目录
1 Bulk API概述
1.1 什么是批量操作
1.2 Bulk API的优势
2 Bulk API的工作原理
2.1 请求处理流程
2.2 底层机制
3 Bulk API的使用方法
3.1 基本请求格式
3.2 操作类型示例
3.3 响应格式
4 Bulk API的最佳实践
4.1 批量大小优化
4.2 错误处理策略
4.3 性能调优技巧
5 高级特性与注意事项
5.1 路由控制
5.2 版本控制
5.3 超时与等待
5.4 安全注意事项
6 常见问题解答
Q1: Bulk API有大小限制吗?
Q2: 如何处理批量操作中的部分失败?
Q3: Bulk API是原子的吗?
Q4: 如何监控批量操作性能?
7 总结
1 Bulk API概述
Elasticsearch的Bulk API是一种高效的数据操作接口,它允许用户通过单个HTTP请求执行多个索引、创建、更新或删除操作。与逐个发送请求相比,Bulk API能显著提高数据处理的吞吐量和系统性能。
1.1 什么是批量操作
批量操作是指将多个数据操作请求打包成一个请求发送到Elasticsearch服务器,服务器接收后会按顺序执行这些操作。这种机制特别适合以下场景:
- 大数据量的初始导入
- 定期批量更新数据
- 需要原子性执行多个操作的场景
1.2 Bulk API的优势
- 网络开销减少:减少了HTTP请求头和认证的开销
- 性能提升:避免了频繁建立连接的开销
- 原子性保证:一个批量请求中的操作要么全部成功,要么全部失败
- 吞吐量提高:相比单条操作,吞吐量可提升数倍
2 Bulk API的工作原理
2.1 请求处理流程

- 客户端准备数据:客户端将多个操作组合成特定格式
- 构建NDJSON:按照Newline Delimited JSON格式组织数据
- 发送请求:通过HTTP POST发送到_bulk端点
- 服务端处理:Elasticsearch顺序执行每个操作
- 返回结果:汇总所有操作结果返回给客户端
2.2 底层机制
Elasticsearch内部使用线程池处理批量请求,主要涉及两个线程池:
- bulk线程池:专门用于处理批量操作请求
- index线程池:实际执行索引操作的线程池
当批量请求到达时,Elasticsearch会:
- 解析NDJSON内容
- 验证每个操作的合法性
- 将操作分发到对应分片
- 并行处理不同分片上的操作
- 等待所有操作完成
3 Bulk API的使用方法
3.1 基本请求格式
- Bulk API要求请求体采用特殊的NDJSON(Newline Delimited JSON)格式,每行一个JSON对象,连续两行表示一个操作:
action_and_meta_data\n
optional_source\n
action_and_meta_data\n
optional_source\n
...3.2 操作类型示例
- 索引文档(自动生成ID)
POST _bulk
{ "index" : { "_index" : "products", "_type" : "_doc" } }
{ "name" : "智能手机", "price" : 3999, "stock" : 100 }- 创建文档(指定ID)
POST _bulk
{ "create" : { "_index" : "products", "_type" : "_doc", "_id" : "101" } }
{ "name" : "笔记本电脑", "price" : 5999, "stock" : 50 }- 更新文档
POST _bulk
{ "update" : { "_index" : "products", "_type" : "_doc", "_id" : "101" } }
{ "doc" : { "price" : 5499 } }- 删除文档
POST _bulk
{ "delete" : { "_index" : "products", "_type" : "_doc", "_id" : "101" } }3.3 响应格式
- Bulk API的响应包含每个操作的结果:
{
"took": 30,
"errors": false,
"items": [
{
"index": {
"_index": "products",
"_type": "_doc",
"_id": "1",
"_version": 1,
"result": "created",
"status": 201
}
},
{
"update": {
"_index": "products",
"_type": "_doc",
"_id": "2",
"_version": 2,
"result": "updated",
"status": 200
}
}
]
}4 Bulk API的最佳实践
4.1 批量大小优化
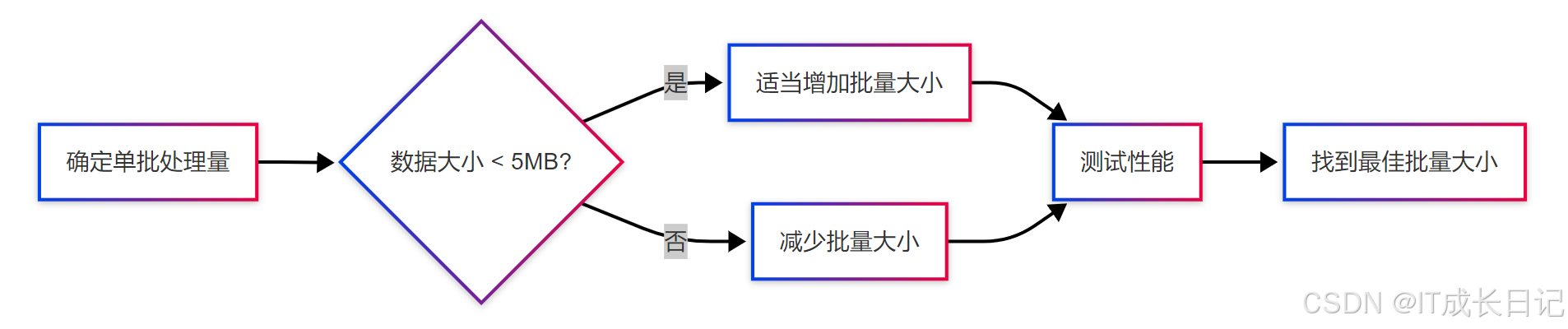
- 初始建议:从5-15MB的批量大小开始测试
- 逐步调整:增加批量直到性能不再提升或开始下降
- 监控指标:关注CPU、内存和IO使用情况
- 考虑因素:
- 文档平均大小
- 集群资源配置
- 网络带宽
4.2 错误处理策略
- 重试机制:对于暂时性错误(如网络问题)实现自动重试
- 部分失败处理:检查响应中的errors字段和每个item的状态
- 日志记录:记录失败的操作以便后续处理
- 回退策略:对于重要数据实现回退存储
4.3 性能调优技巧
客户端配置:
- 使用连接池
- 适当增加重试次数
- 设置合理的超时时间
服务端优化:
- 调整线程池大小
- 增加索引刷新间隔
- 暂时禁用副本
数据结构优化:
- 减少文档大小
- 避免嵌套过深
- 使用合适的数据类型
5 高级特性与注意事项
5.1 路由控制
- 在批量操作中可以为每个操作指定路由:
POST _bulk
{ "index" : { "_index" : "orders", "_type" : "_doc", "_id" : "1", "routing" : "user123" } }
{ "product": "手机", "user_id": "user123", "amount": 1 }5.2 版本控制
- 通过版本号实现乐观并发控制:
POST _bulk
{ "index" : { "_index" : "products", "_type" : "_doc", "_id" : "101", "version" : 2, "version_type" : "external" } }
{ "name" : "笔记本电脑", "price" : 5499, "stock" : 45 }5.3 超时与等待
- 可以设置超时参数控制请求行为:
POST _bulk?timeout=2m参数说明:
- timeout:等待分片响应的时间
- refresh:操作后是否立即刷新索引
- wait_for_active_shards:需要多少分片可用才执行
5.4 安全注意事项
- 请求大小限制:避免过大的请求导致内存问题
- 权限控制:确保客户端有批量操作的权限
- 敏感数据处理:避免在日志中记录敏感数据
- 限流保护:在高负载时实施客户端限流
6 常见问题解答
Q1: Bulk API有大小限制吗?
A: Elasticsearch默认限制HTTP请求大小为100MB,可通过http.max_content_length配置。但实际使用中建议保持5-15MB以获得最佳性能
Q2: 如何处理批量操作中的部分失败?
A: 检查响应中的errors字段和每个操作的status,可以:
- 记录失败操作
- 构建新的批量请求重试失败项
- 实现指数退避重试策略
Q3: Bulk API是原子的吗?
A: 在单个批量请求中,每个操作是独立执行的,不是事务性的。如果中间操作失败,已执行的操作不会回滚。但可以通过版本控制实现乐观锁
Q4: 如何监控批量操作性能?
A: 关键指标包括:
- 批量请求处理时间(took)
- 吞吐量(操作数/秒)
- 错误率
- 系统资源使用率(CPU、内存、IO)
7 总结
Elasticsearch的Bulk API是处理大量数据操作的高效工具,正确使用可以显著提高数据处理的效率和系统吞吐量。关键点包括:
- 使用正确的NDJSON格式构建请求
- 找到适合自己场景的最佳批量大小
- 实现健壮的错误处理和重试机制
- 监控性能并根据指标进行调优
- 理解底层原理以应对复杂场景




![Python[数据结构及算法 --- 栈]](https://i-blog.csdnimg.cn/direct/66963222e52a4079b22f98025e9543f1.png)