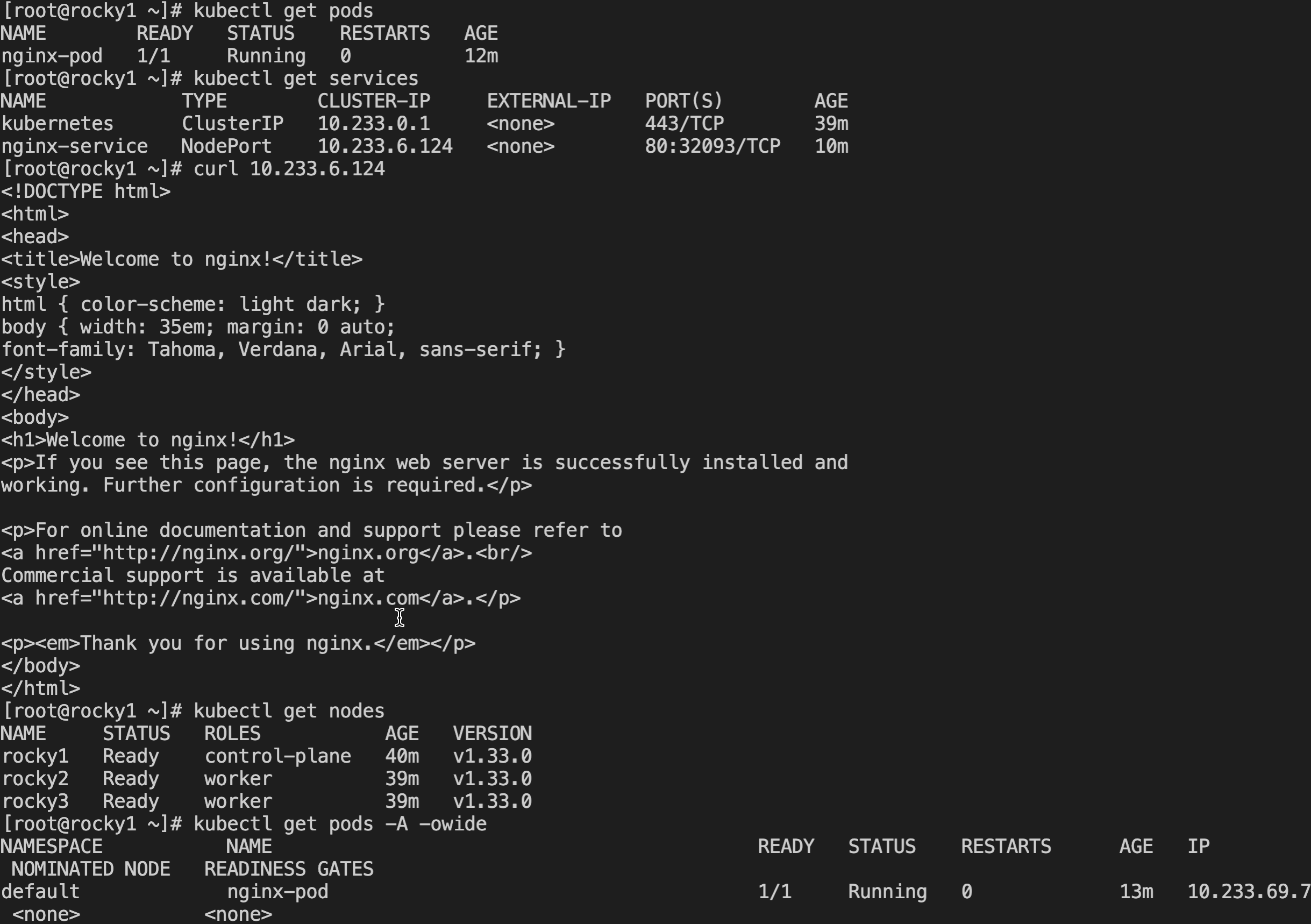
语言模型
- n元文法
- 参数估计
- 数据平滑方法
- 加1法
- 神经网络模型
- 提出原因
- 前馈神经网络(FNN)
- 循环神经网络
n元文法
大规模语料库的出现为自然语言统计处理方法的实现提供了可能,统计方法的成功应用推动了语料库语言学的发展。
语句
𝑠
=
𝑤
1
𝑤
2
…
𝑤
𝑚
𝑠=𝑤_1𝑤_2…𝑤_𝑚
s=w1w2…wm的先验概率
- p ( s ) = p ( w 1 ) × p ( w 2 ∣ w 1 ) p(s)=p(w_1) \times p(w_2|w_1) p(s)=p(w1)×p(w2∣w1)
- p ( s ) = p ( w 1 ) × p ( w 2 ∣ w 1 ) × p ( w 3 ∣ w 1 w 2 ) p(s)=p(w_1) \times p(w_2|w_1) \times p(w_3|w_1w_2) p(s)=p(w1)×p(w2∣w1)×p(w3∣w1w2)
- p ( s ) = p ( w 1 ) × p ( w 2 ∣ w 1 ) × p ( w 3 ∣ w 1 w 2 ) × ⋯ × p ( w m ∣ w 1 … w m − 1 ) p(s)=p\left(w_{1}\right) \times p\left(w_{2} \mid w_{1}\right) \times p\left(w_{3} \mid w_{1} w_{2}\right) \times \cdots \times p\left(w_{m} \mid w_{1} \ldots w_{m-1}\right) p(s)=p(w1)×p(w2∣w1)×p(w3∣w1w2)×⋯×p(wm∣w1…wm−1)
𝑤 𝑖 𝑤_𝑖 wi 可以是字、词、短语或词类等,统称为统计基元。通常以“词”(token)代之; 𝑤 𝑖 𝑤_𝑖 wi 的概率取决于 𝑤 1 𝑤_1 w1,…, 𝑤 𝑖 − 1 𝑤_{𝑖−1} wi−1,条件序列 𝑤 1 𝑤_1 w1,…, 𝑤 𝑖 − 1 𝑤_{𝑖−1} wi−1 称为 𝑤 𝑖 𝑤_𝑖 wi 的历史。
随着历史基元数量的增加,不同的“历史”组合构成的路径数量指数级增长。对于第𝑖(𝑖 > 1)个统计基元,历史基元的个数为𝑖−1,如果共有𝐿个不同的基元,如词汇表,理论上每一个单词都有可能出现在1到𝑖 −1的每一个位置上,那么,𝑖基元就有 𝐿 𝑖 − 1 𝐿^{𝑖−1} Li−1 种不同的历史组合。我们必须考虑在所有𝐿𝑖−1种不同的历史条件下产生第𝑖个基元的概率。那么,对于长度为𝑚的句子,模型中有 𝐿 𝑚 𝐿^𝑚 Lm个自由参数 p ( w m ∣ w 1 … w m − 1 ) p\left(w_{m} \mid w_{1} \ldots w_{m-1}\right) p(wm∣w1…wm−1),如果L=6763,m=3,自由参数的数目为 3.09 × 10 11 3.09\times10^{11} 3.09×1011,这是一个很大的问题。
解决方案:设法减少历史基元的个数,将 𝑤 1 , 𝑤 2 , … , 𝑤 𝑖 − 1 𝑤_1,𝑤_2,…,𝑤_{𝑖−1} w1,w2,…,wi−1映射到等价类S( 𝑤 1 , 𝑤 2 , … , 𝑤 𝑖 − 1 ) 𝑤_1,𝑤_2,…,𝑤_{𝑖−1)} w1,w2,…,wi−1),使等价类的数目远远小于原来不同历史基元的数目。
那么如何划分等价类呢?将两个历史映射到同一个等价类,当且仅当这两个历史中的最近𝑛−1个基元相同,即:

这种计算语言(通常指句子)概率的模型称为语言模型(language model)。由于通常只考虑历史基元与当前词构成𝑛元词序列(即只考虑前𝑛−1个词的历史情况),因此这种模型又称为n
元文法模型(n-gram model)。𝑛为整数,通常𝑛=1~5。
- 当𝑛=1时,出现在第𝑖位置上的基元𝑤𝑖独立于历史,称为一元文法,记作uni-gram或monogram;
- 当𝑛=2时,出现在第𝑖位置上的基元𝑤i只与𝑖−1位置上的基元相关,称为2元文法(2-gram或bi-gram)。2元文法序列又被称为1阶马尔可夫链,2元文法很常见;
- 当𝑛=3时,出现在第𝑖位置上的基元𝑤i与𝑖−2和𝑖−1位置上的基元相关,称为三元文法(3-gram或tri-gram)。三元文法序列又被称为2阶马尔可夫链。
为了保证条件概率在𝑖 = 1时有意义,同时保证句子内所有字符串的概率为1,即 ∑ s p ( s ) = 1 \sum_sp(s)=1 ∑sp(s)=1,可以在句子首尾两端增加两个标志: < B O S > 𝑤 1 𝑤 2 ⋯ 𝑤 𝑚 < E O S > <BOS>𝑤_1𝑤_2⋯𝑤_𝑚<EOS> <BOS>w1w2⋯wm<EOS>。
参数估计
收集、标注大规模样本,我们称其为训练数据/语料,利用最大似然估计(maximum likelihood evaluation, MLE) 方法计算概率。
p ( w i ∣ w i − n + 1 i − 1 ) = f ( w i ∣ w i − n + 1 i − 1 ) = c ( w i − n + 1 i ) ∑ w i c ( w i − n + 1 i ) p\left(w_{i} \mid w_{i-n+1}^{i-1}\right)=f\left(w_{i} \mid w_{i-n+1}^{i-1}\right)=\frac{c\left(w_{i-n+1}^{i}\right)}{\sum_{w_{i}} c\left(w_{i-n+1}^{i}\right)} p(wi∣wi−n+1i−1)=f(wi∣wi−n+1i−1)=∑wic(wi−n+1i)c(wi−n+1i)
举个简单的例子:

数据平滑方法
定义:调整最大似然估计的概率值,使零概率增值,使非零概率下调,“劫富济贫”,消除零概率,改进模型的整体正确率。
目标是为了让测试样本的语言模型困惑度越小越好。
平滑的n-gram概率为 p ( w i ∣ w i − n + 1 i − 1 ) p\left(w_{i} \mid w_{i-n+1}^{i-1}\right) p(wi∣wi−n+1i−1),句子𝑠的概率为: p ( s ) = ∏ i = 1 m + 1 p ( w i ∣ w i − n + 1 i − 1 ) p(s)=\prod_{i=1}^{m+1} p\left(w_{i} \mid w_{i-n+1}^{i-1}\right) p(s)=i=1∏m+1p(wi∣wi−n+1i−1)
假定测试语料𝑇由 𝑙 𝑇 𝑙_𝑇 lT个句子构成:( s 1 , s 2 . . . s l T s_1,s_2...s_{l_T} s1,s2...slT),共含有 w T w_T wT个词,那么整个测试集的概率为: p ( T ) = ∏ i = 1 l T p ( s i ) p(T)=\prod_{i=1}^{l_{T}} p\left(s_{i}\right) p(T)=∏i=1lTp(si)
困惑度可以定义为: P P P ( T ) = 2 − 1 w T log 2 p ( T ) P P_{P}(T)=2^{-\frac{1}{w_{T}} \log _{2} p(T)} PPP(T)=2−wT1log2p(T) ,不难看出,P(T)越接近0,困惑度会特别大。n-gram对于英语文本的困惑度范围一般为10~1000,语言模型设计的任务就是寻找困惑度最小的模型,使其最接近真实的语言。
加1法
基本思想: 每一种情况出现的次数加1。
例如,对于 uni-gram,设 𝑤 1 , 𝑤 2 , 𝑤 3 𝑤_1,𝑤_2,𝑤_3 w1,w2,w3三个词, 𝑤 1 𝑤_1 w1出现1次, 𝑤 2 𝑤_2 w2出现0次, w 3 w_3 w3出现两次,概率分别为:1/3,0,2/3,加1后情况就变为: 2/6,1/6,3/6
对于二元文法有:
p ( w i ∣ w i − 1 ) = 1 + c ( w i − 1 w i ) ∑ w i [ 1 + c ( w i − 1 w i ) ] = 1 + c ( w i − 1 w i ) ∣ V ∣ + ∑ w i c ( w i − 1 w i ) \begin{aligned} p\left(w_{i} \mid w_{i-1}\right) & =\frac{1+c\left(w_{i-1} w_{i}\right)}{\sum_{w_{i}}\left[1+c\left(w_{i-1} w_{i}\right)\right]} \\ & =\frac{1+c\left(w_{i-1} w_{i}\right)}{|V|+\sum_{w_{i}} c\left(w_{i-1} w_{i}\right)}\end{aligned} p(wi∣wi−1)=∑wi[1+c(wi−1wi)]1+c(wi−1wi)=∣V∣+∑wic(wi−1wi)1+c(wi−1wi)
在前面的例题中,原来的概率存在0值:

同样我们还可以求到句子“John read a book”的概率,计算过程如下所示:


神经网络模型
提出原因
首先我们来回顾一下上文提出的n-gram,假设现在有一个句子“这本小说很枯燥,读起来很乏味。”主要会存在以下两个问题:
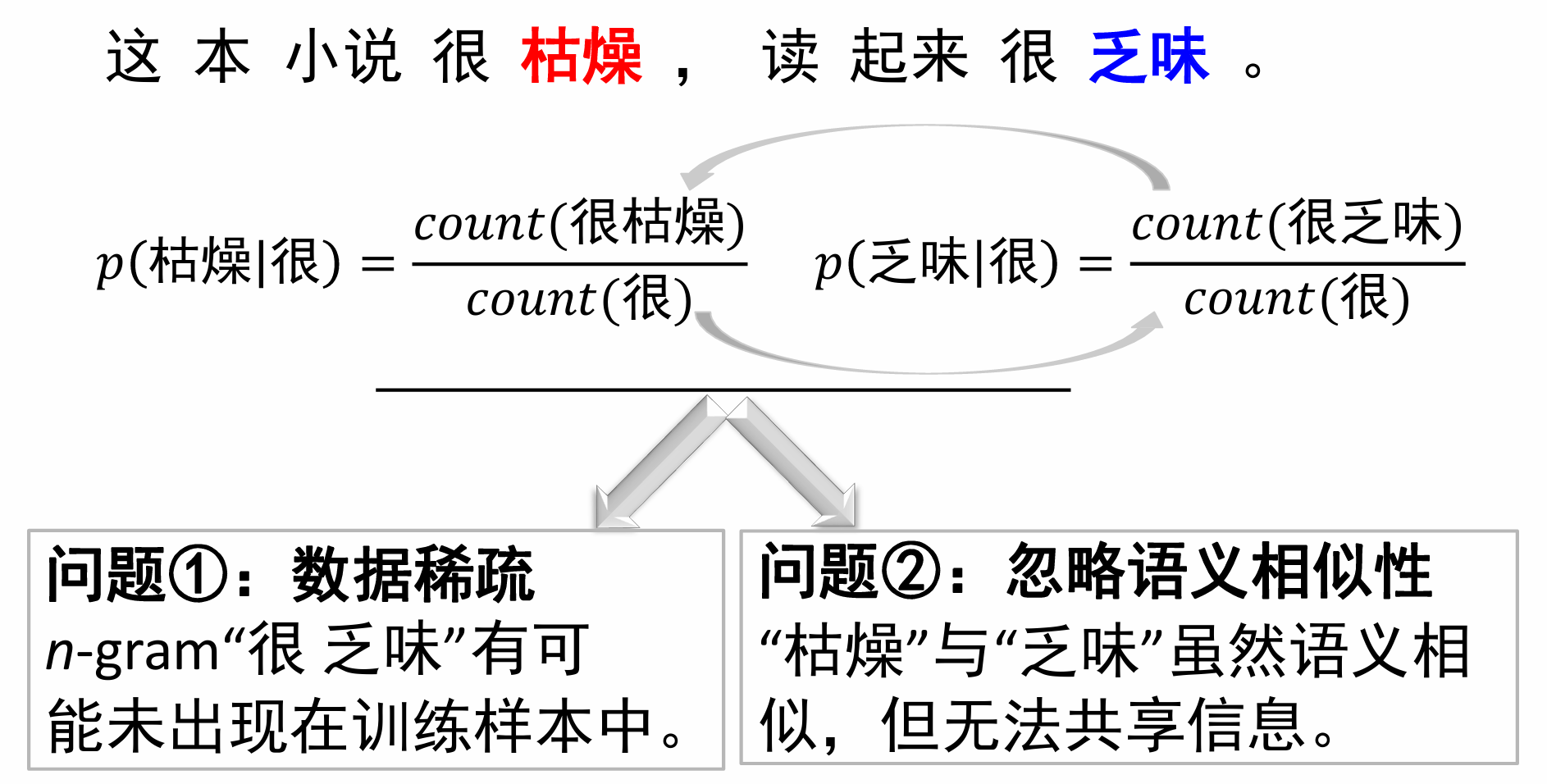
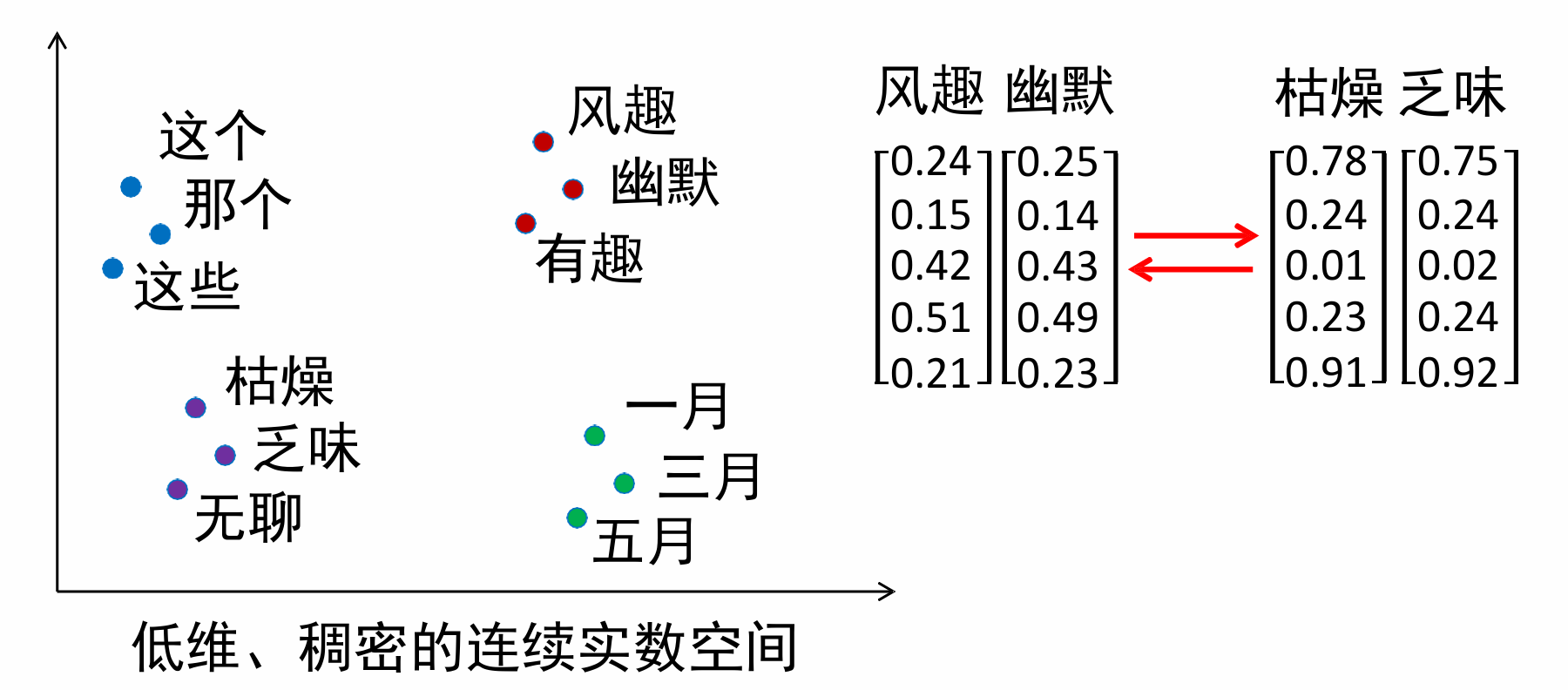
我们来分析一下原因:在n元文法中,“词”以词形本身表示,是离散的符号,这等价于one-hot 向量,这会导致任意两个词之间的相似度都为0。维度太高!
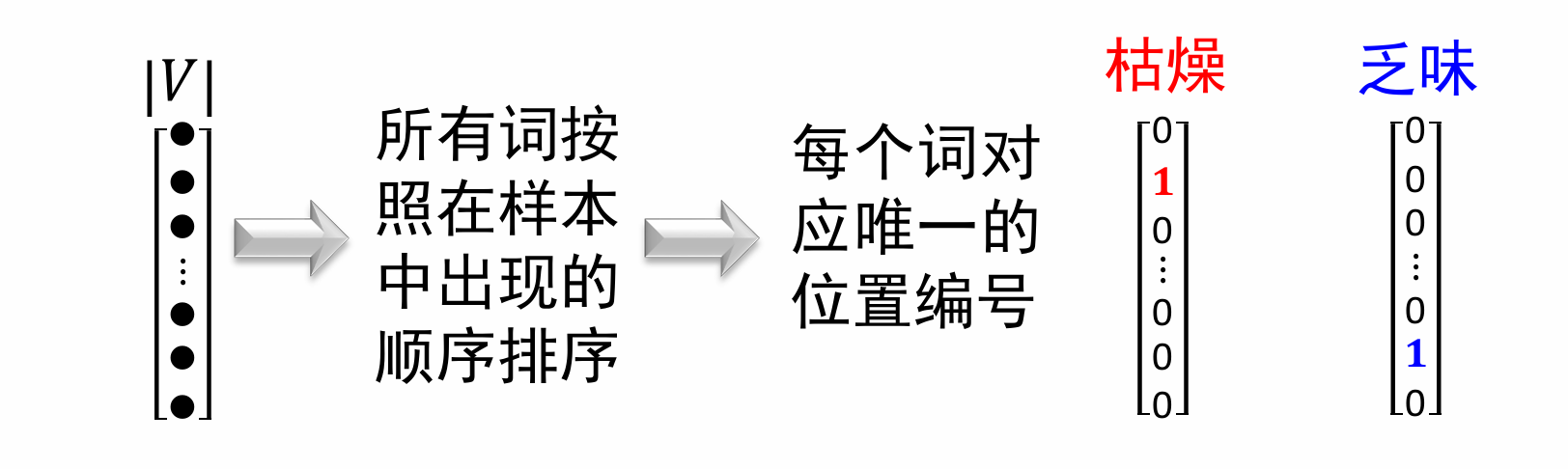
我们需要连续空间的分布式表示赋予词向量!
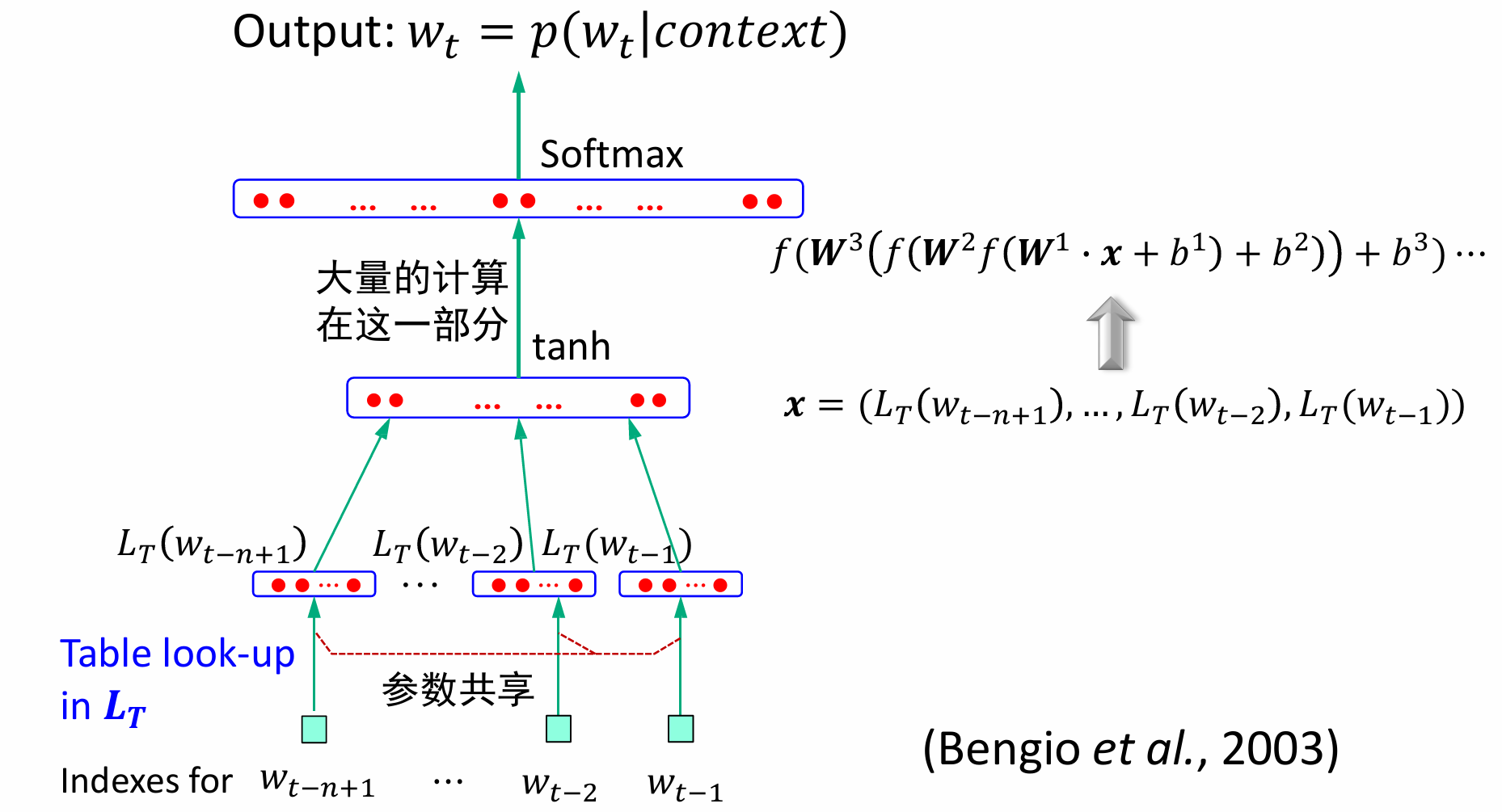
前馈神经网络(FNN)
FNN是最早发明的简单人工神经网络,也经常被称为多层感知(Multi-Layer Perceptron, MLP)。前馈网络中各个神经元按接收信息的先后分为不同的组,每一组可以看作一个神经层,每一层中的神经元接收前一层神经元的输出,并输出到下一层神经元,整个网络中的信息是朝一个方向传播,没有反向的信息传播,可以看作是一个有向的无环图。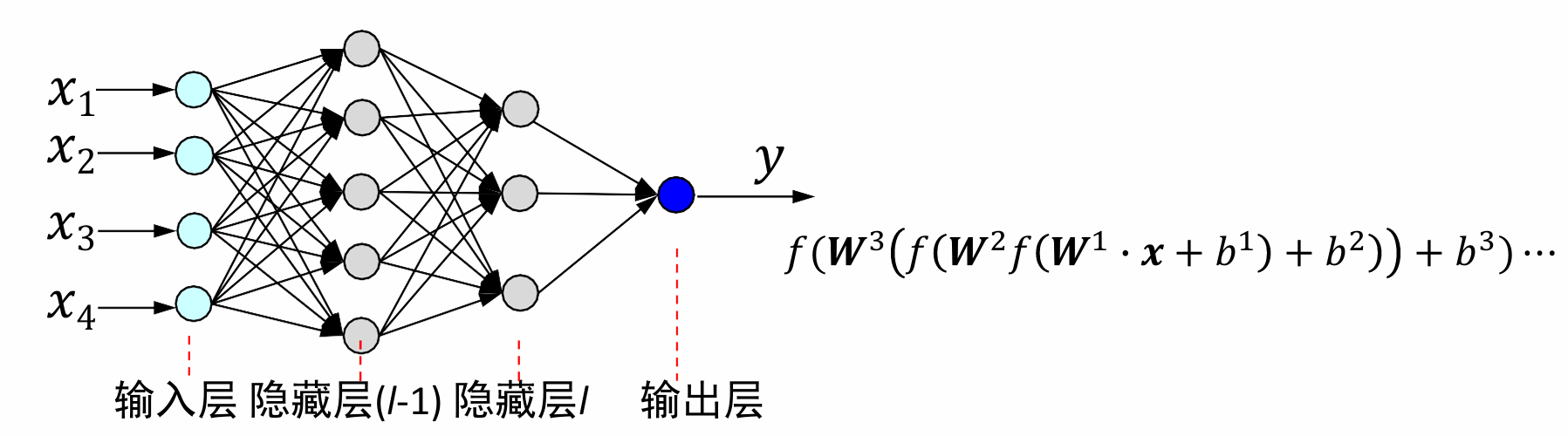
网络表示:𝐿为神经网络的层数;𝑀𝑙为第𝑙层的神经元个数;𝑓𝑙(∙)为第𝑙层神经元的激活函数;
参数学习:确定网络中所有的𝑾和b
基于反向传播(Back Propagation)算法的随机梯度下降参数训练过程:

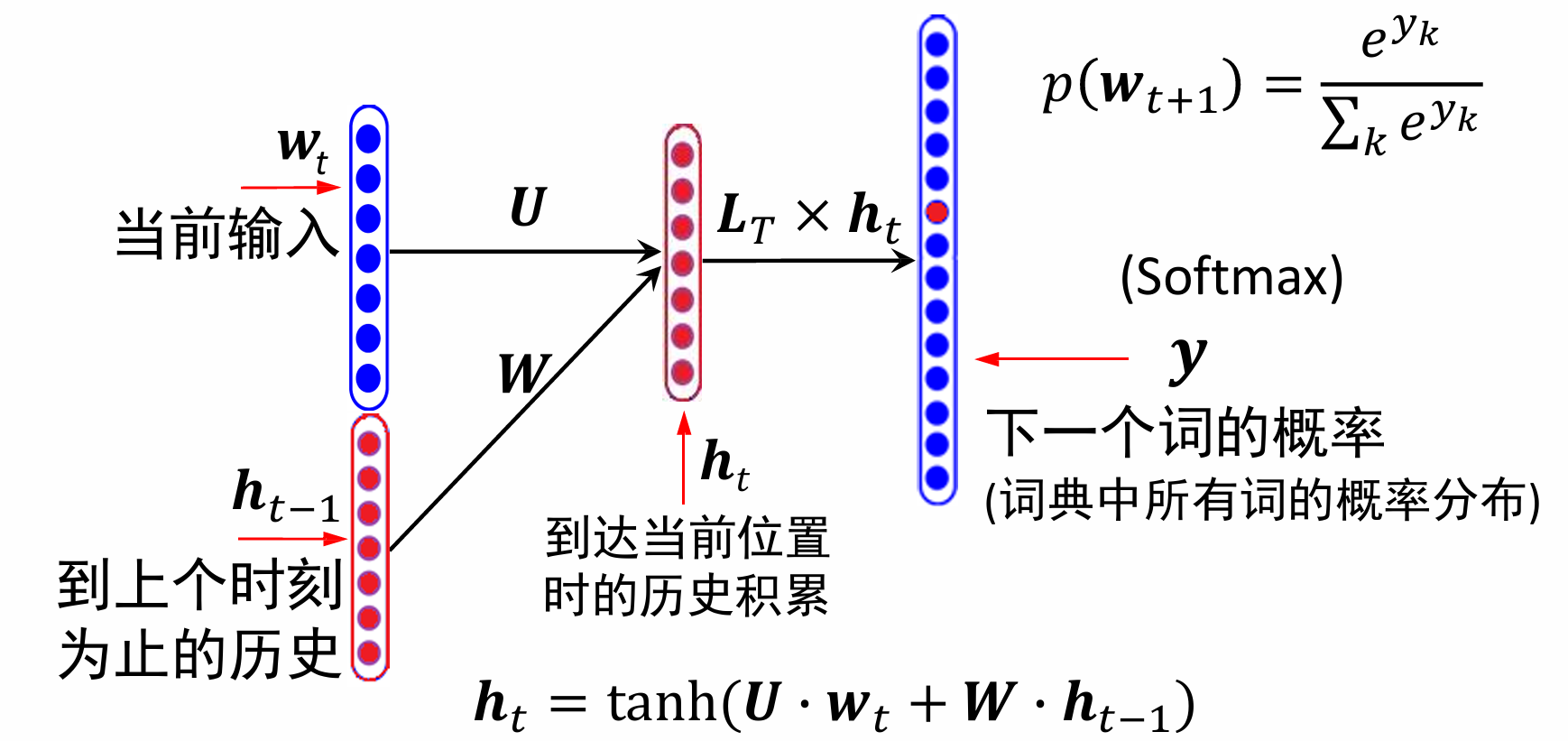
关于词向量的表示,也就是图中的
L
T
L_T
LT,通常先随机初始化,然后通过目标函数优化词的向量表示(如最大化语言模型似然度)。
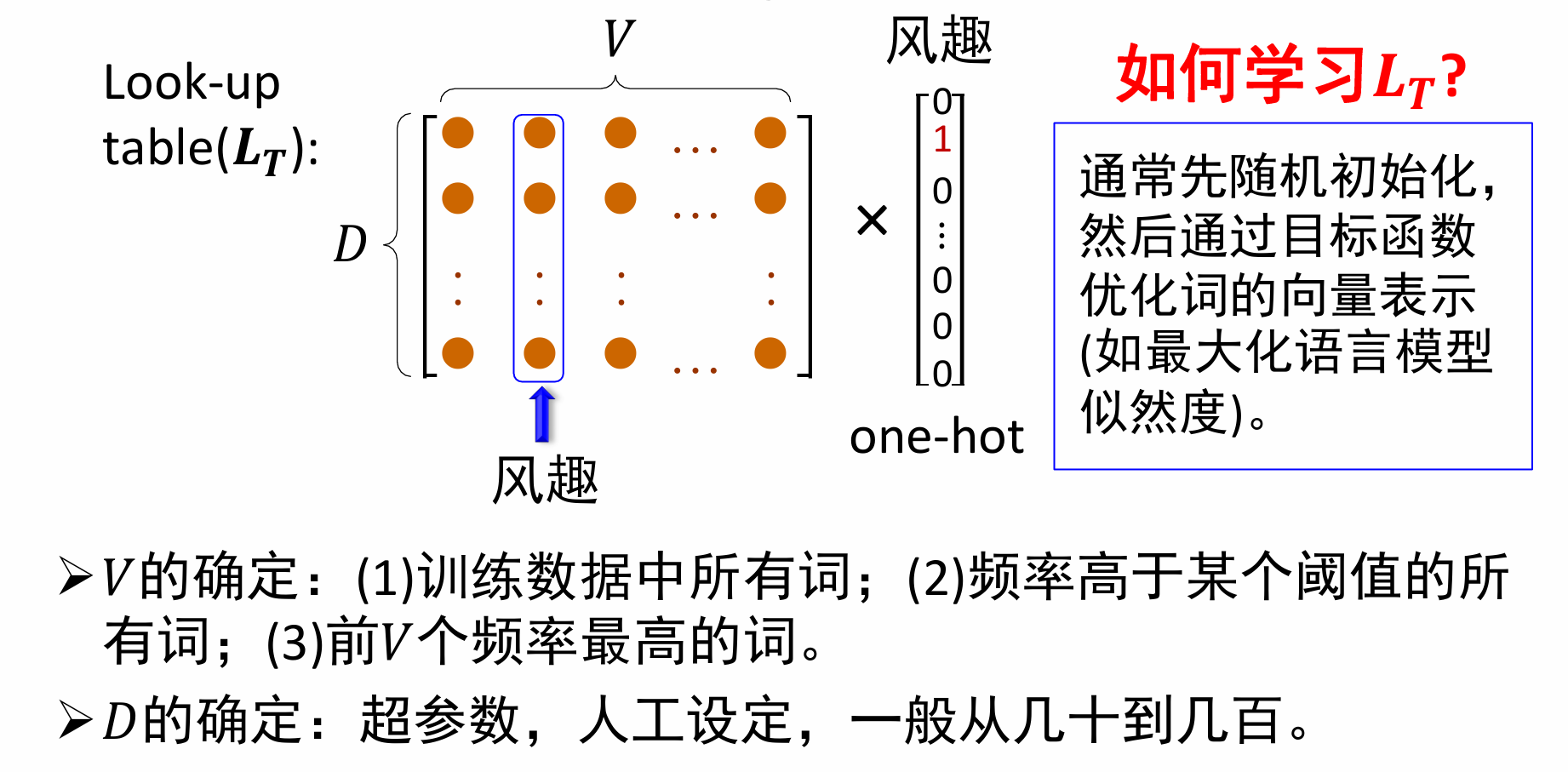
V表示训练集中的词个数,如果训练集很庞大,可以考虑取前V个频率最高的词。
D则表示词向量的维度,一般来说词向量维度越大,模型效果会更好,当然训练难度也会加大。
- Softmax 回归(regression) 也称为多项(Multinomial) 或多类(MultiClass) 的Logistic回归,是Logistic回归在多分类问题上的推广,它也可以看作是一种条件最大熵模型。
- 对于多类问题,类别标签$𝑦∈ 1,2, ⋯,𝐶 $可以有𝐶个取值,给定一个样本𝒙, Softmax回归预测的属于类别𝑐的条件概率为:
p ( y = c ∣ x ) = Softmax ( w c T x ) = exp ( w c T x ) ∑ c ′ = 1 C exp ( w c ′ T x ) \begin{aligned} p(y=c \mid \boldsymbol{x}) & =\operatorname{Softmax}\left(\boldsymbol{w}_{c}^{T} \boldsymbol{x}\right) \\ & =\frac{\exp \left(\boldsymbol{w}_{c}^{T} \boldsymbol{x}\right)}{\sum_{c^{\prime}=1}^{C} \exp \left(\boldsymbol{w}_{c^{\prime}}^{T} \boldsymbol{x}\right)}\end{aligned} p(y=c∣x)=Softmax(wcTx)=∑c′=1Cexp(wc′Tx)exp(wcTx)
其中, 𝒘 𝑐 𝒘_𝑐 wc是第𝑐类的权重向量
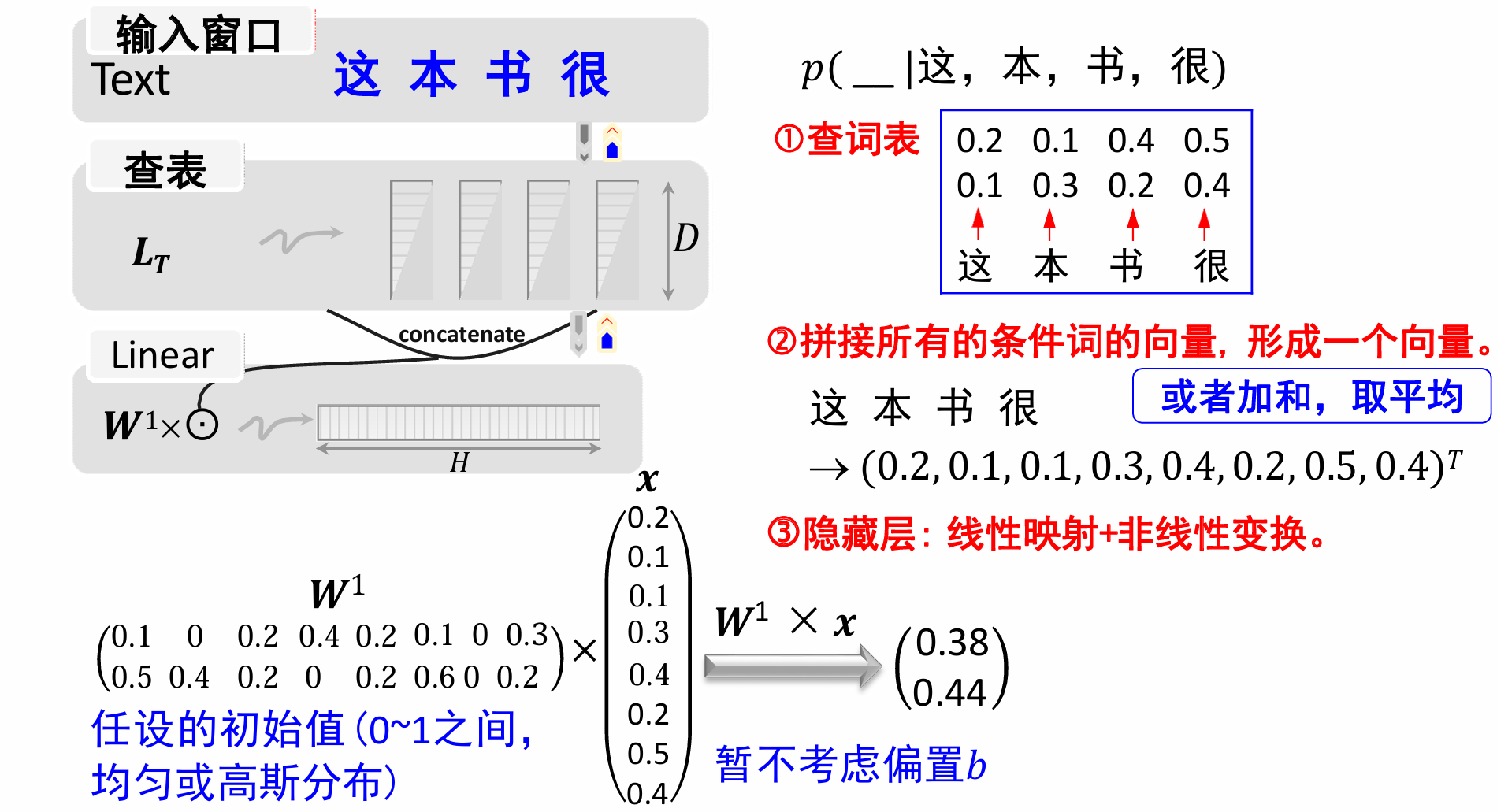
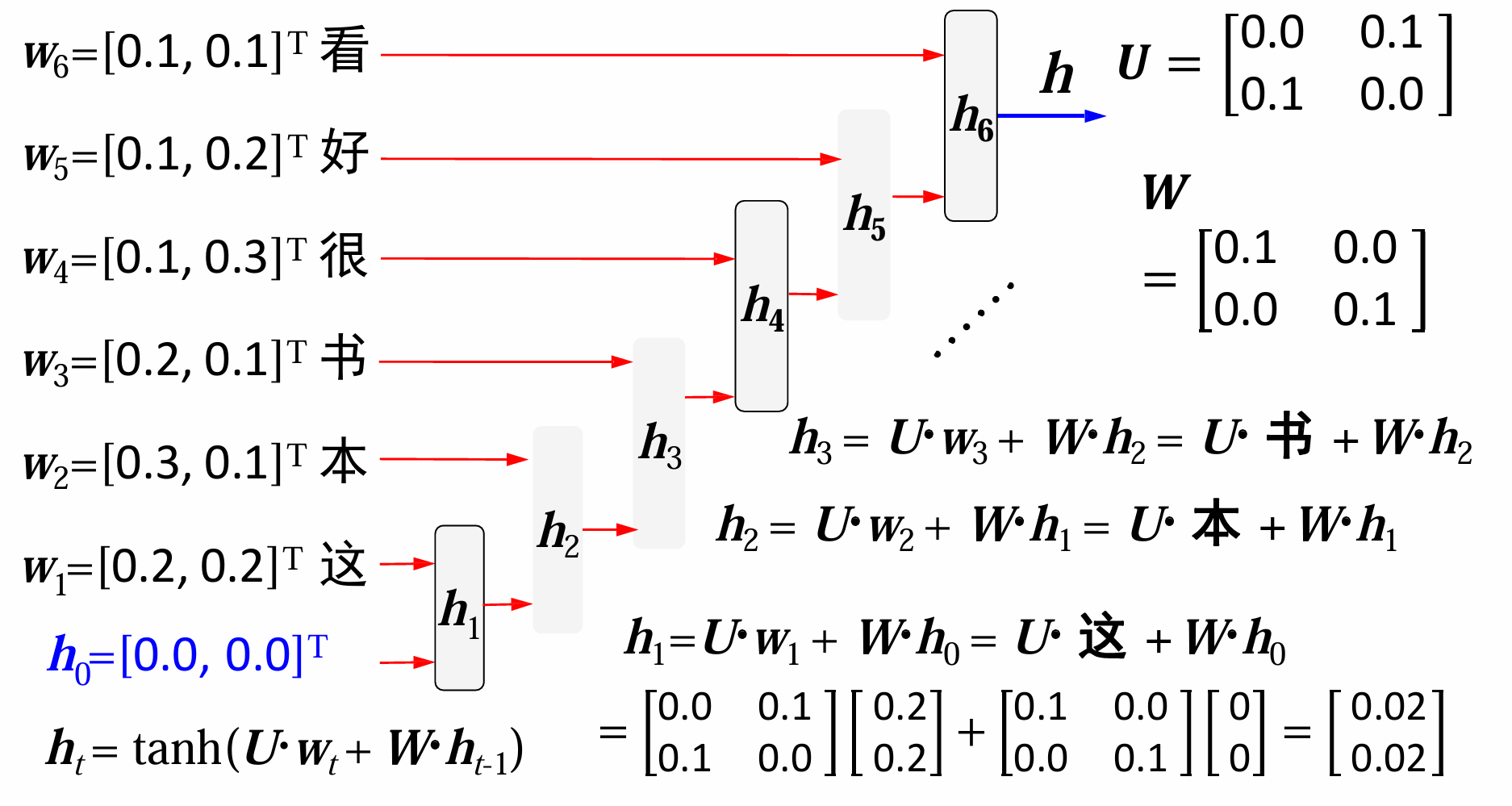
举个例子来看,我们给出
L
T
L_T
LT和输入词串:

暂时不考虑偏置b,分三步进行计算。
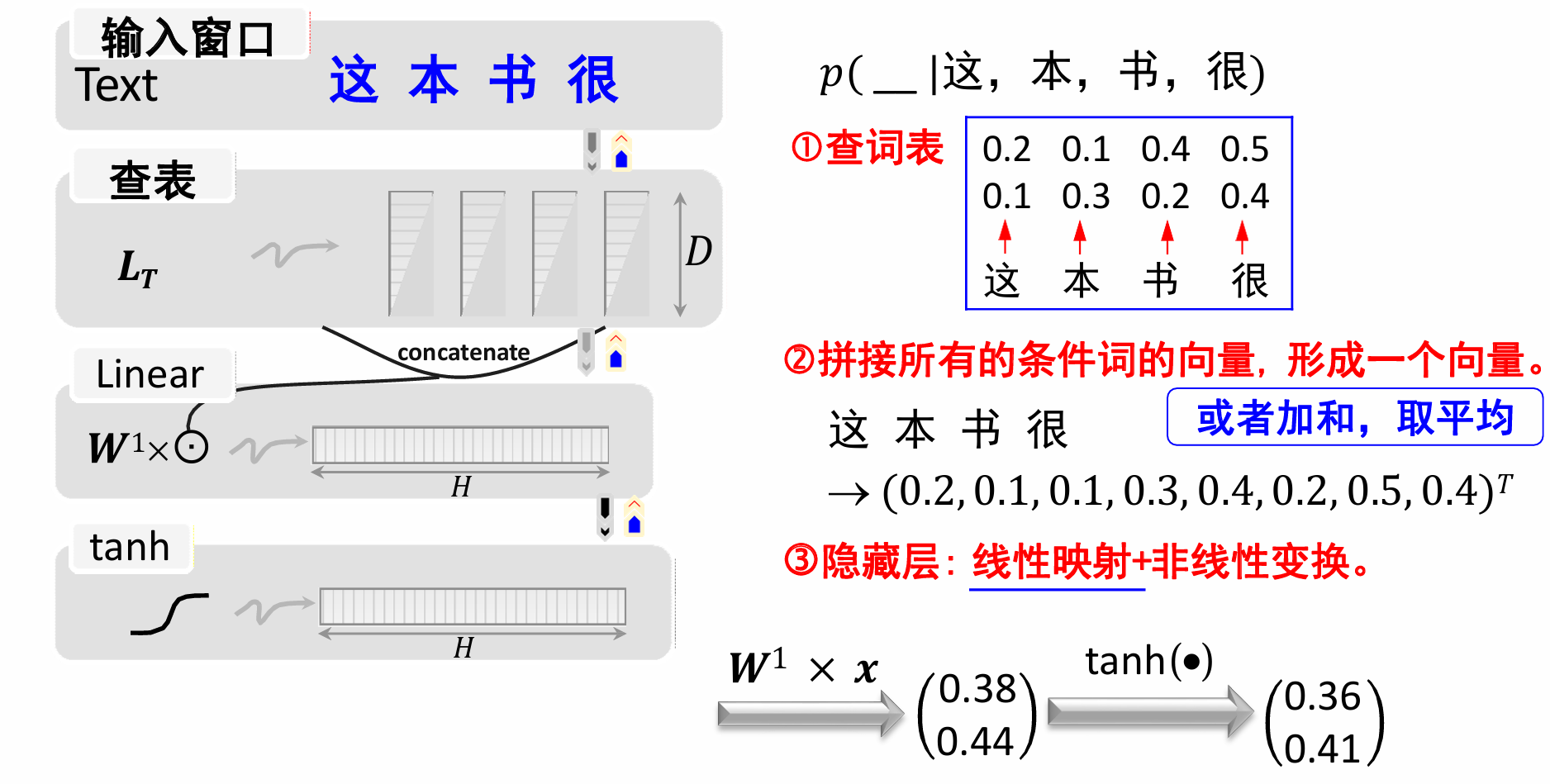
再得到最后的结果向量(0.38,0.44
)
T
)^T
)T后经过tanh激活函数:
最后我们得到的向量和原来的
L
T
L_T
LT进行处理,再送入softmax找到概率最大的一项,如此就可以找到出现概率最大的词了。
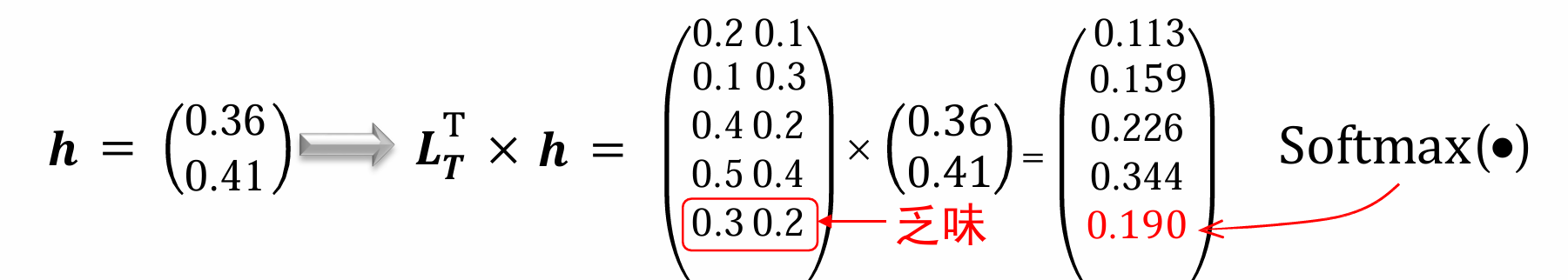
问题:
- 仅对小窗口的历史信息进行建模
- n-gram语言模型仅考虑前面𝑛−1个词的历史信息
我们需要一种对所有的历史信息进行建模的方法!
循环神经网络
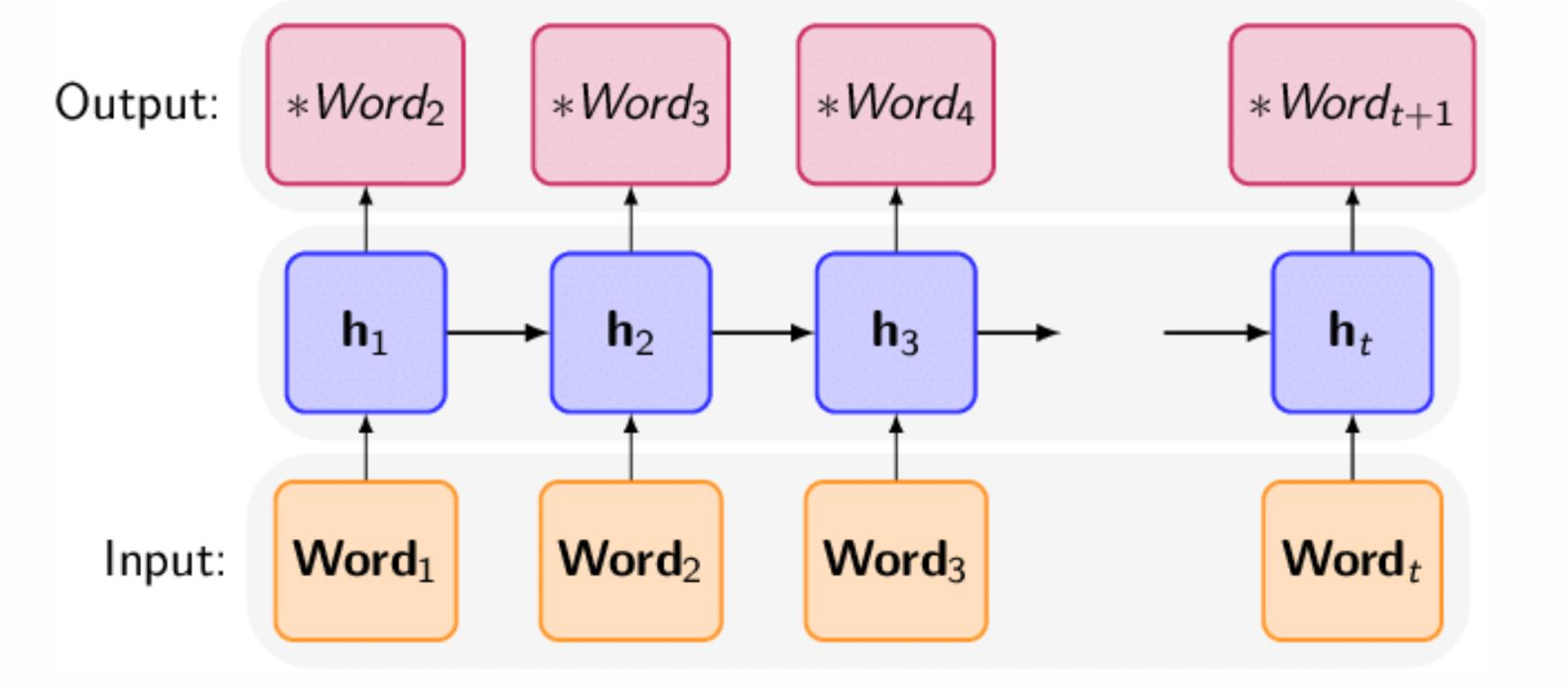
输入:从开始到𝑡−1时刻的历史
𝒉
𝑡
−
1
𝒉_{𝑡−1}
ht−1;当前位置𝑡的词向量
𝒘
𝑡
𝒘_𝑡
wt
输出:到𝑡位置时的历史积累
𝒉
𝑡
𝒉_𝑡
ht及其该位置上词的概率
模型训练时需要保证当前词的概率最大
举个例子:以“这本书很好看”为例
问题:梯度消失或爆炸:参数W经过多次传递后有可能导致梯度消失(小于1)或者爆炸(大于1)。