n8n 的 HTTP Request + HTML 节点组合是个实用又高效的工具。这篇文章就带你一步步搞懂如何用它们提取静态网页内容,重点解析 HTML 节点参数和 CSS 选择器,让你轻松上手 。
一、整体流程概览
我们的目标是从静态网页中提取特定内容,流程分两步:
- HTTP Request 节点:负责获取网页的完整 HTML 源码,相当于模拟浏览器访问网页并拿到原始内容。
- HTML 节点:对获取到的 HTML 源码进行解析,通过 CSS 选择器精准提取我们需要的内容,比如标题、正文、图片链接等。
二、HTTP Request 节点使用(简单铺垫)
在 n8n 里,添加 HTTP Request 节点后,只需填入目标网页的 URL,请求方法选 GET ,就能获取到网页的 HTML 数据啦。获取到的数据会以 JSON 形式输出,后续 HTML 节点要基于这些数据进一步处理,这里重点在后面的 HTML 节点,所以这部分简单设置即可 。
三、HTML 节点深度解析
(一)参数配置核心逻辑
HTML 节点的作用是从 HTTP Request 拿到的 HTML 内容里“挑出”我们想要的部分,关键就在参数设置,下面逐个说:
- Source Data:选
JSON,因为 HTTP Request 节点输出的是 JSON 格式数据,里面的data字段存着网页 HTML 源码。 - JSON Property:填
data,告诉 HTML 节点从 JSON 数据的data字段里取 HTML 内容来解析 。
(二)Extraction Values 参数详解(重点!)
这部分是提取内容的关键配置,包含 Key、CSS Selector、Return Value 等参数,结合实际例子讲:
1. Key:提取结果的“标识名”
你可以把它理解成给提取出来的内容起个变量名,方便后续节点使用。比如要提取文章标题,Key 就填 article_title ;提取正文,就填 article_content ,名字自己定,语义化、好识别就行 。
2. CSS Selector:精准定位元素的“地图”
这是前端选元素的语法,但别慌,后端同学记住核心规则也能轻松用:
.(句点):匹配 HTML 元素的class属性。比如网页里有<h1 class="title">文章标题</h1>,要选这个h1,CSS 选择器就填.title,意思是“找所有 class 为 title 的元素” 。#(井号):匹配 HTML 元素的id属性。要是有<div id="content">正文内容</div>,选它就用#content,代表“找 id 为 content 的元素” 。- 层级选择(后代、直接子元素):
- 后代选择(空格):比如网页结构是
想选到最里层的<div id="title"> <div class="article-title"> <h1 class="title">用完的票根不要扔 小小票根帮你玩转整座城!</h1> </div> </div>h1,可以用#title .title(意思是“在 id 为 title 的元素内部,找所有 class 为 title 的元素” ,这里的空格表示后代关系,不管中间隔多少层嵌套 )。 - 直接子元素(
>):如果想严格找直接子元素,比如<div id="parent"> <div class="child">...</div> </div>,选直接子元素用#parent > .child,但实际提取网页内容时,后代选择(空格)用得更多,没那么严格限制层级 。
- 后代选择(空格):比如网页结构是
举个完整例子,假设网页结构如下(静态 HTML ,内容明确):
<!DOCTYPE html>
<html>
<body>
<div id="title">
<div class="article-title">
<h1 class="title">这是文章标题</h1>
</div>
<div class="article-src-time">
<span class="src">2025-06-05 11:07 来源:测试网</span>
</div>
</div>
<div id="content" class="article-content">
<p class="section txt">这是正文第一段</p>
<p class="section txt">这是正文第二段</p>
</div>
</body>
</html>
- 提取标题(
h1里的文本):Key填article_titleCSS Selector填#title .title(或者更简单的.title,只要页面里 class 为 title 的就这一个h1)Return Value选Text(只要文本内容)
- 提取正文(所有
p标签内容):Key填article_contentCSS Selector填.section.txt(找所有 class 同时包含 section 和 txt 的p元素 )Return Value选Text,要是想保留 HTML 标签结构,就选HTML,根据需求来 。
3. Return Value:决定提取内容的形式
Text:只提取元素里的文本内容,会去掉 HTML 标签。比如<p class="txt">正文内容</p>,选Text就拿到“正文内容” 。HTML:提取元素及内部完整的 HTML 结构。还是上面的p标签,选HTML就拿到<p class="txt">正文内容</p>。Attribute:提取元素的某个属性值,比如想拿图片的src属性,CSS 选择器选img,Return Value选Attribute,再在额外参数里填src,就会提取出图片链接 。
4. Return Array:处理多个匹配结果
如果 CSS 选择器匹配到多个元素(比如页面里有多个 p 标签都符合 .section.txt ),把 Return Array 设为 ON ,提取结果就会以数组形式输出,方便后续遍历处理;设为 OFF ,则只返回第一个匹配到的元素内容 。
四、实际操作演示(闭环例子)
(一)准备工作
找一个静态网页(比如自己本地写个简单 HTML 文件,或者找个公开的静态内容网页,像上面例子里的结构 ),用 HTTP Request 节点获取它的 HTML 内容 。
(二)HTML 节点配置
- 提取标题:
Key:article_titleCSS Selector:#title .titleReturn Value:TextReturn Array:OFF(因为标题一般就一个 )
- 提取正文段落:
Key:article_paragraphsCSS Selector:.section.txtReturn Value:TextReturn Array:ON(因为有多个段落 )
(三)运行与验证
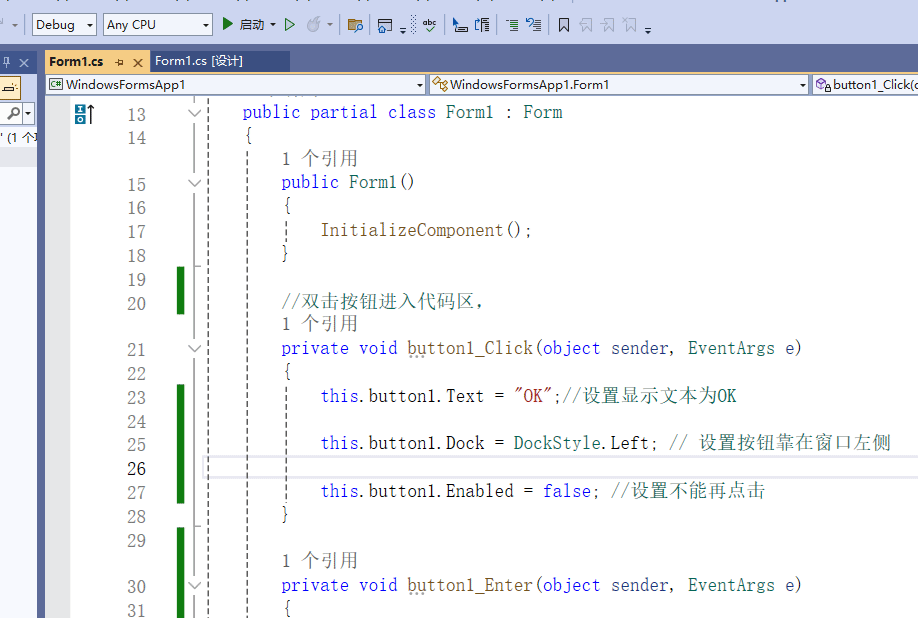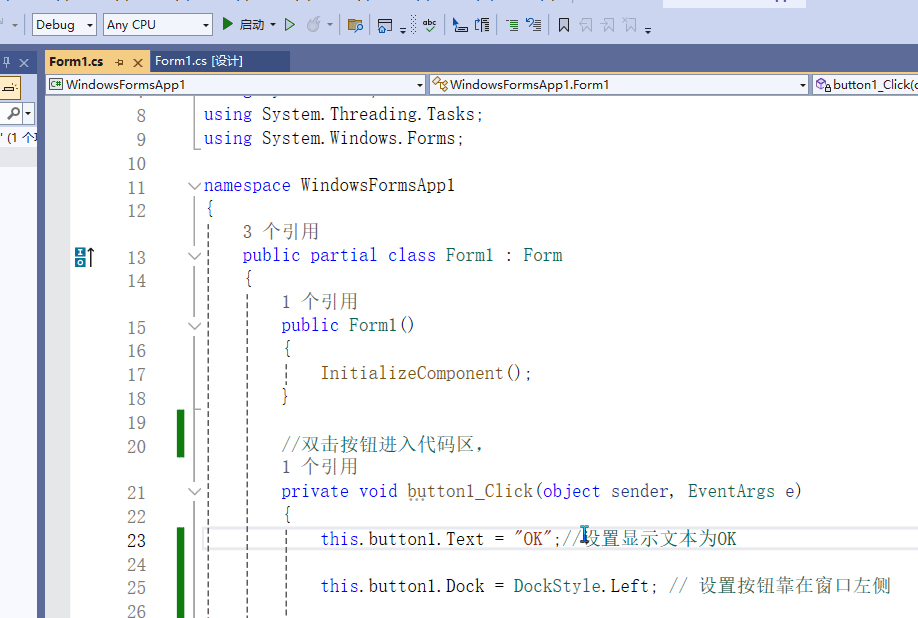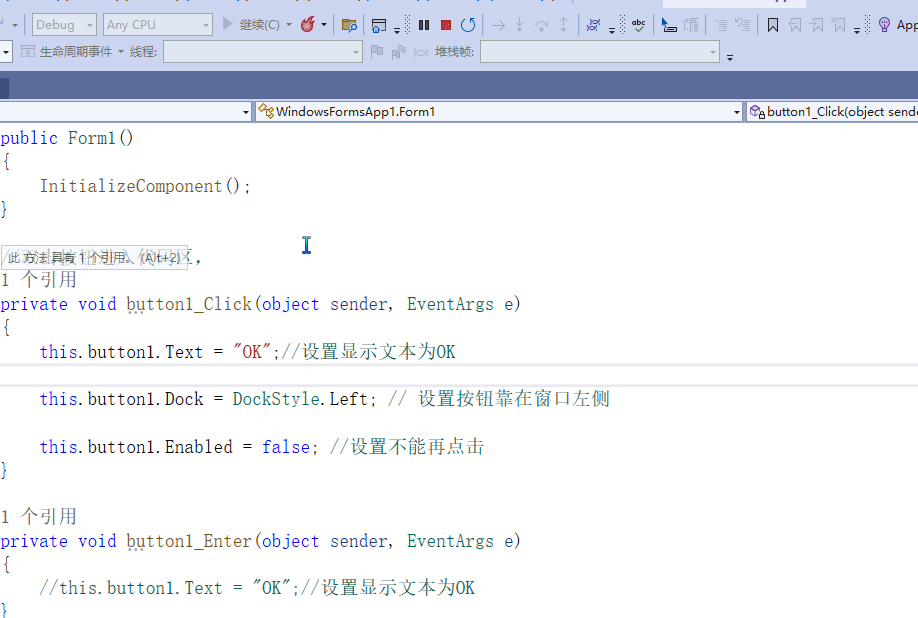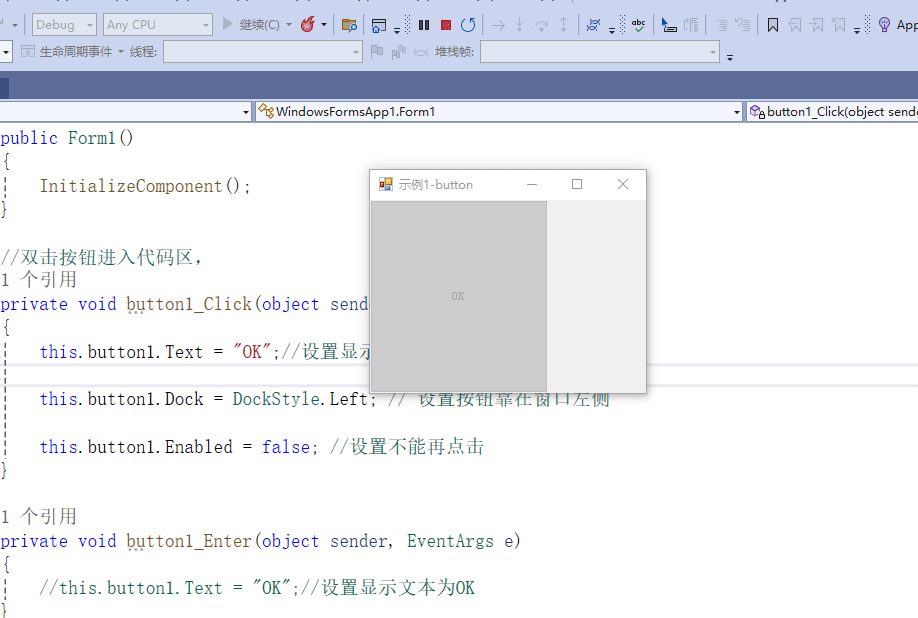
把 HTTP Request 节点和 HTML 节点连起来,执行工作流。在 HTML 节点输出里,就能看到提取的标题文本和正文段落数组啦,形成一个从“获取网页内容”到“提取指定内容”的完整闭环 。
五、常见问题 & 避坑指南
- CSS 选择器不生效:
- 先去浏览器开发者工具(按 F12 )里,用“元素”面板的搜索框,把 CSS 选择器粘进去,看看能不能选中目标元素。能选中,n8n 里才可能提取到;选不中,就调整选择器语法 。
- 注意区分
class和id,别把.和#用混,比如该用#content选 id 为 content 的元素,结果用成.content,就可能选不到 。
- 提取内容为空:
- 检查
Source Data和JSON Property是否正确,确保从 HTTP Request 节点拿到了 HTML 内容 。 - 看看网页是不是动态加载内容(不过咱们这篇讲静态网页,动态的后续再拓展 ),静态网页的话,内容肯定在初始 HTML 里 。
- 检查
掌握 n8n 里 HTTP Request + HTML 节点提取静态网页内容的方法,能轻松应对一些轻量的网页数据采集需求。重点记住 HTML 节点里 CSS Selector 的 . 和 # 用法,以及 Key、Return Value 这些参数的配置逻辑,多实操几次,就能熟练运用啦,遇到问题多借助浏览器开发者工具排查,问题就迎刃而解咯 !