文章目录
- 基本思路
- 目录结构
- 配置文件
- AST解析
- 替换代码中文
- 生成Excel
- 启动脚本
基本思路
- 通过对应语言的AST解析出中文
- 相关信息(文件、所在行列等)存到临时文件
- 通过相关信息,逐个文件位置替换掉中文
- 基于临时文件,通过py脚本生成Excel表格
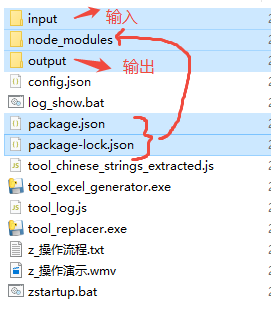
目录结构
配置文件
{
"_NOTE": "// _NOTE后缀都是注释, 无需修改",
"start_id_NOTE": "// 生成配置表的起始id",
"start_id": 10000,
"funCls_NOTE": "// 静态替换函数的类名",
"funCls": "LangUtil",
"replaceFunc_NOTE": "// 替换函数, 形如: public static getLang(code: number, ...args): string; ",
"replaceFunc": "LangUtil.getLang",
"importAbsolute_NOTE": "// import的绝对路径",
"importAbsolute": "import { LangUtil } from 'src/game/mod/common/utils/LangUtil';",
"ignore_file_NOTE": "// 忽略的.ts文件名",
"ignore_file": [
"Const.ts",
"CharConst.ts",
"CharConstLog.ts",
"CharConstFeat.ts",
"CharConstMars.ts",
"CharConstCommon.ts",
"CharConstMeridian.ts",
"LangUtil.ts"
],
"ignore_dir_NOTE": "// 忽略的文件目录名",
"ignore_dir": [
],
"isReplaceStaticProperty_NOTE": "// 是否替换静态的属性的中文字符(建议第一波先不替换;第二波再统一替换,会报错,看能不能优化代码不要用静态的)",
"isReplaceStaticProperty": false,
"replacer_exe_NOTE": "// 是否执行代码中文替换",
"replacer_exe": true,
"gen_xls_exe_NOTE": "// 是否生成xls",
"gen_xls_exe": true,
"xls_name_NOTE": "// 生成的xls文件名",
"xls_name": "lang_tool.xls",
"OPTIONAL_PARAMS_NOTE": "// ==========================================下方一般都没必要修改=============================",
"columns_NOTE": "// 生成表的列占位符",
"columns": ["NOTE", "ID", "文本", "空列", "代码文件来源", "被替换的源代码"],
"ecmaVersion_NOTE": "// 解析所需参数",
"ecmaVersion": 2020,
"sourceType_NOTE": "// 解析所需参数",
"sourceType": "module",
"genTsEnum_NOTE": "// 是否生成ts枚举类",
"genTsEnum": true,
"isPrettyJsn_NOTE": "// 是否美化的json",
"isPrettyJsn": true,
"tempJ_NOTE": " // json文件名",
"tempJ": "tempJ.json"
}
AST解析
const fs = require('fs');
const path = require('path');
const { parse } = require('@typescript-eslint/typescript-estree');
const readline = require('readline');
const POSTFIX_TS = ".ts"
let ENUM_START_ID = 1;
let tblStartId = 1;
const FILENAME_POSTFIX = "Lang";
const __Mark = "________";
const scriptDir = __dirname;
const CharConstClsName = "CharConst";
const IO_ENCODING = "utf8";
const COMBINE_NAME = `${CharConstClsName}${FILENAME_POSTFIX}`;
const CharConstTSFile = `${COMBINE_NAME}${POSTFIX_TS}`;
const input_dir = `${scriptDir}\\input\\`;
const output_dir = `${scriptDir}\\output\\`;
const output = `${COMBINE_NAME}.txt`;
const output_simple = `${COMBINE_NAME}_Simple.txt`;
const SHOW_FILE_LINE = true;
const IS_GEN_SIMPLE_STR = true;
let strings = new Set();
let strings_simple = new Set();
const tempJson = {};
function insertJson(tableId, srcTxt, replaceFullPath, line, type, tgtTxt, args = null) {
tempJson[tableId] = {
srcTxt: srcTxt,
path: replaceFullPath,
line: line,
type: type,
tgtTxt: tgtTxt,
}
if (args) {
tempJson[tableId]['args'] = args;
}
}
function traverse(filePath) {
const content = fs.readFileSync(filePath, IO_ENCODING);
try {
const ast = parse(content, {
ecmaVersion: getValueByKey("ecmaVersion"),
sourceType: getValueByKey("sourceType"),
loc: true,
range: true
});
traverseAST(ast, filePath, content);
} catch (e) {
console.warn(`Parse error in ${filePath}`);
}
}
function isStaticProperty(node) {
if(getValueByKey("isReplaceStaticProperty")){
return false;
}
if (node.type === 'PropertyDefinition' && node.static) {
return true;
}
return false;
}
function traverseAST(node, file, content) {
if(isStaticProperty(node)){
return;
}
if (node.type === 'Literal' &&
typeof node.value === 'string' &&
/[\u4e00-\u9fa5]/.test(node.value)) {
handleStringLiteral(node, file, content, 0);
}
if (node.type === 'TemplateLiteral') {
let processedStr = '';
let argIndex = 0;
for (let i = 0; i < node.quasis.length; i++) {
const quasi = node.quasis[i];
processedStr += quasi.value.raw;
if (i < node.quasis.length - 1) {
processedStr += `{${argIndex++}}`;
}
}
if (/[\u4e00-\u9fa5]/.test(processedStr)) {
handleStringLiteral(node, file, content, 1, processedStr);
}
}
for (let key in node) {
if (node.hasOwnProperty(key) &&
typeof node[key] === 'object' &&
node[key] !== null) {
traverseAST(node[key], file, content);
}
}
}
function handleStringLiteral(node, file, content, type, processedStr = null) {
if (!node.loc) {
console.error(`未知行,不予记录,跳过; file=>${file}`)
return;
}
const newTblId = tblStartId++;
const line = node.loc.start.line;
const isLiterStringType = isLiteral(type);
let srcTxt = "";
let args = [];
if(isLiterStringType){
srcTxt = node.raw;
args = null;
}else{
srcTxt = content.slice(node.range[0], node.range[1]);
node.expressions.forEach(expr => {
const [start, end] = expr.range;
args.push(content.slice(start, end));
});
}
const uid = `${__Mark}${newTblId}`;
const tblSaveStr = isLiterStringType ? node.value : processedStr;
insertJson(newTblId, srcTxt, file, line, type, tblSaveStr, args)
if (SHOW_FILE_LINE) {
strings.add(`${file}:${line}${uid}\n${/* node.value */tblSaveStr}`);
}
if (IS_GEN_SIMPLE_STR) {
strings_simple.add(`${/* node.value */tblSaveStr}${uid}`);
}
}
function isLiteral(type){
return type == 0;
}
function walkDir(currentPath) {
if (!fs.existsSync(currentPath)) {
console.error(`路径不存在: ${currentPath}`);
return;
}
const files = fs.readdirSync(currentPath);
for (const file of files) {
const fullPath = path.join(currentPath, file);
const stat = fs.statSync(fullPath);
if (stat.isDirectory()) {
if(ignore_dir.indexOf(file) > -1){
console.log(`==========忽略文件夹:${file}`)
}else{
walkDir(fullPath);
}
} else if (file.endsWith(POSTFIX_TS)) {
if(ignore_file.indexOf(file) > -1){
console.log(`==========忽略文件:${file}`)
}else{
traverse(fullPath);
}
} else {
}
}
}
function generateEnumFile() {
const entries = Array.from(strings).map(entry => {
const [fileLine, value] = entry.split('\n');
const lastColonIndex = fileLine.lastIndexOf(':');
return {
file: fileLine.slice(0, lastColonIndex),
line: disposeUIdStrByReg(fileLine.slice(lastColonIndex + 1)),
value: value
};
});
const enumLines = entries.map(({ file, line, value }, index) => {
const id = index + ENUM_START_ID;
const key = `ID_${id}`;
const fileName = path.basename(file);
return `\t// ${fileName}:${line}\n\t${key} = ${id}, //${JSON.stringify(value)}`;
});
const enumContent = `/** Attention! The annotations will not change along with the actual table. */\nexport enum ${COMBINE_NAME} {\n${enumLines.join('\n')}\n}`;
fs.writeFileSync(output_dir + CharConstTSFile, enumContent, IO_ENCODING);
}
const enableDelOutput = true;
const delOutputTipsShow = false;
async function clearOutputDir() {
const dirPath = output_dir;
if (!enableDelOutput) return;
console.log(`enableDelOutput:${output_dir}`)
if (!fs.existsSync(dirPath)) {
console.log(`目录不存在: ${dirPath}`);
return;
}
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
try {
let rst = "y";
if (delOutputTipsShow) {
rst = await new Promise(resolve => {
rl.question(`即将清空目录 ${dirPath},确认继续吗?(y/n) `, resolve);
});
}
if (rst.trim().toLowerCase() === 'y') {
fs.rmSync(dirPath, { recursive: true, force: true });
fs.mkdirSync(dirPath);
console.log('√ 目录已清空');
} else {
console.log('× 操作已取消');
}
} finally {
rl.close();
}
}
function disposeUIdStrByReg(s) {
return s.replace(/________\d+/, '');
}
async function main() {
try {
await clearOutputDir();
load_config();
init_cfg_value();
walkDir(input_dir);
fs.writeFileSync(
path.join(output_dir, output),
Array.from(strings).map(s => disposeUIdStrByReg(s)).join('\n'),
IO_ENCODING
);
fs.writeFileSync(path.join(output_dir, output_simple), Array.from(strings_simple).map(str => str.split(__Mark)[0]).join('\n'), IO_ENCODING);
const genTsEnum = getValueByKey("genTsEnum");
if(genTsEnum){
generateEnumFile();
}
console.log(`
√ 提取完成:
- 找到 strings.size=>${strings.size}|||strings_simple.size=>${strings_simple.size} 条中文字符串(已写入 ${output} 和 ${output_simple})
${genTsEnum ? "- 生成枚举文件 ${CharConstTSFile}" : ""}
`);
let jsonData;
if(getValueByKey("isPrettyJsn")){
jsonData = JSON.stringify(tempJson, null, 2);
}else{
jsonData = JSON.stringify(tempJson);
}
fs.writeFileSync(path.join(output_dir, getValueByKey("tempJ")), jsonData);
} catch (err) {
console.error('× 运行出错:', err);
process.exit(1);
}
}
main();
let json_obj;
let ignore_file;
let ignore_dir;
function init_cfg_value(){
tblStartId = ENUM_START_ID = getValueByKey("start_id");
ignore_file = getValueByKey("ignore_file") || [];
ignore_dir = getValueByKey("ignore_dir") || [];
}
function load_config(){
try {
const data = fs.readFileSync('./config.json', 'utf8');
json_obj = JSON.parse(data);
} catch (err) {
console.error('config.json解析失败:', err);
process.exit(1);
}
}
function getValueByKey(key) {
if (json_obj && key in json_obj) {
return json_obj[key];
}
return null;
}
替换代码中文
// tool_replacer.py
import json
import os
import re
from pathlib import Path
import logging
import os
def setup_logger():
log_dir = "output"
os.makedirs(log_dir, exist_ok=True)
log_file = os.path.join(log_dir, "log.txt")
logger = logging.getLogger("my_logger")
logger.setLevel(logging.INFO)
file_handler = logging.FileHandler(log_file, encoding="utf-8", mode="a")
file_handler.setFormatter(logging.Formatter('[%(asctime)s] %(message)s'))
logger.addHandler(file_handler)
console_handler = logging.StreamHandler()
console_handler.setFormatter(logging.Formatter('%(message)s'))
logger.addHandler(console_handler)
return logger
class TsTextReplacer:
def __init__(self, config_path="config.json", data_path="output/tempJ.json"):
self.config = self.load_config(config_path)
self.json_data = self.load_data(data_path)
str_cfg=self.config['funCls']
pattern = r'^import\s+.*?\b{}\b'.format(re.escape(str_cfg))
self.import_pattern = re.compile(pattern, re.MULTILINE)
str_import_cfg=self.config['importAbsolute']
self.import_statement = f"{str_import_cfg}\n"
def load_config(self, path):
with open(path, 'r', encoding='utf-8') as f:
return json.load(f)
def load_data(self, path):
with open(path, 'r', encoding='utf-8') as f:
return json.load(f)
def generate_replacement(self, key, item):
base = f"{self.config['replaceFunc']}({key}"
if item.get('type', 0)!= 0 and item.get('args'):
args = ', '.join(item['args'])
return f"{base}, {args})"
return f"{base})"
def add_import_statement(self, content):
if not self.import_pattern.search(content):
return self.import_statement + content
return content
def process_file(self, file_path, line, src_txt, replacement):
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.readlines()
modified = False
for i in range(line - 1, len(content)):
if src_txt in content[i]:
content[i] = content[i].replace(src_txt, replacement, 1)
modified = True
break
if modified:
full_content = ''.join(content)
full_content = self.add_import_statement(full_content)
with open(file_path, 'w', encoding='utf-8') as f:
f.write(full_content)
return True
return False
except Exception as e:
logger.info(f"处理文件 {file_path} 失败: {str(e)}")
return False
def run(self):
if self.config['replacer_exe']:
success_count = 0
for key, item in self.json_data.items():
if not all(k in item for k in ['srcTxt', 'path', 'line']):
continue
replacement = self.generate_replacement(key, item)
file_path = Path(item['path']).resolve()
if not file_path.exists():
logger.info(f"文件不存在: {file_path}")
continue
if self.process_file(file_path, item['line'], item['srcTxt'], replacement):
logger.info(f"已处理: {file_path} [行{item['line']}]")
success_count += 1
else:
logger.info(f"未找到匹配: {file_path} [行{item['line']}]")
endLog = f"************处理完成!成功替换 {success_count}/{len(self.json_data)} 处"
logger.info(f"{endLog}")
escape_info_str(endLog)
else:
endLog = "************跳过了替换代码中文步骤!"
logger.info(f"{endLog}")
escape_info_str(endLog)
def escape_info_str(value):
escaped_value = value.replace("%", "%%")
print(f'echo "{escaped_value}"')
if __name__ == "__main__":
logger = setup_logger()
replacer = TsTextReplacer()
replacer.run()
生成Excel
// tool_excel_generator.py
import json
import os
from pathlib import Path
from openpyxl import Workbook
from openpyxl.utils import get_column_letter
class ExcelGenerator:
def __init__(self):
self.config = self.load_config()
self.json_data = self.load_data()
self.output_dir = Path("output")
self.output_dir.mkdir(exist_ok=True)
def load_config(self):
with open("config.json", "r", encoding="utf-8") as f:
config = json.load(f)
return {
"xls_name": config.get("xls_name", "lang") + ".xls",
"columns": ["NOTE", "ID", "文本", "空列", "代码文件来源", "被替换的源代码"]
}
def load_data(self):
with open("output/tempJ.json", "r", encoding="utf-8") as f:
return json.load(f)
def get_filename_from_path(self, path):
return Path(path).stem
def clean_output_xls_rtn_name(self):
output_path = self.output_dir / self.config["xls_name"]
if output_path.exists():
os.remove(output_path)
return output_path
def generate_excel(self):
if self.config["gen_xls_exe"]:
"""生成Excel文件"""
output_path = self.clean_output_xls_rtn_name()
wb = Workbook()
ws = wb.active
ws.title = "Lang Data"
ws.column_dimensions[get_column_letter(2)].width = 15
ws.column_dimensions[get_column_letter(3)].width = 40
ws.column_dimensions[get_column_letter(5)].width = 35
ws.column_dimensions[get_column_letter(6)].width = 60
ws.append(self.config["columns"])
row_counter = 0
for idx, (key, item) in enumerate(sorted(self.json_data.items(), key=lambda x: int(x[0])), 1):
filename = self.get_filename_from_path(item["path"])
path_line = f"{filename}:{item['line']}"
row = [
f"VALUE",
key,
item.get("tgtTxt", ""),
"",
path_line,
item.get("srcTxt", "")
]
ws.append(row)
row_counter += 1
if row_counter % 20 == 0:
ws.append([""]*len(self.config["columns"]))
wb.save(output_path)
print(f"生成成功!文件位置:{output_path}")
else:
print(f"跳过了生成xls文件步骤!")
if __name__ == "__main__":
generator = ExcelGenerator()
generator.generate_excel()
启动脚本
REM zstartup.bat
@echo off
echo start tool_chinese_strings_extracted...
node tool_chinese_strings_extracted.js
if errorlevel 1 (
echo tool_chinese_strings_extracted fail.
pause
exit /b
)
echo start tool_replacer...
REM start tool_replacer.exe
call tool_replacer.exe > temp___vars.bat
call temp___vars.bat
del temp___vars.bat
if errorlevel 1 (
echo tool_replacer fail.
start log_show.bat
pause
exit /b
)
echo start tool_excel_generator...
start tool_excel_generator.exe
if errorlevel 1 (
echo tool_excel_generator fail.
start log_show.bat
pause
exit /b
)
call log_show.bat
echo success...
pause