文章目录
- A 论文出处
- B 背景
- B.1 背景介绍
- B.2 问题提出
- B.3 创新点
- C 模型结构
- D 实验设计
- D.1 数据集/评估指标
- D.2 SOTA
- D.3 实验结果
- E 个人总结
- E.1 优点
- E.2 不足
A 论文出处
- 论文题目:LogRAG: Semi-Supervised Log-based Anomaly Detection with Retrieval-Augmented Generation
- 发表情况:2024-ICWS(CCF-B)
- 作者单位:清华大学-网络科学与网络空间研究所、华为
B 背景
B.1 背景介绍
随着微服务架构的复杂性增加,故障和异常的发生频率也随之上升,这对用户体验和系统稳定性构成了威胁。传统的日志分析方法依赖于人工,但在系统日益复杂的情况下,这种方法的效率和有效性都在下降。因此,自动化的日志分析成为了异常检测和故障预测的关键手段。
B.2 问题提出
(1)高度依赖于日志解析器,解析错误可能会显著影响异常检测任务;
(2)现有方法通常需要对日志序列进行建模,但系统更新和演变过程中的不稳定序列使得模型需要频繁重训;
(3)随着系统的发展,会出现许多在训练时未见过的日志,现有方法很难适应这些新日志,导致误报率较高。
B.3 创新点
结合RAG技术,通过两个阶段的检测来减轻日志解析错误的影响,并使用单类分类器来模拟系统的正常行为,同时利用LLM通过RAG对检测到的异常日志进行重新评估。
C 模型结构
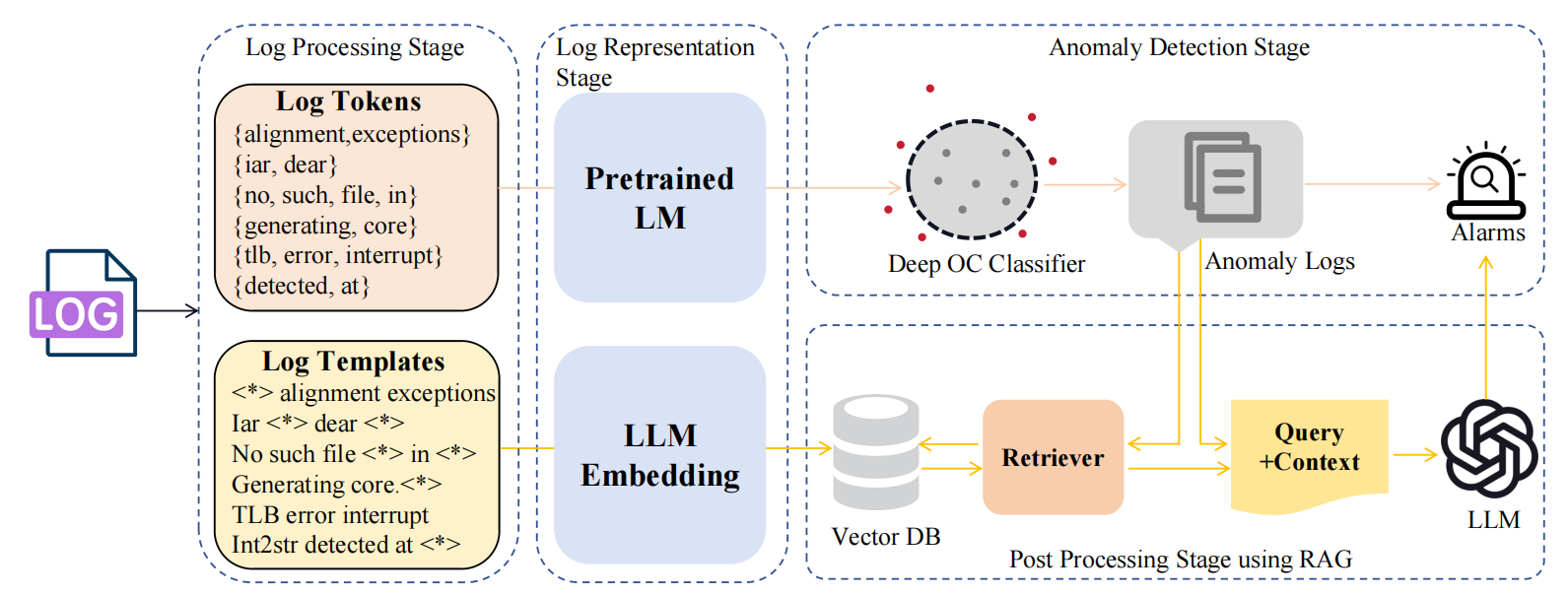
(1)Log Processing
原始日志进行标准化处理,首先去除非字符符号(如数字、标点),统一转为小写以消除大小写差异;其次识别动态参数(如IP地址、ID)并替换为占位符,提取静态模板(如 Connecting to *);最后对模板中的混合词汇应用驼峰规则拆分(如 errorCode → error code)。此步骤将异构日志转化为结构化模板+参数形式,为后续语义分析奠定基础,显著提升数据一致性。
(2)Log Representation
采用双阶段语义学习,通过联合训练,模型同时捕捉具体参数细节与抽象模板逻辑,生成高质量日志向量表示,具体如下:
-
预训练LM:学习日志参数**的上下文语义(如
user123与认证失败的关联); -
微调LLM:学习模板**的全局语义(如
login failed for user [param]表示认证异常)。
(3)Log Anomaly Detection
基于DeepSVDD单分类模型,在训练阶段,模型将所有正常日志的向量表示压缩到超球面中心;检测时,计算新日志向量的球心距离。若距离超过阈值(论文中通过量化损失动态优化),则判为异常。例如,正常日志向量聚集在球心附近,而罕见的错误日志因偏离球心被检测。该方法仅需正常样本训练,适配日志的常态分布特性。
(4)Post-processing Using RAG
为解决误报/漏报,引入RAG机制,此步骤融合检索知识与LLM推理,显著提升决策可解释性与准确性,具体如下:
-
检索当前日志模板的Top-5相似历史模板(基于向量余弦相似度);
-
构建提示(Prompt)注入上下文:
当前日志:[X],相似案例:[Y1,Y2...] 均属[正常/异常]; -
LLM基于提示推理:综合历史案例语义,输出最终异常判定及解释。
D 实验设计
D.1 数据集/评估指标
- 数据集:BGL、Split
- 评估指标:Precision、Recall、F1-Score
D.2 SOTA
无
D.3 实验结果
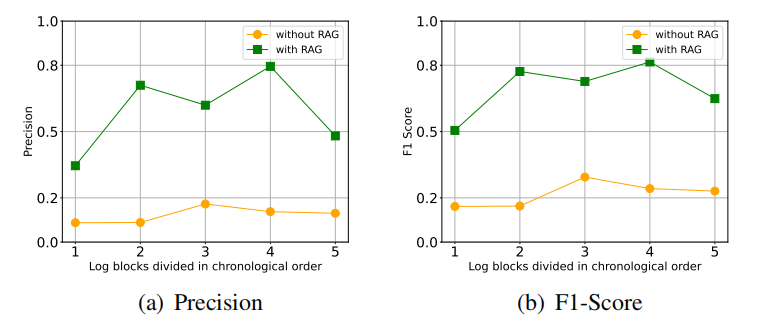
E 个人总结
E.1 优点
(1)在实验部分将数据集分成若干组,每次都是训练前一组,然后在下一组上做测试。
(2)有二次判断的过程,对初步异常检测的结果进行再判断,避免分类错误。
E.2 不足
(1)抛弃参数,同时对日志的token部分进行组合,会损失部分语义。
(2)只对正常行为进行建模,模型训练的过程缺少负样本,也会损失部分语义。
(3)在召回阶段采用的是模板向量,模板向量是由之前的语言模型编码得到的,并没有体现出来日志之间的关联性,所以召回的结果并不能代表与目标日志的关联程度。