目录
- 1.摘要
- 2.粒子群算法PSO原理
- 3.改进策略
- 4.结果展示
- 5.参考文献
- 6.代码获取
- 7.算法辅导·应用定制·读者交流

1.摘要
能源数据的科学预测对于能源行业决策和国家经济发展具有重要意义,尤其是短期能源预测,其精度直接影响经济运行效率。为了更好地提高预测模型的精度,本文提出了一种自适应学习粒子群算法(AEPSO)用于优化灰色预测模型的参数,并通过引入正弦混沌机制、自适应引导觅食策略、随机维度学习策略以及自适应均值优化策略来提升原始算法的性能。
2.粒子群算法PSO原理
【智能算法】粒子群算法(PSO)原理及实现
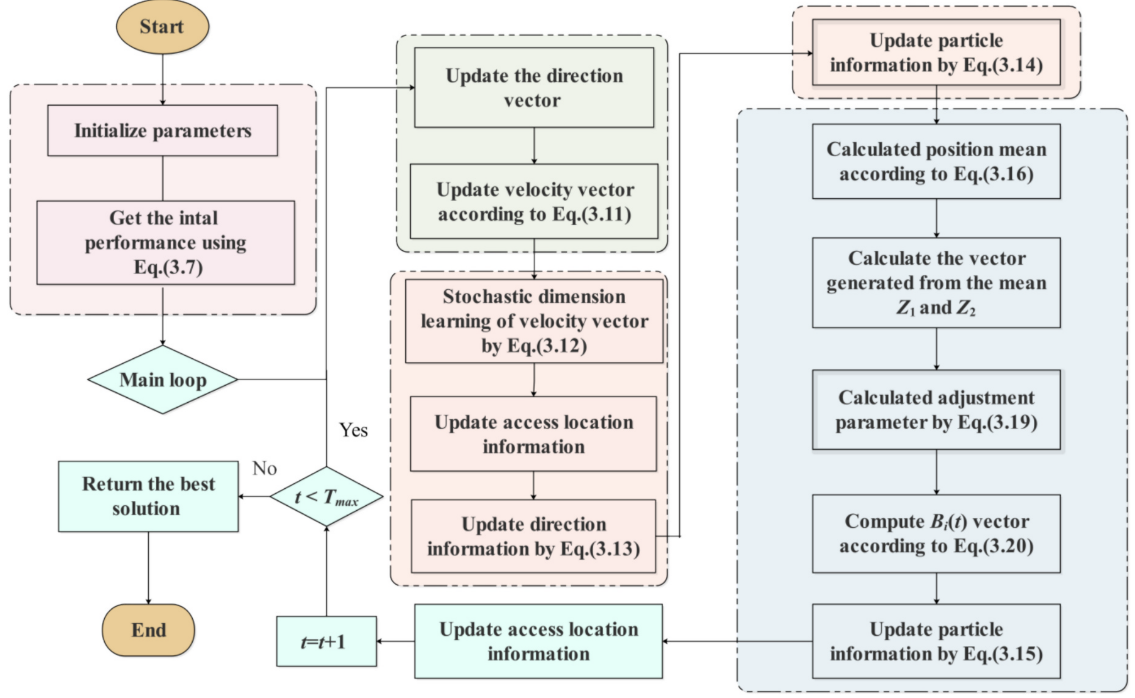
3.改进策略
自适应导引觅食策略
自适应引导觅食策略通过引入方向切换向量,构建了三种飞行方式:全方向飞行、对角飞行和轴向飞行。
-
轴向飞行表示个体可以沿任意坐标轴方向飞行;
-
对角飞行表示个体可以从一个矩形角落飞到另一个角落;
-
全方向飞行表示个体的飞行方向可以映射到所有坐标轴方向。
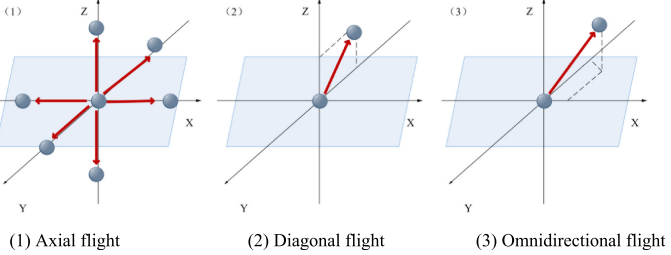
轴向飞行:
D
i
=
{
1
,
i
=
r
a
n
d
i
(
[
1
,
d
]
)
,
i
=
1
,
2
,
⋯
,
d
0
,
e
l
s
e
\boldsymbol{D}_i=\left\{ \begin{array} {cc}1, & i=randi([1,d]),i=1,2,\cdots,d \\ 0, & else \end{array}\right.
Di={1,0,i=randi([1,d]),i=1,2,⋯,delse
对角飞行:
D
i
=
{
1
,
i
=
P
(
i
)
,
j
∈
[
1
,
k
]
,
P
=
r
a
n
d
p
e
r
m
(
k
)
,
k
∈
[
2
,
[
r
1
∙
(
d
−
2
)
]
+
1
]
0
,
e
l
s
e
\boldsymbol{D}_i=\left\{ \begin{array} {cc}1, & i=P(i),j\in[1,k],P=randperm(k),k\in[2,[r_1\bullet(d-2)]+1] \\ 0, & else \end{array}\right.
Di={1,0,i=P(i),j∈[1,k],P=randperm(k),k∈[2,[r1∙(d−2)]+1]else
全方向飞行:
D
i
=
1
i
=
1
,
2
,
⋯
,
d
D_i=1i=1,2,\cdots,d
Di=1i=1,2,⋯,d
个体判断方向信息后更新速度:
V
i
(
t
+
1
)
=
w
∙
x
i
,
t
a
r
(
t
)
+
c
1
a
1
∙
D
∙
(
x
i
(
t
)
−
x
i
,
t
a
r
(
t
)
)
+
c
2
a
2
∙
(
x
i
(
t
)
−
x
i
n
d
e
x
(
t
)
)
\begin{aligned} V_{i}(t+1) & =w\bullet x_{i,tar}(t)+c_{1}a_{1}\bullet D\bullet\left(x_{i}(t)-x_{i,tar}(t)\right)+c_{2}a_{2} \\ & \bullet\left(x_{i}(t)-x_{index}(t)\right) \end{aligned}
Vi(t+1)=w∙xi,tar(t)+c1a1∙D∙(xi(t)−xi,tar(t))+c2a2∙(xi(t)−xindex(t))
随机维度学习策略
随机维度学习策略,使PSO不仅可以向全局最优个体学习,还可以从随机个体的部分维度中进行学习,从而增强搜索能力:
{
V
i
,
p
1
(
t
+
1
)
=
x
index
,
p
1
(
t
)
+
(
V
i
,
p
1
(
t
)
−
x
index
,
p
1
(
t
)
)
⋅
(
r
1
+
1
)
⋅
sin
(
r
2
⋅
360
)
V
i
,
p
2
(
t
+
1
)
=
x
index
,
p
2
(
t
)
+
(
V
i
,
p
2
(
t
)
−
x
index
,
p
2
(
t
)
)
⋅
(
r
1
+
1
)
⋅
cos
(
r
2
⋅
360
)
\begin{cases} V_{i,p_1}(t+1) = x_{\text{index},p_1}(t) + \left(V_{i,p_1}(t) - x_{\text{index},p_1}(t)\right) \cdot (r_1 + 1) \cdot \sin(r_2 \cdot 360) \\ V_{i,p_2}(t+1) = x_{\text{index},p_2}(t) + \left(V_{i,p_2}(t) - x_{\text{index},p_2}(t)\right) \cdot (r_1 + 1) \cdot \cos(r_2 \cdot 360) \end{cases}
{Vi,p1(t+1)=xindex,p1(t)+(Vi,p1(t)−xindex,p1(t))⋅(r1+1)⋅sin(r2⋅360)Vi,p2(t+1)=xindex,p2(t)+(Vi,p2(t)−xindex,p2(t))⋅(r1+1)⋅cos(r2⋅360)
在更新位置信息之前先更新飞行方向,以帮助个体能够在最有效的路径上找到食物,并更新方向信息:
D
i
(
t
+
1
)
=
D
i
(
t
)
+
(
−
P
+
2
∙
P
∙
r
a
n
d
(
1
,
D
i
m
)
)
∙
D
i
(
t
)
\boldsymbol{D}_i(t+1)=\boldsymbol{D}_i(t)+(-P+2\bullet P\bullet rand(1,Dim))\bullet\boldsymbol{D}_i(t)
Di(t+1)=Di(t)+(−P+2∙P∙rand(1,Dim))∙Di(t)
更新方向信息后,粒子的位置信息更新:
x
i
(
t
+
1
)
=
x
i
(
t
)
+
r
a
n
d
n
∙
x
i
(
t
)
∙
D
i
(
t
)
x_i(t+1)=x_i(t)+randn\bullet x_i(t)\bullet D_i(t)
xi(t+1)=xi(t)+randn∙xi(t)∙Di(t)
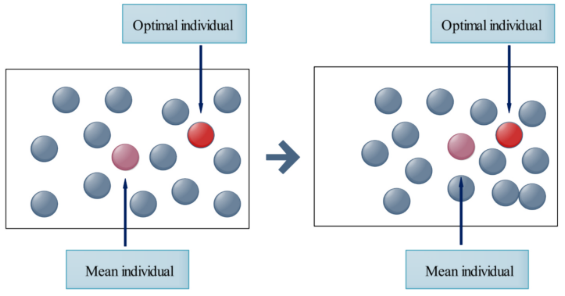
自适应均值优化策略
均值优化策略目标是缩小均值解与全局最优解之间的距离,使均值解在优化过程中持续向全局最优解靠近。
x
i
(
t
+
1
)
=
B
i
(
t
)
+
(
c
∙
z
1
+
(
1
−
c
)
∙
z
2
)
−
M
(
t
)
x_i(t+1)=B_i(t)+(c\bullet z_1+(1-c)\bullet z_2)-M(t)
xi(t+1)=Bi(t)+(c∙z1+(1−c)∙z2)−M(t)

4.结果展示
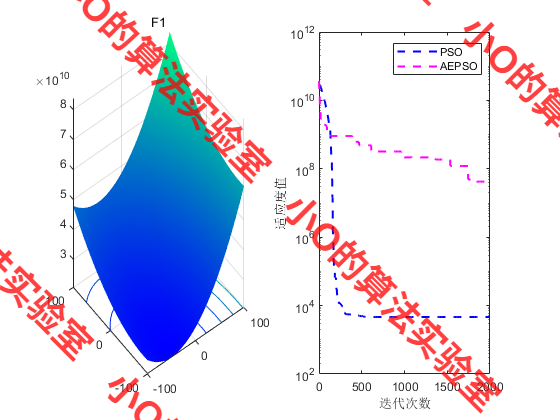
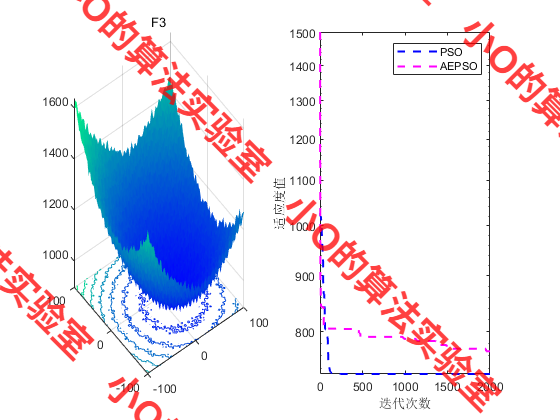
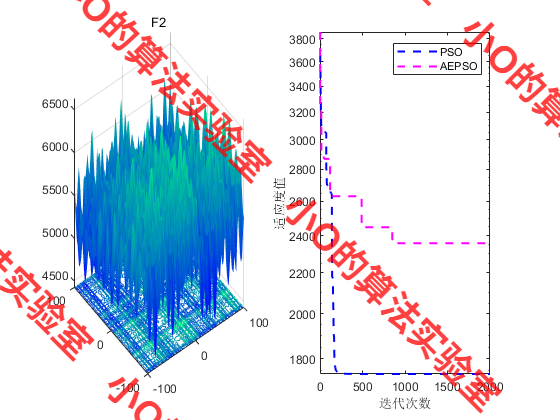
PS:效果不好🤣🤣🤣
5.参考文献
[1] Hu G, Wang S, Shu B, et al. AEPSO: An adaptive learning particle swarm optimization for solving the hyperparameters of dynamic periodic regulation grey model[J]. Expert Systems with Applications, 2025: 127578.
6.代码获取
xx