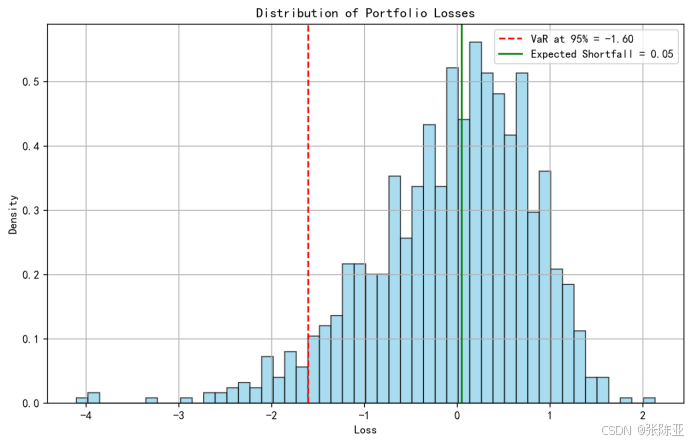
引言 ——
想象一台能瞬间读懂整本《战争与和平》、精准翻译俳句中的禅意、甚至为你的设计草图生成前端代码的机器——这一切并非科幻,而是过去七年AI领域最震撼的技术革命:Transformer架构创造的奇迹。
当谷歌在2017年揭开Transformer的神秘面纱时,它用“自注意力”这把钥匙,一举击碎了困扰AI数十年的长序列处理魔咒。从此,循环神经网络(RNN)的缓慢串行成为历史,卷积神经网络(CNN)的局部视野不再受限。Transformer如同为机器装上全局感知的超级大脑,让模型真正学会“联系上下文思考”,从ChatGPT的对话魔法到AlphaFold的蛋白质折叠突破,其影响力早已超越自然语言处理,重塑了整个AI疆域。
本文将带您穿透技术迷雾,从数学原理到结构设计,解析这个驱动当今所有大语言模型的“终极引擎”。无需高深数学背景,您将理解Transformer如何用三个核心革新(自注意力、并行计算、残差堆叠)重新定义人工智能的底层逻辑。
目录
引言 ——
概念 ——
编者概念解读tips ——》
核心数学原理 ——
结构原理 ——组件如何协同工作?
核心可变参数(超参数) ——
结束语 ——
概念 ——
Transformer 架构 是一种革命性的深度学习模型架构,于2017年由Google的研究者在论文《Attention Is All You Need》中提出。它彻底颠覆了自然语言处理(NLP)领域,并迅速扩展到计算机视觉(CV)、语音识别、生成式AI(如ChatGPT)等多个领域。
Transformer 的核心思想是:完全摒弃传统的循环神经网络(RNN)和卷积神经网络(CNN),仅依赖“自注意力机制”来捕捉输入序列中元素之间的全局依赖关系,并实现高效的并行计算。
Question:
那么!!transformer架构是一个数学模型?还是一个大模型训练逻辑?还是什么?
Transformer 既不仅仅是一个纯粹的数学模型,也不仅仅是一个大模型训练逻辑。它更准确地说是一个深度学习模型架构的设计范式。
我们可以从不同层次来理解 Transformer:
-
核心是一个创新的架构设计理念:
-
Transformer 提出了一种全新的、基于自注意力机制来构建神经网络的方式。
-
它定义了模型的核心组成部分(如自注意力层、多头注意力、位置编码、残差连接、层归一化、Encoder-Decoder结构等)以及这些组件之间如何连接和交互。
-
这就像建筑师设计了一套创新的房屋建造蓝图,规定了使用什么新型材料(自注意力)、如何布局房间(Encoder/Decoder层)、如何连接水电(残差连接/层归一化)等。
-
-
包含特定的数学模型:
-
这个架构的核心依赖于一个强大的数学模型:自注意力机制。其计算过程(Query, Key, Value 的点积、缩放、Softmax、加权求和)是一个精确定义的数学公式 (
Attention(Q, K, V) = softmax(QK^T / √d_k) V)。 -
位置编码(如正弦/余弦函数)也是一个数学模型。
-
前馈神经网络层、层归一化、Softmax 输出层等也都是标准的数学运算模块。
-
所以,数学模型是构建这个架构的“砖块”和“粘合剂”。
-
-
定义了模型的训练和推理逻辑:
-
Transformer 架构的设计(特别是其并行性)深刻影响了模型的训练逻辑:
-
并行训练: 由于摒弃了 RNN 的顺序依赖,整个序列可以同时输入计算,极大提升了 GPU/TPU 等硬件的利用效率,这是其训练逻辑的关键优势。
-
优化目标: 通常使用交叉熵损失函数进行监督学习(如机器翻译的单词预测)。
-
训练技巧: 架构本身的设计(如残差连接、层归一化)也使得训练更深更大的网络成为可能,并促进了诸如 Adam 优化器、学习率预热、标签平滑等训练技巧的使用。
-
-
它也定义了推理(预测)逻辑:
-
自回归生成: 在 Decoder-only 模型(如 GPT)或 Decoder 部分,通常采用自回归方式,逐个生成输出 token。
-
注意力计算: 在推理时,模型需要计算输入序列内部(自注意力)以及输入与输出之间(编码器-解码器注意力)的关联权重。
-
-
-
是构建具体模型(包括大模型)的基础框架:
-
Transformer 架构本身是一个通用模板。
-
研究人员和工程师可以基于这个模板,通过以下方式构建出具体的、或大或小的模型实例:
-
配置超参数: 决定 Encoder/Decoder 的层数 (
N)、注意力头的数量、隐藏层的维度 (d_model)、前馈层内部维度、词嵌入大小等。选择变体: 使用完整的 Encoder-Decoder(如原始 Transformer、T5),或仅用 Encoder(如 BERT, RoBERTa),或仅用 Decoder(如 GPT 系列, LLaMA)。
应用于不同数据: 将输入数据(文本、图像块、音频片段)转换成序列形式,并嵌入到向量空间。
加载海量数据训练: 当使用巨大的数据集(如整个互联网文本)和庞大的计算资源训练一个配置非常大的 Transformer 模型时,就诞生了大语言模型。
编者概念解读tips ——》
-
Transformer 架构: 就像一套创新的汽车设计图纸。
-
它规定了核心原理(燃油发动机/自注意力)、底盘结构(底盘/Encoder-Decoder框架)、传动系统(传动轴/残差连接)等。
-
它不是一辆具体的汽车(模型实例),也不是发动机的物理公式(数学模型),也不是驾驶手册(训练逻辑),但它包含了所有这些元素的设计理念和实现方案。
-
-
数学模型 (如自注意力): 是图纸中描述的发动机工作原理(内燃循环公式)。
-
训练逻辑: 是按照图纸制造和调试汽车发动机的工艺流程(强调并行化装配线)。
-
具体的 Transformer 模型 (如 BERT, GPT-3): 是按照这套图纸实际制造出来的、不同型号和排量的汽车。其中 GPT-3 就是一辆超级跑车(大模型)。
-
大模型训练: 是按照图纸,在巨型工厂里,用海量原材料(数据)和强大设备(算力),制造超级跑车(如 GPT-3)的过程。
因此,最准确的说法是:Transformer 是一种革命性的深度学习模型架构设计范式。 它提供了一套基于自注意力的核心组件和连接方式,用于构建能够高效处理序列数据的神经网络。基于这个范式,可以设计出不同规模、不同用途的具体模型,而大语言模型(LLM)就是其中最引人注目的成果之一。它包含了支撑其运行的数学模型,并深刻影响了模型的训练和推理逻辑。
核心数学原理 ——
Transformer 的数学基础主要围绕 自注意力机制 (Self-Attention) 展开:
-
自注意力 (Self-Attention)
-
输入表示:每个输入词转换为向量
X ∈ R^(d_model)。 -
线性变换:生成 Query、Key、Value 矩阵:
-
Q = X · W_Q(W_Q ∈ R^(d_model × d_k)) -
K = X · W_K(W_K ∈ R^(d_model × d_k)) -
V = X · W_V(W_V ∈ R^(d_model × d_v))
-
-
注意力得分:计算词与词之间的相关性权重:
-
Attention(Q, K, V) = softmax( QK^T / √d_k ) · V -
缩放点积:
√d_k防止梯度消失(点积值过大导致 softmax 饱和)。
-
-
物理意义:模型动态学习每个词应“关注”序列中哪些词,并加权融合其信息。
-
-
多头注意力 (Multi-Head Attention)
-
并行使用
h组独立的 Q/K/V 线性变换,捕获不同子空间的关系:-
MultiHead(Q, K, V) = Concat(head_1, ..., head_h) · W_O -
其中
head_i = Attention(Q · W_Q_i, K · W_K_i, V · W_V_i)
-
-
核心价值:增强模型捕捉多样上下文关系的能力(如语法结构、语义关联)。
-
-
位置编码 (Positional Encoding)
-
问题:自注意力本身不感知词序。
-
解决方案:为每个位置
pos生成编码向量PE(pos) ∈ R^(d_model):-
正弦/余弦函数(原始论文):
PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right)
PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right)
-
-
可学习位置嵌入(如 BERT):将位置索引映射为向量。
-
-
层归一化 (Layer Normalization) 与残差连接 (Residual Connection)
-
残差连接:
Output = LayerNorm(X + Sublayer(X)) -
作用:缓解梯度消失,加速训练收敛。
-
结构原理 ——组件如何协同工作?
Transformer 是一个模块化堆叠的架构,核心组件如下:
| 组件 | 功能 | 结构特点 |
|---|---|---|
| Encoder 栈 | 将输入序列编码为上下文感知的表示 | 由 N 个相同层堆叠而成 |
| Decoder 栈 | 基于 Encoder 输出和已生成部分,预测下一个词 | 由 N 个相同层堆叠,含 掩码自注意力 |
| Encoder Layer | 包含: 1. 多头自注意力层 2. 前馈神经网络层 (FFN) | 每层后接 残差连接 + 层归一化 |
| Decoder Layer | 包含: 1. 掩码多头自注意力层 2. 编码器-解码器注意力层 3. FFN | 掩码确保预测时仅依赖已生成词 |
| 位置编码 | 为输入注入位置信息 | 加在输入嵌入上 |
| 输出层 | 线性变换 + Softmax,生成词概率分布 | Linear(d_model → vocab_size) + Softmax |
关键协作逻辑:
-
Encoder:逐层提炼输入序列的全局表示。
-
Decoder:
-
掩码自注意力:聚焦已生成输出序列。
-
编码器-解码器注意力:基于当前 Decoder 状态查询 Encoder 输出的关键信息(类似对齐机制)。
-
FFN:非线性变换特征。
-
核心可变参数(超参数) ——
这些参数决定了模型规模、能力和计算效率:
| 参数类型 | 符号 | 含义 | 典型值示例 | 影响 |
|---|---|---|---|---|
| 模型深度 | N | Encoder/Decoder 的层数 | 6 (原始), 12 (BERT), 96 (GPT-3) | 层数↑ → 模型容量↑,训练难度↑ |
| 隐藏层维度 | d_model | 输入向量、位置编码、注意力输出的维度 | 512 (原始), 768 (BERT), 12288 (GPT-3) | 维度↑ → 表征能力↑,计算量↑² |
| 注意力头数 | h | 多头注意力的并行头数量 | 8 (原始), 12 (BERT), 96 (GPT-3) | 头数↑ → 多视角建模能力↑,计算量线性增长 |
| Key/Query 维度 | d_k | 每个注意力头的 Key/Query 向量维度 | d_k = d_model / h (常用) | 维度↓ → 计算量↓,但需平衡信息容量 |
| Value 维度 | d_v | 每个注意力头的 Value 向量维度 | 通常与 d_k 相同 | 同上 |
| 前馈网络维度 | d_ff | 前馈神经网络中间层的维度(两层线性变换) | 4 * d_model (常用) | 维度↑ → 非线性能力↑,参数量占比大(如 d_model=768 时 d_ff=3072) |
| 词表大小 | vocab_size | 输入/输出词表的大小 | 3万-50万(依任务而定) | 影响嵌入层参数量(d_model × vocab_size) |
| 位置编码类型 | - | 固定(正弦) vs 可学习 | BERT/GPT 多用可学习位置嵌入 | 可学习嵌入灵活性更高 |
结束语 ——
当我们回顾Transformer的发展轨迹,会发现它的本质是一场关于“高效理解关联性”的伟大实验。从《Attention Is All You Need》论文中优雅的Encoder-Decoder设计,到如今支撑万亿参数大模型的Decoder-only巨兽;从最初512词的限制,到FlashAttention技术突破的百万级上下文窗口——Transformer的进化史,正是人类对机器认知能力边界的一次次冲锋。
但Transformer的传奇远未终结:
-
在科学前沿,它正解码蛋白质语言、模拟量子系统,成为基础科学的新显微镜;
-
在产业落地,轻量化变体(如MobileViT)已嵌入手机芯片,让实时图像翻译触手可及;
-
在伦理深水区,我们更需思考:当模型能关联所有人类知识时,如何避免偏见放大与创造性枯竭?
理解Transformer,不仅是掌握当下AI的密码,更是预见人机共生未来的关键透镜。正如电力革命不止于电灯,Transformer的终极意义或许在于:它让我们第一次拥有了接近人类认知效率的通用关联引擎。下一次技术奇点,也许就藏在某个注意力矩阵的权重之中。