Agent的工作流
下面展示了如何创建一个“计划并执行”风格的代理。 这在很大程度上借鉴了 计划和解决 论文以及Baby-AGI项目。
核心思想是先制定一个多步骤计划,然后逐项执行。完成一项特定任务后,您可以重新审视计划并根据需要进行修改。
般的计算图如下所示
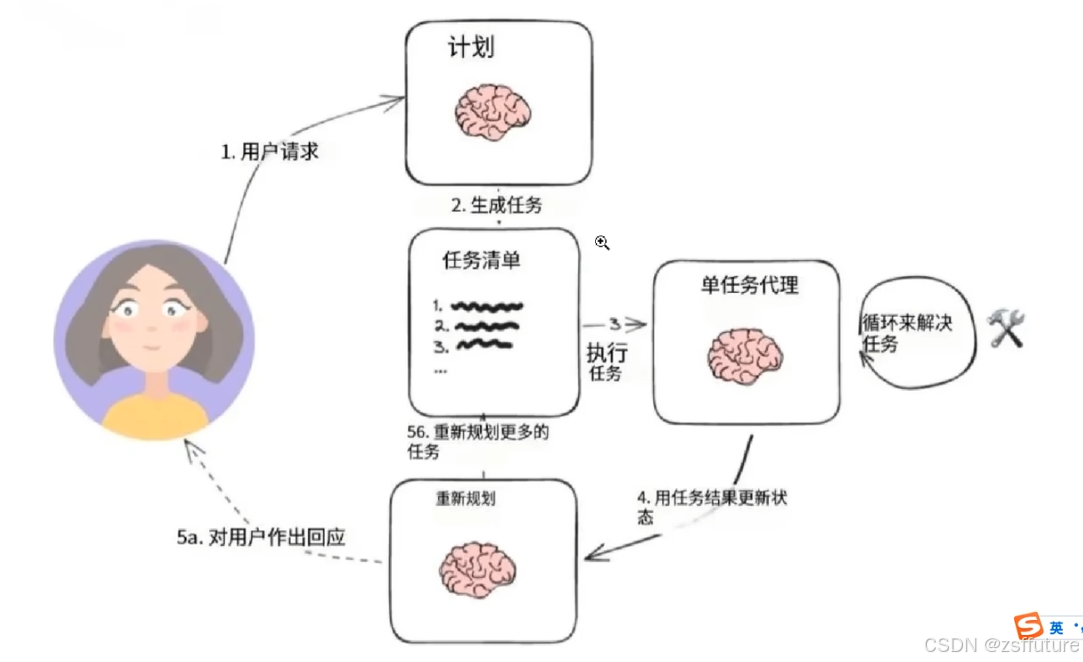
这与典型的 ReAct 风格的代理进行了比较,在该代理中,您一次思考一步。 这种“计划并执行”风格代理的优势在于
1.明确的长期规划(即使是真正强大的 LLM 也可能难以做到)
2.能够使用更小/更弱的模型来执行步骤,仅在规划步骤中使用更大/更好的模型以下演练演示了如何在 LangGraph 中实现这一点。
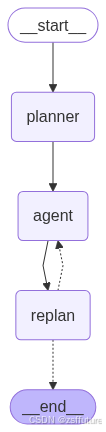
根据langgraph搭建一个智能体的工作流,具体如下:
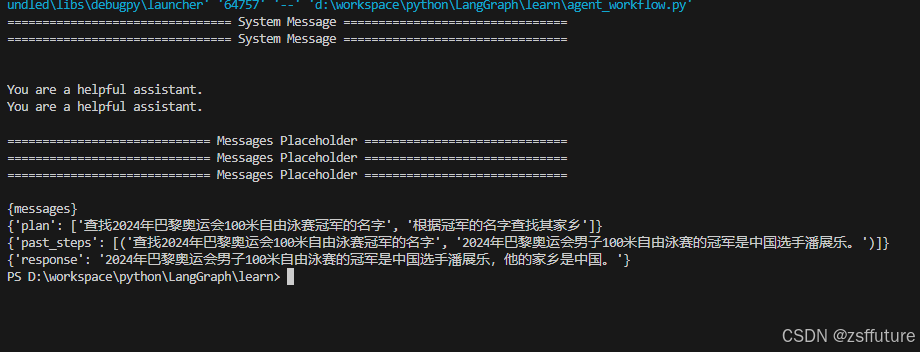
执行结果如下:
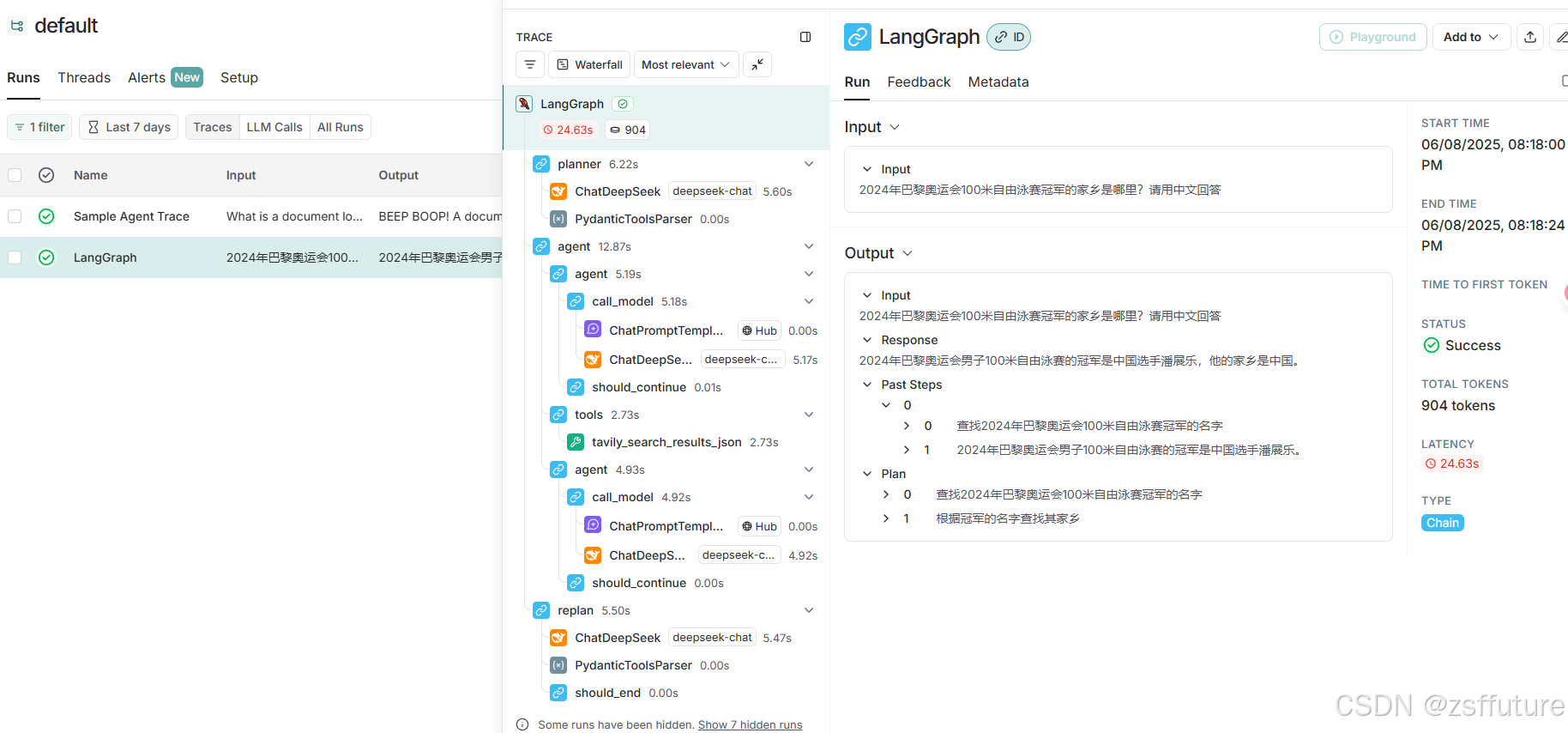
使用LANGSMITH进行数据跟踪,这个需要你注册登录获取key,就可以查看了,我使用的是deepseek,充了钱了,没免费的了。
源码如下:
TAVILY_API_KEY = "xxxx"# 使用你自己的key
LANGCHAIN_TRACING_V2 = "true"
DEEPSEEK_API_KEY = "xxxx" # 使用你自己的key
LANGSMITH_TRACING="true"
LANGSMITH_ENDPOINT="https://api.smith.langchain.com"
LANGSMITH_API_KEY="xxxx"# 使用你自己的key
LANGSMITH_PROJECT="pr-glossy-analogue-76"
import os
os.environ["DEEPSEEK_API_KEY"] = DEEPSEEK_API_KEY
os.environ["TAVILY_API_KEY"] = TAVILY_API_KEY
os.environ["LANGCHAIN_TRACING_V2"] = LANGCHAIN_TRACING_V2
os.environ["LANGSMITH_TRACING"] = LANGSMITH_TRACING
os.environ["LANGSMITH_ENDPOINT"] = LANGSMITH_ENDPOINT
os.environ["LANGSMITH_API_KEY"] = LANGSMITH_API_KEY
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
# 导入tavily的搜索功能
from langchain_community.tools.tavily_search import TavilySearchResults
# 创建TavilySearchResults工具,设置最大结果数为1
tools = [TavilySearchResults(max_results = 1)]
from langchain import hub
from langchain_openai import ChatOpenAI
from langchain_deepseek import ChatDeepSeek
import asyncio
from langgraph.prebuilt import create_react_agent
# 从langchain的hub获取prompt的模板,可以进行修改 "mintyflinter/best-chatbot", include_model=True
# prompt = hub.pull("wfh/react-agent-executor") # 会报错,官方的api的参数改变了,所以需要修改为下面的
prompt = hub.pull("zhang1career/react-agent-executor")
prompt.pretty_print()
# 选择大模型
# Model
llm = ChatDeepSeek(
model="deepseek-chat",
api_key=DEEPSEEK_API_KEY,
#base_url="https://api.deepseek.com",
#temperature=0.0
)
agent_executor = create_react_agent(llm, tools,prompt=prompt)
#agent_executor.invoke({"input":[("user", "谁是美国公开赛的获胜者?")]}) # 这种方法调用会报错
# 正确调用方式
# response = agent_executor.invoke({"input": "谁是美国公开赛的获胜者?"})
# print(response["messages"])
import operator
from typing import Annotated, List, Tuple, TypedDict,Literal
# 定义一个TYpeDict类 PlanExecute , 用于存储输入、计划、过去的步骤和响应
class PlanExecute(TypedDict):
input: str
plan:List[str]
past_steps:Annotated[List[Tuple], operator.add]
response:str
from pydantic import BaseModel, Field
# 定义一个plan模型类, 用于描述未来要执行的计划
class Plan(BaseModel):
"""未来要执行的计划"""
steps:List[str] = Field(
description="需要执行的不同步骤,应该按顺序排列"
)
from langchain_core.prompts import ChatPromptTemplate
# 创建一个计划生成的提示模板
planner_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""对于给定的目标,提出一个简单的逐步计划。这个计划应该包含独立的任务,如果正确执行将得出正确答案,不要添加任何多余的步骤,最后一步的结果应该是最终答案。确保每一步都有所有必要的信息 - 不要跳过步骤。"""
),
("placeholder","{messages}")
]
)
# 使用指定的提示词模板创建一个计划生成器,使用deepseek模型
planner = planner_prompt|ChatDeepSeek(
model="deepseek-chat",
api_key=DEEPSEEK_API_KEY,
#base_url="https://api.deepseek.com",
# temperature=0.0
).with_structured_output(Plan)
#planner.invoke({"messages":[("user", "现任澳网冠军的家乡是哪里?")]})
from typing import Union
# 定义一个响应模型类,用于描述用户的响应
class Response(BaseModel):
"""用户响应"""
response: str
# 定义 一个行为模型类,用于描述要执行的行为,该类继承自BaseModel
# 类中有一个属性action, 类型为Union[Response, Plan],表示可以是Responese 或Plan的类型
# action 属性的描述为: 要执行的行为,如果要回应用户,使用Response: 如果需要进一步使用工具获取答案,使用plan
class Act(BaseModel):
"""要执行的行为"""
action: Union[Response,Plan] = Field(
description="要执行的行为, 如果要回应用户,使用Response,如果需要进一步使用工具获取答案,使用Plan。"
)
replanner_prompt = ChatPromptTemplate.from_template(
"""对于给定的目标,提出一个简单的逐步计划。这个计划应该包含独立的任务,如果正确执行将得出正确答案,不要添加任何多余的步骤,最后一步的结果应该是最终答案。确保每一步都有所有必要的信息 -
你的目标是:
{input}
你的原计划是:
{plan}
你目前已完成的步骤是:
{past_steps}
相应的更新你的计划,如果不需要更多的步骤并且可以返回给用户,那么就这样响应。如果需要,填写计划。只添加仍然需要完成的步骤,不要返回已完成的步骤
"""
)
# 使用指定的提示模板创建一个重新计划生成器,使用deepseek
replanner = replanner_prompt|ChatDeepSeek(
model="deepseek-chat",
api_key=DEEPSEEK_API_KEY,
#base_url="https://api.deepseek.com",
# temperature=0.0
).with_structured_output(Act)
# 定义一个异步函数
async def main():
# 定义一个异步函数,用于生成计划步骤
async def plan_step(state: PlanExecute):
plan = await planner.ainvoke({"messages": [("user", state["input"])]})
return {"plan": plan.steps}
# 定义一个异步函数执行步骤
async def execute_step(state: PlanExecute):
plan = state["plan"]
plan_str = "\n".join(f"{i+1}.{step}" for i, step in enumerate(plan))
task = plan[0]
task_formatted = f"""对于一下计划:
{plan_str}\n\n你的任务执行第{1}步,{task}.
"""
agent_response = await agent_executor.ainvoke(
{"messages":[("user", task_formatted)]}
)
return {"past_steps": state["past_steps"]+[(task, agent_response["messages"][-1].content)]}
# 定义一个异步函数,用于重新计划步骤
async def replan_step(state: PlanExecute):
output = await replanner.ainvoke(state)
if isinstance(output.action, Response):
return {"response": output.action.response}
else:
return {"plan":output.action.steps}
# 定义一个函数用于判断是否结束
def should_end(state: PlanExecute)->Literal["agent","__end__"]:
if("response" in state and state["response"]):
return "__end__"
else:
return "agent"
from langgraph.graph import StateGraph, START
# 创建一个状态图,初始化PlanEexecute
workflow = StateGraph(PlanExecute)
# 添加计划节点
workflow.add_node("planner",plan_step)
# 添加执行步骤节点
workflow.add_node("agent", execute_step)
# 重新计划节点
workflow.add_node("replan", replan_step)
# 从开始到计划节点的边
workflow.add_edge(START, "planner")
# 设置从计划到代理节点的边
workflow.add_edge("planner", "agent")
# 设置从代理到重新计划节点的边
workflow.add_edge("agent","replan")
# 添加条件边,用于判断下一步操作
workflow.add_conditional_edges(
"replan",
should_end,
)
app = workflow.compile()
graph_png = app.get_graph().draw_mermaid_png()
with open("agent_workflow.png", "wb") as f:
f.write(graph_png)
# 设置配置,递归限制为50次
config = {"recursion_limit":50}
inputs = {"input":"2024年巴黎奥运会100米自由泳赛冠军的家乡是哪里?请用中文回答"}
async for event in app.astream(inputs, config=config):
for k,v in event.items():
if k!="__end__":
print(v)
asyncio.run(main())