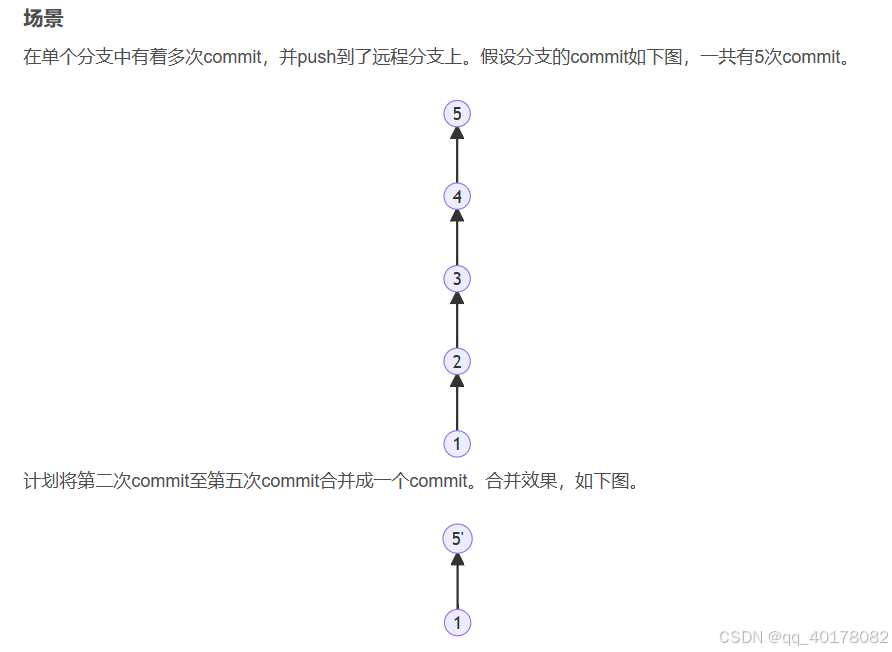
今天给大家讲一下关于Agent长期对话的几种持久化存储方式,之前的文章给大家说过短期记忆和长期记忆,短期记忆基于InMemorySaver做checkpointer(检查点),短期记忆 (线程级持久性) 使代理能够跟踪多轮次对话,保存了图的执行状态,可以做回滚。而长期记忆基于BaseStore做checkpointer,InMemoryStore是 BaseStore 的具体实现,可以存取相应的应用数据,使用长期内存 (跨线程持久性) 跨对话存储特定于用户或特定于应用程序的数据。但是在生产环境中,我们必须要采用持久化的版本来保证我们的Agent重启时数据丢失。
下面我们重点讲一下短期记忆的持久化方式:
一. PostgresSaver检查点
首先引入需要的库
pip install -U "psycopg[binary,pool]" langgraph langgraph-checkpoint-postgres langchain-openai langchain
设置大模型的key,这里根据具体的大模型设置
import os
from langchain.chat_models import init_chat_model
os.environ["OPENAI_API_KEY"] = "sk-xxxxxxx"
os.environ["OPENAI_API_BASE"] = "https://openkey.cloud/v1"
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.postgres import PostgresSaver
初始化我们的大模型
model = init_chat_model(model="anthropic:claude-3-5-haiku-latest")
然背后开始我们的postgressql的初始化,设置好你postgres的地址,端口和密码。
DB_URI = "postgresql://postgres:postgres@localhost:5442/postgres?sslmode=disable"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
# checkpointer.setup()
def call_model(state: MessagesState):
response = model.invoke(state["messages"])
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(checkpointer=checkpointer)
config = {
"configurable": {
"thread_id": "1"
}
}
for chunk in graph.stream(
{"messages": [{"role": "user", "content": "hi! I'm bob"}]},
config,
stream_mode="values"
):
chunk["messages"][-1].pretty_print()
for chunk in graph.stream(
{"messages": [{"role": "user", "content": "what's my name?"}]},
config,
stream_mode="values"
):
chunk["messages"][-1].pretty_print()
这里需要注意的是,如果首次初始化postgres的checkpointer的话,需要调用checkpointer.setup(),因为需要初始化表。我们可以打开你的postgresSql数据库
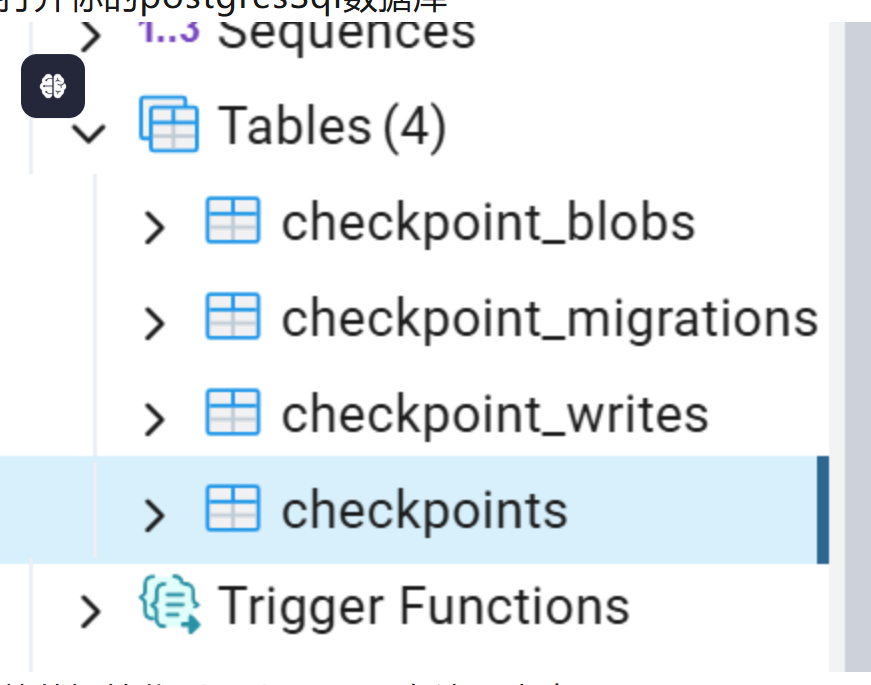
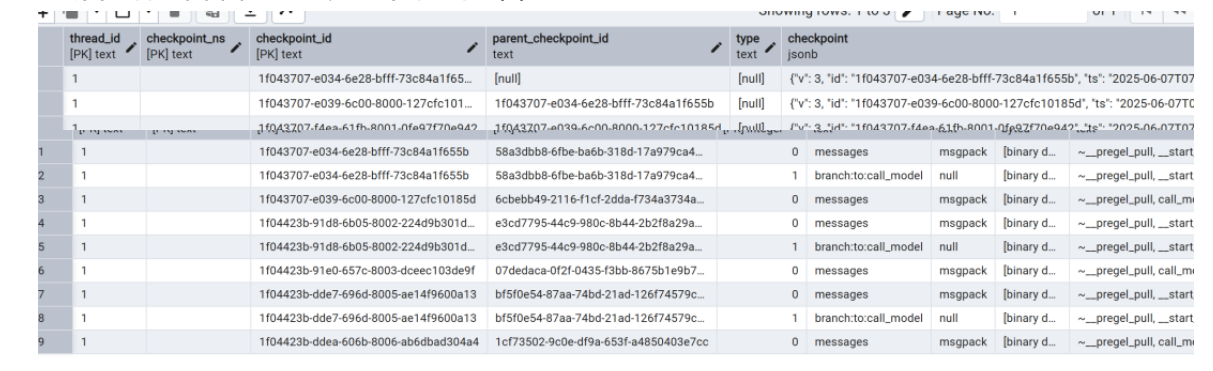
可以看到总共初始化checkpointer有这几张表。
然后我们看看这张表里面的内容
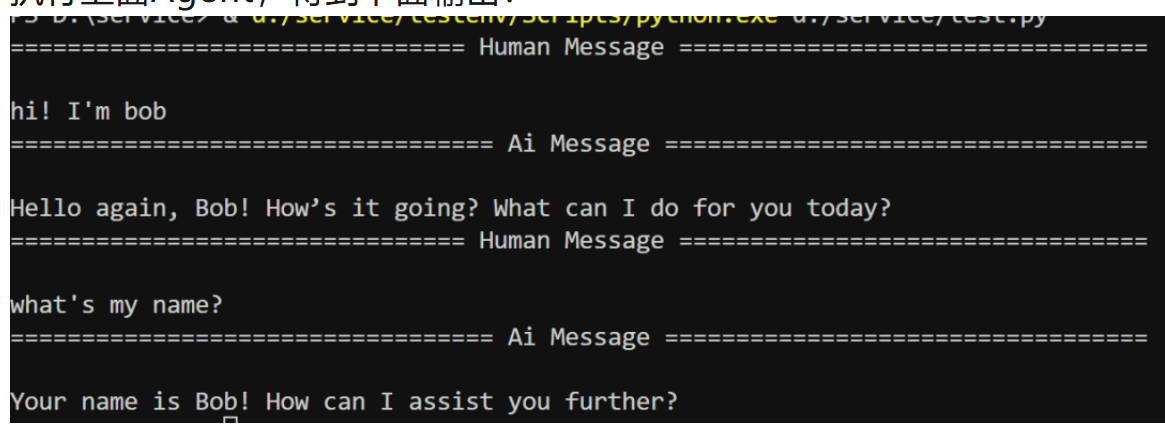
执行上面Agent,得到下面输出:
二. PostgresSaver检查点
使用mongodb需要注意引入下面库
pip install langgraph.checkpoint.mongodb
from langgraph.checkpoint.mongodb import MongoDBSaver
使用mongodb检查点:
DB_URI = "localhost:27017"
with MongoDBSaver.from_conn_string(DB_URI) as checkpointer:
def call_model(state: MessagesState):
response = model.invoke(state["messages"])
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(checkpointer=checkpointer)
config = {
"configurable": {
"thread_id": "1"
}
}
for chunk in graph.stream(
{"messages": [{"role": "user", "content": "hi! I'm bob"}]},
config,
stream_mode="values"
):
chunk["messages"][-1].pretty_print()
for chunk in graph.stream(
{"messages": [{"role": "user", "content": "what's my name?"}]},
config,
stream_mode="values"
):
chunk["messages"][-1].pretty_print()
得到下面结果:
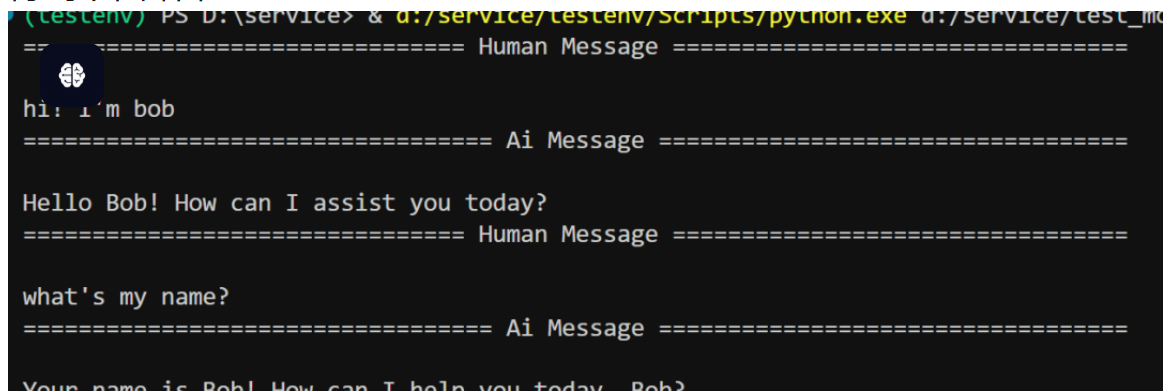
我们打开吗,mongodb数据库会看到这几张表:
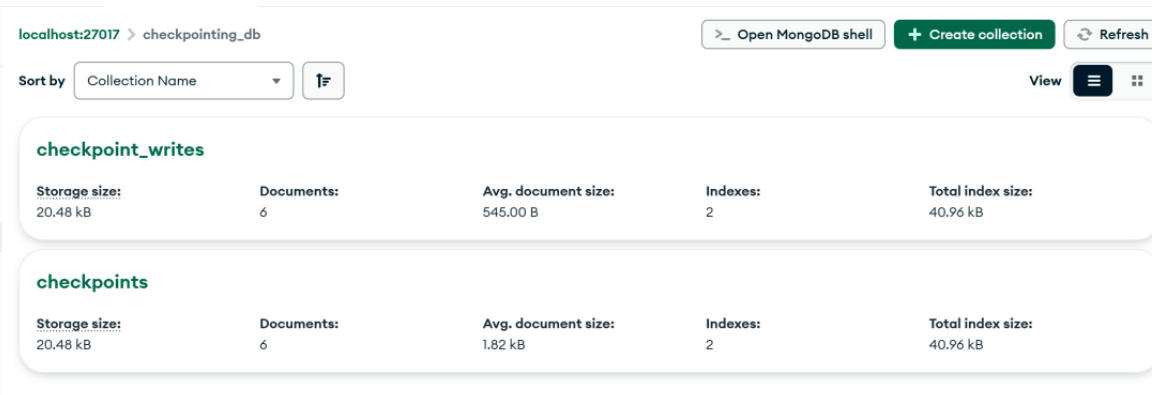
存储的结构阶段如下:
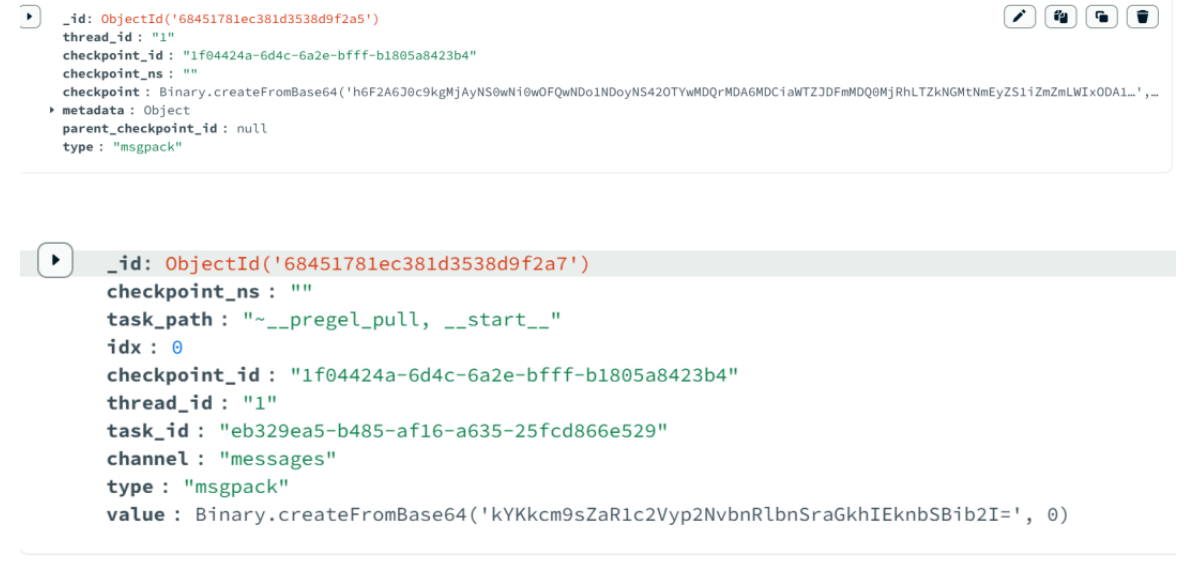
三. Redis检查点
这里需要引入下面库
langgraph.checkpoint.redis
from langgraph.checkpoint.redis import RedisSaver
然后开始使用Redis检查点:
DB_URI = "redis://localhost:6379"
with RedisSaver.from_conn_string(DB_URI) as checkpointer:
# checkpointer.setup()
def call_model(state: MessagesState):
response = model.invoke(state["messages"])
return {"messages": response}
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(checkpointer=checkpointer)
config = {
"configurable": {
"thread_id": "1"
}
}
for chunk in graph.stream(
{"messages": [{"role": "user", "content": "hi! I'm bob"}]},
config,
stream_mode="values"
):
chunk["messages"][-1].pretty_print()
for chunk in graph.stream(
{"messages": [{"role": "user", "content": "what's my name?"}]},
config,
stream_mode="values"
):
chunk["messages"][-1].pretty_print()
得到如下结果
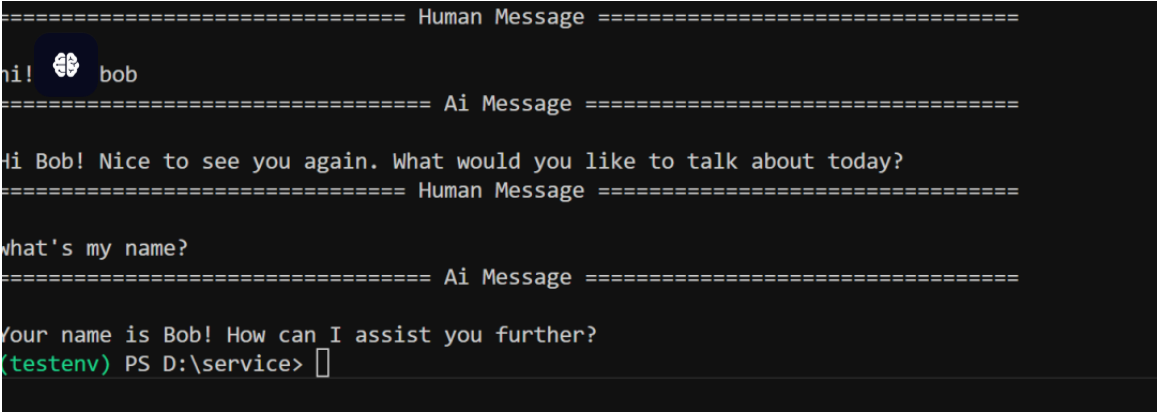
这三种方式就是我们常用的短期记忆持久化方式,感兴趣的同学可以跟着里面的字段来学习它的底层是怎么存储的,在我们写Agent的时候,一个持久化方案在我们多Agent交互的时候往往有很高的效率。
下面一章我们接着说长期记忆的持久化方式。