ChatterBox 是一个近期备受关注的开源语音克隆与文本转语音(TTS)模型,由 Resemble AI 推出,具备体积轻巧及超快的推理速度等特色。它也是首个支持情感夸张控制的开放源代码 TTS 模型,这一强大功能能让您的声音脱颖而出。
ChatterBox 是一个近期备受关注的开源语音克隆与文本转语音(TTS)模型,由 Resemble AI 推出,具备体积轻巧及超快的推理速度等特色。它也是首个支持情感夸张控制的开放源代码 TTS 模型,这一强大功能能让您的声音脱颖而出。
核心特点
零样本语音克隆 仅需数秒参考音频即可克隆目标声音,无需额外训练,适用于个性化语音助手和虚拟角色配音。
情绪夸张控制 首个支持通过参数调节语音情感强度的开源 TTS 模型,可生成从平淡到戏剧化的多种表达,显著优于传统机械输出。
超低延迟与高效部署 推理延迟低于 200ms,支持实时应用(如语音助手、游戏对话),并提供轻量级 Python 库(chatterbox-tts)简化部署。
内置安全水印 集成 PerTh 神经水印技术,确保生成音频可溯源,平衡技术开放性与伦理风险。
开源与高性能 基于 0.5B 参数的 LLaMA 架构,训练数据达 50 万小时,盲测中 63.75% 用户认为其音质优于 ElevenLabs。
应用领域
娱乐与媒体:动画配音、广告旁白、游戏角色语音生成。
智能交互:个性化语音助手、实时对话系统。
内容创作:短视频、有声书、多语言播客的自动化语音合成。
伦理研究:水印技术为 AI 语音滥用防治提供案例
使用教程:(建议N卡,显存4G起。支持50系显卡,基于CUDA12.8)
包含TTS(文本转语音)和VC(语音转换)两种功能
TTS,和其他类似软件操作一样,输入文本,上传参考音频,生成即可。
VC,上传需要转换的音频和参考音频,提交生成即可。
TTS目前只支持英文,其他语音等待后期官方更新。
VC支持跨语种转换
下载地址:https://deepfaces.cc/thread-692-1-1.html
ChatterBox - 轻巧快速的语音克隆与文本转语音模型,支持情感控制 支持50系显卡 一键整合包下载
news2026/4/16 11:53:22
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2405002.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

前端开发面试题总结-HTML篇
文章目录 HTML面试高频问答一、HTML 的 src 和 href 属性有什么区别?二、什么是 HTML 语义化?三、HTML的 script 标签中 defer 和 async 有什么区别?四、HTML5 相比于 HTML有哪些更新?五、HTML行内元素有哪些? 块级元素有哪些? 空(void)元素有哪些?六、iframe有哪些优点…
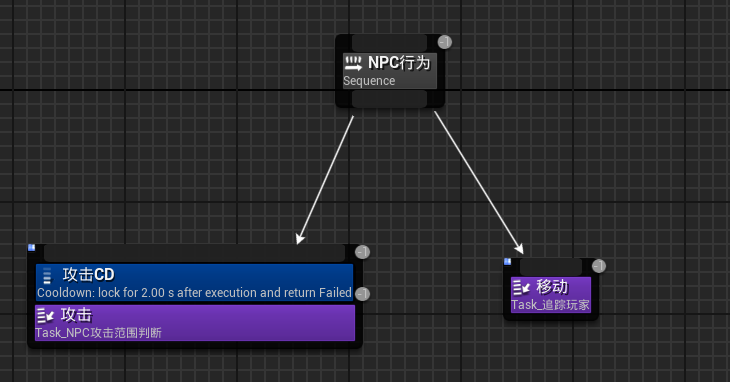
嵌入式学习--江协stm32day4
只能说拖延没有什么好结果,欠下的债总是要还的。
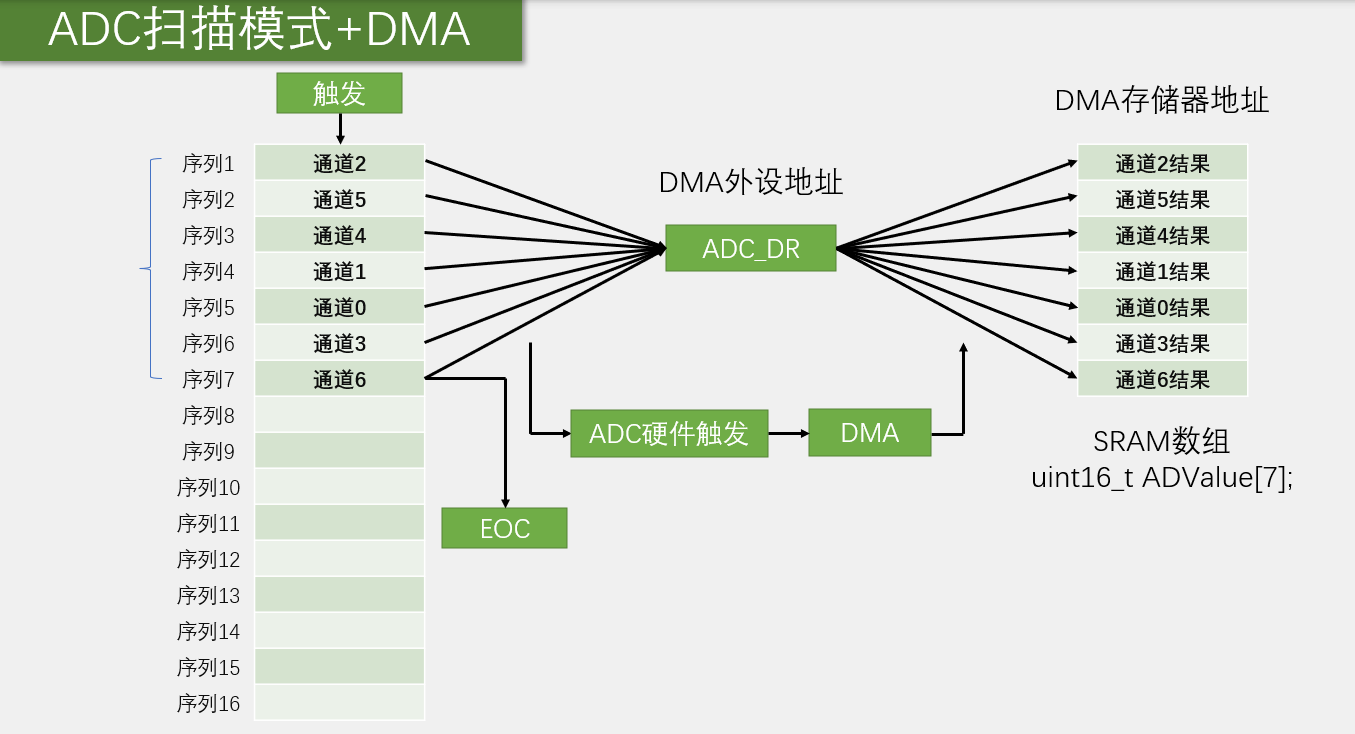
ADC 模拟信号转化为数字信号,例如温度传感器将外部温度的变化(模拟信号),转换为内部电压的变化(数字信号) IN是八路输入,下方是选择…
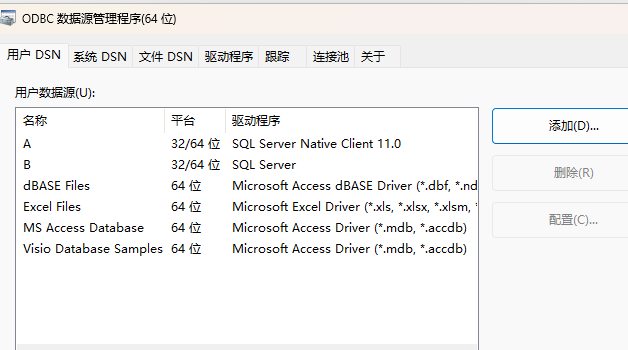
【Matlab】连接SQL Server 全过程
文章目录 一、下载与安装1.1 SQL Server1.2 SSMS1.3 OLE DB 驱动程序 二、数据库配置2.1 SSMS2.2 SQL Server里面设置2.3 设置防火墙2.4 设置ODBC数据源 三、matlab 链接测试 一、下载与安装
微软的,所以直接去微软官方下载即可。
1.1 SQL Server
下载最免费的Ex…

9.RV1126-OPENCV 视频的膨胀和腐蚀
一.膨胀
1.视频流的膨胀流程 之前膨胀都是在图片中进行的,现在要在视频中进行也简单,大概思路就是:获取VI数据,然后把VI数据给Mat化发给VENC模块,然后VENC模块获取,这样就完成了。流程图: 2.代…
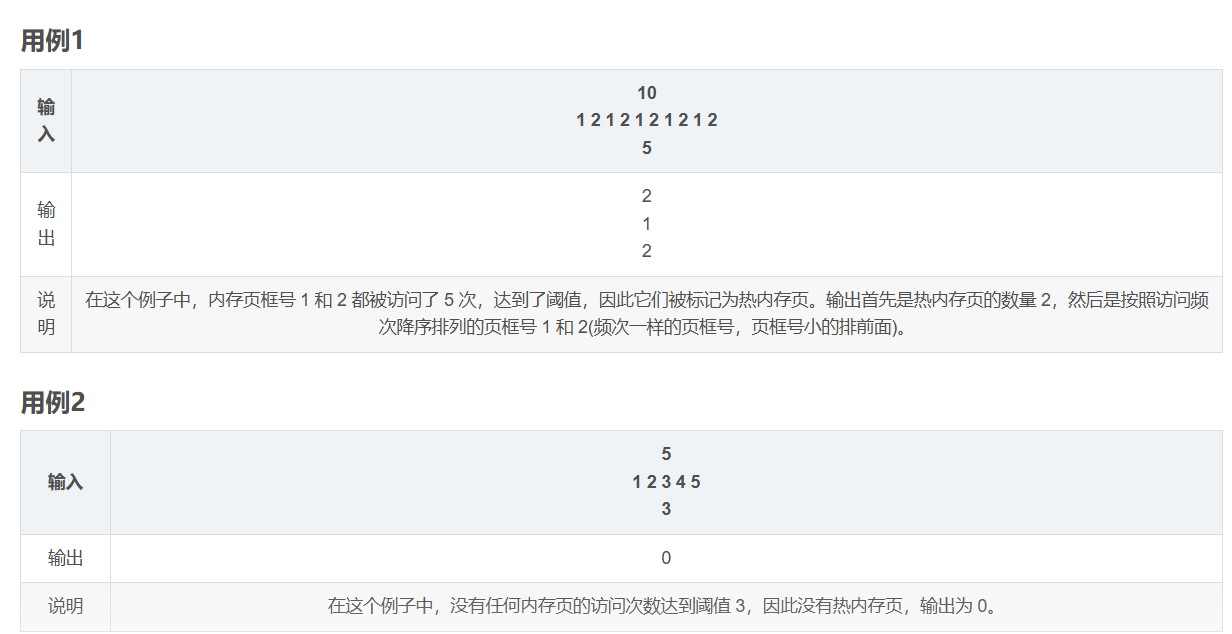
华为OD机考-内存冷热标记-多条件排序
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextInt();int[] arr new int[a];for(int…

AI时代:学习永不嫌晚,语言多元共存
最近看到两个关于AI的两个问题,“现在开始学习AI,是不是为时已晚?”、“AI出现以后,翻译几乎已到末路,那么,随着时代的进步,中文会一统全球吗?” 联想到自己正在做的“万能AI盒”小程…
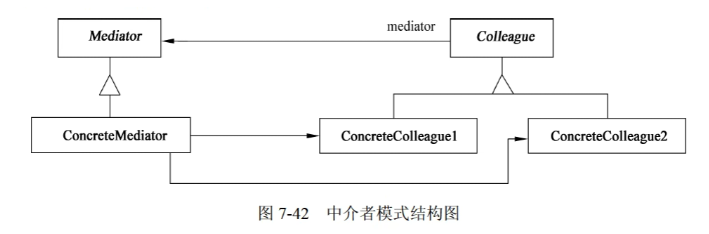
行为型设计模式之Mediator(中介者)
行为型设计模式之Mediator(中介者)
1)意图
用一个中介对象来封装一系列的对象的交互。中介者使各对象不需要显示的相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
2)结构 其中ÿ…

三维图形、地理空间、激光点云渲染技术术语解析笔记
三维图形、地理空间、激光点云渲染技术术语解析笔记 code review! 文章目录 三维图形、地理空间、激光点云渲染技术术语解析笔记1. Minecraft风格的方块渲染2. Meshing(网格化)3. Mipmapping(多级纹理映射)4. Marching Cubes&…
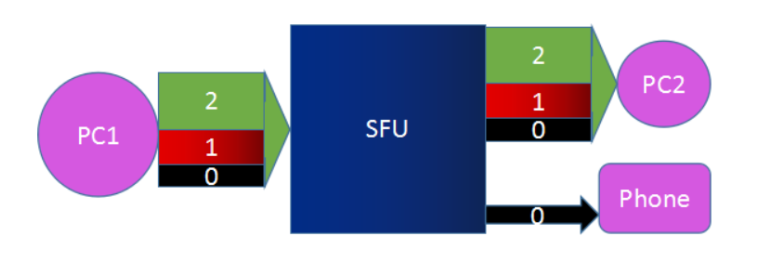
从webrtc到janus简介
1.基础知识
1.1 信令的基础知识
在 WebRTC(Web Real-Time Communication) 中,信令(Signaling) 是实现浏览器之间实时通信的关键机制,负责在通信双方(或多方)之间传递控制信息&…

JVM 核心概念深度解析
最近正在复习Java八股,所以会将一些热门的八股问题,结合ai与自身理解写成博客便于记忆
一、JVM内存结构/运行时数据区
JVM运行时数据区主要分为以下几个部分: 程序计数器(PC Register) 线程私有,记录当前线程执行的字节码行号唯…
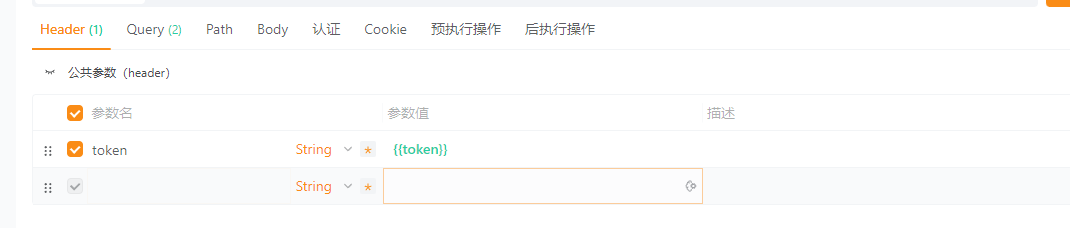
api将token设置为环境变量
右上角 可以新增或者是修改当前的环境 环境变量增加一个token,云端值和本地值可以不用写
在返回token的接口里设置后执行操作,通常是登录的接口 右侧也有方法提示
//设置环境变量
apt.environment.set("token", response.json.data.token);
在需要传t…

SIFT算法详细原理与应用
SIFT算法详细原理与应用 1 SIFT算法由来
1.1 什么是 SIFT?
SIFT,全称为 Scale-Invariant Feature Transform(尺度不变特征变换),是一种用于图像特征检测和描述的经典算法。它通过提取图像中的局部关键点,…
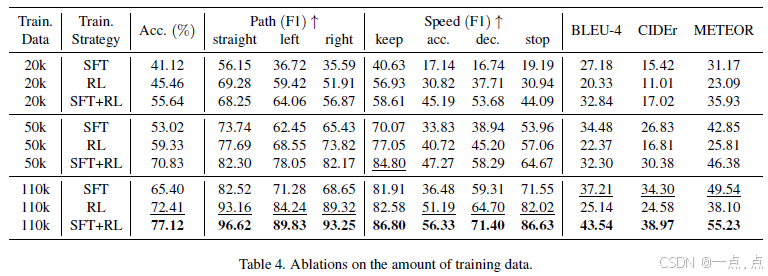
AlphaDrive:通过强化学习和推理释放自动驾驶中 VLM 的力量
AlphaDrive: Unleashing the Power of VLMs in Autonomous Driving via Reinforcement Learning and Reasoning
25年3月来自华中科技大学和地平线的论文 OpenAI 的 o1 和 DeepSeek R1 在数学和科学等复杂领域达到甚至超越了人类专家水平,其中强化学习(R…

【八股消消乐】如何解决SQL线上死锁事故
😊你好,我是小航,一个正在变秃、变强的文艺倾年。 🔔本专栏《八股消消乐》旨在记录个人所背的八股文,包括Java/Go开发、Vue开发、系统架构、大模型开发、具身智能、机器学习、深度学习、力扣算法等相关知识点ÿ…

如何使用 HTML、CSS 和 JavaScript 随机更改图片颜色
原文:如何使用 HTML、CSS 和 JavaScript 随机更改图片颜色 | w3cschool笔记
(请勿标记为付费!!!!)
在网页开发中,为图片添加动态效果可以显著提升用户体验。今天,我将向…
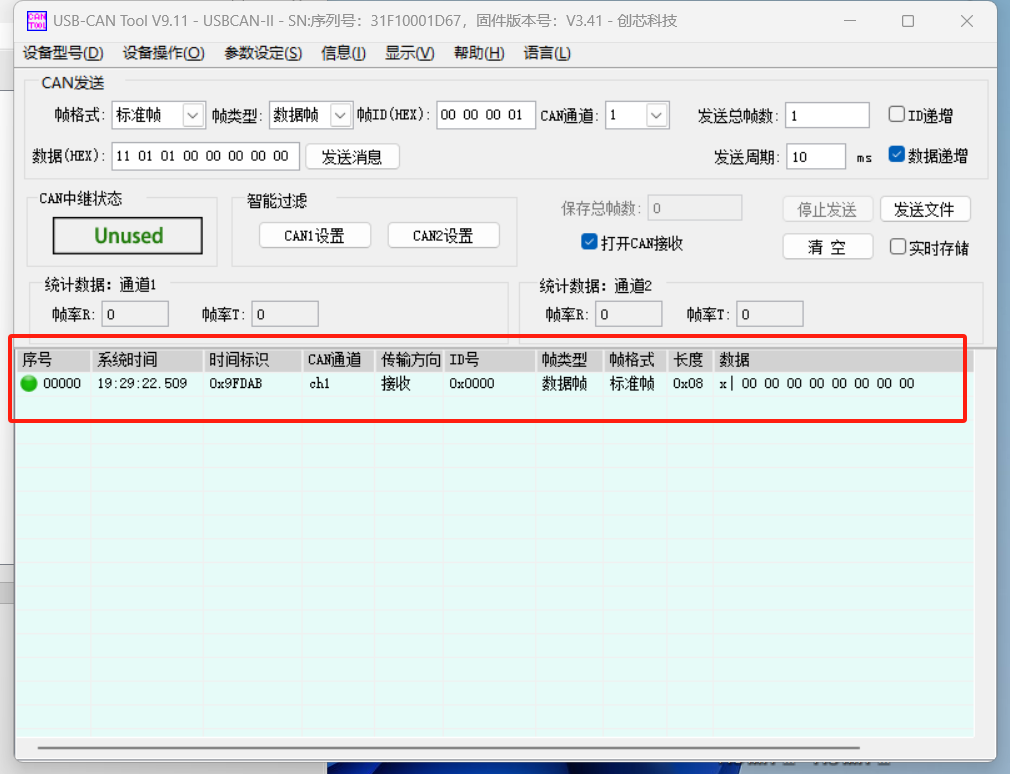
CAN通信收发测试(USB2CAN模块测试实验)
1.搭建测试环境
电脑:安装 USB 驱动,安装原厂调试工具,安装cangaroo(参考安装包的入门教程即可) USB驱动路径:~\CAN分析仪资料20230701_Linux\硬件驱动程序 原厂调试工具路径:~\CAN分析仪资料2…
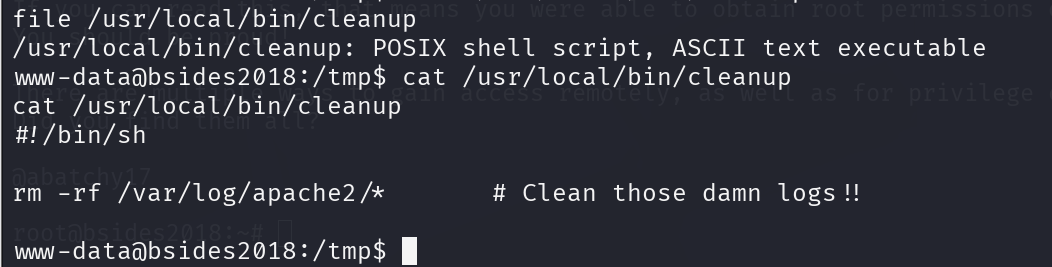
OSCP备战-BSides-Vancouver-2018-Workshop靶机详细步骤
一、靶机介绍
靶机地址:https://www.vulnhub.com/entry/bsides-vancouver-2018-workshop%2C231/
靶机难度:中级(CTF)
靶机发布日期:2018年3月21日
靶机描述:
Boot2root挑战旨在创建一个安全的环境&…
PDF转Markdown/JSON软件MinerU最新1.3.12版整合包下载
MinerU发布至今我已经更新多版整合包了,5天前MinerU发布了第一个正式版1.0.1,并且看到在18小时之前有更新模型文件,我就做了个最新版的一键启动整合包。 2025年02月21日更新v1.1.0版整合包
2025年02月27日更新v1.2.0版整合包
2025-06-05 更…
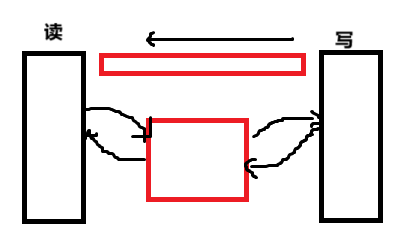
【深入学习Linux】System V共享内存
目录 前言 一、共享内存是什么? 共享内存实现原理 共享内存细节理解 二、接口认识 1.shmget函数——申请共享内存 2.ftok函数——生成key值 再次理解ftok和shmget 1)key与shmid的区别与联系 2)再理解key 3)通过指令查看/释放系统中…