自然语言处理——Transformer
- 自注意力机制
- 多头注意力机制
- Transformer
虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。
我们可以考虑用CNN来替代RNN,但是缺点是显而易见的——只能捕获局部信息
这就引出了自注意力机制。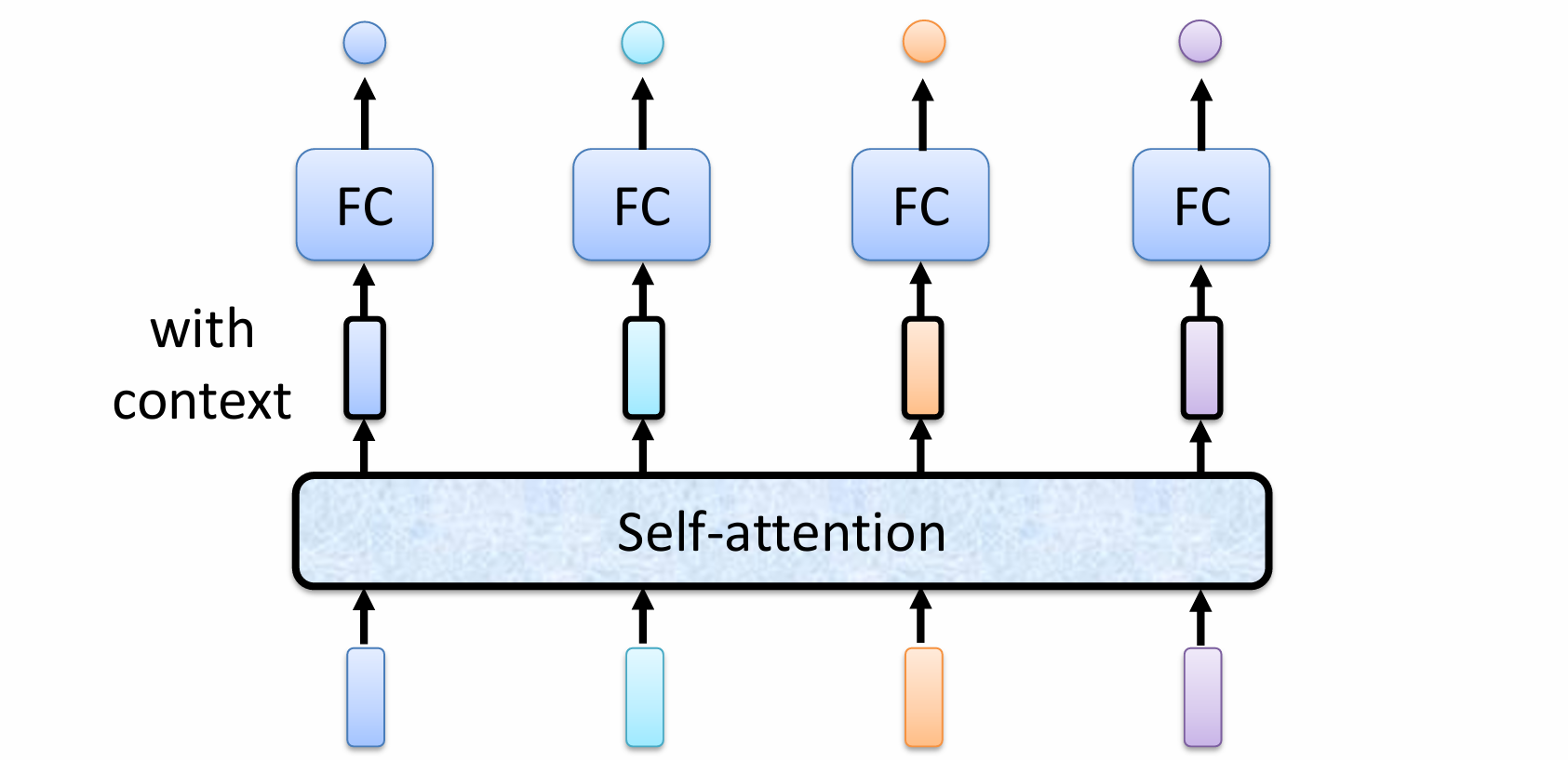
自注意力机制
首先我们需要先回顾一下注意力机制,在经典的注意力机制中,例如在机器翻译任务中,通常会有两个不同的序列:源语言序列(作为编码器的输出)和目标语言序列(作为解码器的输入)。
- 查询(Query):通常来自目标序列的当前元素(或者解码器的隐藏状态)。
- 键(Key):来自源序列的所有元素。
- 值(Value):同样来自源序列的所有元素。
通过计算查询与所有键的相似度,得到一个注意力权重分布,然后将这些权重应用于对应的值,加权求和得到一个上下文向量。这个上下文向量包含了源序列中与查询相关的信息,帮助模型更好地进行解码。
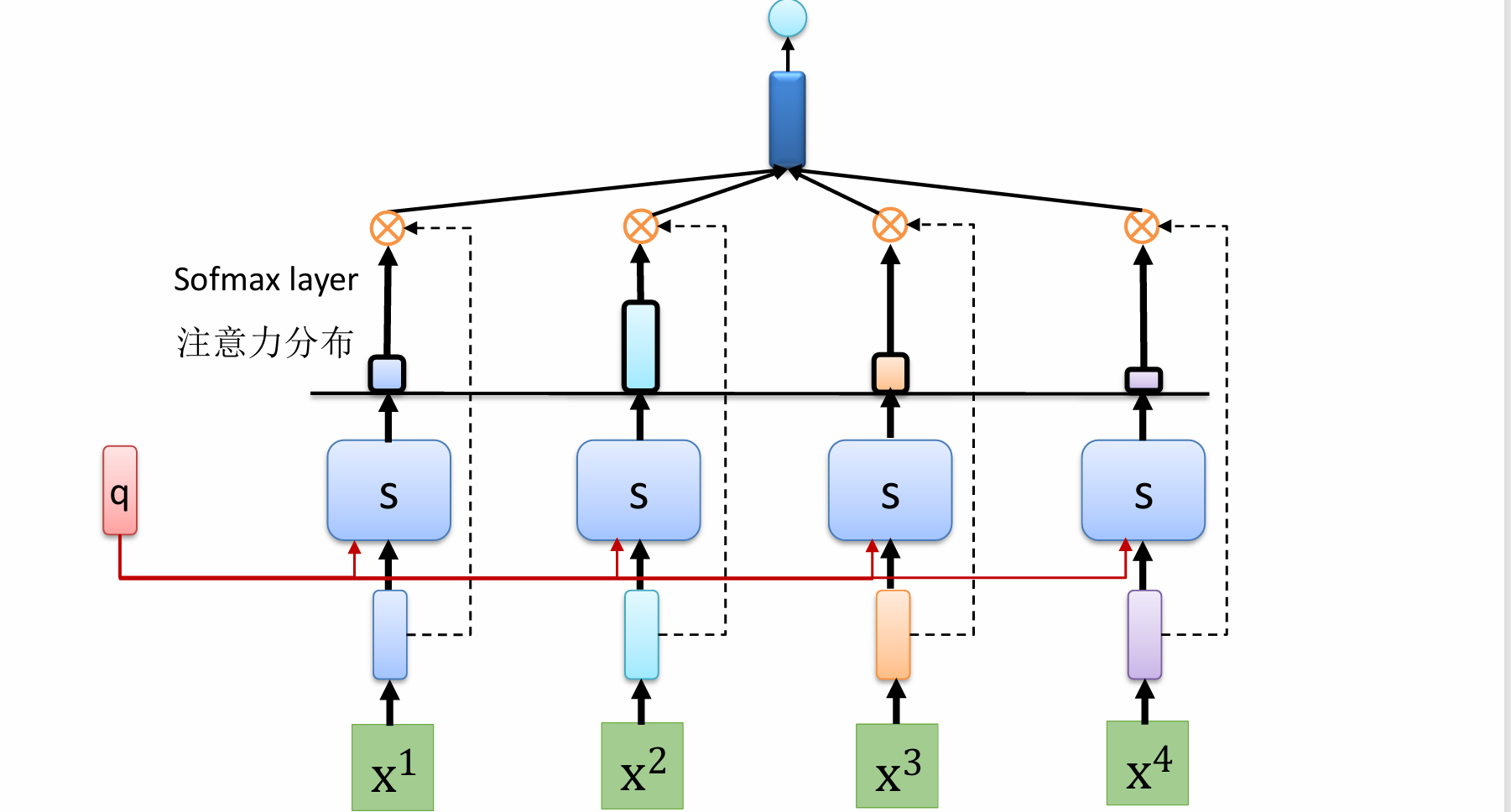
而在自注意力机制中,查询(Query)、键(Key)和值(Value)都来自同一个输入序列。
这意味着模型在处理一个序列中的某个元素时,会去关注该序列中所有其他元素,并根据它们之间的相关性来加权整合信息,从而更好地表示当前元素。
自注意力机制的计算步骤如下:
- 首先通过输入序列计算Q、K、V三个矩阵,将整个序列的输入向量 X 视为一个矩阵,我们可以并行地计算所有 Q,K,V 矩阵
Q = X W Q K = X W K V = X W V Q=X W_{Q}\\K=X W_{K}\\V=X W_{V} Q=XWQK=XWKV=XWV - 对于序列中的每个查询向量
q
i
q_i
qi ,我们需要计算它与所有键向量
k
j
k_j
kj的相似度(或“注意力分数”)。最常用的方法是点积(Dot Product):
score
(
q
i
,
k
j
)
=
q
i
⋅
k
j
=
q
i
k
j
T
\operatorname{score}\left(q_{i}, k_{j}\right)=q_{i} \cdot k_{j}=q_{i} k_{j}^{T}
score(qi,kj)=qi⋅kj=qikjT
更正式地,我们可以将 Q 矩阵和 K 矩阵相乘,得到所有查询与所有键的相似度矩阵: S c o r e s = Q K T Scores=Q K^{T} Scores=QKT - 为了防止点积结果过大导致 softmax 函数进入梯度饱和区,同时当向量维度变大的时候,softmax 函数会造成梯度消失问题,通常会将注意力分数除以 d k d_k dk的平方根。这被称为缩放点积注意力(Scaled Dot-Product Attention),这个缩放因子有助于保持梯度的稳定性。 A t t e n t i o n S c o r e s = Q K T d k AttentionScores =\frac{Q K^{T}}{\sqrt{d_{k}}} AttentionScores=dkQKT
- 对缩放后的注意力分数矩阵的每一行(对应每个 q i q_i qi对所有 k j k_j kj的关注程度)应用 Softmax 函数,注意是在每一列上进行Softmax。这会将分数转换为一个概率分布,使得所有注意力权重之和为 1。 A t t e n t i o n S c o r e s = Softmax ( Q K T d k ) AttentionScores=\operatorname{Softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) AttentionScores=Softmax(dkQKT)
- 最后,将注意力权重与值向量 V 进行加权求和,得到每个输入元素的最终输出表示。 O u t p u t = A t t e n t i o n W e i g h t s ⋅ V Output=AttentionWeights \cdot V Output=AttentionWeights⋅V
一个简化的一元自注意力计算流程可以概括为:
Attention
(
Q
,
K
,
V
)
=
Softmax
(
Q
K
T
d
k
)
V
\operatorname{Attention}(Q, K, V)=\operatorname{Softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V
Attention(Q,K,V)=Softmax(dkQKT)V
这个公式是自注意力机制的精髓。
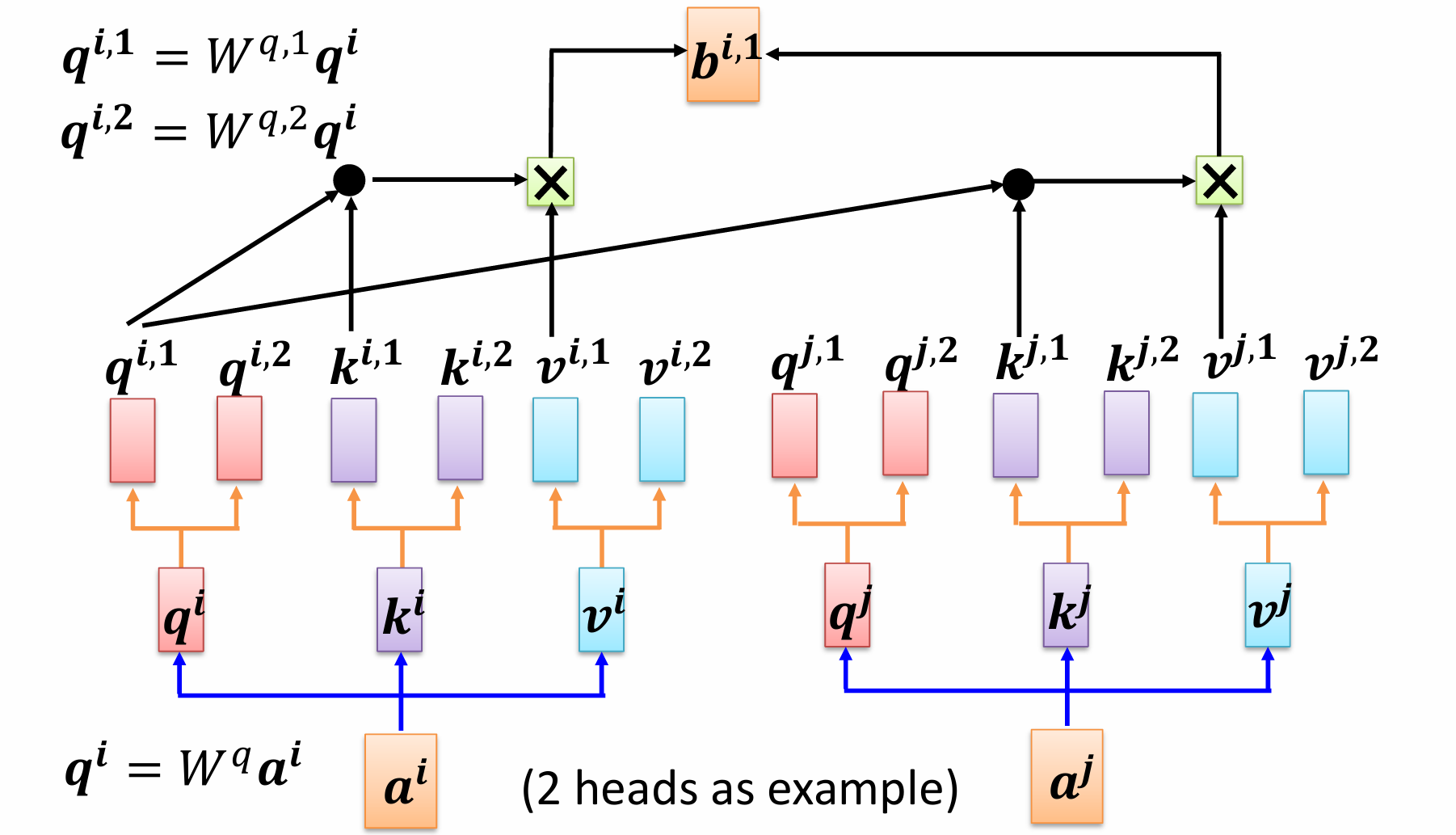
多头注意力机制
以二头注意力为例,下图中的重点为如何生成多头 Q, K, V ,对于
q
i
q^i
qi,我们将其分成了
q
i
,
1
q^{i,1}
qi,1和
q
i
,
2
q^{i,2}
qi,2,分别代表第一个头和第二个头的查询向量。同理对于
k
i
k^i
ki和
v
i
v^i
vi,我们同样也对进行划分。图中左上角的公式表示在划分时,
q
i
,
1
q^{i,1}
qi,1和
q
i
,
2
q^{i,2}
qi,2的得到方式中,原始的
q
i
q^i
qi会被不同的权重矩阵相乘。在实际应用上,更常见的实现方式是,每个注意力头有自己独立的
W
Q
(
h
)
,
W
K
(
h
)
,
W
V
(
h
)
W_{Q}^{(h)}, W_{K}^{(h)}, W_{V}^{(h)}
WQ(h),WK(h),WV(h)矩阵,直接将原始输入
a
i
a^i
ai映射到每个头的
q
(
h
)
,
k
(
h
)
,
v
(
h
)
q^{(h)}, k^{(h)}, v^{(h)}
q(h),k(h),v(h)
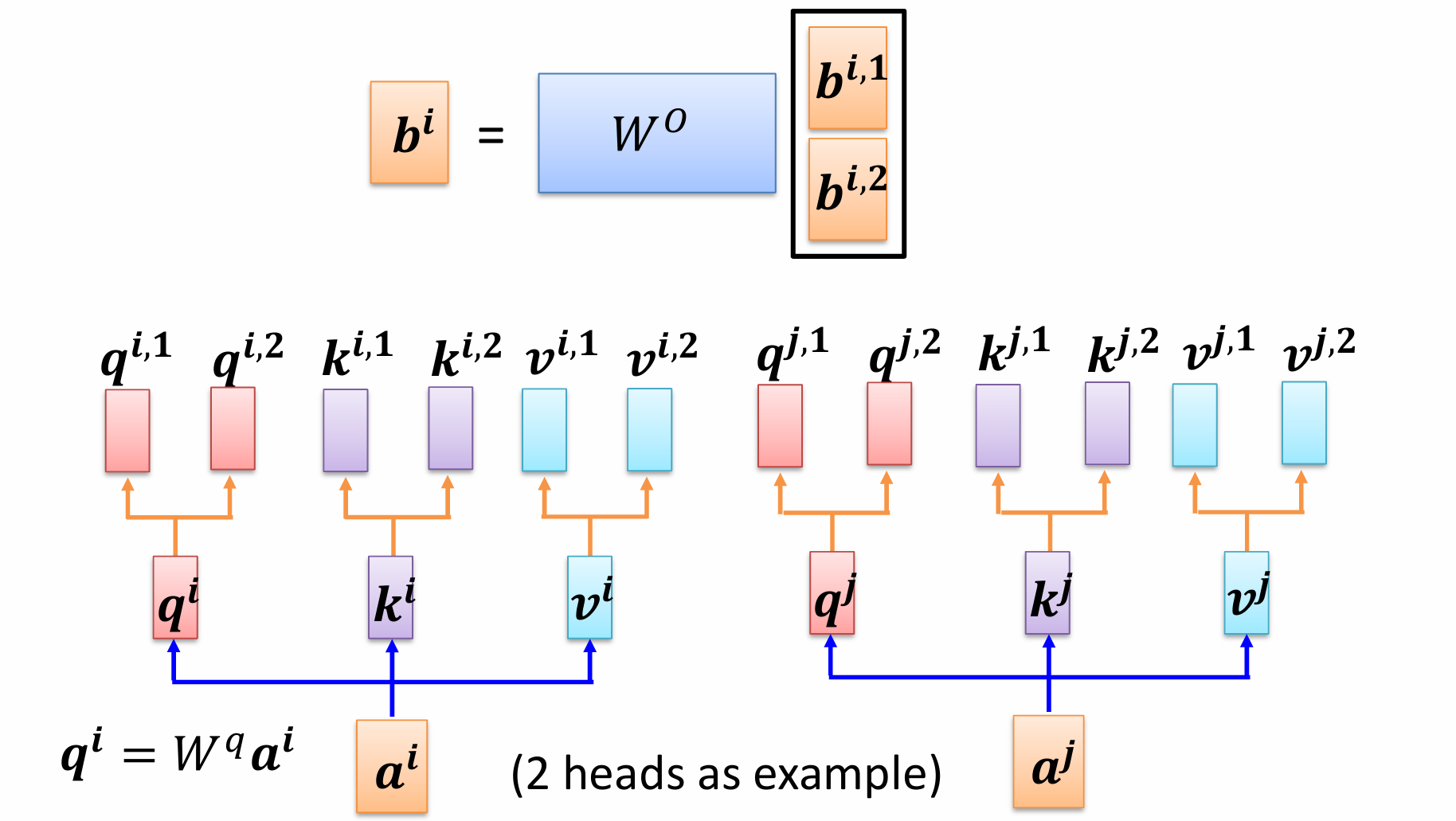
多头注意力机制的最后,我们将得到的两个输出
b
i
,
1
b^{i,1}
bi,1和
b
i
,
2
b^{i,2}
bi,2进行拼接,再乘以
W
O
W^O
WO矩阵就可以得到最终的输出
b
i
b^i
bi了。
自注意力机制缺陷——忽略了序列中的位置信息
为每个位置引入一个位置编码
e
i
e^i
ei,可以通过人工构造,也可以通过参数学习。
Transformer
如图是Transformer的具体架构,可以简化为Encoder-Decoder架构
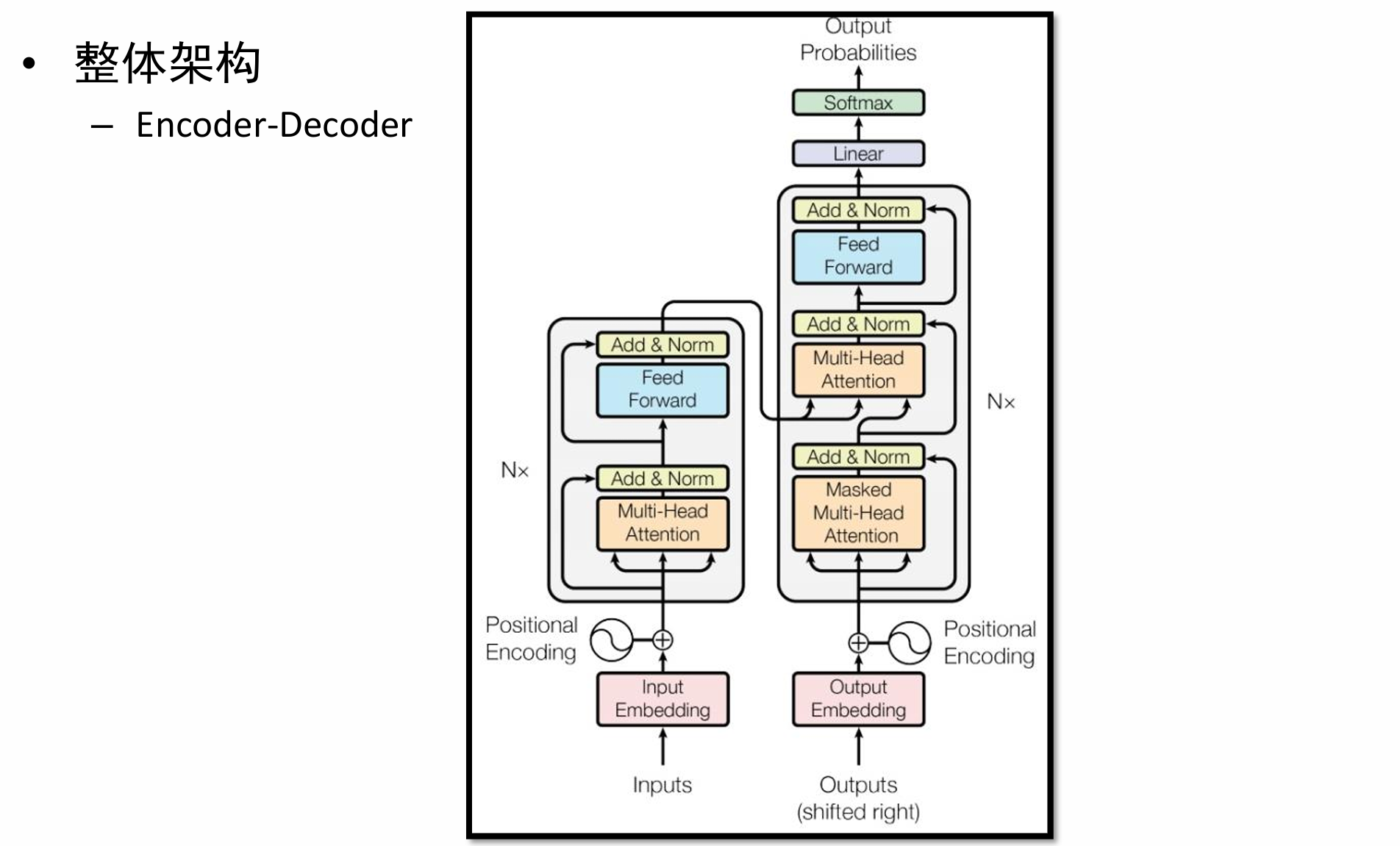
如图所示,Encoder 的左侧部分是一个多层堆叠的结构,由多个相同的“Block”组成。
输入:
x
1
,
x
2
,
x
3
,
x
4
x_1,x_2,x_3,x_4
x1,x2,x3,x4代表输入序列中的四个 Token(可以是词嵌入向量加上位置编码)。
输出:
h
1
,
h
2
,
h
3
,
h
4
h_1,h_2,h_3,h_4
h1,h2,h3,h4代表经过 Encoder 编码后得到的每个 Token 的上下文表示。这些输出向量包含了输入序列中所有 Token 的信息,是深度语境化的表示。
堆叠的 Block: 每一层 Block 都处理前一层 Block 的输出,逐层提取更高级别的特征和语义信息。图中的虚线和“Block”之间的点表示可能有多层 Block。
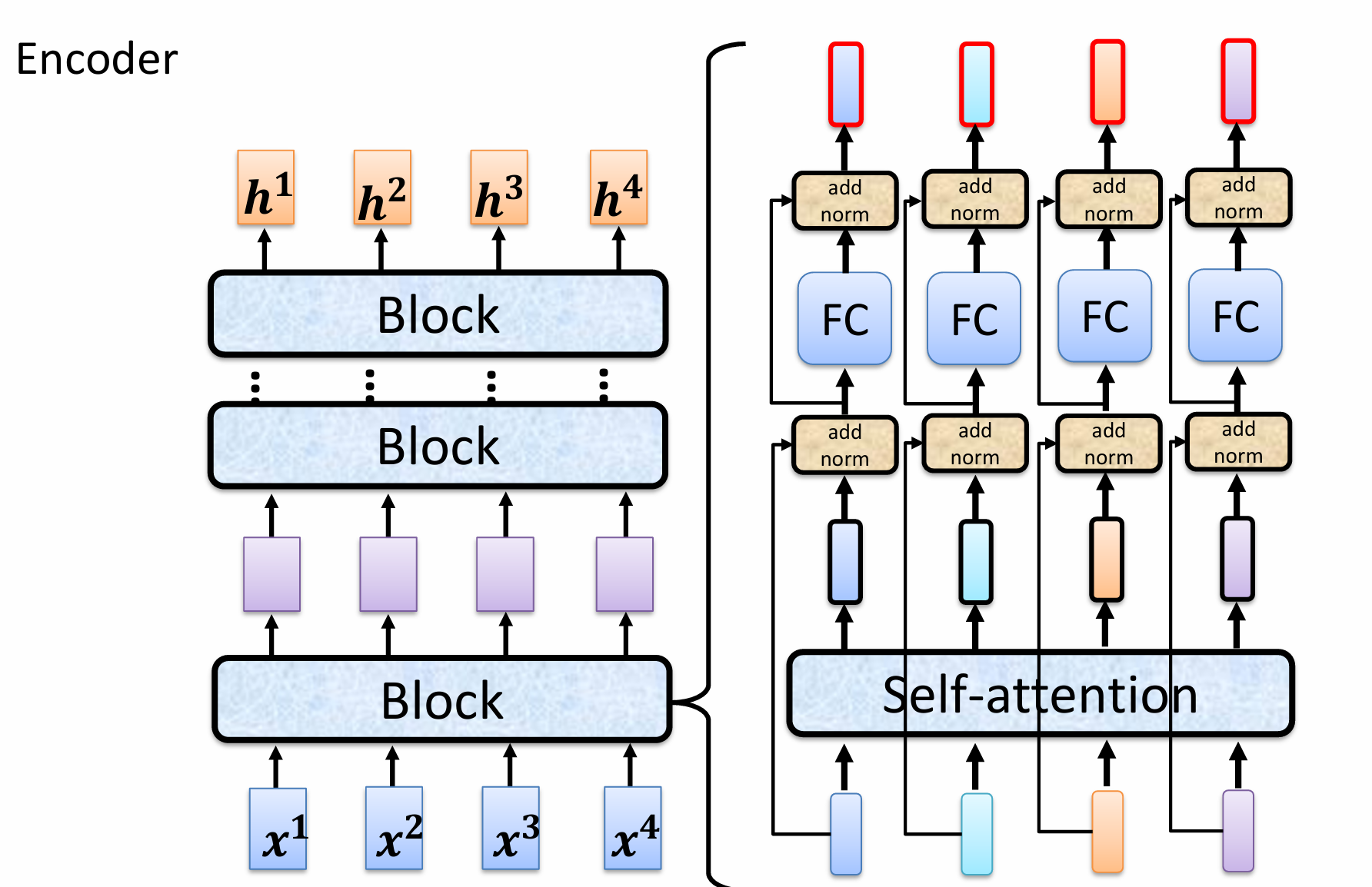
Encoder 的右侧部分详细展示了一个“Block”的内部构成。每个 Block 都包含两个主要的子层:
- 自注意力机制层
- 前馈神经网络层
在这两个子层之间和之后,都使用了两个重要的技巧:残差连接和层归一化。
残差连接有助于缓解深度神经网络中的梯度消失问题,使得信息可以直接通过多层传递,有助于训练更深的模型。形式上,如果一个子层的函数是 Sublayer(x),那么残差连接的输出是 x+Sublayer(x)。
层归一化则对每个样本的每个特征维度进行归一化,使得神经网络的训练过程更加稳定和高效。它有助于避免内部协变量偏移,并允许使用更高的学习率。
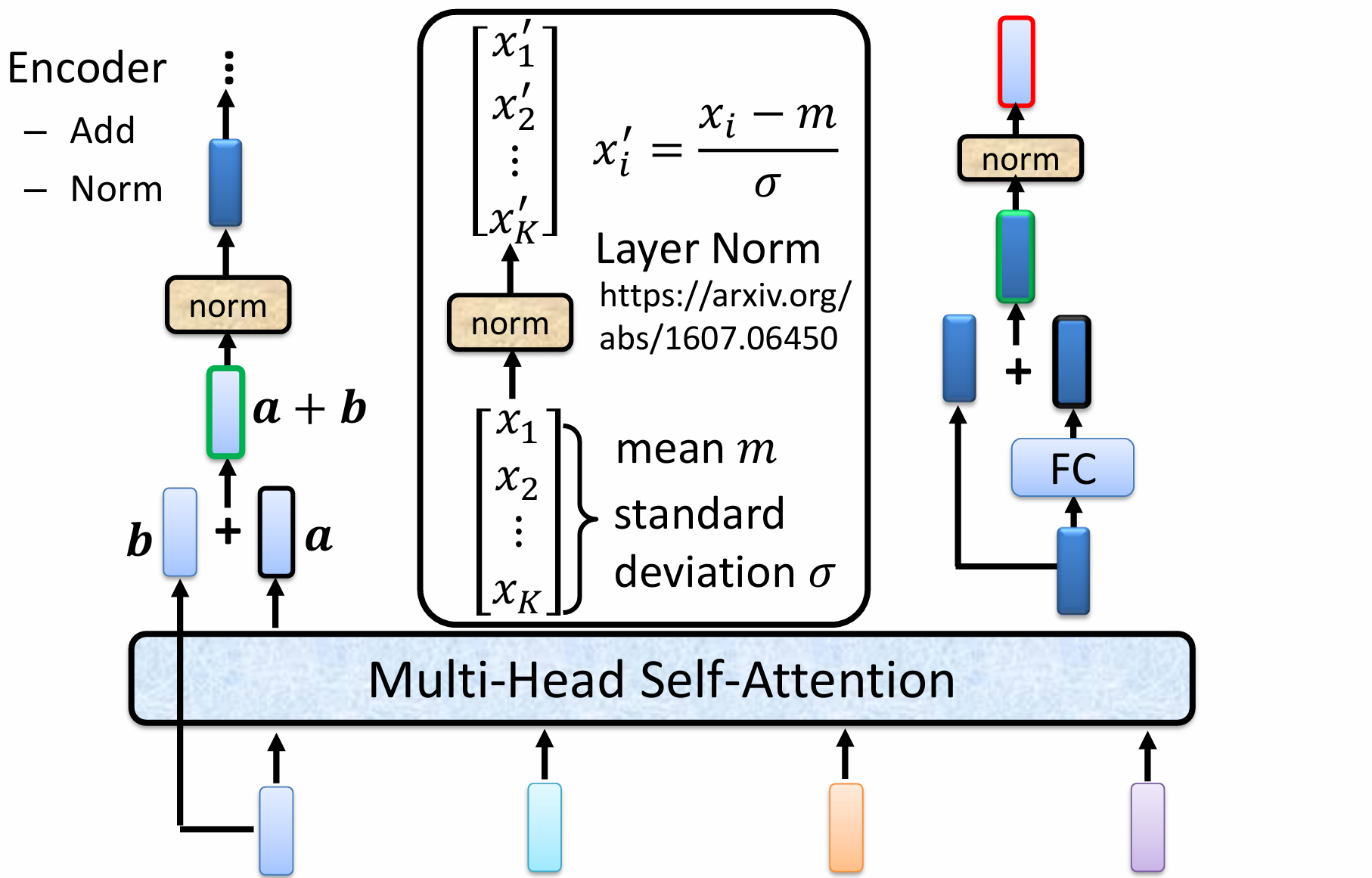
在encoder中,如果对原句有padding,将padding的部分加上-10^5,这样子使其softmax之后=0。
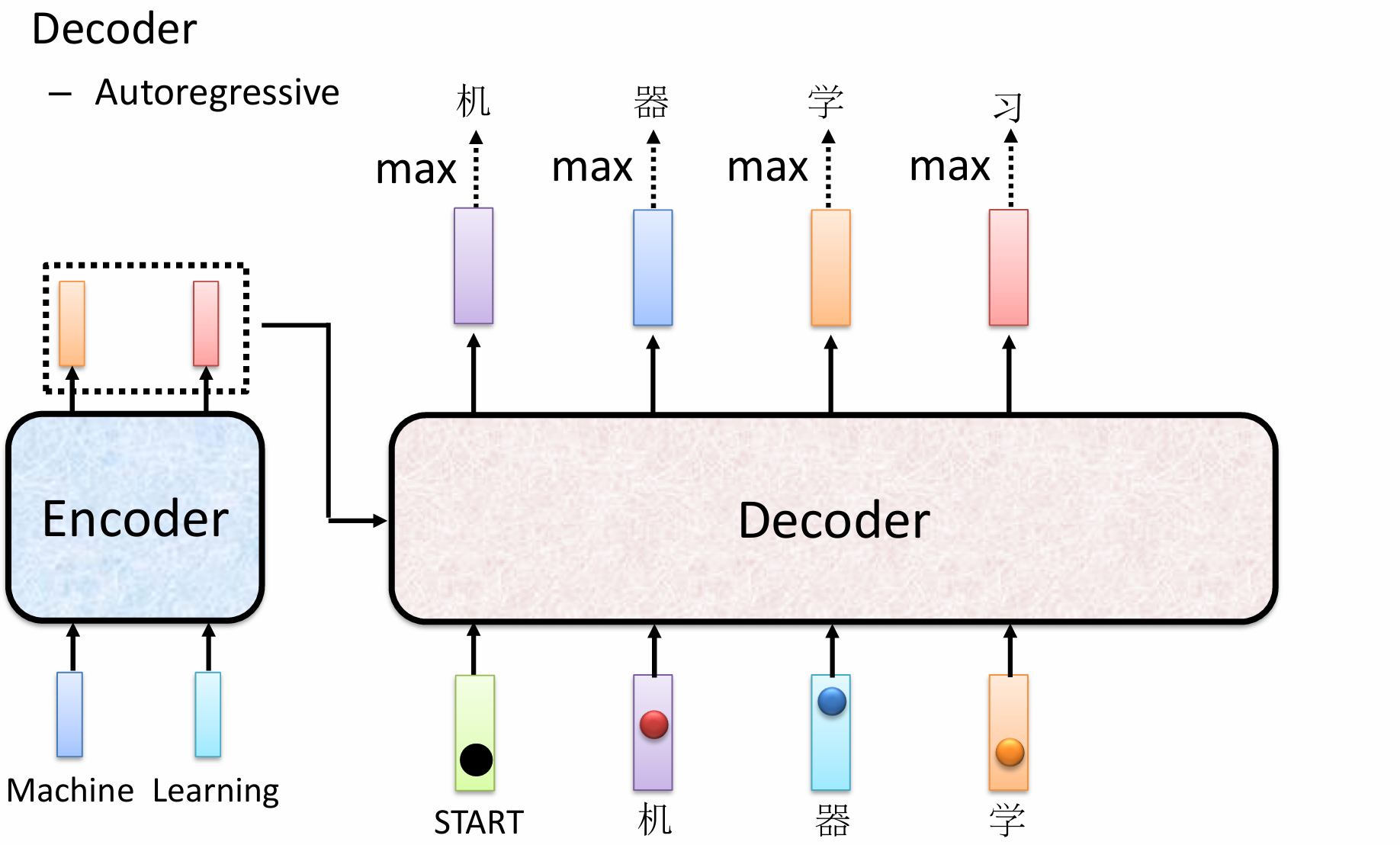
Decoder 的核心任务是根据 Encoder 编码后的上下文信息,生成目标序列。在图中,输入是英文单词 “Machine Learning”,Encoder 将其编码成一个或一组上下文向量(图中Encoder右上角的虚线框)。Decoder 则利用这些上下文向量以及它自己之前生成的词语,逐步生成中文序列 “机 器 学 习”。
Decoder 是 Autoregressive自回归的。这是 Decoder 的一个非常重要的特性,意味着:
- 逐步生成: Decoder 是一个逐个生成输出序列元素的模型。
- 依赖先前的输出: 在生成当前词时,它会利用之前已经生成的词作为输入。
Encoder(左侧蓝色方框)接收输入序列 “Machine Learning”,并将其转换为一系列上下文表示(图中虚线框中的橙色和红色方块,可以是一个上下文向量,也可以是Transformer Encoder中最后一层的所有输出向量)。这些表示包含了输入序列的所有必要信息。
Decoder 的初始输入:Decoder 的第一个输入通常是一个特殊的 START 标记(图中绿色的输入框),这告诉Decoder 开始生成序列。同时,Decoder 会接收来自 Encoder 的上下文信息。之后Decoder 结合 START 标记和 Encoder 的上下文信息,预测输出序列的第一个词。接下来,Decoder 将已经生成的第一个词 “机” 作为它的下一个输入(图中紫色的输入框)。
结合 Encoder 的上下文信息和新的输入 “机”,Decoder 预测出第二个词 “器”。依此类推: 这个过程会重复进行。每生成一个词,就将其作为下一个时间步的输入,直到生成一个特殊的 END 标记,或者达到最大序列长度。
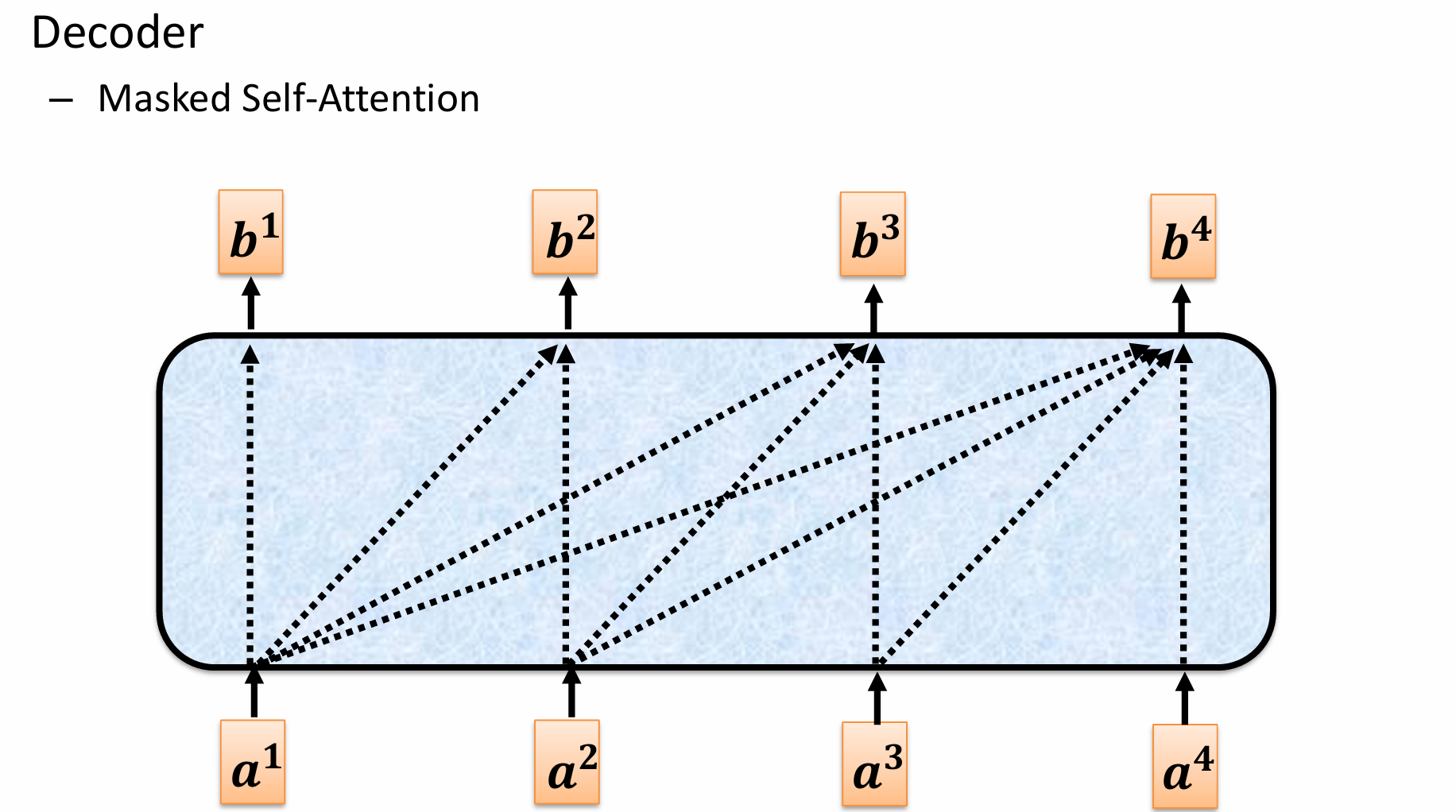
如上图所示:在标准的自注意力机制中(如 Encoder 中使用的),序列中的每个位置都可以“看到”并关注序列中的所有其他位置(包括它自身以及它之后的未来位置)。
然而,在 Decoder 的生成过程中,我们通常是逐个生成输出序列的词语。这意味着当 Decoder 在生成当前位置的词语时,它不应该能够“看到”或利用未来的词语信息,否则就相当于作弊了(模型已经知道答案了)。
Masked Self-Attention 的目的就是强制 Decoder 在生成当前位置的输出时,只能关注当前位置以及之前已经生成过的位置,而不能关注未来的位置。

另外在Transformer的Decoder中,还引入了Cross-attention机制,与自注意力机制(Q, K, V 都来自同一个序列)不同,交叉注意力机制的 Q、K、V 来自不同的源:
- 查询(Query, Q):来自于 Decoder 自身的上一层输出(通常是 Masked Self-Attention 层的输出)。
- 键(Key, K):来自于 Encoder 的输出。
- 值(Value, V):来自于 Encoder 的输出。
交叉注意力层的主要作用是让 Decoder 在生成目标序列的每个词时,能够有选择性地关注 Encoder 编码后的源序列信息。这类似于传统 Seq2Seq 模型中的注意力机制,允许 Decoder 动态地对源序列的不同部分分配权重,从而更好地捕获源序列的上下文信息。



















