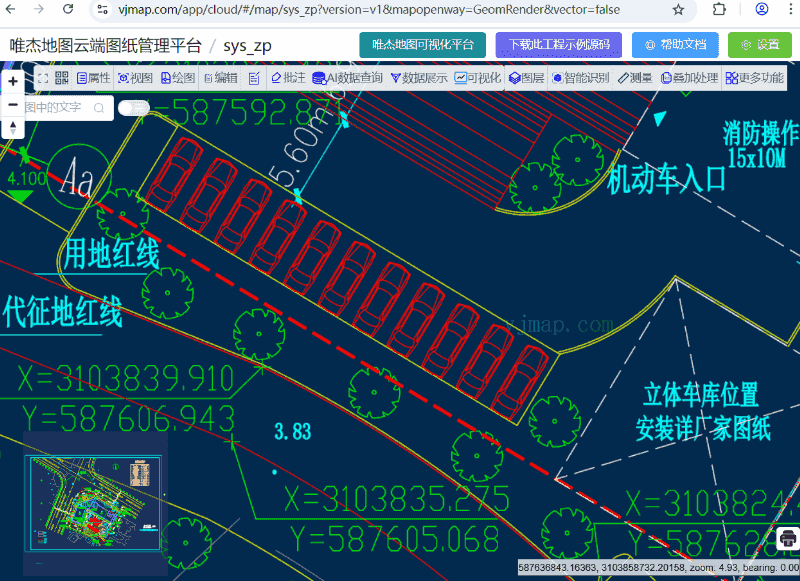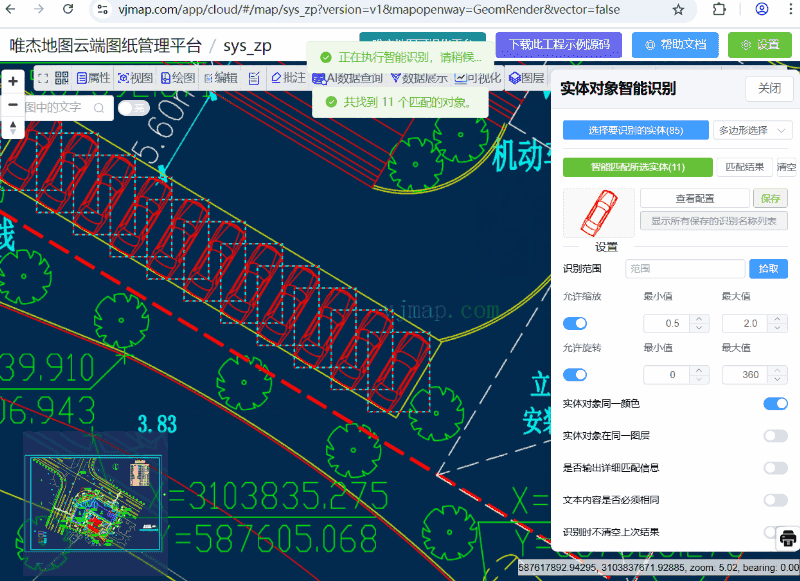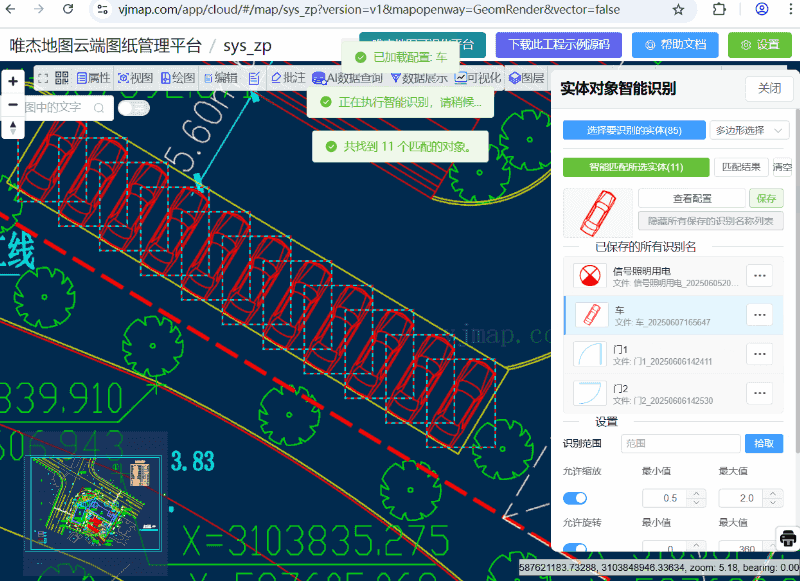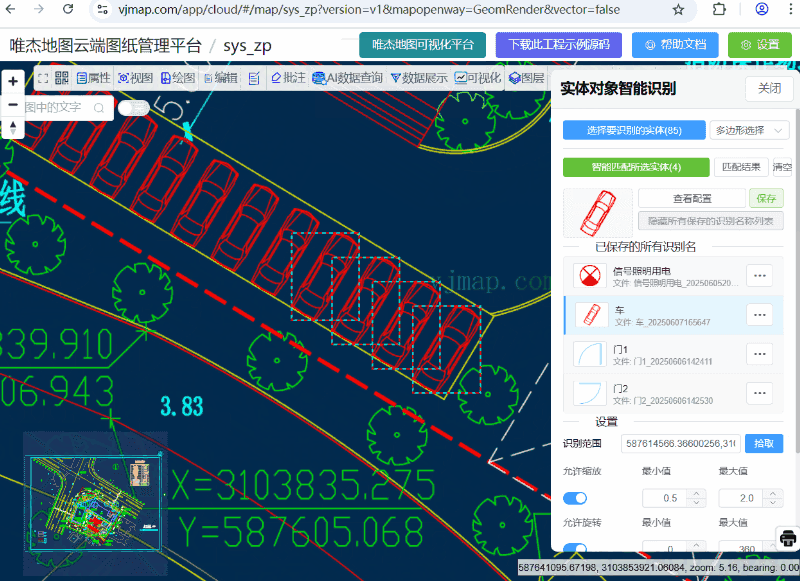
以 https://www.kaggle.com/datasets/vipoooool/new-plant-diseases-dataset 为例
1. 图像分类数据集文件结构 (例如用于 yolov11n-cls.pt 训练)
import os
import csv
import random
from PIL import Image
from sklearn.model_selection import train_test_split
import shutil
# ====================== 配置参数 ======================
# 从 Kaggle Hub 下载植物病害数据集
# https://www.kaggle.com/datasets/vipoooool/new-plant-diseases-dataset
import kagglehub
tf_download_path = kagglehub.dataset_download("vipoooool/new-plant-diseases-dataset")
print("Path to dataset files:", tf_download_path)
# 定义数据集路径
tf_dataset_path = f"{tf_download_path}/New Plant Diseases Dataset(Augmented)/New Plant Diseases Dataset(Augmented)"
INPUT_DATA_DIR = tf_dataset_path # 输入数据集路径(解压后的根目录)
OUTPUT_YOLO_DIR = "./runs/traindata/yolo/yolo_plant_diseases_classify" # 输出YOLO数据集路径
if os.path.exists(OUTPUT_YOLO_DIR):
shutil.rmtree(OUTPUT_YOLO_DIR)
os.makedirs(OUTPUT_YOLO_DIR, exist_ok=True)
TRAIN_SIZE = 0.8 # 训练集比例
IMAGE_EXTENSIONS = [".JPG", ".jpg", ".jpeg", ".png"] # 支持的图像扩展名
# ====================== 类别映射(需根据实际数据集调整) ======================
# 从原数据集的类别名称生成映射(示例:假设病害类别为文件夹名)
def get_class_mapping(data_dir):
class_names = []
for folder in os.listdir(data_dir):
folder_path = os.path.join(data_dir, folder)
if os.path.isdir(folder_path) and not folder.startswith("."):
class_names.append(folder)
class_names.sort() # 按字母序排序,确保类别编号固定
return {cls: idx for idx, cls in enumerate(class_names)}
# ====================== 划分数据集并保存 ======================
def save_dataset(annotations, class_map, output_dir, train_size=0.8):
# 划分训练集和验证集
random.shuffle(annotations)
split_idx = int(len(annotations) * train_size)
train_data = annotations[:split_idx]
val_data = annotations[split_idx:]
# 创建目录结构
os.makedirs(os.path.join(output_dir, "train"), exist_ok=True)
os.makedirs(os.path.join(output_dir, "val"), exist_ok=True)
for cls in class_map.keys():
os.makedirs(os.path.join(output_dir, "train", cls), exist_ok=True)
os.makedirs(os.path.join(output_dir, "val", cls), exist_ok=True)
# 保存训练集
for data in train_data:
img_path = data["image_path"]
cls = data["class_name"]
try:
shutil.copy2(img_path, os.path.join(output_dir, "train", cls))
print(f"图像 {img_path} 复制到训练集 {cls} 类成功")
except Exception as e:
print(f"图像 {img_path} 复制到训练集 {cls} 类失败,错误信息: {e}")
# 保存验证集
for data in val_data:
img_path = data["image_path"]
cls = data["class_name"]
try:
shutil.copy2(img_path, os.path.join(output_dir, "val", cls))
print(f"图像 {img_path} 复制到验证集 {cls} 类成功")
except Exception as e:
print(f"图像 {img_path} 复制到验证集 {cls} 类失败,错误信息: {e}")
# 生成类别名文件(classes.names)
with open(os.path.join(output_dir, "classes.names"), "w") as f:
for cls in class_map.keys():
f.write(f"{cls}\n")
# 生成数据集配置文件(dataset.yaml)
yaml_path = os.path.join(output_dir, "dataset.yaml")
with open(yaml_path, "w") as f:
f.write(f"path: {output_dir}\n") # 数据集根路径
f.write(f"train: train\n") # 训练集路径(相对于path)
f.write(f"val: val\n") # 验证集路径
# f.write(f"test: images/test\n") # 测试集路径(如果有)
f.write(f"nc: {len(class_map)}\n") # 类别数
# 修改 names 字段输出格式
class_names = list(class_map.keys())
f.write(f"names: {class_names}\n")
return train_data, val_data
# ====================== 主函数 ======================
if __name__ == "__main__":
# 1. 检查输入路径是否存在
if not os.path.exists(INPUT_DATA_DIR):
raise FileNotFoundError(f"请先下载数据集并解压到路径:{INPUT_DATA_DIR}")
# 2. 获取类别映射(假设图像按类别存放在子文件夹中)
class_map = get_class_mapping(os.path.join(INPUT_DATA_DIR, "train")) # 假设训练集图像在train子文件夹中,每个子文件夹为一个类别
# 3. 解析标注(仅按文件夹分类)
annotations = []
for cls, idx in class_map.items():
cls_dir = os.path.join(INPUT_DATA_DIR, "train", cls) # 假设类别文件夹路径为train/类别名
for img_file in os.listdir(cls_dir):
if any(img_file.lower().endswith(ext) for ext in IMAGE_EXTENSIONS):
img_path = os.path.join(cls_dir, img_file)
annotations.append({
"image_path": img_path,
"class_name": cls
})
# 4. 保存为YOLO格式
train_data, val_data = save_dataset(annotations, class_map, OUTPUT_YOLO_DIR, train_size=TRAIN_SIZE)
print(f"✅ 转换完成!YOLO数据集已保存至:{OUTPUT_YOLO_DIR}")
print(f"类别数:{len(class_map)},训练集样本数:{len(train_data)},验证集样本数:{len(val_data)}")train的时候,使用的文件夹
2. 目标检测数据集文件结构 (例如用于 yolo11n.pt 训练)
import os
import csv
import random
from PIL import Image
from sklearn.model_selection import train_test_split
import shutil
# ====================== 配置参数 ======================
# 从 Kaggle Hub 下载植物病害数据集
# https://www.kaggle.com/datasets/vipoooool/new-plant-diseases-dataset
import kagglehub
tf_download_path = kagglehub.dataset_download("vipoooool/new-plant-diseases-dataset")
print("Path to dataset files:", tf_download_path)
# 定义数据集路径
tf_dataset_path = f"{tf_download_path}/New Plant Diseases Dataset(Augmented)/New Plant Diseases Dataset(Augmented)"
INPUT_DATA_DIR = tf_dataset_path # 输入数据集路径(解压后的根目录)
OUTPUT_YOLO_DIR = "./traindata/yolo/yolo_plant_diseases" # 输出YOLO数据集路径
if os.path.exists(OUTPUT_YOLO_DIR):
shutil.rmtree(OUTPUT_YOLO_DIR)
os.makedirs(OUTPUT_YOLO_DIR, exist_ok=True)
TRAIN_SIZE = 0.8 # 训练集比例
IMAGE_EXTENSIONS = [".JPG", ".jpg", ".jpeg", ".png"] # 支持的图像扩展名
# ====================== 类别映射(需根据实际数据集调整) ======================
# 从原数据集的类别名称生成映射(示例:假设病害类别为文件夹名)
def get_class_mapping(data_dir):
class_names = []
for folder in os.listdir(data_dir):
folder_path = os.path.join(data_dir, folder)
if os.path.isdir(folder_path) and not folder.startswith("."):
class_names.append(folder)
class_names.sort() # 按字母序排序,确保类别编号固定
return {cls: idx for idx, cls in enumerate(class_names)}
# ====================== 解析CSV标注(假设标注在CSV中) ======================
def parse_csv_annotations(csv_path, class_map, image_dir):
annotations = []
with open(csv_path, "r", encoding="utf-8") as f:
reader = csv.DictReader(f)
for row in reader:
image_name = row["image_path"]
class_name = row["disease_class"] # 需与CSV中的类别列名一致
x_min = float(row["x_min"])
y_min = float(row["y_min"])
x_max = float(row["x_max"])
y_max = float(row["y_max"])
# 检查图像是否存在
image_path = os.path.join(image_dir, image_name)
if not os.path.exists(image_path):
continue
# 获取图像尺寸
with Image.open(image_path) as img:
img_width, img_height = img.size
# 转换为YOLO坐标
center_x = (x_min + x_max) / 2 / img_width
center_y = (y_min + y_max) / 2 / img_height
width = (x_max - x_min) / img_width
height = (y_max - y_min) / img_height
annotations.append({
"image_path": image_path,
"class_id": class_map[class_name],
"bbox": (center_x, center_y, width, height)
})
return annotations
# ====================== 划分数据集并保存 ======================
def save_dataset(annotations, class_map, output_dir, train_size=0.8):
# 划分训练集和验证集
random.shuffle(annotations)
split_idx = int(len(annotations) * train_size)
train_data = annotations[:split_idx]
val_data = annotations[split_idx:]
# 创建目录结构
os.makedirs(os.path.join(output_dir, "images/train"), exist_ok=True)
os.makedirs(os.path.join(output_dir, "images/val"), exist_ok=True)
os.makedirs(os.path.join(output_dir, "labels/train"), exist_ok=True)
os.makedirs(os.path.join(output_dir, "labels/val"), exist_ok=True)
# 保存训练集
for data in train_data:
img_path = data["image_path"]
lbl_path = os.path.join(
output_dir, "labels/train",
os.path.splitext(os.path.basename(img_path))[0] + ".txt"
)
# 复制图像
try:
shutil.copy2(img_path, os.path.join(output_dir, 'images/train'))
print(f"图像 {img_path} 复制到训练集成功")
except Exception as e:
print(f"图像 {img_path} 复制到训练集失败,错误信息: {e}")
# 保存标注
with open(lbl_path, "w") as f:
f.write(f"{data['class_id']} {' '.join(map(str, data['bbox']))}\n")
# 保存验证集
for data in val_data:
img_path = data["image_path"]
lbl_path = os.path.join(
output_dir, "labels/val",
os.path.splitext(os.path.basename(img_path))[0] + ".txt"
)
# 复制图像
try:
shutil.copy2(img_path, os.path.join(output_dir, 'images/val'))
print(f"图像 {img_path} 复制到验证集成功")
except Exception as e:
print(f"图像 {img_path} 复制到验证集失败,错误信息: {e}")
# 保存标注
with open(lbl_path, "w") as f:
f.write(f"{data['class_id']} {' '.join(map(str, data['bbox']))}\n")
# 生成类别名文件(classes.names)
with open(os.path.join(output_dir, "classes.names"), "w") as f:
for cls in class_map.keys():
f.write(f"{cls}\n")
# 生成数据集配置文件(dataset.yaml)
yaml_path = os.path.join(output_dir, "dataset.yaml")
with open(yaml_path, "w") as f:
f.write(f"path: {output_dir}\n") # 数据集根路径
f.write(f"train: images/train\n") # 训练集路径(相对于path)
f.write(f"val: images/val\n") # 验证集路径
# f.write(f"test: images/test\n") # 测试集路径(如果有)
f.write(f"nc: {len(class_map)}\n") # 类别数
f.write("names:\n")
for idx, cls in enumerate(class_map.keys()):
f.write(f" {idx}: {cls}\n")
return train_data, val_data
# ====================== 主函数 ======================
if __name__ == "__main__":
# 1. 检查输入路径是否存在
if not os.path.exists(INPUT_DATA_DIR):
raise FileNotFoundError(f"请先下载数据集并解压到路径:{INPUT_DATA_DIR}")
# 2. 获取类别映射(假设图像按类别存放在子文件夹中,无CSV标注时使用此方法)
# 若有CSV标注,需手动指定CSV路径和列名,注释掉下方代码并取消注释parse_csv_annotations部分
class_map = get_class_mapping(os.path.join(INPUT_DATA_DIR, "train")) # 假设训练集图像在train子文件夹中,每个子文件夹为一个类别
# 3. 解析标注(根据实际情况选择CSV或文件夹分类)
# 情况A:无标注,仅按文件夹分类(弱监督,边界框为图像全尺寸)
annotations = []
for cls, idx in class_map.items():
cls_dir = os.path.join(INPUT_DATA_DIR, "train", cls) # 假设类别文件夹路径为train/类别名
for img_file in os.listdir(cls_dir):
if any(img_file.lower().endswith(ext) for ext in IMAGE_EXTENSIONS):
img_path = os.path.join(cls_dir, img_file)
with Image.open(img_path) as img:
img_width, img_height = img.size
# 边界框为全图(弱监督场景,仅用于分类任务,非检测)
annotations.append({
"image_path": img_path,
"class_id": idx,
"bbox": (0.5, 0.5, 1.0, 1.0) # 全图边界框
})
# # 情况B:有CSV标注(需取消注释以下代码并调整参数)
# CSV_PATH = os.path.join(INPUT_DATA_DIR, "labels.csv") # CSV标注文件路径
# IMAGE_DIR = os.path.join(INPUT_DATA_DIR, "images") # 图像根目录
# class_map = {"Apple Scab": 0, "Black Rot": 1, ...} # 手动定义类别映射
# annotations = parse_csv_annotations(CSV_PATH, class_map, IMAGE_DIR)
# 4. 保存为YOLO格式
train_data, val_data = save_dataset(annotations, class_map, OUTPUT_YOLO_DIR, train_size=TRAIN_SIZE)
print(f"✅ 转换完成!YOLO数据集已保存至:{OUTPUT_YOLO_DIR}")
print(f"类别数:{len(class_map)},训练集样本数:{len(train_data)},验证集样本数:{len(val_data)}")train的时候,使用的yaml文件路径