分为80,行动得分为0,则该循环的整体性能评分为60(假设三个步骤的权重相等)。
- 任务级指标(Task-level metrics):
- 聚合所有循环的循环级评分,计算任务的整体性能评分。同时,引入额外的指标,如任务循环总数或所用时间,以直接反映任务执行效率。
- 例如,如果UAV-EA完成任务使用了四个循环,循环级评分分别为90、90、80和80,则任务级评分为85(假设权重相等),而任务循环计数为4。
BEDI基准

混合虚拟-真实测试环境
BEDI基准测试平台结合了真实世界的数据和虚拟环境的优势,以提供一个全面的测试平台。
基于无人机影像的真实世界测试环境
数据集构建
为了评估UAV-EAs的感知和决策能力,论文构建了一个基于真实无人机图像的测试数据集。该数据集涵盖了多种场景,包括火灾救援、交通监控、城市巡逻和野外探索等,以确保测试环境的多样性和真实性。
任务设计
测试任务分为感知任务和决策任务,具体包括:
- 感知任务:
- 语义信息识别(Semantic_InfoDis):识别图像中选定区域的对象类别。
- 语义信息描述(Semantic_InfoDes):描述选定区域对象的特征,包括类型、颜色、大小等。
- 语义信息目标确定(Semantic_InfoDet):根据文本描述确定图像中匹配的区域。
- 空间位置关系识别(Spatial_PosRelDis):确定目标相对于无人机的方向。
- 空间相对距离关系识别(Spatial_RelDisRelDis):识别满足特定距离条件的区域。
- 决策任务:
- 运动控制(Motion):根据任务描述和图像中的相关区域,确定所需的运动调整。
- 工具利用(Tool):根据任务描述和可用工具信息,决定是否使用特定工具。
- 任务规划(Plan):评估任务是否可以独立完成,并提出后续任务分配或协调计划。
利用虚拟仿真工具的模拟测试环境
- 虚拟环境设计:为了支持感知、决策和行动的实时交互,论文使用Unreal Engine 4.27.2开发了一个模拟测试环境。该环境支持从第一人称视角执行任务,并提供了与真实操作条件高度一致的视觉保真度。
- 场景设计:模拟环境包括多种场景,如货港、城市建筑群和城市火灾场景,每个场景都对应一个具有实际相关性的任务领域。关键元素如街道、车辆、货物和货船都被精心建模,以增强交互性和视觉保真度。
- 货港场景:模拟现代集装箱港口,评估目标识别、路径规划、运动调整和工具利用等能力。
- 城市火灾场景:模拟高层建筑密集的城市环境,评估紧急情况感知、任务理解、协同规划和工具操作能力。
- 城市移动目标跟踪场景:模拟城市道路网络中的移动车辆,评估行为预测能力。

开放交互接口
为了使研究人员能够灵活、快速地测试UAV-EAs,BEDI提供了一个开放的交互接口。
- 接口设计:该平台包括一个Python客户端应用程序和一个基于HTTP的代理服务器,便于用户定义的智能体的集成和评估。通过二次开发AirSim插件,封装并重新设计了其底层控制操作,提供了三种主要的交互接口类别:感知接口、动作接口和状态接口。
- 感知接口:模拟无人机的感官输入,允许智能体从第一人称视角观察环境。无人机配备了五个可配置的视角(前、后、左、右、底),智能体可以在这些视角之间自主切换以收集环境信息。
- 动作接口:允许智能体通过一组运动命令控制无人机的行为,支持目标导向的任务执行。平台包括基本动作API,如起飞、降落、方向导航、转向和视角切换。此外,还支持特定任务的动作,如货运任务中的货物装卸或灭火任务中的水喷头激活/停用。
- 状态接口:提供关键无人机和环境数据的访问权限,例如智能体的内部状态、目标对象状态和交互结果。示例包括无人机位置、方向和视角,以及环境条件,如火灾状态或无人机是否成功降落在移动平台上。专用状态查询接口支持实时监控和自动化评估,提高态势感知能力,并促进自动化测试流程的设计,用于系统性任务性能评估。
统一评估指标
BEDI为真实世界和虚拟环境中的任务设计了不同的评估指标,以准确评估UAV-EAs的性能。
静态任务评估指标
- 准确性(Accuracy):衡量智能体在给定测试集上的预测正确性,适用于语义信息识别、空间相对距离关系识别和工具利用问题。
P eval Acc = 1 N ∑ i = 1 N P ( A true , i , A gen , i ) P_{\text{eval}}^{\text{Acc}} = \frac{1}{N} \sum_{i=1}^{N} P(A_{\text{true},i}, A_{\text{gen},i}) PevalAcc=N1i=1∑NP(Atrue,i,Agen,i)
其中, N N N 是相应类型问题的总数, P ( ⋅ ) P(\cdot) P(⋅) 是指示函数,如果生成的答案正确则返回1,否则返回0。 - 完整性评分(Completeness Score):用于评估智能体在语义信息目标确定问题中的表现,衡量其是否完全覆盖了所有相关的真实目标。
P eval Cov = ∣ P true ∩ P pred ∣ ∣ P true ∪ P pred ∣ P_{\text{eval}}^{\text{Cov}} = \frac{|P_{\text{true}} \cap P_{\text{pred}}|}{|P_{\text{true}} \cup P_{\text{pred}}|} PevalCov=∣Ptrue∪Ppred∣∣Ptrue∩Ppred∣
其中, ∣ P true ∩ P pred ∣ |P_{\text{true}} \cap P_{\text{pred}}| ∣Ptrue∩Ppred∣ 表示正确预测的目标数量, ∣ P true ∪ P pred ∣ |P_{\text{true}} \cup P_{\text{pred}}| ∣Ptrue∪Ppred∣ 表示预测或真实中提到的唯一目标总数。 - 相对距离评分(Relative Distance Score):用于空间位置关系识别问题,量化预测和真实位置之间的方向误差。
P eval RelDir = 1 − min ( ∣ t 1 − t 2 ∣ , 12 − ∣ t 1 − t 2 ∣ ) 6 P_{\text{eval}}^{\text{RelDir}} = 1 - \frac{\min(|t_1 - t_2|, 12 - |t_1 - t_2|)}{6} PevalRelDir=1−6min(∣t1−t2∣,12−∣t1−t2∣)
其中, t 1 t_1 t1 和 t 2 t_2 t2 分别是目标的真实和预测的时钟面方向。 - 基于GPT的评分(GPT-Based Judge Score):利用GPT-4o模型作为评估专家,通过精心设计的提示来评估智能体响应与真实答案之间的相关性。该指标主要用于语义信息描述、运动控制和任务规划问题。
P eval GPT = GPT-4o ( Prompt , I ∣ A true , A gen ) P_{\text{eval}}^{\text{GPT}} = \text{GPT-4o}(\text{Prompt}, I | A_{\text{true}}, A_{\text{gen}}) PevalGPT=GPT-4o(Prompt,I∣Atrue,Agen)
其中, Prompt \text{Prompt} Prompt 是设计的评估提示, I I I 是输入的无人机图像。
动态任务评估指标
- 感知评分(Perception Score):通过人工评估智能体在动态任务执行过程中的感知准确性。对于每个包含感知步骤的阶段,如果感知正确则得100分,否则得0分。最终感知评分是所有相关阶段的平均分。
P eval Per = 1 N Per ∑ i = 1 N Per P eval Per , i P_{\text{eval}}^{\text{Per}} = \frac{1}{N_{\text{Per}}} \sum_{i=1}^{N_{\text{Per}}} P_{\text{eval}}^{\text{Per},i} PevalPer=NPer1i=1∑NPerPevalPer,i
其中, N Per N_{\text{Per}} NPer 是涉及感知过程的阶段总数。 - 决策评分(Decision Score):与感知评分类似,决策评分是通过评估智能体在所有涉及决策的阶段中的决策准确性来确定的。如果决策正确,则得100分,否则得0分。整体决策评分是所有个体决策评分的平均值。
P eval Dec = 1 N Dec ∑ i = 1 N Dec P eval Dec , i P_{\text{eval}}^{\text{Dec}} = \frac{1}{N_{\text{Dec}}} \sum_{i=1}^{N_{\text{Dec}}} P_{\text{eval}}^{\text{Dec},i} PevalDec=NDec1i=1∑NDecPevalDec,i
其中, N Dec N_{\text{Dec}} NDec 是涉及决策过程的阶段总数。 - 执行步数(Execution Steps):记录智能体完成任务所需的步骤数,作为评估任务执行效率的关键指标。步骤数越少,表示任务完成效率越高。
- 综合评分(Composite Score):综合考虑感知质量、决策质量和任务执行效率,给出智能体在动态任务中的整体表现评分。假设任务完成效率是主要因素,其次是每个步骤中的感知和决策质量。即使智能体在每个阶段都表现出良好的感知和决策能力,如果未能在规定的步数内完成任务,整体评分将大幅降低。
P eval Comp = α eff × ( P eval Per + P eval Dec ) P_{\text{eval}}^{\text{Comp}} = \alpha_{\text{eff}} \times (P_{\text{eval}}^{\text{Per}} + P_{\text{eval}}^{\text{Dec}}) PevalComp=αeff×(PevalPer+PevalDec)
其中, α eff \alpha_{\text{eff}} αeff 是任务效率因子,它随着任务完成所需步数的减少而增加,但前提是任务在预定义的步数限制 P steps ′ P_{\text{steps}}' Psteps′ 内完成。如果模型未能在 P steps ′ P_{\text{steps}}' Psteps′ 内完成任务,则认为任务失败, α eff \alpha_{\text{eff}} αeff 被赋予一个较低的值以反映这一结果。效率因子 α eff \alpha_{\text{eff}} αeff 的定义如下:
α eff = { e − α ( P steps − P steps ′ ) , if P steps < P steps ′ a fail , if P steps ≥ P steps ′ \alpha_{\text{eff}} = \begin{cases} e^{-\alpha (P_{\text{steps}} - P_{\text{steps}}')}, & \text{if } P_{\text{steps}} < P_{\text{steps}}' \\ a_{\text{fail}}, & \text{if } P_{\text{steps}} \geq P_{\text{steps}}' \end{cases} αeff={e−α(Psteps−Psteps′),afail,if Psteps<Psteps′if Psteps≥Psteps′
其中, α \alpha α 是一个缩放因子, a fail a_{\text{fail}} afail 是一个分数阈值,它们都是固定的常数。这些值可以根据任务的难度进行调整。如果某个任务阶段不涉及感知或决策过程,则相应的分数默认为100。 - 归一化综合评分(Normalized Composite Score):为了使不同模型之间的评分具有可比性,将综合评分归一化到一个固定的范围内。具体来说,定义最大综合评分
P
eval
Comp
,
max
P_{\text{eval}}^{\text{Comp},\text{max}}
PevalComp,max 为在单步完成任务(
P
steps
=
1
P_{\text{steps}} = 1
Psteps=1)且感知和决策分数均为100时获得的分数。归一化综合评分
P
eval
Comp
P_{\text{eval}}^{\text{Comp}}
PevalComp 则按以下公式计算:
P eval Comp = P eval Comp P eval Comp , max × 100 P_{\text{eval}}^{\text{Comp}} = \frac{P_{\text{eval}}^{\text{Comp}}}{P_{\text{eval}}^{\text{Comp},\text{max}}} \times 100 PevalComp=PevalComp,maxPevalComp×100
实验与分析
实验设置
测试模型
- 静态图像任务:选取了一系列多模态大语言模型(MLLMs),包括闭源模型(如GPT-4系列、Claude 3.5、Gemini 1.5-Pro和QwenVL-Max)和开源模型(如GLM4V、LLaVA-OneVision、QwenVL、Qwen2VL、MiniCPM-V-2.5、MiniCPM-V-2.6和InternVL2)。这些模型的参数范围从7B到10B不等。
- 动态任务:由于动态任务的复杂性和对高级多模态推理能力的需求,实验重点关注闭源模型,包括GPT-4o、Claude 3.5、Gemini 1.5-Pro和QwenVL-Max。
评估模式
- 静态感知和决策任务:采用标准的MLLM评估方法,通过比较模型输出与参考答案的相似度来评估模型的智能水平。
- 动态具身任务:实现两种评估模式:
- 逐步模式(Step-by-Step):将复杂任务分解为一系列较简单的子任务,每个子任务评估特定能力,以便更详细地评估模型在不同能力上的表现。
- 端到端模式(End-to-End):模型需要根据单一的高级指令完成整个任务,更接近真实世界中的任务执行,评估模型在动态环境中的整体效果。
提示设计

- 由于GPT-4o等通用MLLMs可能不适用于UAV-EA任务,特别是需要与环境交互和执行复杂动作的动态场景,因此设计了结构化和详细的提示来引导模型的行为。每个提示包括以下五个关键部分:
- 状态信息(State Information):提供无人机当前的视角和位置等上下文信息,帮助模型理解其环境状态。
- 任务描述(Task Description):明确指定任务目标,为任务执行提供明确指导。
- 可用动作(Available Actions):列出当前上下文中允许的操作及其简要描述,帮助模型选择适当的动作。
- 任务提示(Task Tips):提供辅助指导,以支持更有效的决策。
- 响应格式要求(Response Format Requirements):定义期望的输出格式,确保响应可以被可靠地解析并转化为可执行的无人机动作。
实验结果
静态图像感知任务
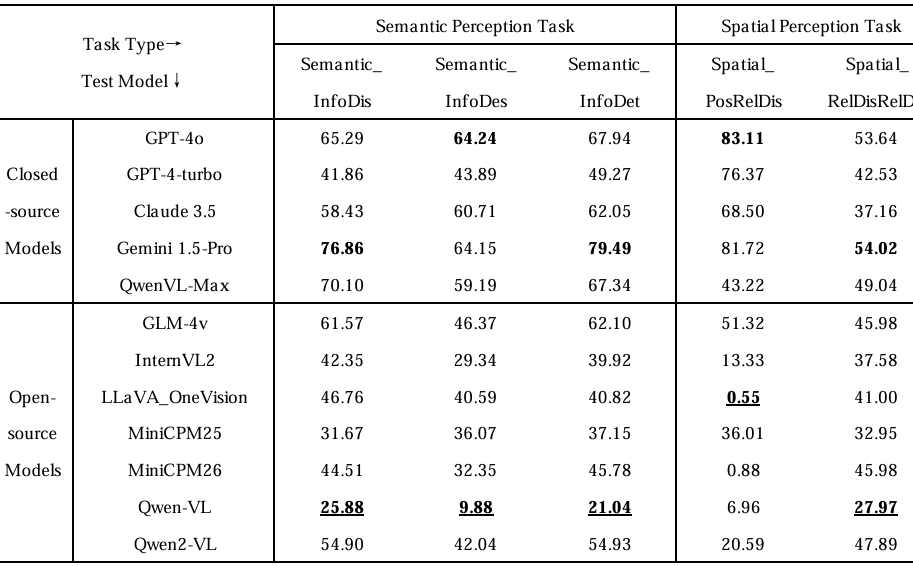
- 实验结果:结果显示,当前模型在基于UAV影像的感知任务中普遍表现不佳,不同模型之间的表现差异显著,且在判别性和生成性能力之间存在较大差距。闭源模型与开源模型之间也存在明显的性能差异。
- 具体表现:
- 在语义感知任务中,Gemini 1.5-Pro在语义信息判别和语义目标确定任务中表现最佳,分别达到76.86%和79.49%,而GPT-4o在语义信息描述任务中略胜一筹(64.24%)。其他闭源模型如Claude 3.5和QwenVL-Max的准确率大多在60%到70%之间。相比之下,开源模型表现普遍较低,如GLM-4V在判别和目标确定任务中表现与GPT-4o相似,但在语义描述方面仍显不足。Qwen2-VL在判别(54.90%)和目标确定(54.93%)任务中较Qwen-VL有显著提升,但在语义描述任务中表现仍低至42.04%。MiniCPM-V-2.5和InternVL2在多数任务中得分低于50%。
- 在空间感知任务中,测试模型表现极化严重,许多模型在位置关系估计任务中完全失败。闭源模型在空间位置关系判别任务中领先,GPT-4o达到最高准确率83.11%。而开源模型几乎全军覆没,如LLaVA-OneVision(0.55%)、MiniCPM-V-2.6(0.88%)和Qwen-VL(6.96%)得分接近随机水平。在空间相对距离关系判别任务中,Gemini 1.5-Pro再次略微领先于GPT-4o(54.02% vs. 53.64%),而大多数开源模型仍落后,如MiniCPM-V-2.5得分32.95%,LLaVA-OneVision为41.00%,Qwen2-VL为47.89%,仍低于Gemini 1.5-Pro的54.02%。这些结果表明,轻量级模型在应对复杂空间推理任务时存在困难。
- 结论:实验结果突出了当前VLMs在UAV具身智能应用中的两个主要局限性。首先,语义感知与空间感知之间存在弱连接,使模型难以同时处理生成、分类和空间推理任务。其次,缺乏嵌入的领域特定知识,如钟面方向编码和UAV动力学理解,导致在真实世界UAV任务中性能显著下降。这些局限性凸显了实际可用性方面的差距,并为具身AI研究中的VLMs发展指明了明确方向。
静态图像决策任务
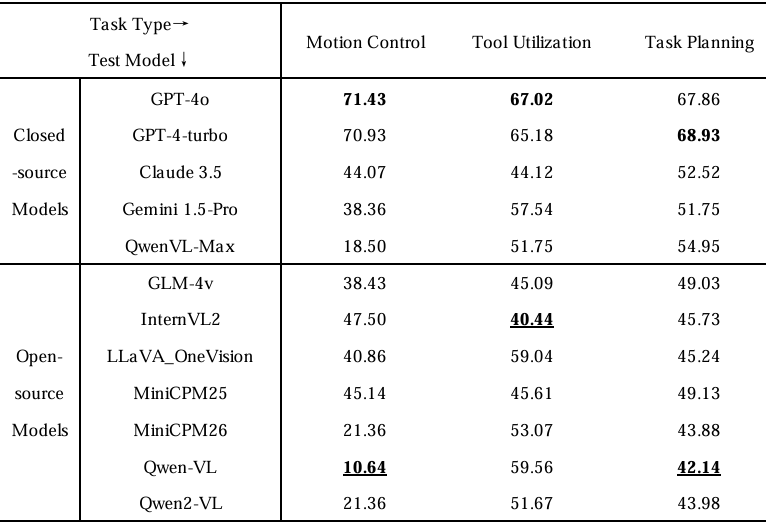
- 实验结果:尽管闭源模型与开源模型在决策任务中的表现相对平衡,与感知任务中观察到的较大差异相比,整体结果仍显示出显著的提升空间。
- 具体表现:
- 在运动控制任务中,模型之间的表现差异显著。GPT系列模型(GPT-4o为71.43%,GPT-4-turbo为70.93%)领先,但仍未突破72%的上限,暴露出它们在理解动态场景和从单帧输入生成多步UAV运动计划方面的能力限制。在闭源模型中,Claude 3.5(44.07%)和Gemini 1.5-Pro(38.36%)表现中等,而QwenVL-Max(18.50%)接近随机猜测水平,令人意外地表现不如许多较小的闭源模型。
- 在工具利用任务中,所有模型的整体表现较弱,准确率集中在40%到70%之间,远低于实际部署的阈值。GPT-4o(67.02%)和GPT-4-turbo(65.18%)在闭源模型中保持领先,但未能突破70%。Claude 3.5(44.12%)、Gemini 1.5-Pro(57.54%)和QwenVL-Max(51.75%)得分中等。在开源模型中,Qwen-VL(59.56%)和LLaVA-OneVision(59.04%)接近闭源模型表现,但仍低于60%。其他开源模型,如MiniCPM-V-2.6(53.07%)、Qwen2-VL(51.67%)、GLM-4V(45.09%)、InternVL2(40.44%)和MiniCPM-V-2.5(45.61%)表现较差,但准确率仍高于40%。定性分析表明,中等得分主要源于模型对工具使用指令的响应风格。
- 在任务规划任务中,所有模型的表现相对平衡,但得分均低于70%。闭源模型GPT-4-turbo(68.93%)和GPT-4o(67.86%)表现最佳,而QwenVL-Max(54.95%)和Claude 3.5(52.52%)的规划能力相对较弱。开源模型普遍表现较差:GLM-4V(49.03%)、MiniCPM-V-2.5(49.13%)和InternVL2(45.73%)得分在40%-50%之间,而Qwen-VL(42.14%)、Qwen2-VL(43.98%)和MiniCPM-V-2.6(43.88%)得分更低。这些方法大幅降低了模型得分,反映出在平衡长期收益与潜在风险方面的能力不足,导致规划方案过于简化且任务结果次优。
- 结论:
- 总体而言,这些结果揭示了当前UAV决策模型的三个主要局限性。
- 首先,对UAV动力学的建模不足,损害了姿态调整决策,导致输出无法满足任务约束。
- 其次,工具调用中的模糊响应降低了操作效率,阻碍了任务的进展。
- 最后,过于保守的任务规划缺乏对环境变化的主动适应性,未能权衡长期利益,阻碍了有效任务的完成。
- 解决这些问题将需要增强领域特定知识的整合、改进多模态推理以及为UAV具身智能量身定制更复杂的规划机制。
动态任务的实验结果
货物运输任务
- 任务描述:无人机从远离指定港口的起始位置开始,给定港口的空间坐标,UAV-EA需要导航至港口,并将机载货物交付给停靠在那里的特定目标船只。任务分为三个连续阶段:“导航至港口”“寻找货船”和“靠近目标船只”。
- 评估方法:在端到端测试设置中,每个模型在相同条件下进行五次重复试验。每次试验开始时,模型都接收到相同的任务提示,然后自主进行操作,性能通过记录完成任务所需的执行步数以及每个相关阶段的感知和决策准确性来衡量。每次试验后计算任务得分,五次试验的平均值作为模型的最终性能得分。
- 在逐步测试设置中,每个模型在相同条件下对每个子任务进行四次重复试验。在每个子任务阶段,模型根据前一阶段的结果执行下一个子任务。计算每个子任务的四次试验的平均得分。在指标计算过程中,复合评分参数设置如下: α = 1.1 \alpha = 1.1 α=1.1, a fail = 0.5 a_{\text{fail}} = 0.5 afail=0.5。对于端到端任务,步数阈值设置为 P steps ′ = 25 P_{\text{steps}}' = 25 Psteps′=25。对于逐步设置,各阶段的步数阈值分别定义为:“导航至港口”阶段 P steps ′ = 5 P_{\text{steps}}' = 5 Psteps′=5,“寻找货船”阶段 P steps ′ = 10 P_{\text{steps}}' = 10 Psteps′=10,“靠近目标船只”阶段 P steps ′ = 20 P_{\text{steps}}' = 20 Psteps′=20。
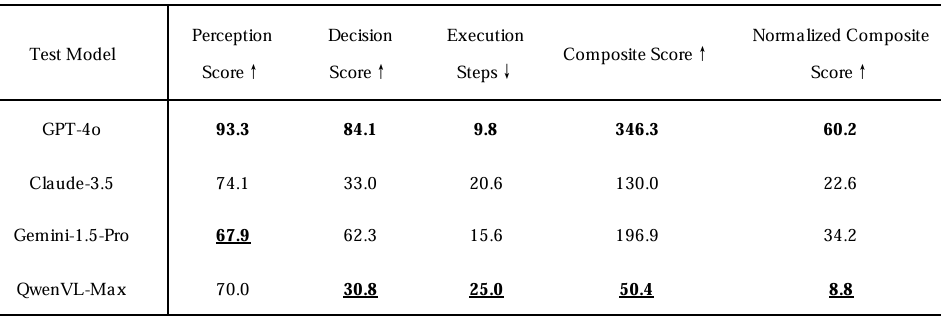
- 实验结果:
- 端到端测试结果:端到端测试结果显示,没有一个评估的VLMs得分超过60.2%(GPT-4o),QwenVL-Max得分低至8.8%。这些结果强调了在自主任务分解和多步协调方面的重大缺陷。例如,GPT-4o在感知准确性方面达到了93.3%,但其决策得分(84.1%)和执行步数(9.8)表明在动态路径规划方面存在效率问题。理论上的最佳步数大约为5步,但由于模型无法平衡最小化距离和避免障碍物等冲突目标,并实时调整策略,实际表现几乎翻倍。过多的轨迹修正导致了冗余运动和步数增加。Claude-3.5和Gemini-1.5-Pro进一步说明了这个问题,其决策得分分别为33.0%和62.3%。Claude-3.5在动态障碍物规避过程中经常陷入局部最优,而Gemini-1.5-Pro则因逻辑推理中断而导致路径规划支离破碎。
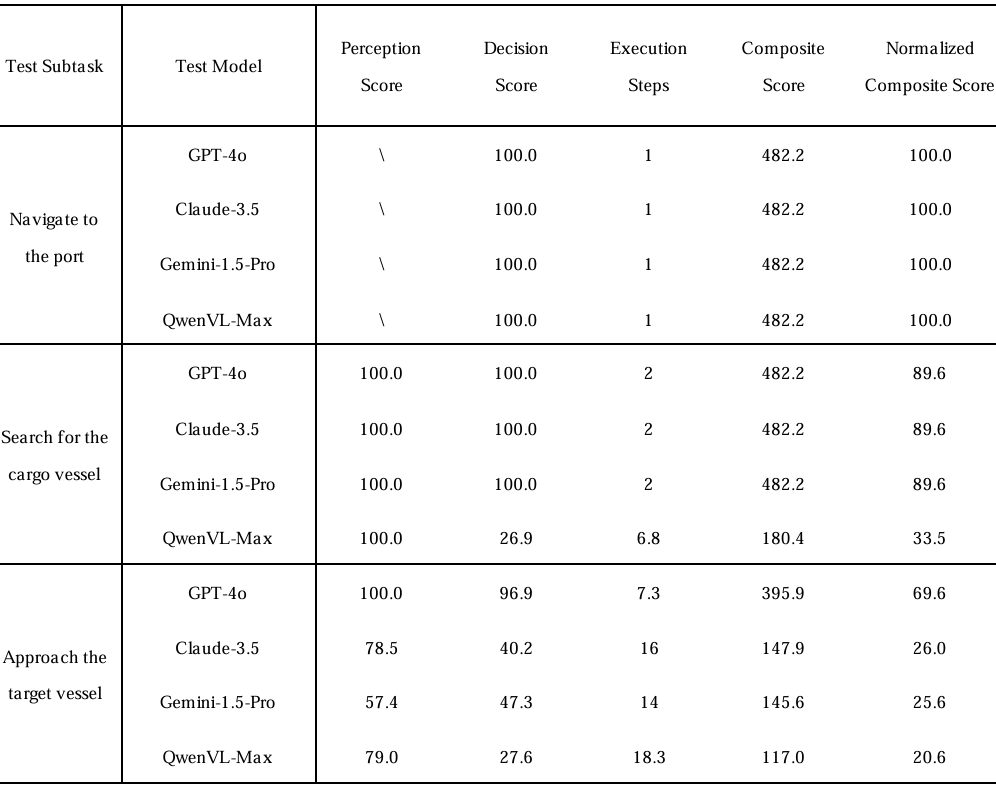
- 逐步测试结果:在逐步测试结果中,模型在子任务之间的表现差异更为明显。在最简单的“导航至港口”任务中,所有模型都表现完美(决策准确率为100%)。然而,在更复杂的阶段,表现急剧下降。例如,在“靠近目标船只”阶段,QwenVL-Max的决策得分降至27.6%,执行步数增加到18.3,其复合得分降至20.6%。这表明在多模态推理方面存在更深层次的问题。尽管该模型在视觉上能够定位船只(感知得分为79.0%),但未能将空间坐标与动态环境因素(如风速或船只运动)相结合,从而导致决策不佳。它仍然根据船只的初始坐标跟随过时的路径,忽略了其实时运动,因此执行了无效的动作。Gemini-1.5-Pro的感知与决策得分差距(57.4%对47.3%)进一步突显了当前模型在将视觉输入与空间推理有效整合方面的无能。它们的决策往往依赖于表面的语义线索,而不是基于物理的推理。此外,QwenVL-Max在“寻找货船”任务中的表现不佳(6.8步,得分33.5%),揭示了其在动态条件下适应能力有限。它未能根据实时更新(如船只运动)调整策略,而是 rigidly following preplanned sequences.
- 结论:综合两种评估模式的结果,当前模型的核心局限性可以归纳为三个方面:
- 缺乏自主任务分解能力:在端到端测试中,执行步数始终高于最优值(例如,GPT-4o为9.8步),表明模型在动态条件下(如障碍物)生成连贯子目标方面存在困难。这一问题源于它们依赖于静态知识库或固定的规则集,这阻碍了它们对环境变化的适应能力。
- 多模态推理能力弱:在逐步测试中,复杂子任务揭示了感知和决策得分之间存在显著差距(例如,Gemini-1.5-Pro:感知得分为57.4%,决策得分为47.3%),突显了跨模态信息整合方面的缺陷。尽管模型可能正确识别了货船的视觉特征,但它们往往未能将这些信息锚定在空间坐标系统内,阻碍了有效的路径规划,导致感知和决策过程脱节。
- 领域泛化能力有限:QwenVL-Max在两种测试模式中的表现都较差(端到端为8.8%,逐步为33.5%),表明开源模型在适应专门任务(如动态港口作业)时严重依赖于领域特定的训练数据。通用预训练未能捕捉到关键知识,如无人机动力学或空间模式,导致在真实世界任务中表现近乎随机。
建筑灭火任务
- 任务描述:UAV-EA初始位置距离燃烧建筑较远。给定目标建筑的空间坐标,智能体需要导航至现场并执行灭火操作。具体而言,智能体需先抵达建筑的火势暴露面,精准定位火源,再利用机载灭火设备将其扑灭。任务划分为三个连续阶段:“导航至火灾现场”“定位火源”和“执行灭火操作”。
- 评估方法:评估流程与货物运输任务相同。在端到端设置中,每个模型在相同条件下进行五次测试,平均结果如表5所示。在逐步设置中,每个子任务重复四次,结果汇总于表6。在指标计算过程中,复合评分参数设定为: α = 1.1 \alpha = 1.1 α=1.1, a fail = 0.5 a_{\text{fail}} = 0.5 afail=0.5。对于端到端任务,步数阈值设定为 P steps ′ = 25 P_{\text{steps}}' = 25 Psteps′=25。对于逐步设置,各阶段的步数阈值分别为:“导航至火灾现场”阶段 P steps ′ = 5 P_{\text{steps}}' = 5 Psteps′=5,“寻找火源”阶段 P steps ′ = 10 P_{\text{steps}}' = 10 Psteps′=10,“执行灭火操作”阶段 P steps ′ = 10 P_{\text{steps}}' = 10 Psteps′=10。
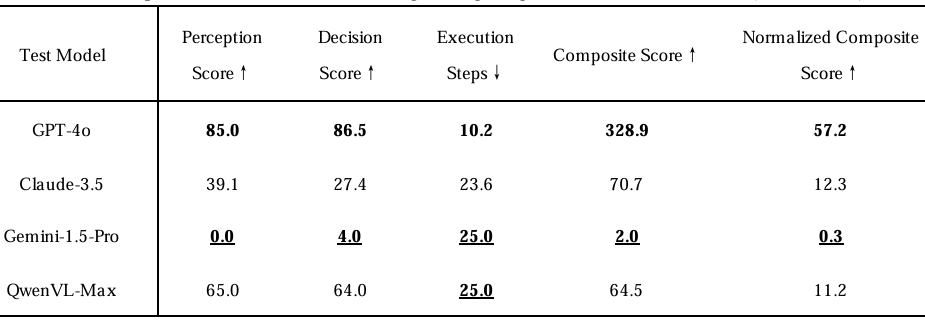
- 实验结果:
- 端到端评估:在端到端评估中,GPT-4o取得了最高的归一化复合评分57.2%,但所需执行步数高达10.2步,远超理论最优值约6步,反映出其对动态环境适应能力不足。模型未能及时响应火势蔓延,导致反复修正路径及执行多余动作。Claude-3.5和QwenVL-Max分别得分12.3%和11.2%,而Gemini-1.5-Pro仅得0.3分,凸显出在自主任务分解与多模态推理方面存在显著弱点。例如,Gemini-1.5-Pro的感知和决策准确率近乎为零(分别为0.0%和4.0%),且执行步数达25步,表明其未能识别火势特征或应用灭火策略。
- 逐步评估:如表6所示,在逐步评估中,模型表现呈现出明显的任务依赖性。所有模型在较为简单的“导航至火灾现场”和“寻找火源”子任务中均表现出色,感知和决策准确率均达100%。然而,在关键子任务“执行灭火操作”中,性能急剧下降。GPT-4o的感知和决策准确率分别为81.7%和76.7%,且需要5步完成。尽管能够定位火源,但在任务规划方面,例如调整喷头角度和控制灭火剂用量方面,仍存在困难。Claude-3.5在该阶段得分完美,但其较低的端到端评分12.3%表明,在跨阶段的长期协调方面存在不足,过度专注于灭火而未考虑上下文风险。QwenVL-Max在灭火子任务中得分61.2%,但其端到端评分仅为11.2%,反映出在任务阶段间的整合能力欠缺。Gemini-1.5-Pro再次表现不佳,感知和决策准确率分别为55.0%和45.0%,需要10步完成,且复合评分仅为9.3%,这可能是由于对火势严重性判断失误以及推理能力有限所致。
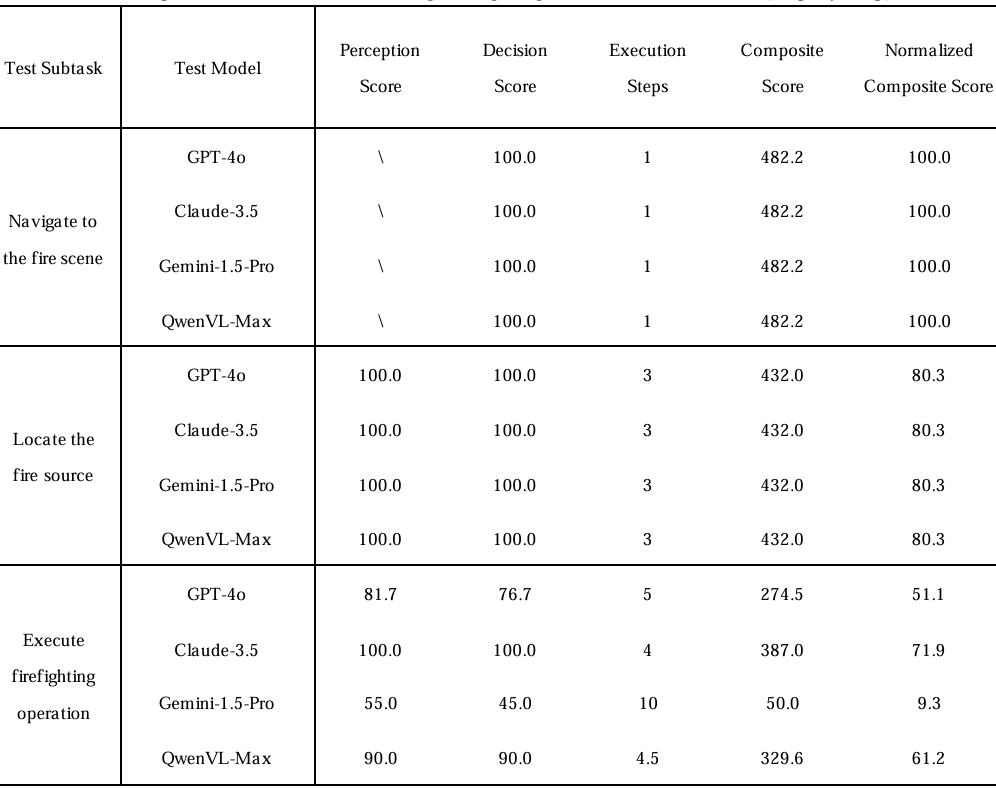
- 结论:综合两种测试模式的结果,揭示了模型的三个核心局限性。首先,对动态环境的适应能力有限。在端到端设置中,高步数(如GPT-4o的10.2步)表明规划不够灵活,无法实时调整。其次,复杂任务中的多模态整合效率低下。尽管模型能够定位火源,但难以将视觉信息与任务特定知识相结合,以制定有效决策。最后,任务链整合能力不足。从逐步到全任务执行的性能下降(如Claude-3.5从71.9%降至12.3%)反映了跨任务阶段协调能力弱,无法妥善管理相互依赖的子任务。
移动目标跟踪任务
- 任务描述:无人机从一个能清晰看到目标的位置开始,但距离目标有一定距离。任务开始后,目标车辆开始移动,无人机需要持续跟踪它。在此过程中,目标会经过多个交叉路口并执行多次转弯。无人机必须在这些关键点做出准确决策,以避免丢失目标。目标车辆的轨迹,包括转弯次数和位置,在任务中是固定的。由于跟踪任务难以分解为不同的子阶段,因此此任务不包括“逐步”测试模式。
- 评估方法:与前两个任务不同,此任务专注于评估UAV-EA在关键行为转换点(即目标车辆在交叉路口转弯时)的性能。每次运行后,评估模型在每个转弯处的感知和决策性能,然后计算整个任务的平均得分。每个模型在相同条件下进行五次测试,最终感知和决策得分通过对所有运行取平均值得到。整体复合得分是感知和决策得分的平均值。
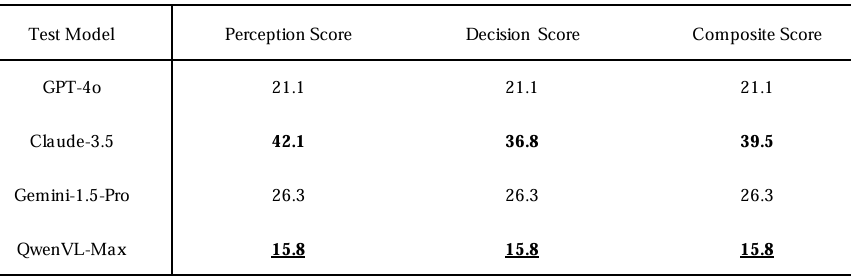
- 实验结果:所有评估模型在移动目标跟踪任务中表现欠佳,均未达到40%的复合得分,凸显了动态空间推理的艰巨挑战。Claude-3.5表现最佳,综合得分为39.5%,感知得分为42.1%,决策得分为36.8%。尽管如此,Claude-3.5在应对目标行为转换(如在交叉路口检测转弯意图)时仍面临困难,常常导致轨迹偏差或响应延迟。
- GPT-4o和Gemini-1.5-Pro分别得分为21.1%和26.3%,反映出它们在处理动态输入流方面的局限性。GPT-4o在感知方面表现不佳,表明其在从无人机视角解释视觉序列方面存在困难。相比之下,Gemini-1.5-Pro的感知和决策得分相对平衡但较低,表明其在运动变化下将感知观察转化为连贯跟踪决策方面存在困难。QwenVL-Max表现最差,感知和决策得分均为15.8%,几乎完全无法理解目标运动。该模型频繁误判方向变化或未能发出任何有意义的响应,表明其在运动识别和自适应控制方面出现了故障。
- 在测试过程中,观察到模型存在两大缺陷。首先,模型在从无人机的第一人称视角解释视觉信息方面存在困难。位置、视角和光照的变化导致视觉噪声,但模型往往依赖于静态图像坐标,从而导致频繁的方向误判。其次,模型缺乏维持一致空间参考框架的稳健机制。它们未能根据位置或方向的变化更新空间理解,导致跟踪策略支离破碎。例如,一些模型未能及时调整无人机的姿态,导致丢失目标。
- 结论:总体而言,这些缺陷表现为动态场景理解能力差,在行为转换期间感知和决策得分较低,以及空间推理能力有限,因为大多数模型无法维持稳定的参考框架。这在QwenVL-Max中尤为明显,其在转弯点的综合得分低至15.8%,凸显了动态空间推理和目标跟踪方面的故障。
结论与未来工作
- 结论:
- BEDI基准测试填补了具身智能领域系统化和标准化评估的空白,为模型比较提供了客观的基础,并为未来的研究奠定了坚实的基础。
- 然而,BEDI也存在一些局限性,例如当前框架未涵盖记忆和预测等更高阶的认知能力,模拟环境缺乏物理干扰(如天气变化和传感器噪声),且评估流程依赖于2D视觉输入,未包含3D传感器数据(如激光雷达或深度图)。
- 未来工作:
- 未来的研究将重点关注以下三个方向:一是整合记忆和预测机制,以支持长期推理和预见能力的评估;二是引入现实的物理干扰,如天气和传感器噪声,以提高模拟的真实性;三是扩展输入空间,包括3D传感器数据,以更好地反映真实世界无人机感知的要求。
- 这些扩展将增强BEDI在评估无人机具身智能体的高级认知能力和环境适应性方面的能力。




















