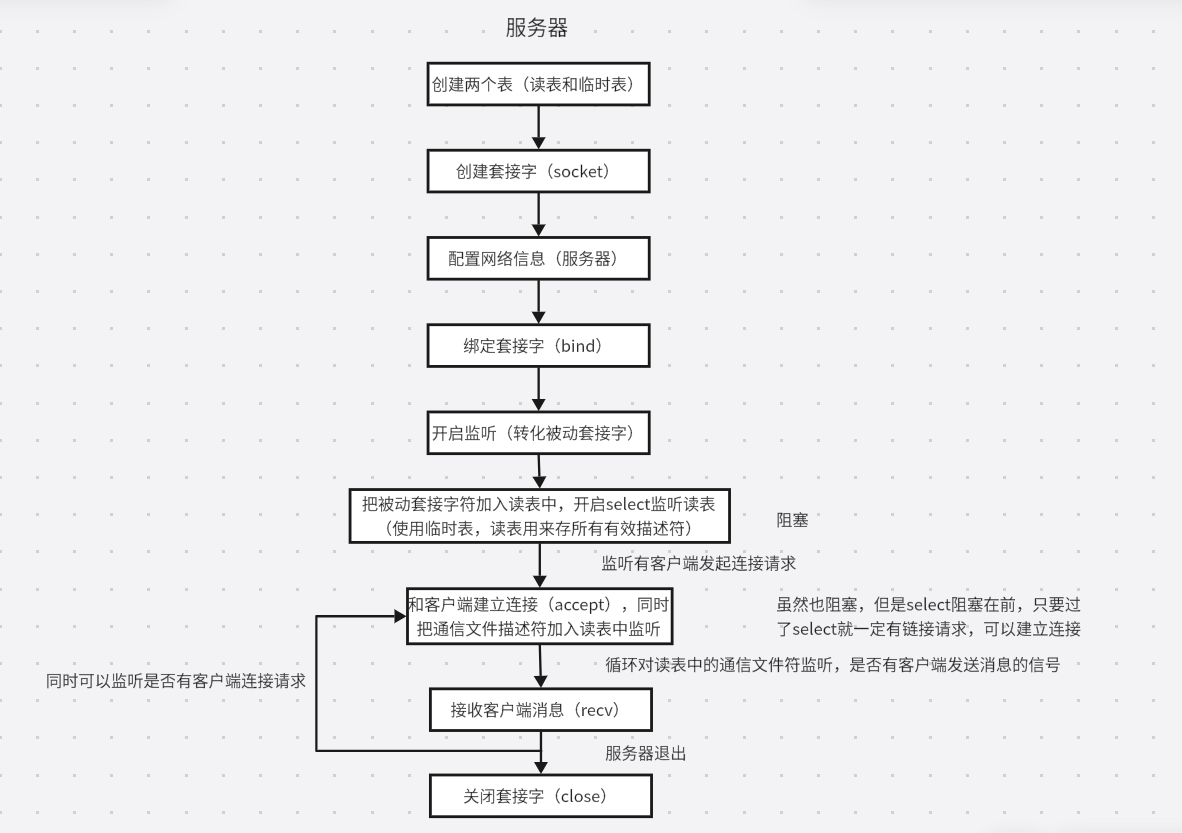
TL;DR
- 2025 年普林斯顿大学提出的硬件友好 attention 设计,在 MQA/GQA 与 deepseek 提出的 MLA 基础之上继续优化,提出 Grouped-Tied Attention (GTA) 和 Grouped Latent Attention (GLA),实现更高推理效率的同时也能保持较好的模型效果。
Paper name
Hardware-Efficient Attention for Fast Decoding
Paper Reading Note
Paper URL:
- https://arxiv.org/pdf/2505.21487
Code URL:
- https://github.com/Dao-AILab/grouped-latent-attention
Introduction
背景
- LLM(大语言模型)的解码在大批量和长上下文情况下受到瓶颈限制,主要原因在于从高带宽内存中加载键值(KV)缓存会增加每个 token 的延迟,同时解码的顺序性限制了并行度。
- 为加速解码,研究者提出了若干面向推理的注意力变体:
- 多查询注意力(MQA)(Shazeer, 2019)只缓存一个 KV 头,极大减少了内存占用;
- 分组查询注意力(GQA)(Ainslie 等,2023)在少数 query 头之间共享一个 KV 头,实现了内存效率与质量之间的折中;
- 多头潜变量注意力(MLA),由 DeepSeek 提出(2024,2025),将隐藏状态压缩为一个潜在向量(latent vector),通过低秩投影进行表示,并缓存这个高维 latent 头,然后在注意力计算前再上投影回原维度。
- 算术强度(Arithmetic Intensity)(Williams 等,2009),即每字节内存访问对应的浮点计算次数(FLOPs/byte),是分析工作负载是否受限于内存带宽的常用指标。
- MQA 提高了算术强度,通过重用一个 KV 头减少了内存占用,但以牺牲质量与并行度为代价(Pope 等,2022)。
- GQA 提高了算术强度(与组大小成正比),但即便在适度 tensor-parallel 度下,每张 GPU 仍需缓存大量 KV 状态。
- DeepSeek 进一步在推理阶段吸收低秩投影矩阵,直接用 latent head 参与注意力计算,使得其算术强度是 MQA 的两倍。
本文方案
-
本文分析了算术强度、并行化能力与模型质量之间的关系,并质疑当前架构是否充分利用了现代硬件的潜力。为此,本文重新设计了注意力机制,旨在在不牺牲并行扩展性的前提下,通过每字节加载更多计算量来最大化硬件效率。
- 提出 Grouped-Tied Attention (GTA):将 key 和 value 表示绑定为一个共享状态,由小规模 query 组共享。相较于同组大小的 GQA,GTA 能将 KV 缓存减少一半,并将算术强度提升至 2 倍,同时保留模型质量和并行性。
- 提出 Grouped Latent Attention (GLA):一种更适合并行计算的 latent attention 变体,结合底层优化。GLA 保持与 MLA 类似的模型质量,在推测性解码中,当 query 长度 ≥2 时可实现最高 2× 的加速。在在线推理基准中,GLA 可将端到端延迟降低并将 token 吞吐提升最多 2 倍。
-
在中等规模语言建模任务(使用 FineWeb-Edu 数据集)中验证了这两个变体的效果:
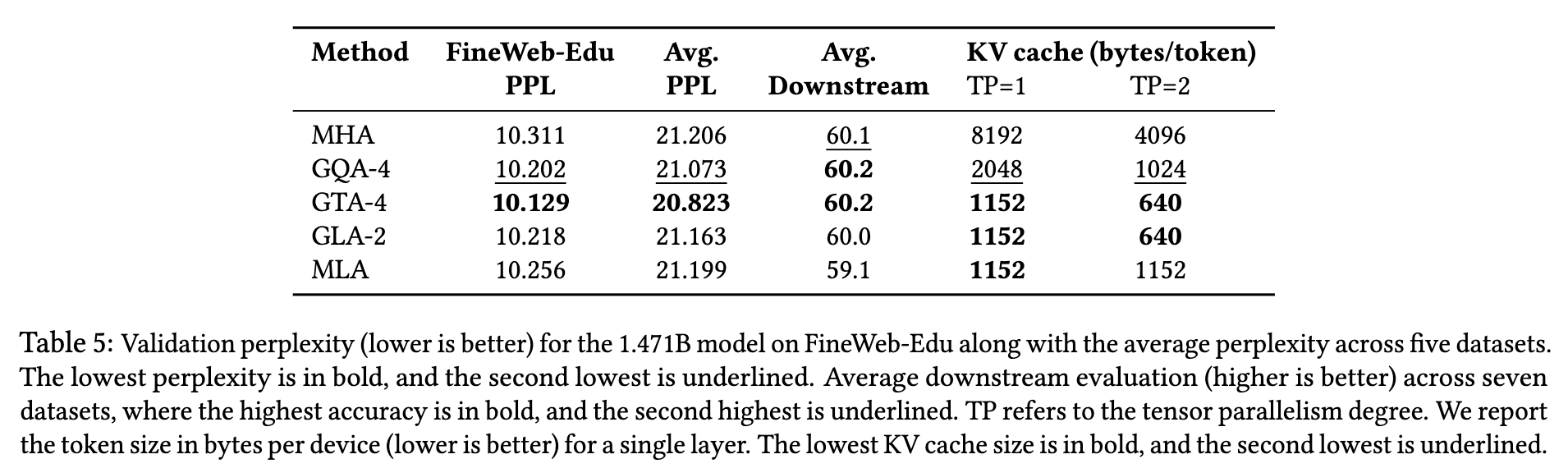
- 在一个 XL 模型(1.47B 参数)中,GTA 达到困惑度(perplexity)10.12(GQA 为 10.20),GLA 实现平均下游准确率 60.0%、困惑度 10.21(MLA 为 59.1%、10.25)。
- 在大模型(876M 参数)中,GTA 困惑度为 11.2,准确率 57.6%(优于 GQA 的 11.3 和 56.9%)。
- 在中型模型(433M)中,GLA 的准确率为 55.4%,略高于 MLA 的 54.9%。
-
图 1 显示了解码阶段,MLA(左)与 GLA-2(右)在内存加载过程中的对比。GLA-2 通过减小数据搬移并提升算术强度,实现更高的硬件效率。
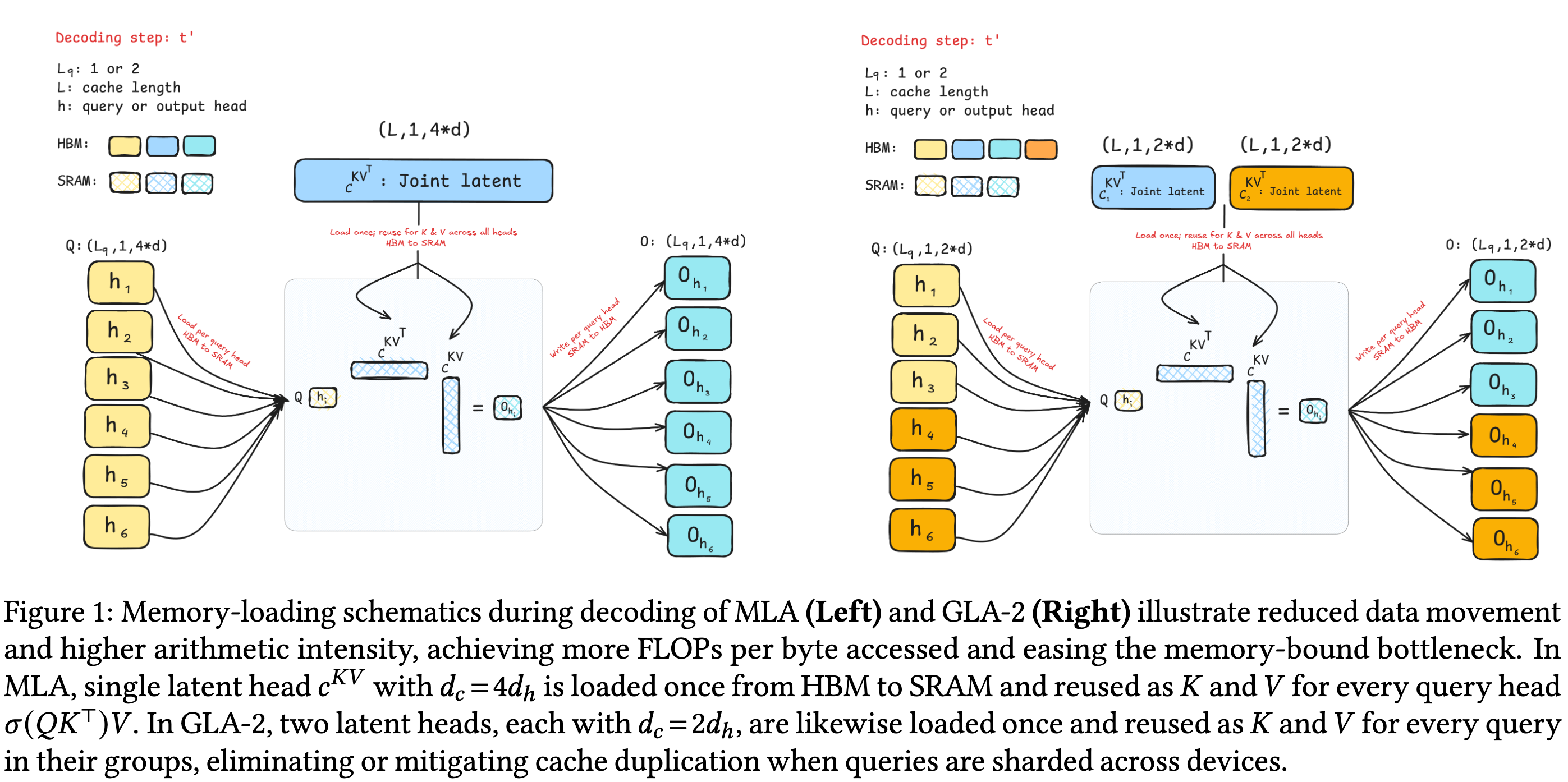
2 前置知识
2.1 面向推理优化的注意力机制
MQA(Shazeer, 2019)通过在多头注意力(MHA)中仅缓存一个 KV 头,大幅减少 KV 缓存大小,从而加快解码速度。然而,这种极端共享方式牺牲了模型质量。在分布式推理中,由于通常在注意力头的维度上划分工作,每个设备都必须复制这一个 KV 头,以保证所有 query head 都能访问到,从而抵消了内存节省的优势(Pope 等,2022)。
GQA(Ainslie 等,2023)对此进行了改进,通过将 query 头分组,每组共享一个独立的 KV 头。这种方式在分布式推理中几乎无需复制 KV 缓存,也不会带来额外的内存开销,因此在保留较高模型质量的同时,降低了 KV 缓存大小。为保持模型性能,GQA 需使用适度数量的分组,但这会导致当序列较长或批量较大时,如果设备数量少(例如张量并行度为 2),每个 GPU 上的 KV 缓存仍会超出 HBM 容量。仅当设备数量足够多(如 8 路并行)时,KV 缓存才会显著缩小。
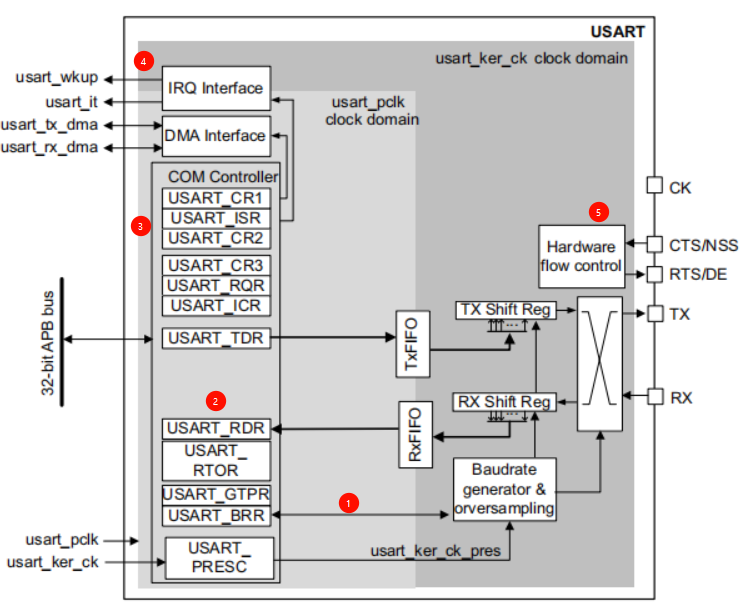
MLA(Multi-head Latent Attention)最早在 DeepSeek V2(2024)中提出,后被广泛应用于 DeepSeek R1(2025)与 FlashMLA(Li,2025)。该方法将每个 token 的隐藏状态压缩为一个低秩 latent 向量 c K V c_{KV} cKV,只缓存这一向量,并在计算注意力前重新投影为全头维度的 K/V,保留每个头的特征。
为进一步降低开销,MLA 的设计将 K/V 合并为一个低秩共享表示,并在解码阶段通过将 K 的上投影矩阵吸收进 Q 矩阵,将 V 的上投影吸收进输出矩阵 W O W_O WO,从而避免显式构造 K/V。这意味着query 会直接对 latent 向量进行注意力计算。为了保留位置编码,MLA 将 decoupled RoPE 编码(Su 等,2023)拼接到 latent 向量中,使上述“权重吸收”技巧可行。最终的解码注意力计算公式为:
σ ( Q K ⊤ + Q rope K rope ⊤ ) ⋅ V \sigma(QK^\top + Q_{\text{rope}} K^\top_{\text{rope}}) \cdot V σ(QK⊤+QropeKrope⊤)⋅V
2.2 分布式推理
由于解码的逐 token 顺序性,注意力机制的并行化只能在“head”维度上进行。张量并行(TP) 将注意力层划分至多个设备上,需要频繁地同步激活(如 all-gather 操作),但现代 GPU 的高速互联(如 NVLink)可缓解此开销。
相较之下,数据并行(DP) 在推理中不适用,因为它要求每个 GPU 拷贝完整模型,内存压力巨大;流水并行(PP) 在 token-by-token 解码中存在设备空闲问题。故 TP 是解码阶段的优选方案,它可分布权重,减少加载 KV 缓存时的瓶颈(Su 等,2025)。
2.3 硬件特性
GPU 架构总览:现代 GPU 拥有大量计算单元(如浮点运算单元),被组织为多个流处理器(SMs),并具有层次化内存结构。NVIDIA 的 GPU 还包含用于低精度矩阵乘法的 Tensor Cores。HBM(高带宽内存)用于大容量数据存储,而片上 SRAM(共享内存)用于快速访问。
例如,NVIDIA H100:
- HBM3 容量为 80 GB,带宽 3.35 TB/s
- 每个 SM 具备 256KB SRAM,共 132 个 SM,片上 SRAM 总带宽约为 33 TB/s(NVIDIA, 2022)
执行模型:GPU 执行 kernel,kernel 包含大量线程,组织为 thread blocks,在 SM 上调度执行。每个 block 内,线程以 warp(32 线程)为单位,通过 shuffle 指令或共享内存进行通信。计算过程从 HBM 加载数据,执行计算后再写回 HBM。
性能指标:操作可分为计算受限或内存受限。关键在于算术强度(Arithmetic Intensity):每字节内存访问对应的 FLOPs 数。
3 方法论
3.1 解码阶段的算术强度视角
在解码时,大规模的 GEMM 操作变为更小的 GEMV 操作。每个 BF16(2 字节)元素仅与一个 token 的 query 做一次乘加(MAC,2 FLOPs),算术强度为 1,远低于 H100 的理论上限(~295 FLOPs/byte, 也即 989 T F L O P s 3.35 T B / s \frac{989 TFLOPs}{3.35 TB/s} 3.35TB/s989TFLOPs)。因此 tensor cores 使用率极低,GPU 利用率可低至 7%(Recasens 等,2025)。
理论上,这些硬件能处理高两个数量级的 FLOPs 而不增加延迟,但实际速度受限于 kernel 开销与通信瓶颈。现代 GPU 计算能力增长远快于内存带宽,每两年 FLOPs 增长约 3 倍,而 HBM 带宽仅增 1.6 倍(Gholami 等,2024)。
缓解策略包括:
- kernel 融合
- 数据 tiling 提高片上复用
- 选择性重计算中间结果
- 注意力重排序以减少 off-chip 传输(Dao 等,2022)
3.2 提高算术强度的设计策略
GQA 通过在每个 KV 头下共享多个 query 头,使得操作次数不变但内存访问减少,从而算术强度提升(比例为分组大小 g q = h q / h k v g_q = h_q / h_{kv} gq=hq/hkv)。
MQA 是极端情况,所有 query 共享一个 KV 头,算术强度约为 h q h_q hq。
MLA(DeepSeek 提出) 则通过:
- 缓存单一 latent head,
- 将该 latent 同时作为 key 和 value,
- 增加 query head 数量,
实现了远高于 MQA 的算术强度。其 latent 表示不会 materialize 出具体 K/V,而是直接用于 attention 计算。
此外,使用低秩投影矩阵减少参数后,可在不增加总体参数量的前提下,增加 query 头数量,从而进一步提升算术强度。
表格说明(表 1):

定义:
- L L L:序列长度
- h q h_q hq:query 头数量
- h k v h_{kv} hkv:KV 头数量
- g q = h q / h k v g_q = h_q / h_{kv} gq=hq/hkv:每个 KV 头所对应的 query 头数
- m k v ∈ { 1 , 2 } m_{kv} \in \{1, 2\} mkv∈{1,2}:KV 是否共享(1 为共享,即 K = V K=V K=V;2 为分开,即 K ≠ V K \ne V K=V)
算术强度 ≈
2 ⋅ L ⋅ h q 2 ⋅ h q + m k v ⋅ h q g q ≈ 2 g q m k v , 当 L ≫ h q \frac{2 \cdot L \cdot h_q}{2 \cdot h_q + m_{kv} \cdot \frac{h_q}{g_q}} \approx \frac{2g_q}{m_{kv}}, \quad \text{当 } L \gg h_q 2⋅hq+mkv⋅gqhq2⋅L⋅hq≈mkv2gq,当 L≫hq
KV 缓存字节数 ≈
KVBytes = m k v ⋅ B ⋅ L ⋅ h q g q ⋅ d h ⋅ sizeof(dtype) \text{KVBytes} = m_{kv} \cdot B \cdot L \cdot \frac{h_q}{g_q} \cdot d_h \cdot \text{sizeof(dtype)} KVBytes=mkv⋅B⋅L⋅gqhq⋅dh⋅sizeof(dtype)
并行性与冗余约束:
提高 g q g_q gq 虽能增加算术强度,但也会导致 KV 头数量变少,从而增加 KV 缓存在各设备间的复制,降低并行扩展性。设:
- N N N:张量并行设备数量,
- 复制因子 D = N ⋅ g q h q D = \frac{N \cdot g_q}{h_q} D=hqN⋅gq
则:
- 若 D = 1 D = 1 D=1,为零冗余并行,最优;
- 要满足 g q ≤ h q / N g_q \le h_q / N gq≤hq/N,否则每个设备将持有冗余参数副本,无法扩展。
3.3 硬件高效且可并行化的注意力机制
3.3.1 Grouped-Tied Attention(GTA)
奇异值分布显示,Key 缓存存在显著低秩性,几乎所有方差都集中在少数主方向中,表明 key 存在于一个低秩子空间中,且存在大量冗余(Saxena 等,2024)。这种效应在应用 RoPE 编码之前更加明显(Yu 等,2024a;Sun 等,2024)。
多个研究指出,只对每个 head 的部分维度施加 RoPE 编码即可保持模型准确性,因此对整个维度旋转并不能带来质量提升(Black 等,2022;Barbero 等,2025)。既然 key 本身就处于低秩空间,且位置编码只需旋转部分维度,那么每次都对整个向量施加 RoPE 并缓存 full-rank key 是内存的浪费。
因此,我们提出:
- 仅对 key 的部分通道应用 RoPE 旋转(用于位置编码)
- 未旋转部分为低秩冗余部分,可与 value 状态绑定共享

在 GQA 的基础上,我们结合 low-rank 和部分 RoPE 的观察,提出 Grouped-Tied Attention(GTA)。该方法具备以下特点:
- 类似 GQA,每组 query heads 共享一个独立 KV 头
- 更进一步,将 Key 和 Value 的 projection 参数绑定为一个共享状态(tied KV)
- 仅对 Key 的一半维度应用 RoPE
如下所示:
- Value 路径:使用整个 tied KV 向量
- Key 路径:前一半使用 tied KV 中的未旋转部分,后一半来自一个独立的 RoPE 编码 single-head 投影,该部分会广播至所有组并拼接形成完整的 key 向量
实验证明,若对共享部分施加 RoPE,再用于 value 路径,即便在之后做逆旋转,也会损害模型质量,因此该共享部分永远不施加 RoPE。
定义如下:
- Q ∈ R B × L × h q × d h Q \in \mathbb{R}^{B \times L \times h_q \times d_h} Q∈RB×L×hq×dh
- K V , K , V ∈ R B × L × h k v × d h KV, K, V \in \mathbb{R}^{B \times L \times h_{kv} \times d_h} KV,K,V∈RB×L×hkv×dh
- K RoPE ∈ R B × L × 1 × d h 2 K_{\text{RoPE}} \in \mathbb{R}^{B \times L \times 1 \times \frac{d_h}{2}} KRoPE∈RB×L×1×2dh
- K NoPE ∈ R B × L × h k v × d h 2 K_{\text{NoPE}} \in \mathbb{R}^{B \times L \times h_{kv} \times \frac{d_h}{2}} KNoPE∈RB×L×hkv×2dh
最终拼接方式:
K = concat ( K NoPE , broadcast h k v ( K RoPE ) ) , V = K V [ : , : , : , : ] K = \text{concat}(K_{\text{NoPE}}, \text{broadcast}_{h_{kv}}(K_{\text{RoPE}})), \quad V = KV[:,:,:,:] K=concat(KNoPE,broadcasthkv(KRoPE)),V=KV[:,:,:,:]
优势:
- 加载一个 KV 状态到片上内存即可复用为 Key 与 Value
- 在每组 Query 中共享使用,减少内存搬运
- 相比 GQA 算术强度翻倍、KV 缓存减半
例如,GQA-4 表示 4 个独立 KV 头,GTA-4 表示 4 个绑定共享 KV 头。实验证明,在困惑度和下游任务表现上,GTA 与 GQA 相当。
3.3.2 Grouped Latent Attention(GLA)
MLA 使用低秩的 KV 联合压缩,每个 token 缓存一个维度为 d c = 4 d h d_c = 4d_h dc=4dh 的 latent 头。由于张量并行(TP)会将 key 和 value 的上投影矩阵以列并行方式分布在多个设备上,因此每个设备都必须完整保留该 latent 向量以重建其所需的 key/value。这意味着:每个设备都复制了 latent KV 缓存,其总占用与并行设备数成正比。
与之相比,GQA 缓存 2 h k v d h 2h_{kv}d_h 2hkvdh 个元素,如果 d c < 2 h k v d h d_c < 2h_{kv}d_h dc<2hkvdh 且 h k v > 2 h_{kv} > 2 hkv>2,则 GQA 的 KV 缓存可能比 MLA 更大。但在 TP=4 时,MLA 与 GQA-8 的每设备缓存占用相近,而后者来自原始模型结构所分配的缓存占用是前者的约 4 倍。
问题在于:虽然 MLA 的结构使得算术强度高,但由于 latent 是全头共享的,因此无法按头划分分片,阻碍分布式并行扩展性。
为此,我们提出 Grouped Latent Attention(GLA),具有以下特征:
- 将 token 压缩为多个 latent head(记为 h c h_c hc 个,每个维度为 d c = 2 d h d_c = 2d_h dc=2dh,是 MLA 的一半)
- 每个 latent head 通过其上投影矩阵,重建属于其 query 分组的特定 key 和 value
- 投影矩阵列数为 g q ⋅ d h g_q \cdot d_h gq⋅dh 而非 MLA 的 h q ⋅ d h h_q \cdot d_h hq⋅dh
权重吸收后,每个 latent 仅与其 group 的 query 头交互。GLA 可将 latent head 按 TP rank 分片,从而避免 latent KV cache 的冗余复制,并保持并行性。
例如:
- 设置 h c = 2 h_c = 2 hc=2,每个 latent 为 2 d h 2d_h 2dh,总维度仍为 4 d h 4d_h 4dh
- TP = 2 时,每个设备缓存 1 个 latent head
- 每个 TP rank 执行对应的 attention 计算,最后通过 AllReduce 聚合输出
数学表达如下:
- c K V 0 , c K V 1 ∈ R B × L × 2 d h c_{KV_0}, c_{KV_1} \in \mathbb{R}^{B \times L \times 2d_h} cKV0,cKV1∈RB×L×2dh
- Q 0 , Q 1 ∈ R B × 1 × h q 2 × 2 d h Q_0, Q_1 \in \mathbb{R}^{B \times 1 \times \frac{h_q}{2} \times 2d_h} Q0,Q1∈RB×1×2hq×2dh
- 输出合并:
O 0 = softmax ( Q 0 ⋅ c K V 0 ⊤ ) ⋅ c K V 0 , O ~ 0 = O 0 W v o 0 O_0 = \text{softmax}(Q_0 \cdot c_{KV_0}^\top) \cdot c_{KV_0}, \quad \tilde{O}_0 = O_0 W_{vo0} O0=softmax(Q0⋅cKV0⊤)⋅cKV0,O~0=O0Wvo0
O = AllReduce ( O ~ 0 + O ~ 1 ) O = \text{AllReduce}(\tilde{O}_0 + \tilde{O}_1) O=AllReduce(O~0+O~1)
相较 MLA,GLA 的优势:
- 不需要在每个 TP rank 复制 latent,每个设备缓存更少
- 解码时每步数据搬运更小,端到端延迟更低
- 更容易在实际部署中处理 不等长序列、batch 小等情况
例如:
- 设置 GLA-4:latent 被分为 4 个 head,每个为 2 d h 2d_h 2dh,总 KV 缓存仍为 4 d h 4d_h 4dh,但 每个设备只加载 1/4 的 KV
- TP=4、DP=2 时,对比 MLA,GLA 每设备缓存减半,吞吐量更高
在我们的实验中,使用 h c = 2 h_c=2 hc=2 的 GLA,在最大 1.471B 模型下,与 MLA 质量相当,但在 TP≥2 时,每设备缓存减半。
算术强度分析(详见表 1):
- GLA 的算术强度约为 2 g q 2g_q 2gq,是 GQA 的两倍
- GLA-2 的 FLOPs/Byte 与最激进的 MQA 接近,但质量更高
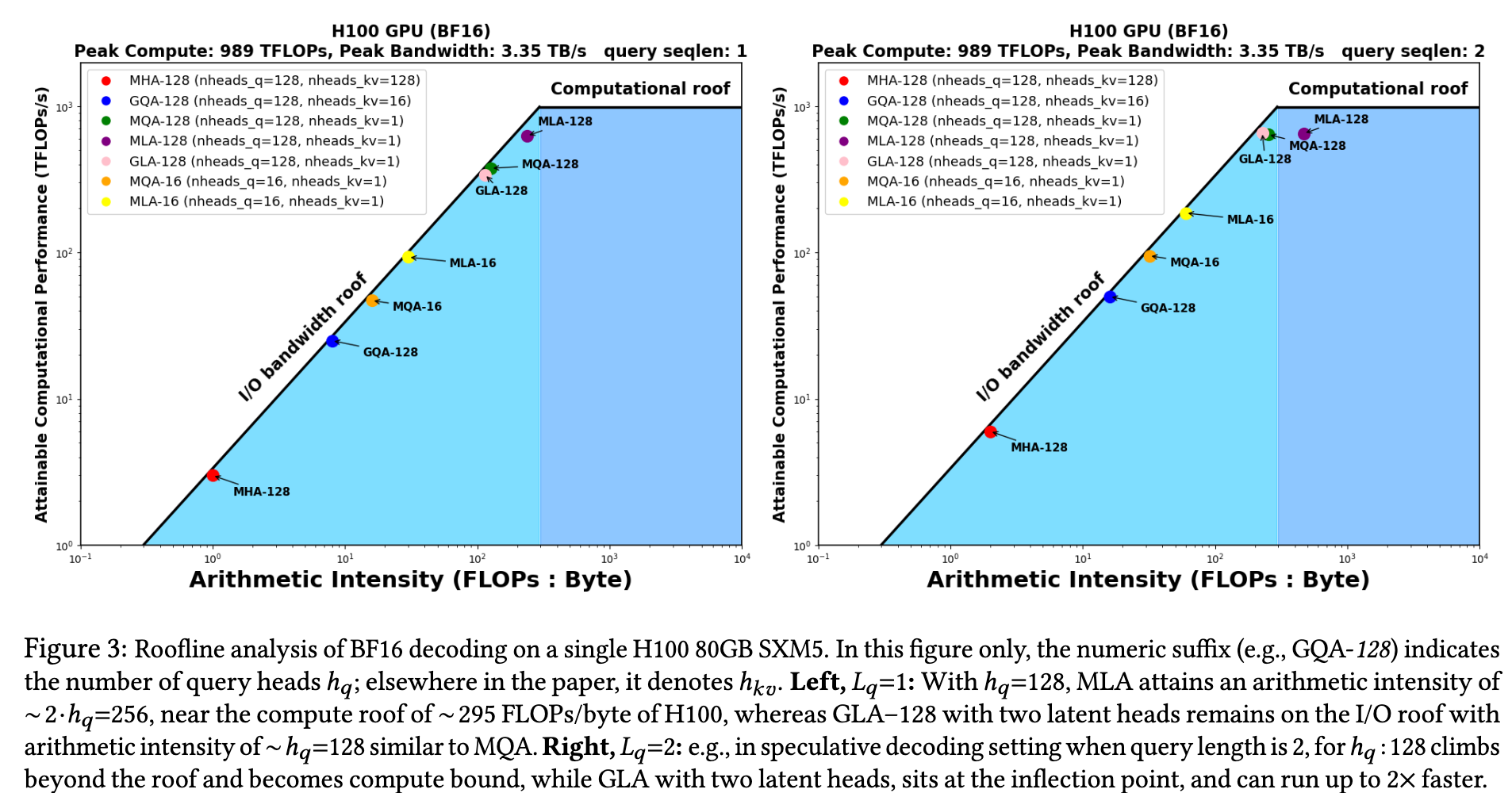
4 系统优化:异步执行与分布式偏移计算
我们提出了一套系统优化策略,以在现代硬件(如 H100 GPU)上充分释放 MLA、GTA 与 GLA 的性能潜力。由于现代 GPU 拥有极快的 Tensor Core 等专用矩阵乘单元(参见第2.3节),为了保持 Tensor Core 始终处于高负载,我们需要仔细设计软件流水线与 warp 专用化(warp specialization) 的组合,以实现计算与内存加载的最大重叠。
4.1 软件流水线与 Warp 专用化的异步优化
我们采用了两种策略来实现计算与内存加载的重叠:
-
软件流水线(Software Pipelining):在使用当前 KV block 进行计算的同时,提前加载下一个 KV block(Lam, 1988),从而避免因等待数据加载而使 Tensor Core 空闲。
-
Warp 专用化(Warp Specialization):
- 使用部分 warp 执行内存加载,借助 TMA(Tensor Memory Accelerator)或异步复制指令
cp.async; - 其他 warp 负责执行矩阵乘累加(MMA)操作;
- 前者称为生产者 warp,后者为消费者 warp(Bauer 等,2014)。
- 使用部分 warp 执行内存加载,借助 TMA(Tensor Memory Accelerator)或异步复制指令
该策略广泛用于矩阵乘法(Thakkar 等,2023)与注意力机制(Shah 等,2024a)。通过解耦内存与计算任务,warp 调度器能自然地重叠执行内存加载与计算操作。
4.2 分布式偏移计算:支持 Paged KV 缓存
随着 MLA、GTA 与 GLA 等新型注意力机制对计算与内存子系统提出更高要求,系统需尽可能快速完成内存加载。Paged KV(Kwon 等,2023)已成为 KV 缓存的标准存储格式,但其分页结构不便于使用 TMA,因为 TMA 适用于连续内存块的加载与地址边界检查。
因此我们采用 cp.async 异步加载指令,由每个线程单独发起加载请求。挑战在于,地址计算成本高昂,因为 64 位整数索引通常需多个指令完成。
为此,我们设计了一种跨线程协作计算地址的方法。例如在 head 维度为 128 时,从全局内存加载一个 128 × 128 128 \times 128 128×128 的 KV 块至共享内存的过程如下:
-
将 128 个线程划分为 8 个小组(每组16个连续线程),编号 g = 0 , 1 , . . . , 7 g = 0, 1, ..., 7 g=0,1,...,7,每组负责加载其对应的行(如: g , g + 8 , g + 16 , . . . , g + 120 g, g+8, g+16, ..., g+120 g,g+8,g+16,...,g+120)。
-
每个线程 t t t 属于第 g = ⌊ t / 16 ⌋ g = \lfloor t/16 \rfloor g=⌊t/16⌋ 组,其加载任务对应行为 g + ( t m o d 16 ) × 8 g + (t \bmod 16) \times 8 g+(tmod16)×8。线程从页表中读取页索引,计算目标 KV 所在地址并写入寄存器。
-
每个组的 16 个线程使用 warp shuffle 指令 互相传递目标地址,然后并行加载对应 KV 数据行。
优势:每个线程只需存储 1 行的地址偏移,而不是整组 16 行。即便使用极小页大小(如 page size = 1),也不会引入额外开销,从而解锁如 RadixAttention(Zheng 等,2024b)所需的按 token 精确分页缓存(Prefix Caching)。详见附录 B.5,我们在 GLA 中测得 paged KV 的解码速度提升达 1.2–1.5 倍。
5 实验与结果
我们实证验证了 GTA 和 GLA 的方法:
- (1)模型质量可与 GQA 和 MLA 相媲美;
- (2)并行扩展性良好;
- (3)能在如 H100 等现代硬件上高效运行。
例如,GLA 实现了与 MLA 相似的上下游质量表现,但更易于分片部署。在 speculative decoding(推测式解码)设置中,我们优化后的 GLA kernel 相比 DeepSeek FlashMLA 快最多 2 倍。
GLAₛ(GLA-q)表示 latent query 被分片配置,消除了 query down projection 跨设备的重复,并减少每设备参数量(此配置用于消融研究,因为 query latent 并不缓存)。
实验设置
我们在四种规模上训练模型:
- 小型(183M)
- 中型(433M)
- 大型(876M)
- 超大(XL,1.471B)
使用数据集 FineWeb-Edu-100B(Lozhkov 等,2024),训练设置参考 GPT-3(Brown 等,2020)架构,模型框架为 LLaMA 3(Grattafiori 等,2024):
- 小型模型训练语料为 250 亿 token;
- 中、大、超大模型训练语料为 500 亿 token。
5.1 模型质量(Model Quality)
5.1.1 验证困惑度(Validation Perplexity)
我们不仅在 FineWeb-Edu 验证集的 1 亿个 token 上评估验证困惑度,还在另外四个数据集上进行了评估:RedPajama v1(Weber 等,2024)中的 Wikipedia 和 C4 子集、Cosmopedia(Ben Allal 等,2024)、Pile(Gao 等,2020),每个数据集也使用 1 亿个 token。表 2 和表 5 报告了五个数据集的平均困惑度。
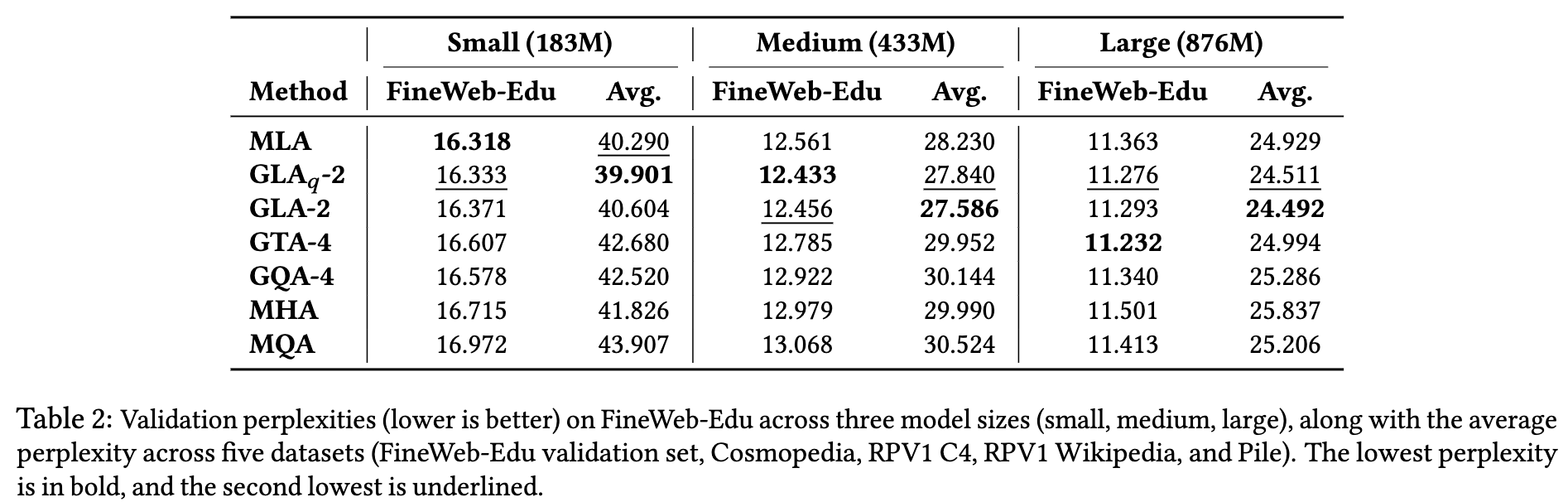
在 large 模型中,我们对 MLA 与 GLA 默认使用 RoPE 编码维度 d R = 32 d_R = 32 dR=32。在 medium 与 large 模型规模上,小型(183M)GLA-2 在困惑度上优于 MLA,而在 small 模型规模上表现持平。
GTA 解决了 GQA 在低 TP 并行度下无法降低每设备 KV 缓存的问题,并在 medium 与 large 规模上显著降低了困惑度。
对于 large 模型:
- GLA-2 与 GLAₛ-2(GLA-q)表现相当,困惑度最低(24.49–24.51),优于 MLA(24.93)
对于 XL 模型(1.47B):
- GTA-4 的困惑度优于 GQA-4(10.12 vs. 10.20)
- GLA 优于 MLA(10.21 vs. 10.25,见表 5)
5.1.2 下游任务评估(Downstream Evaluation)
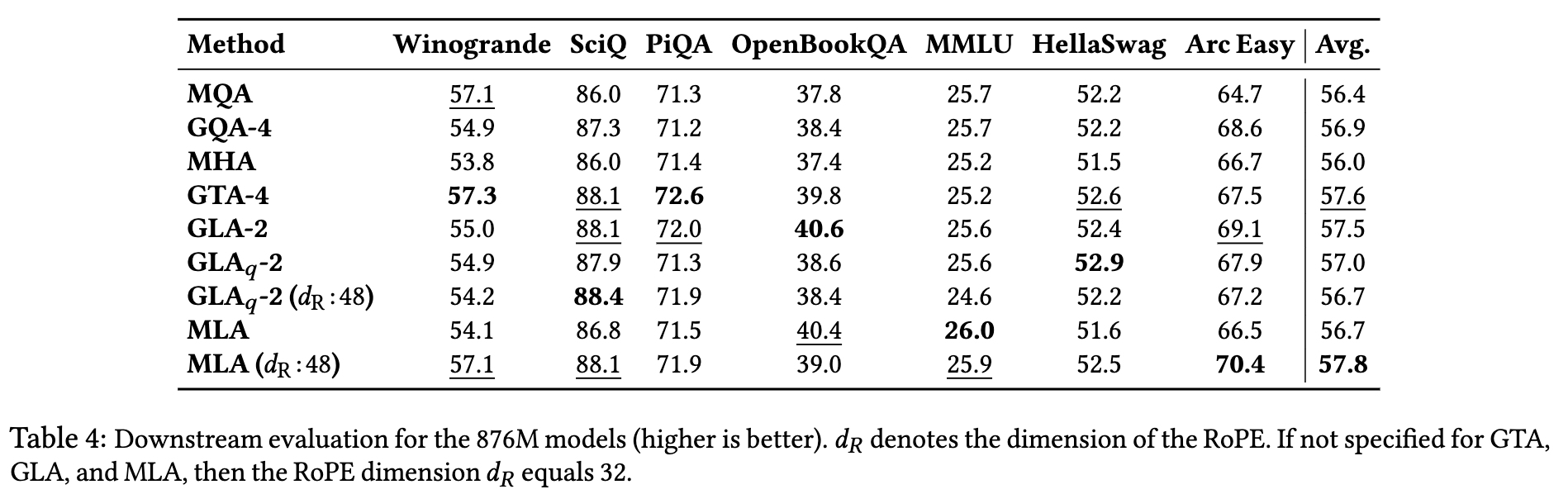
我们评估了零样本(zero-shot)性能,涵盖多个标准基准任务:
- SciQ(Welbl 等,2017)
- OpenBookQA(Mihaylov 等,2018)
- ARC-Easy 子集(Yadav 等,2019)
- HellaSwag(Zellers 等,2019)
- PIQA(Bisk 等,2020)
- WinoGrande(Sakaguchi 等,2020)
- MMLU(Hendrycks 等,2021)
在这些任务上,我们提出的注意力机制能保持或提升准确率:
- 中型模型(433M):GLA-2 平均准确率 55.4%,略高于 MLA(54.9%)(表 3)
- 大型模型(876M):GLA-2 准确率 57.5%,与 GTA-4(57.6%)几乎持平,优于或匹配 GQA-4(表 4)
- 超大模型(1.471B):GLA-2 达 60.0%,高于 MLA(59.1%);GTA-4 与 GQA-4 均为 60.2%(表 5)
这表明,我们的硬件友好注意力机制从中型到超大型模型均不损失模型质量,甚至略有提升。
5.2 并行化能力(Parallelization)
GLA 通过将 latent head 分片实现 GPU 间负载均衡与缓存缩减,加速解码过程。相比之下,MLA 需要在每个 GPU 上重复其单个大 latent 头,因此在 TP 中存在 KV 缓存复制的问题。
早期系统尝试通过混合 TP + DP 的方式缓解 MLA 的缓存问题,即将不同批次分配给不同设备(适用于大批量或高并发请求)。
我们验证了 GLA 的扩展能力,平台为:
- DeepSeek Coder V2 Base(236B 总参数,21B 激活参数)
- 量化至 FP8
- 使用 FlashAttention-3 核心,部署在 SGLang 框架中(Zheng 等,2024b)
实验对比:
- 纯 TP(8×H100)
- 混合并行:TP + 2路或 4路 DP
混合并行下,仅复制注意力子模块,输出在 MoE FFN 前聚合并重新分配,以避免 MLA 缓存冗余。
GLA 配置支持“零冗余”分片(latent head 在 TP 维度平均分布),因此相较 MLA:
- 每设备加载更小的 KV 缓存
- 并行效率更高
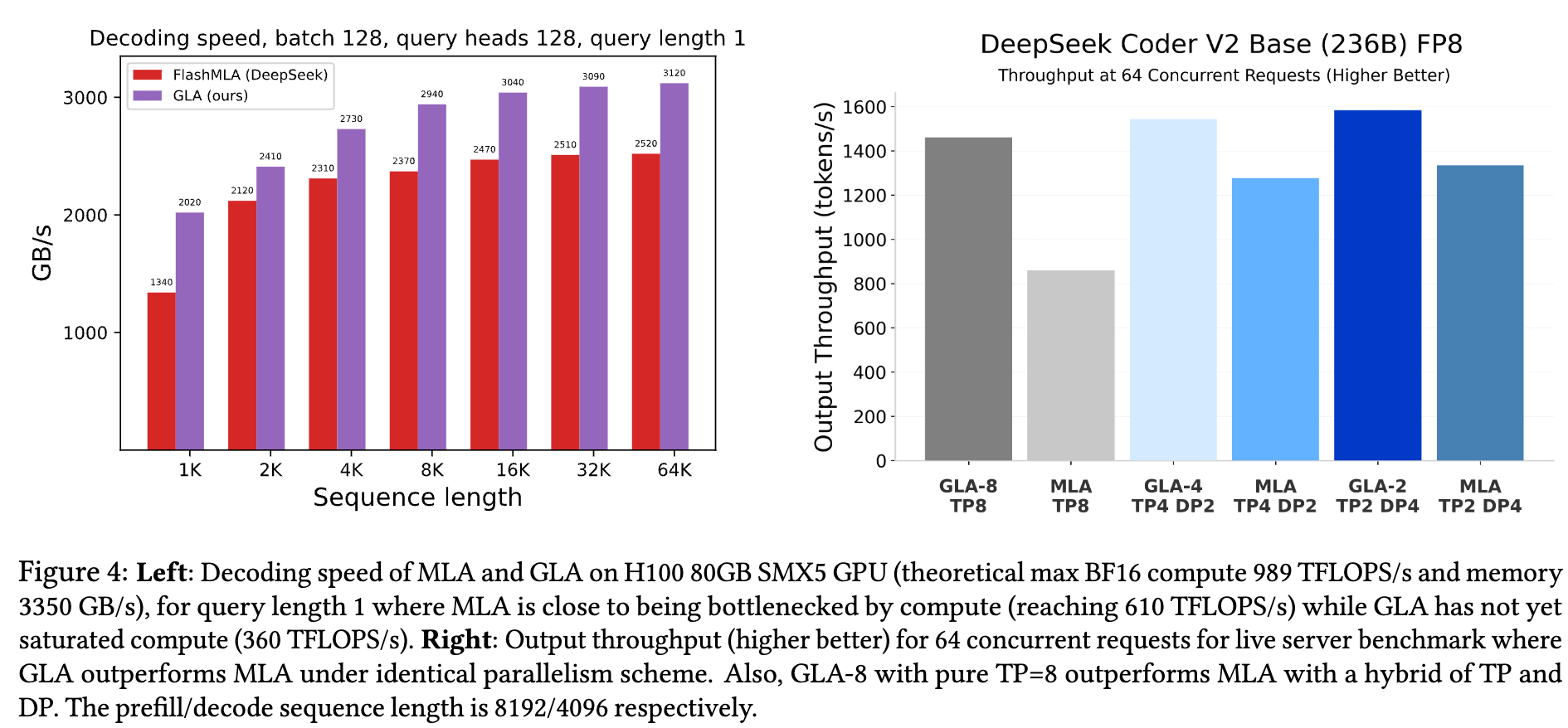
如图 4(右)所示:
- GLA-8( h c = 8 h_c = 8 hc=8, d c = 256 d_c = 256 dc=256)在 8×H100 上吞吐量为 MLA( d c = 512 d_c = 512 dc=512)的 2 倍
- 即使使用相同的 TP+DP 配置,GLA 仍优于 MLA(因为 latent head 无重复)
此外,即使仅使用 纯 TP=8 的 GLA-8,仍优于 TP=2 + DP=4 的 MLA,表现出出色的并行性与吞吐率提升能力。
现实部署中常面临的挑战如:
- 序列长度不一致
- 小 batch 导致 GPU 空闲
GLA 的架构天然适配这些情况,更适合高并发与延迟敏感任务场景。
6 讨论
GTA 与 GQA 的缓存比较
与 GQA 相比,在相同 KV 头数量下,GTA 通过对 KV 进行绑定共享,大约将未分片 KV 缓存减半。例如,在 TP = 8 且 KV 头为 8 的情况下,GTA-8 每个 token 储存 1.5 d h 1.5 d_h 1.5dh,其中一半( d h / 2 d_h/2 dh/2)来自单独的 RoPE 投影,而 GQA-8 储存 2 d h 2 d_h 2dh,节省幅度为 25%。
但若 TP 降为 4,差距更明显:
- GTA-8 每 token 为 2.5 d h 2.5 d_h 2.5dh
- GQA-8 为
4
d
h
4 d_h
4dh
→ 表明在中等并行度下,GTA 带来更显著的内存节省。
GLA 与 MLA 的比较与拓展
我们的 GLA 实验使用两个 latent head,使其未分片的 KV 缓存与 MLA 相等。但在 TP ≥ 2 的情况下,GLA 每设备的缓存缩减为一半,而 MLA 则在所有设备间复制 KV 缓存。
在 1.471B 模型规模下,GLA 和 MLA 的模型质量保持可比。未来值得探索更大规模模型下 GLA 的性能,如 Llama 4 系列(最大达 400B 参数)采用 GQA-8( h q = 40 h_q = 40 hq=40, h k v = 8 h_{kv} = 8 hkv=8),若 TP = 8,每设备每 token KV 缓存为 2 d h 2 d_h 2dh。超过该并行度后将发生 KV 缓存重复。
在相同配置下,GLA-8(8 个 latent head)每 token 每设备缓存略高( 2.5 d h 2.5 d_h 2.5dh,其中 d h / 2 d_h/2 dh/2 为 RoPE 部分),但是否能在近似缓存预算下提升质量仍待研究。
在 1.471B 规模实验中:
- GLA-2 验证困惑度为 10.218,GQA-4 为 10.202
此外,RoPE 所占额外缓存( d h / 2 d_h/2 dh/2)可通过只在部分层应用 RoPE 减轻开销,该策略已在 Cohere(Yang 等,2025)和 Llama 4(Meta AI,2025)中应用。
模型压缩与算术强度
第 3.2 节指出:算术强度随 Query Head 数量增加而提升。附录 B.3 探索了使用低秩投影替代 full-rank query/output 投影以减少参数量,并通过增加每组 Query Head 数量来补偿能力损失,进一步提升算术强度、GPU 利用率。
在小规模模型中,此策略的验证困惑度相较基线略微下降(差值约 0.1–0.2)。该类权衡仍需更系统的评估。
Conclusion
- GTA 是 GQA 的高效替代方案,仅需一半 KV 缓存
- GLA 是 MLA 的实用替代方案,具备更好的可扩展性与解码速度