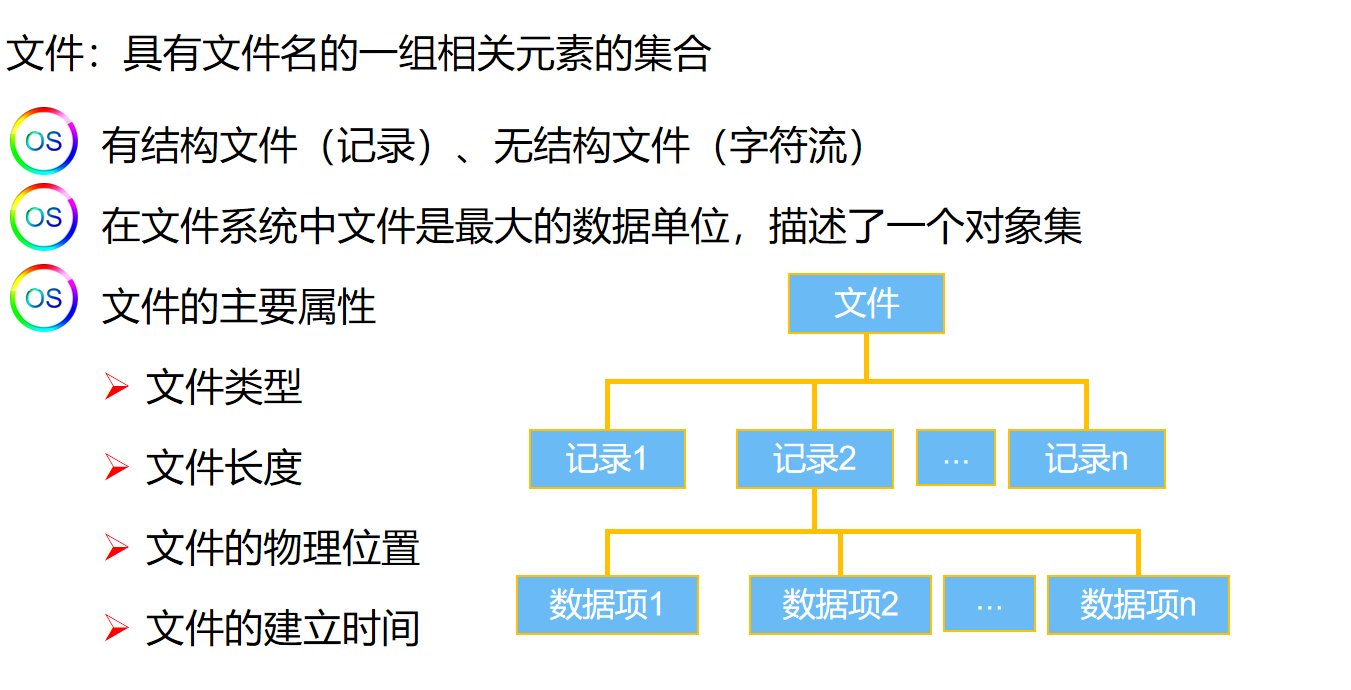
在人工智能领域,卷积神经网络(Convolutional Neural Network, CNN)无疑是计算机视觉领域的璀璨明珠。从 1998 年 Yann LeCun 提出 LeNet-5 实现手写数字识别,到 2012 年 AlexNet 在 ImageNet 大赛上创造历史性突破,CNN 彻底改变了图像处理的范式。如今,无论是手机相册的人脸识别、自动驾驶的实时路况分析,还是医疗影像的肿瘤检测,CNN 都在其中扮演着核心角色。本文将从基础原理出发,逐步解析这个「图像智能处理器」的工作机制。
二、核心概念:为什么 CNN 适合图像处理?
(一)传统神经网络的困境
当我们尝试用全连接神经网络处理图像时,会遇到维度爆炸问题。以 32x32 像素的彩色图像为例,输入层神经元数量达到 32x32x3=3072 个,第一层若有 1000 个神经元,仅输入层到第一层的连接就超过 300 万条。这种指数级增长的参数不仅消耗海量计算资源,还极易导致过拟合。
(二)CNN 的三大核心优势
- 局部感知(Local Perception):人类视觉系统在识别物体时,会先关注边缘、纹理等局部特征。CNN 通过卷积核(Kernel)模拟这一机制,每个神经元仅与输入图像的局部区域相连(如 5x5 的窗口),专注于提取局部空间特征。
- 权值共享(Weight Sharing):同一个卷积核在图像不同位置滑动时,权值保持不变。这意味着提取边缘特征的卷积核可在整幅图像中重复使用,将参数数量从 O (N²) 降至 O (K²),其中 K 为卷积核尺寸。
- 层次化特征提取:通过多层卷积与池化的组合,CNN 能够实现从低层特征(边缘、角点)到中层特征(纹理、形状)再到高层语义特征(物体部件、完整物体)的渐进式抽象。
三、网络架构:解构 CNN 的核心组件
(一)卷积层(Convolutional Layer):特征提取的引擎
1. 卷积运算的数学本质
给定输入矩阵 X 和卷积核 K,卷积运算可表示为:
Y(i,j)=m=0∑M−1n=0∑N−1X(i+m,j+n)K(m,n)
其中 M、N 为卷积核尺寸,Y 为输出特征图。实际应用中常使用互相关运算(Cross-correlation)替代严格卷积,两者区别仅在于卷积核是否翻转。
2. 关键超参数解析
- 填充(Padding):分为「Valid」(不填充)和「Same」(填充使输出尺寸不变),计算公式为:填充像素数 = floor ((K-1)/2)
- 步幅(Stride):控制卷积核滑动步长,当输入尺寸为 W,卷积核 K,步幅 S,填充 P 时,输出尺寸 H 为:
H=⌊(W−K+2P)/S⌋+1
- 多通道处理:对于彩色图像,每个卷积核包含与输入通道数相同的三维矩阵(如 3x3x3),输出通道数由卷积核数量决定。
3. 可视化案例:边缘检测
使用竖直边缘检测核
111000−1−1−1
对灰度图像进行卷积,输出特征图中竖直边缘区域将呈现高响应值。
(二)池化层(Pooling Layer):特征的精简与抽象
1. 核心作用
- 降低特征图维度,减少计算量
- 提供平移不变性,增强鲁棒性
- 抑制噪声,突出主要特征
2. 主流池化方法
| 类型 | 操作方式 | 应用场景 |
| 最大池化 | 取窗口内最大值 | 保留显著特征 |
| 平均池化 | 取窗口内平均值 | 保留整体统计特性 |
| 随机池化 | 按概率选取窗口内元素 | 增强模型泛化能力 |
3. 尺寸变化规律
池化层通常采用 2x2 窗口,步幅 2,输出尺寸为输入的 1/2,如 16x16 特征图经池化后变为 8x8。
(三)全连接层(Fully Connected Layer):从特征到决策的桥梁
1. 结构特点
- 前向传播时将多维特征图展平为一维向量
- 反向传播时负责将分类误差传递到前层
- 典型案例:AlexNet 最后三层全连接层参数占比超过 90%
2. 改进方案
- 使用全局平均池化(Global Average Pooling)替代全连接层,可减少 90% 以上参数(如 GoogLeNet)
- 引入 Dropout 技术随机断开连接,缓解过拟合问题
(四)激活函数层(Activation Layer):赋予网络非线性能力
| 函数 | 公式 | 优势 | 局限性 |
| Sigmoid | 1/(1+e^-x) | 输出 0-1 概率值 | 梯度消失、饱和问题 |
| Tanh | (e^x - e^-x)/(e^x + e^-x) | 输出 - 1~1,中心对称 | 仍存在梯度消失 |
| ReLU | max(0, x) | 缓解梯度消失、计算快 | 神经元死亡问题 |
| Leaky ReLU | max(αx, x) (α=0.01) | 解决负区间零梯度问题 | 超参数 α 需手动调整 |
四、工作流程:图像特征的渐进式抽象过程
(一)输入层(Input Layer)
- 接收原始图像数据,通常进行归一化处理(如减去均值、除以标准差)
- 尺寸规范:常见 224x224(VGG)、299x299(Inception)、32x32(CIFAR-10)
(二)特征提取阶段(多层卷积 + 池化)
案例:手写数字识别(LeNet-5 架构)
- 第 1 层:6 个 5x5 卷积核,输出 6 个 28x28 特征图(输入 32x32,Padding=2,Stride=1)
- 第 2 层:2x2 平均池化,输出 6 个 14x14 特征图
- 第 3 层:16 个 5x5 卷积核,输出 16 个 10x10 特征图(无 Padding,Stride=1)
- 第 4 层:2x2 平均池化,输出 16 个 5x5 特征图
(三)分类决策阶段(全连接 + Softmax)
- 将最后一层特征图展平为 16x5x5=400 维向量
- 经过两层全连接(400→120→84),最终通过 Softmax 输出 10 类概率分布
(四)特征可视化验证
通过反卷积网络(Deconvolution Network)可将高层特征映射回像素空间,直观展示不同层次的关注点:
- 低层特征:边缘、线条等基础视觉元素
- 中层特征:数字的拐角、圆弧等部件
- 高层特征:完整数字的整体形状
五、关键技术:提升 CNN 性能的实用技巧
(一)数据增强(Data Augmentation)
通过对训练数据进行变换生成新样本,缓解数据不足问题:
- 几何变换:旋转、翻转、缩放、裁剪
- 颜色变换:亮度、对比度、饱和度调整
- 噪声注入:高斯噪声、椒盐噪声
- 典型案例:AlexNet 对训练图像进行 224x224 随机裁剪,数据量扩大 2048 倍
(二)正则化技术
- L2 正则化:在损失函数中添加权重平方和惩罚项,防止参数过大:
L=Ldata+λ∑∣∣w∣∣2
- Dropout:训练时以一定概率(如 0.5)随机关闭神经元,测试时恢复权重:
wtest=wtrain×(1−p)
- Batch Normalization(BN):
- 对每个批次数据进行归一化:
x^=Var[x]+ϵx−E[x]
- 引入可学习参数 γ 和 β 恢复网络表达能力
- 优势:加速收敛、缓解梯度消失、允许更高学习率
(三)优化算法演进
| 算法 | 核心思想 | 优势 | 适用场景 |
| SGD | 梯度下降 | 简单直观 | 大规模数据集 |
| Momentum | 引入动量项加速收敛 | 逃离局部最优 | 非凸优化问题 |
| RMSprop | 自适应调整学习率 | 处理稀疏梯度 | 循环神经网络 |
| Adam | 结合动量和 RMSprop | 综合性能最优 | 大多数场景默认选择 |
六、经典模型:从 LeNet 到 Swin Transformer 的进化之路
(一)奠基之作:LeNet-5(1998)
- 首个成功应用的 CNN 架构
- 核心贡献:证明深度卷积网络的有效性
- 架构:2 卷积层 + 2 池化层 + 3 全连接层
- 应用:美国银行支票手写数字识别(准确率 99.2%)
(二)突破之作:AlexNet(2012)
- ImageNet 大赛冠军(Top-5 错误率 15.3% vs 上届 26.2%)
- 关键创新:
- 使用 ReLU 激活函数替代 Sigmoid
- 引入 Dropout 防止过拟合
- 双 GPU 并行训练加速
- 局部响应归一化(LRN)
(三)深度探索:VGGNet(2014)
- 证明增加网络深度可提升性能(16/19 层)
- 统一使用 3x3 卷积核(堆叠两层等效 5x5,三层等效 7x7)
- 缺点:参数数量巨大(16 层模型 1.38 亿参数)
(四)结构创新:GoogLeNet(2014)
- 引入 Inception 模块:并行使用不同尺寸卷积核(1x1, 3x3, 5x5)和池化
- 首次使用全局平均池化替代全连接层
- 参数数量比 AlexNet 减少 12 倍(680 万 vs 6000 万)
(五)残差学习:ResNet(2015)
- 解决深度网络退化问题(训练误差随层数增加反而上升)
- 核心创新:残差块(Residual Block)
y=F(x,{Wi})+x
- 实现 152 层超深网络(ImageNet Top-5 错误率 3.57%)
- 衍生变体:ResNeXt(分组卷积)、Wide ResNet(增加宽度)
(六)最新进展:Swin Transformer(2021)
- 融合 Transformer 架构与 CNN 优势
- 采用分层窗口注意力机制
- 在多个视觉任务(分类、检测、分割)刷新 SOTA
- 证明 ViT(Vision Transformer)在图像领域的有效性
七、应用实践:CNN 的多维落地场景
(一)图像分类(Image Classification)
- 工业质检:手机外壳缺陷检测(准确率 99.8%)
- 农业监测:农作物病虫害识别(支持 50 + 种类)
- 典型工具:TensorFlow Hub 预训练模型迁移学习
(二)目标检测(Object Detection)
- 两阶段算法:Faster R-CNN(区域建议 + 分类回归)
- 一阶段算法:YOLO(You Only Look Once)系列(实时性优势)
- 应用案例:自动驾驶车辆检测(延迟 <50ms,准确率> 95%)
(三)语义分割(Semantic Segmentation)
- 经典模型:U-Net(医学图像分割)、DeepLab(空洞卷积)
- 农业应用:无人机农田作物与杂草分割
- 评价指标:交并比(IoU)、像素准确率(PA)
(四)图像生成(Image Generation)
- GAN(生成对抗网络):通过 CNN 生成以假乱真的图像
- 应用场景:艺术创作、虚拟试穿、数据增强
- 典型案例:英伟达 StyleGAN 生成高分辨率人脸图像(1024x1024)
八、挑战与未来:CNN 的进化方向
(一)现存挑战
- 计算资源需求:训练 ResNet-50 需数百 GB 显存,限制边缘设备应用
- 模型解释性:深层网络成为「黑箱」,医疗等领域需可解释 AI
- 小样本学习:依赖大规模标注数据,现实场景数据获取困难
- 平移不变性局限:对全局结构建模能力弱(如文字识别顺序信息)
(二)前沿方向
- 轻量化模型:MobileNet(深度可分离卷积)、ShuffleNet(通道洗牌)
- 跨模态融合:结合自然语言处理(如 CLIP 模型图文联合训练)
- 自监督学习:利用无标注数据预训练(SimCLR、MoCo)
- 神经架构搜索(NAS):自动化设计最优网络结构
- 量子 CNN:探索量子计算加速卷积运算的可能性
(三)开发者建议
- 入门阶段:从 MNIST 数据集开始,复现 LeNet-5 实现
- 进阶实践:使用 Keras/TensorFlow 构建 CIFAR-10 分类器,尝试数据增强
- 研究方向:关注 CVPR、ICCV 等顶会最新成果,探索小样本学习场景
九、结语:开启视觉智能的新篇章
卷积神经网络的发展历程,是人类对视觉认知规律不断模仿和超越的过程。从最初的手写数字识别到如今的通用视觉任务,CNN 始终站在技术变革的前沿。随着 Transformer、自监督学习等新技术的融合,视觉智能正迈向更广阔的空间。对于开发者而言,掌握 CNN 的核心原理不仅是进入计算机视觉领域的钥匙,更是理解深度学习本质的重要窗口。让我们保持对技术的好奇心,共同见证智能视觉时代的更多可能。
附录:关键资源推荐
- 经典教材:《深度学习》(花书)第 9 章
- 在线课程:Coursera《Convolutional Neural Networks》
- 开源框架:PyTorch/TensorFlow 官方 CNN 教程
- 数据集:ImageNet、COCO、VOC2007
- 可视化工具:TensorBoard、CNN Visualization Zoo