SEA: Supervised Embedding Alignment for Token-Level Visual-Textual Integration in MLLMs
➡️ 论文标题:SEA: Supervised Embedding Alignment for Token-Level Visual-Textual Integration in MLLMs
➡️ 论文作者:Yuanyang Yin, Yaqi Zhao, Yajie Zhang, Ke Lin, Jiahao Wang, Xin Tao, Pengfei Wan, Di Zhang, Baoqun Yin, Wentao Zhang
➡️ 研究机构: 中国科学技术大学、北京大学、快手科技
➡️ 问题背景:多模态大语言模型(MLLMs)在多模态感知和推理任务中展现了显著的能力,通常由视觉编码器、适配器和大语言模型(LLM)组成。适配器作为视觉和语言组件之间的关键桥梁,其训练通常依赖于图像级监督,这往往导致显著的对齐问题,削弱了LLMs的能力,限制了多模态LLMs的潜力。
➡️ 研究动机:现有的训练范式在多模态大语言模型中存在视觉和文本特征对齐不足的问题,尤其是在预训练阶段,视觉特征与文本特征之间的不匹配导致了模型理解能力和生成能力的不一致。为了改善这一问题,研究团队提出了一种新的监督嵌入对齐方法(Supervised Embedding Alignment, SEA),旨在通过显式监督精确对齐视觉令牌与LLM的嵌入空间,从而提高模型的性能和可解释性。
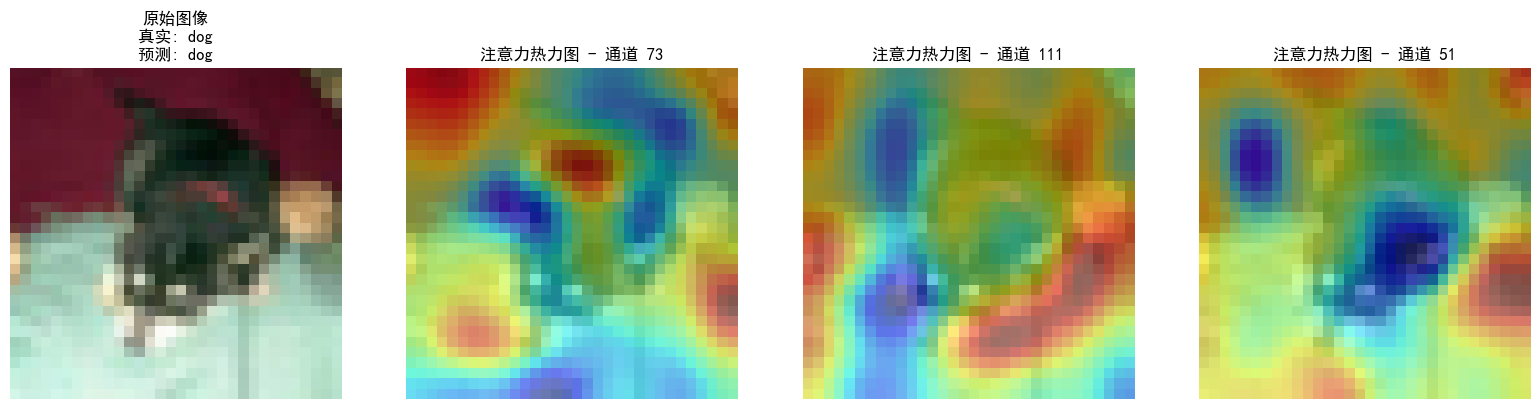
➡️ 方法简介:研究团队提出了一种新的监督对齐范式SEA,该方法利用视觉-语言预训练模型(如CLIP)来生成每个视觉令牌的语义标签,并通过对比学习在预训练阶段直接对齐视觉令牌与LLM的嵌入空间。具体来说,SEA通过两个关键方面改进了对齐:1) 通过细粒度的语义标签进行令牌级对齐;2) 通过对比学习损失与LLM预测损失的结合来更新适配器,从而增强其对齐能力。
➡️ 实验设计:研究团队在8个基准数据集上进行了实验,包括VQAv2、TextVQA、GQA、ScienceQA-IMG、MMBench、POPE、VizWiz和MM-Vet。实验结果表明,SEA显著提高了LLaVA-1.5在这些基准上的性能,而无需额外的注释、数据或推理成本。此外,SEA在保持语言模型能力的同时,提高了多模态任务的性能,展示了其通用性和成本效益。
AppAgent v2: Advanced Agent for Flexible Mobile Interactions
➡️ 论文标题:AppAgent v2: Advanced Agent for Flexible Mobile Interactions
➡️ 论文作者:Yanda Li, Chi Zhang, Wanqi Yang, Bin Fu, Pei Cheng, Xin Chen, Ling Chen, Yunchao Wei
➡️ 研究机构: University of Technology Sydney、Tencent、Beijing Jiaotong University、Westlake University
➡️ 问题背景:随着多模态大语言模型(MLLM)的发展,基于LLM的视觉代理在软件界面,尤其是图形用户界面(GUI)中,正逐渐发挥更大的作用。然而,准确识别GUI仍然是一个关键挑战,影响了多模态代理的决策准确性。传统的基于文本的代理在处理视觉数据和其他模态时存在局限性,特别是在移动和操作系统平台等复杂环境中,需要执行多步推理、提取和整合信息,并对用户输入做出适应性响应。
➡️ 研究动机:现有的多模态代理在处理不熟悉的或独特的界面元素时,由于依赖于标准解析器,其操作灵活性受到限制,影响了其在多样化应用中的整体有效性。为了解决这些局限性,研究团队提出了一种新的多模态代理框架,旨在适应动态的移动环境和多样化应用,通过构建灵活的动作空间和结构化的存储系统,增强代理与GUI的交互能力和对新环境任务的适应性。
➡️ 方法简介:研究团队开发了一种多模态代理框架,该框架结合了解析器和视觉特征,构建了一个灵活的动作空间,增强了与GUI的交互能力。框架通过两个主要阶段运行:探索阶段和部署阶段。在探索阶段,代理自主分析和记录未知UI元素和应用的功能,构建一个强大的知识库。在部署阶段,代理利用RAG技术动态访问和更新知识库,显著提高了其在新场景中的适应能力和决策精度。
➡️ 实验设计:研究团队在三个不同的基准测试上进行了实验,涵盖了多个应用的任务。实验结果包括定量分析和用户研究,验证了该方法在各种智能手机应用中的优越性和鲁棒性,证明了其在真实场景中的适应性、用户友好性和效率。
CaRDiff: Video Salient Object Ranking Chain of Thought Reasoning for Saliency Prediction with Diffusion
➡️ 论文标题:CaRDiff: Video Salient Object Ranking Chain of Thought Reasoning for Saliency Prediction with Diffusion
➡️ 论文作者:Yunlong Tang, Gen Zhan, Li Yang, Yiting Liao, Chenliang Xu
➡️ 研究机构: ByteDance、University of Rochester
➡️ 问题背景:视频显著性预测旨在识别视频中吸引人类注意力和注视的区域,这一过程受到视频的自下而上的特征和自上而下的记忆和认知过程的影响。语言在这一过程中扮演了重要角色,通过塑造视觉信息的解释来引导注意力。然而,现有的方法主要集中在建模感知信息,而忽视了语言在推理过程中的作用,特别是排名线索在显著性预测中的重要性。
➡️ 研究动机:为了弥补现有方法的不足,研究团队提出了一种新的框架CaRDiff(Caption, Rank, and generate with Diffusion),该框架通过整合多模态大语言模型(MLLM)、接地模块和扩散模型,增强了视频显著性预测的能力。具体来说,研究团队引入了一种新的提示方法VSOR-CoT(Video Salient Object Ranking Chain of Thought),利用MLLM和接地模块生成视频内容的字幕,并推断显著对象及其排名和位置,从而生成排名图,指导扩散模型解码最终的显著性图。
➡️ 方法简介:研究团队提出了一种系统的方法,通过构建VSOR-CoT Tuning数据集,评估了不同提示方法对视频显著性预测的影响。VSOR-CoT方法通过链式思维推理生成显著对象的排名,这些排名图与视频帧结合,作为扩散模型的解码条件,以预测最终的显著性图。
➡️ 实验设计:研究团队在MVS和DHF1k两个数据集上进行了实验,评估了CaRDiff在不同条件下的表现。实验设计了不同的因素(如排名图的比例、随机排名图的替换等),以及不同类型的评估指标(如AUC-J、CC、SIM、NSS),以全面评估模型的性能和泛化能力。实验结果表明,CaRDiff在MVS数据集上取得了最先进的性能,并在DHF1k数据集上展示了零样本评估的能力。
MaVEn: An Effective Multi-granularity Hybrid Visual Encoding Framework for Multimodal Large Language Model
➡️ 论文标题:MaVEn: An Effective Multi-granularity Hybrid Visual Encoding Framework for Multimodal Large Language Model
➡️ 论文作者:Chaoya Jiang, Jia Hongrui, Haiyang Xu, Wei Ye, Mengfan Dong, Ming Yan, Ji Zhang, Fei Huang, Shikun Zhang
➡️ 研究机构: 北京大学软件工程国家重点实验室、阿里巴巴集团
➡️ 问题背景:当前的多模态大模型(Multimodal Large Language Models, MLLMs)主要集中在单图像视觉理解上,这限制了它们在多图像场景中解释和整合信息的能力。多图像场景包括基于知识的视觉问答(Knowledge Based VQA)、视觉关系推理(Visual Relation Inference)和多图像推理(Multi-image Reasoning)等,这些场景具有广泛的实际应用价值。
➡️ 研究动机:现有的多模态大模型在处理多图像任务时表现不佳,主要因为这些模型的设计初衷是处理单图像输入。研究团队提出了一种新的多粒度混合视觉编码框架MaVEn,旨在通过结合离散视觉符号序列和连续视觉特征序列,提高多模态大模型在多图像场景中的理解和推理能力。
➡️ 方法简介:MaVEn框架利用离散视觉符号序列来抽象图像中的粗粒度语义概念,同时使用连续高维向量序列来捕捉细粒度的视觉细节。此外,为了减少多图像场景中的输入上下文长度,研究团队还设计了一种基于文本语义的动态视觉特征减少机制。该框架通过多阶段模型训练方法,逐步优化模型的多图像理解能力。
➡️ 实验设计:研究团队在多个公开数据集上进行了实验,包括DemonBench和SEED-Bench,这些数据集涵盖了多图像理解和推理任务以及视频理解任务。实验结果表明,MaVEn在多图像场景中显著提高了模型的理解和推理能力,同时在单图像任务中也表现出色。
Vintern-1B: An Efficient Multimodal Large Language Model for Vietnamese
➡️ 论文标题:Vintern-1B: An Efficient Multimodal Large Language Model for Vietnamese
➡️ 论文作者:Khang T. Doan, Bao G. Huynh, Dung T. Hoang, Thuc D. Pham, Nhat H. Pham, Quan T. M. Nguyen, Bang Q. Vo, Suong N. Hoang
➡️ 研究机构: HKUST (GZ)、BJUT、Drexel University、University of Oxford
➡️ 问题背景:当前的多模态大语言模型(Multimodal Large Language Models, MLLMs)在处理越南语任务时表现出色,尤其是在光学字符识别(OCR)、文档信息提取和视觉问答(VQA)等任务中。然而,越南语MLLMs的发展受到高质量多模态数据集有限的限制,尤其是在处理特定于越南的文档、图表和场景文本识别方面。
➡️ 研究动机:为了克服现有越南语MLLMs在处理特定于越南的视觉和文本数据时的局限性,研究团队开发了Vintern-1B,这是一个专门针对越南语任务的10亿参数多模态大语言模型。通过整合Qwen2-0.5B-Instruct语言模型和InternViT-300M-448px视觉模型,Vintern-1B在多个越南语基准测试中表现出色,并且适用于各种设备上的应用。
➡️ 方法简介:研究团队构建了一个详细的架构,包括视觉编码器(InternViT-300M-448px)、多层感知机投影器(MLP Projector)和大型语言模型(Qwen2-0.5B-Instruct)。此外,团队还创建了多个越南语多模态数据集,涵盖了一般问答、OCR、文档理解、手写识别和信息提取等任务,以全面训练和评估模型的性能。
➡️ 实验设计:Vintern-1B在多个数据集上进行了训练和测试,包括Vista、Viet-OpenViVQA-gemini-VQA、Viet-Localization-VQA、Viet-OCR-VQA等。实验设计了不同的任务类型和场景,以评估模型在处理越南语多模态数据时的准确性和鲁棒性。通过这些贡献,研究团队旨在推动越南语MLLMs的发展,为研究人员和实践者提供必要的工具和资源,以探索和创新语言和视觉在越南语背景下的交叉应用。