Task:
1.不同CNN层的特征图:不同通道的特征图
2.什么是注意力:注意力家族,类似于动物园,都是不同的模块,好不好试了才知道。
3.通道注意力:模型的定义和插入的位置
4.通道注意力后的特征图和热力图

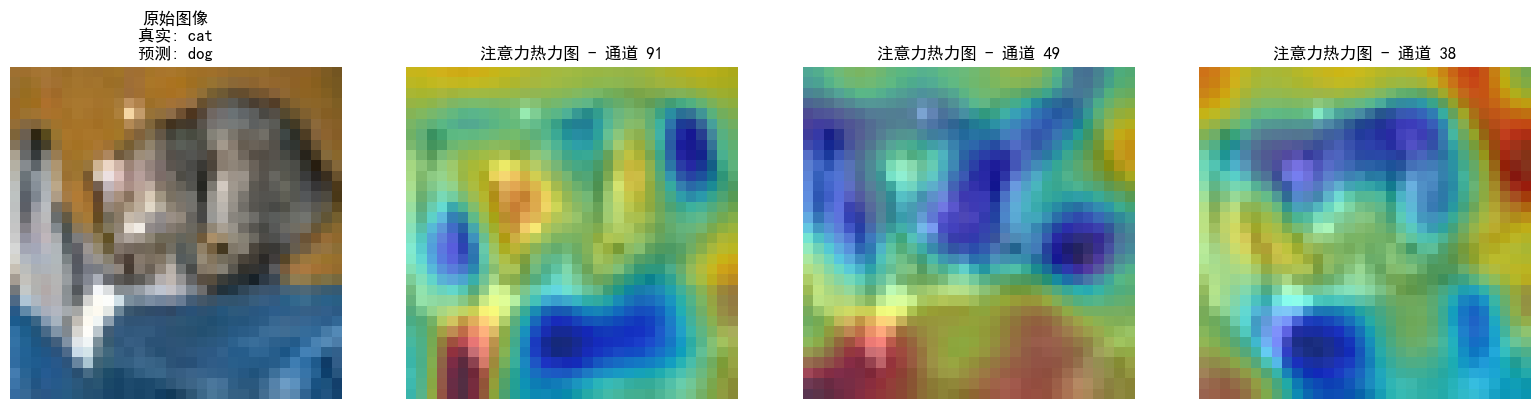
1. 不同CNN层的特征图:不同通道的特征图
什么是特征图 (Feature Map)?
在卷积神经网络 (CNN) 中,特征图是卷积层(或池化层、激活层)的输出。它是一个三维张量 (Tensor),通常表示为 [高度 H, 宽度 W, 通道数 C]。
- 高度 (H) 和 宽度 (W):对应于输入图像的局部区域,表示该区域检测到的特征的空间位置。
- 通道数 ©:表示该层提取到的特征的数量。每个通道都是一个二维的“激活图 (Activation Map)”,对应于一个特定的卷积核(或滤波器)检测到的某种特征模式。
不同CNN层的特征图:
- 浅层 (Early Layers):
- 特点:特征图的尺寸(H, W)通常较大,通道数可能相对较少。
- 内容:这些层提取的是低级(Low-level)特征,例如边缘(水平、垂直、对角)、纹理、颜色斑块等。
- 例子:一个浅层可能有一个通道专门检测水平边缘,另一个通道检测垂直边缘,等等。这些特征图上的高激活值表示在对应位置检测到了这种特定的低级特征。
- 深层 (Deep Layers):
- 特点:经过多层卷积和池化后,特征图的尺寸(H, W)通常会变小,但通道数会大幅增加。
- 内容:这些层提取的是高级(High-level)语义特征,它们是浅层特征的组合和抽象。例如,深层可能识别出眼睛、鼻子、车轮、猫的身体等“部件”,甚至更高层能识别出“一张人脸”、“一辆汽车”、“一只猫”等完整的概念。
- 例子:一个深层通道可能对“狗的耳朵”特征有高激活,另一个对“猫的胡须”有高激活。这些复杂的特征是在更抽象的层面上描述图像内容。
不同通道的特征图:
在一个卷积层的输出特征图 [H, W, C] 中,C 个通道中的每一个通道(即 [H, W] 的二维切片)都代表了由一个特定的卷积核检测到的一种特定的特征模式。
- 想象一下有C个不同的“探测器”,每个探测器都在图像的每个位置寻找一种特定的东西。
- 例如,在识别猫的图像中:
- 通道1可能对“尖耳朵”特征有高激活。
- 通道2可能对“细长胡须”特征有高激活。
- 通道3可能对“特定毛发纹理”特征有高激活。
- …等等。
- 因此,不同的通道捕捉的是图像中不同类型、不同语义信息的特征。这些通道共同构成了该层对输入图像的完整理解。
2. 什么是注意力 (Attention)
核心思想:注意力机制模仿了人类视觉和认知系统的一个关键能力——在处理信息时,能够有选择地聚焦于最相关、最重要的部分,同时抑制不相关或次要的部分。
目的:在神经网络中引入注意力,是为了让模型能够:
- 更有效地利用信息:让模型知道“应该看哪里”或“应该关注哪些特征”。
- 提高性能:通过聚焦重要信息,减少噪音干扰,从而提升模型的准确性和鲁棒性。
- 增强可解释性:有时,注意力权重可以指示模型在做出决策时,哪些输入区域或特征是关键的。
“注意力家族,类似于动物园,都是不同的模块,好不好试了才知道。”
这个比喻非常恰当!
- 动物园:意味着注意力机制并非单一的一种算法,而是一个庞大而多样化的家族。
- 不同的模块:包括但不限于:
- 通道注意力 (Channel Attention):关注不同特征通道的重要性。
- 空间注意力 (Spatial Attention):关注特征图不同空间位置的重要性。
- 混合注意力 (Hybrid Attention):结合通道和空间注意力。
- 自注意力 (Self-Attention):在序列数据(如Transformer)中尤为重要,通过计算序列中不同元素之间的关系来分配注意力。
- 跨模态注意力 (Cross-Modal Attention):处理不同类型数据(如图像和文本)之间的关系。
- 好不好试了才知道:由于不同的任务、不同的数据集和不同的模型架构对注意力的需求不同,没有一种注意力机制是“万能”的。一种在某个任务上表现出色的注意力模块,在另一个任务上可能效果平平。因此,研究人员和工程师通常需要根据具体场景,通过实验来验证哪种注意力机制最有效。
3. 通道注意力 (Channel Attention):模型的定义和插入的位置
定义:
通道注意力机制旨在动态地调整不同特征通道的重要性。它通过学习一个权重向量,为每个特征通道分配一个0到1之间的标量权重。这个权重表示了该通道的特征对于当前任务(例如图像分类、目标检测等)的贡献程度。权重越高,表示该通道越重要,其激活值会被放大;权重越低,表示该通道越不重要,其激活值会被抑制。
典型实现:
最著名的通道注意力模块是 Squeeze-and-Excitation (SE) Block,由Hu等人于2017年提出。
SE Block的工作流程:
-
Squeeze (挤压):
- 输入:一个特征图
X,维度为[H, W, C]。 - 操作:对每个通道执行全局平均池化 (Global Average Pooling, GAP)。这将每个
[H, W]的2D通道压缩成一个单一的数值。 - 输出:一个
[1, 1, C]的特征向量。这个向量的每个元素代表了对应通道的全局信息(例如,该通道的平均激活强度),可以看作是该通道的“全局描述子”。
- 输入:一个特征图
-
Excitation (激励):
- 输入:Squeeze步骤得到的
[1, 1, C]全局描述子。 - 操作:
- 通过一个全连接层 (Fully Connected Layer) 将
C维向量降维到C/r维(r是缩减率,通常为16)。这是一个“瓶颈”结构,用于减少模型参数和计算量。 - 再通过另一个全连接层将
C/r维向量恢复到C维。 - 最后,通过一个 Sigmoid 激活函数 将输出值归一化到
[0, 1]之间。
- 通过一个全连接层 (Fully Connected Layer) 将
- 输出:一个
[1, 1, C]的权重向量s,其中每个元素s_c是对应通道的权重。这些权重表示了模型学习到的每个通道的重要性。
- 输入:Squeeze步骤得到的
-
Scale (缩放):
- 输入:原始特征图
X([H, W, C]) 和学习到的权重向量s([1, 1, C])。 - 操作:将
s中的每个权重s_c与原始特征图X中对应的通道X_c进行逐元素相乘 (element-wise multiplication)。 - 输出:通道加权后的特征图
X'([H, W, C])。
- 输入:原始特征图
通过这个过程,SE Block 学习到了每个特征通道的“重要性”,并用这些权重来强化重要的通道,弱化不重要的通道。
插入的位置:
通道注意力模块通常被插入在:
- 卷积块之后 (After Convolution Blocks):在标准的卷积层(或一系列卷积层,如ResNet中的残差块)的输出之后,但在下一个主要操作(如池化层、另一个卷积块或最终分类层)之前。
- 残差块内部 (Within Residual Blocks):在像ResNet这样的网络中,SE Block可以非常自然地集成到残差块的跳跃连接之前或之后,以优化每个残差学习的特征。例如,在ResNet的每个bottleneck block的卷积操作之后、ReLU激活之前,或者直接在ReLU之后。
它通常作为一种即插即用 (Plug-and-Play) 的模块,可以轻松地添加到现有网络架构中,而无需对整个网络进行大幅度的修改。
4. 通道注意力后的特征图和热力图
通道注意力后的特征图 (Feature Map after Channel Attention):
通道注意力模块的直接输出仍然是一个特征图,其维度与输入特征图相同 [H, W, C]。
所不同的是,这个新的特征图 X' 中的每个通道的激活值都被相应的注意力权重 s_c 进行了加权调整:
X'_c(i, j) = X_c(i, j) * s_c
其中 X'_c(i, j) 是加权后特征图在通道 c 的位置 (i, j) 的值,X_c(i, j) 是原始特征图对应的值,s_c 是通道 c 的注意力权重。
效果:
- 如果某个通道的权重
s_c接近1,表示该通道非常重要,其特征值基本保持不变或略微增强。 - 如果某个通道的权重
s_c接近0,表示该通道不重要,其特征值会被大幅度抑制,接近于0。 - 这样,模型在后续处理中会更加关注那些被强化的、重要的特征通道,从而提升对关键信息的感知能力。
与热力图 (Heatmap) 的关系:
“热力图”通常指的是空间注意力图 (Spatial Attention Map) 或 类激活映射 (Class Activation Map, CAM),它以可视化的方式显示输入图像中哪些区域对模型的决策贡献最大。通道注意力本身并不直接生成一个显示输入图像空间重要性的热力图。
然而,通道注意力对“热力图”的影响体现在:
-
间接影响下游特征图的语义:
- 通道注意力通过增强对任务更重要的特征通道(例如,与特定类别相关的部件特征)和抑制不重要的通道,实际上是在引导模型内部的信息流。
- 当这些经过通道加权调整的特征图继续传播到网络的更深层时,它们将携带更聚焦、更具判别性的信息。
-
改善最终生成的类激活热力图 (CAM/Grad-CAM):
- 当结合通道注意力机制的网络用于生成CAM或Grad-CAM时,由于网络在内部已经学习了哪些特征是重要的,所以生成的CAM通常会更准确地聚焦于目标对象或其关键部分。
- 举例来说,如果没有通道注意力,网络可能对狗的毛发纹理和背景草地都分配了一定的关注。而有了通道注意力,它可能学会了在识别狗时,毛发纹理这个通道比草地纹理通道更重要,从而在生成的CAM中,狗的身体区域会显示出更强的激活,而背景区域的激活会被抑制。
总结:
- 通道注意力后的特征图:是原始特征图经过通道维度上的加权调整,强调了重要的特征通道,抑制了不重要的特征通道。
- 热力图:通常是空间上的可视化。通道注意力不直接产生空间热力图,但它通过优化特征通道的重要性,能够间接且有效地提升最终生成的空间热力图的准确性和聚焦能力,使其更能反映模型对图像关键区域的关注。
- 当然,以下是一个示例代码,演示如何在PyTorch框架中对比不同卷积层的特征图可视化。这个示例以ResNet模型为例,展示如何提取并可视化第1层、第2层和第3层卷积输出的特征图。
代码:对比不同卷积层特征图可视化(PyTorch)
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
# 定义设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载预训练模型(如ResNet18)
model = torchvision.models.resnet18(pretrained=True).to(device)
model.eval()
# 选定需要可视化的层
# 这里使用ResNet的层,具体以layer1[0], layer2[0], layer3[0]为例
# 你可以根据需要选择不同的层
layer1 = model.layer1[0].conv1
layer2 = model.layer2[0].conv1
layer3 = model.layer3[0].conv1
# 创建钩子函数,用于提取特征图
features = {}
def get_hook(name):
def hook(module, input, output):
features[name] = output.detach()
return hook
# 注册钩子
layer1.register_forward_hook(get_hook('layer1'))
layer2.register_forward_hook(get_hook('layer2'))
layer3.register_forward_hook(get_hook('layer3'))
# 图像预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std =[0.229, 0.224, 0.225])
])
# 载入一张示例图片
img_path = '你的图片路径.jpg' # 替换为你的图片路径
from PIL import Image
img = Image.open(img_path).convert('RGB')
input_tensor = transform(img).unsqueeze(0).to(device)
# 前向传播,激活钩子函数
with torch.no_grad():
output = model(input_tensor)
# 定义函数用于可视化特征图
def plot_feature_maps(feature_maps, title):
num_feature_maps = feature_maps.shape[1]
size = int(np.sqrt(num_feature_maps))
plt.figure(figsize=(15, 15))
for i in range(min(num_feature_maps, 16)): # 最多显示16个特征图
plt.subplot(4, 4, i+1)
plt.imshow(feature_maps[0, i].cpu(), cmap='viridis')
plt.axis('off')
plt.suptitle(title)
plt.show()
# 可视化不同层的特征图
for layer_name in ['layer1', 'layer2', 'layer3']:
fmap = features[layer_name]
plot_feature_maps(fmap, f'Feature Maps from {layer_name}')
说明:
- 你可以选择不同的层(
layer1、layer2、layer3)进行钩子注册,提取不同卷积层的特征图。 - 代码中
plot_feature_maps函数会显示前16个特征图(如果存在)。 - 替换
img_path为你的测试图片路径。 - 可视化结果会显示不同层的特征图,帮助你直观对比。