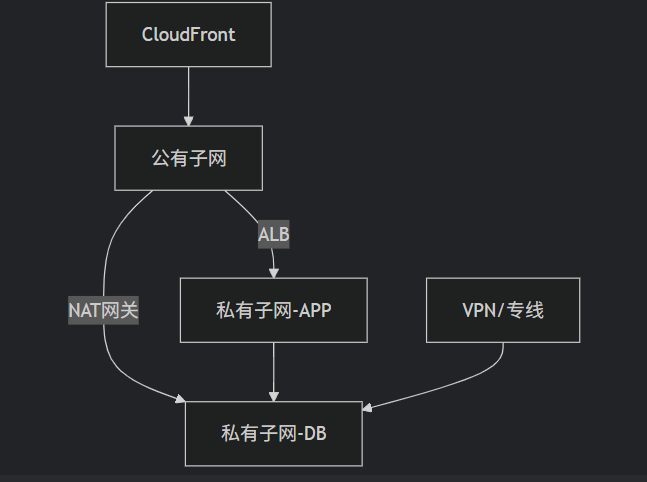
一、为什么机器需要“试错学习”?——强化学习的核心秘密
你有没有玩过《超级马里奥》?当你操控马里奥躲避乌龟、跳过悬崖时,其实就在用一种“试错”的方法学习最优路径。强化学习(Reinforcement Learning, RL)就是让机器像人类玩游戏一样,通过不断尝试和环境反馈来学会做决策的技术。只不过机器的“游戏”可能是开车、下棋、推荐商品等更复杂的场景。
1. 强化学习的三大角色
- 智能体(Agent):像游戏中的马里奥,是做决策的主体,比如自动驾驶汽车、下棋程序。
- 环境(Environment):智能体所处的世界,比如马路、棋盘,环境会给智能体反馈。
- 奖励(Reward):环境对智能体动作的打分,比如马里奥吃到金币+10分,碰到敌人-5分。
2. 核心公式:用数学描述“学习目标”
智能体的终极目标是最大化未来奖励的总和。用公式表示就是:
G
t
=
R
t
+
1
+
γ
R
t
+
2
+
γ
2
R
t
+
3
+
…
G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \dots
Gt=Rt+1+γRt+2+γ2Rt+3+…
- G t G_t Gt:从时刻t开始的总奖励
- R t + k R_{t+k} Rt+k:时刻t+k获得的奖励
- γ \gamma γ(伽马):折扣因子,比如明天的1分奖励可能不如今天的1分重要,通常取0.9左右
举个例子:假设你在玩一个“写作业游戏”,状态是“是否写完作业”,动作是“写作业”或“玩游戏”。奖励规则是:写完作业+100分(未来还能看动画片),没写完-50分(被妈妈批评)。你会选择先写作业,因为长远来看总奖励更高,这就是强化学习的逻辑!
二、机器如何“学会”做决策?——强化学习的实现步骤
1. 第一步:把世界“翻译”成机器能懂的语言(环境建模)
- 状态(State):环境的“快照”,比如开车时的车速、周围车辆位置,用数字或图像表示。
示例:在“红绿灯路口决策”中,状态可以是:
[红灯/绿灯状态,本车速度,前车距离,左右车道车辆速度] - 动作(Action):智能体的可选操作,比如开车时“加速”“刹车”“变道”。
表格表示:状态(红绿灯颜色) 可选动作 红灯 刹车停车 绿灯 保持速度/加速通过
2. 第二步:设计“游戏得分规则”(奖励函数)
奖励函数是强化学习的“指挥棒”,决定了智能体的行为方向。
案例:智能扫地机器人
- 碰到家具 → 奖励-10分(避免碰撞)
- 清扫完房间 → 奖励+100分(核心目标)
- 每移动1米 → 奖励+1分(鼓励高效工作)
公式化表达:
R
(
s
,
a
)
=
{
+
100
if 清扫完成
−
10
if 碰撞
+
1
otherwise
R(s,a) = \begin{cases} +100 & \text{if 清扫完成} \\ -10 & \text{if 碰撞} \\ +1 & \text{otherwise} \end{cases}
R(s,a)=⎩
⎨
⎧+100−10+1if 清扫完成if 碰撞otherwise
3. 第三步:选择学习策略——无模型学习 vs 有模型学习
(1)无模型学习:像玩新游戏一样瞎试
-
Q-Learning算法:用表格记录每个状态-动作的“得分”(Q值),每次选Q值最高的动作。
公式:
Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s,a) \leftarrow Q(s,a) + \alpha \left[ r + \gamma \max_{a'} Q(s',a') - Q(s,a) \right] Q(s,a)←Q(s,a)+α[r+γa′maxQ(s′,a′)−Q(s,a)]- α \alpha α(阿尔法):学习率,比如0.1表示慢慢更新表格
- 类比:你第一次学骑自行车时,每次摔倒后调整姿势,慢慢记住“车向左歪时要向右打方向盘”。
-
深度Q网络(DQN):用神经网络代替表格,处理图像等复杂状态,比如AlphaGo用CNN识别棋盘。
(2)有模型学习:先“脑补”世界再行动
- 蒙特卡洛树搜索(MCTS):像下棋时先在脑子里模拟几步走法。
步骤:- 选分支:优先选“没试过的走法”或“看起来能赢的走法”
- 模拟:随机走完剩下的步数,看输赢
- 更新:根据模拟结果给走法打分
类比:你考试时遇到选择题,先排除明显错误的选项,再在剩下的选项里“脑补”解题过程。
三、真实世界的“强化学习玩家”——从AlphaGo到自动驾驶
1. AlphaGo:让机器学会下围棋的“超级玩家”
- 三招绝技:
- 策略网络(Policy Network):用人类棋谱训练,预测下一步可能的落子(像模仿高手下棋)。
- 价值网络(Value Network):评估当前棋局的胜率,避免无效搜索(比如一眼看出“这步棋必输”)。
- 蒙特卡洛树搜索(MCTS):结合前两者,优先探索高胜率的走法。
- 突破性成果:2016年击败人类围棋冠军李世石,靠的就是“强化学习+树搜索”的组合拳。
2. 自动驾驶:让汽车学会“看路”和“决策”
- 场景:无保护左转
- 状态:摄像头拍摄的图像(识别行人、车辆)、雷达测量的距离、交通灯状态。
- 动作:左转、等待、鸣笛。
- 奖励函数:
R = { − 1000 碰撞行人 + 50 成功左转 − 1 每等待1秒 R = \begin{cases} -1000 & \text{碰撞行人} \\ +50 & \text{成功左转} \\ -1 & \text{每等待1秒} \end{cases} R=⎩ ⎨ ⎧−1000+50−1碰撞行人成功左转每等待1秒 - 算法:DDPG(深度确定性策略梯度),处理连续动作空间(如方向盘转角)。
四、强化学习的“成长烦恼”——挑战与解决办法
1. 问题1:奖励太少,学不会(奖励稀疏性)
- 例子:机器人学开门,只有最后成功开门才有奖励,中间步骤不知道对错。
- 解决:
- 设计“中间奖励”:比如手靠近门把手时+10分,握住把手时+20分。
- 逆强化学习:观察人类怎么做,反推出奖励规则(比如通过老师批改作业的结果,反推评分标准)。
2. 问题2:不敢尝试新动作(探索-利用平衡)
- 例子:推荐系统总推荐用户看过的内容(利用),不敢推荐新内容(探索),导致用户体验变差。
- 解决:
- ϵ \epsilon ϵ-贪心策略:以10%的概率随机推荐新内容,90%的概率推荐热门内容。
- 好奇心驱动学习:机器自己给自己设置“探索奖励”,比如“没见过的商品页面+5分”。
3. 问题3:计算量太大(算力需求高)
- 例子:AlphaGo训练需要数千块GPU,普通电脑根本跑不动。
- 解决:
- 分布式训练:让多台电脑一起算,像“分工合作写作业”。
- 迁移学习:先用简单游戏(如Atari)预训练模型,再微调适应新任务(如围棋)。
五、未来展望:强化学习如何改变互联网?
1. 通用强化学习(GRL):让机器学会“学习”
未来可能出现一种算法,能像人类一样快速适应不同任务:今天学下棋,明天学开车,后天学写代码。比如DeepMind的IMPALA架构,已经能在多种Atari游戏中表现出色。
2. 神经符号强化学习:让决策“可解释”
现在的强化学习像“黑箱”,机器为什么选这个动作说不清楚。未来可能结合逻辑推理(如“如果前方有行人,必须刹车”),让决策过程像“写作文列提纲”一样清晰。
3. 自然语言控制:用说话指挥机器
你可以对智能音箱说:“帮我规划一个省油又安全的上班路线”,它会自动把语言转化为奖励函数,让汽车优化驾驶策略。这需要强化学习与自然语言处理(NLP)结合。
六、小学生也能懂的强化学习——用“学走路”打比方
假设你是一个刚学走路的小朋友(智能体),环境是客厅,目标是从沙发走到玩具堆(终点)。
- 状态:你当前的位置(离沙发多远,离玩具多远)、身体平衡度(晃不晃)。
- 动作:迈左脚、迈右脚、伸手扶墙。
- 奖励:
- 走到玩具堆 +100分(开心!)
- 摔倒 -50分(疼!)
- 每走稳1步 +10分(中间奖励)
- 学习过程:
一开始你乱走,经常摔倒(探索);慢慢发现“扶墙走更稳”(利用);后来学会先迈左脚再迈右脚,平衡感越来越好(策略优化)。这就是强化学习的核心——在试错中找规律,用奖励指导行动。
结语:从“机器”到“智能体”的进化之路
强化学习让机器不再是被动执行指令的工具,而是能主动“思考”、适应环境的智能体。从互联网推荐系统(猜你喜欢的视频)到工业机器人(智能工厂流水线),它正在悄悄改变我们的生活。虽然现在还有“黑箱”、算力等挑战,但随着技术进步,未来的机器可能像人类一样,在复杂世界中灵活决策,甚至学会“创新”和“探索”。
如果你对强化学习感兴趣,可以试着用“奖励思维”分析生活中的问题:比如如何用“中间奖励”激励自己每天坚持读书?这其实就是强化学习的入门实践哦!