文章目录
- 0.简介
- 1.并发编程需要保证的特性
- 2.原子操作
- 2.1 原子操作的特性
- 3.内存顺序
- 3.1 顺序一致性
- 3.2 释放-获取(Release-Acquire)
- 3.3 宽松顺序(Relaxed)
- 3.4 内存顺序
- 4.无锁并发
- 5. 使用建议
0.简介
在并发编程中,原子性、可见性和有序性是确保程序正确执行的三大特性。常见的保证这三个特性的操作是通过加锁来限制资源的访问,但这种方式会带来性能的降低,所以无锁编程变的日益常见,本文将对原子性、可见性和有序性进行介绍,同时介绍原子操作和内存顺序从而实现无锁的并发。
1.并发编程需要保证的特性
要理解原子性,可见性和有序性就需要先明确其对应问题,先从硬件架构和内存访问来看,现代的处理器为了提高性能,普遍采用的都是多级缓存技术和乱序执行技术。
1)多级缓存:每个cpu核心拥有独立的L1/L2缓存,共享L3缓存。这导致不同核心间可见性延迟,如对同一个变量的读写可能存在问题。
2)乱序执行:为了充分的利用指令流水线,只要不影响单线程内结果,指令是存在重排的可能性的,这就导致多线程下可能存在问题。
了解了面对的基础设施,接下来来看这三个特性如果不能保证会存在的问题:
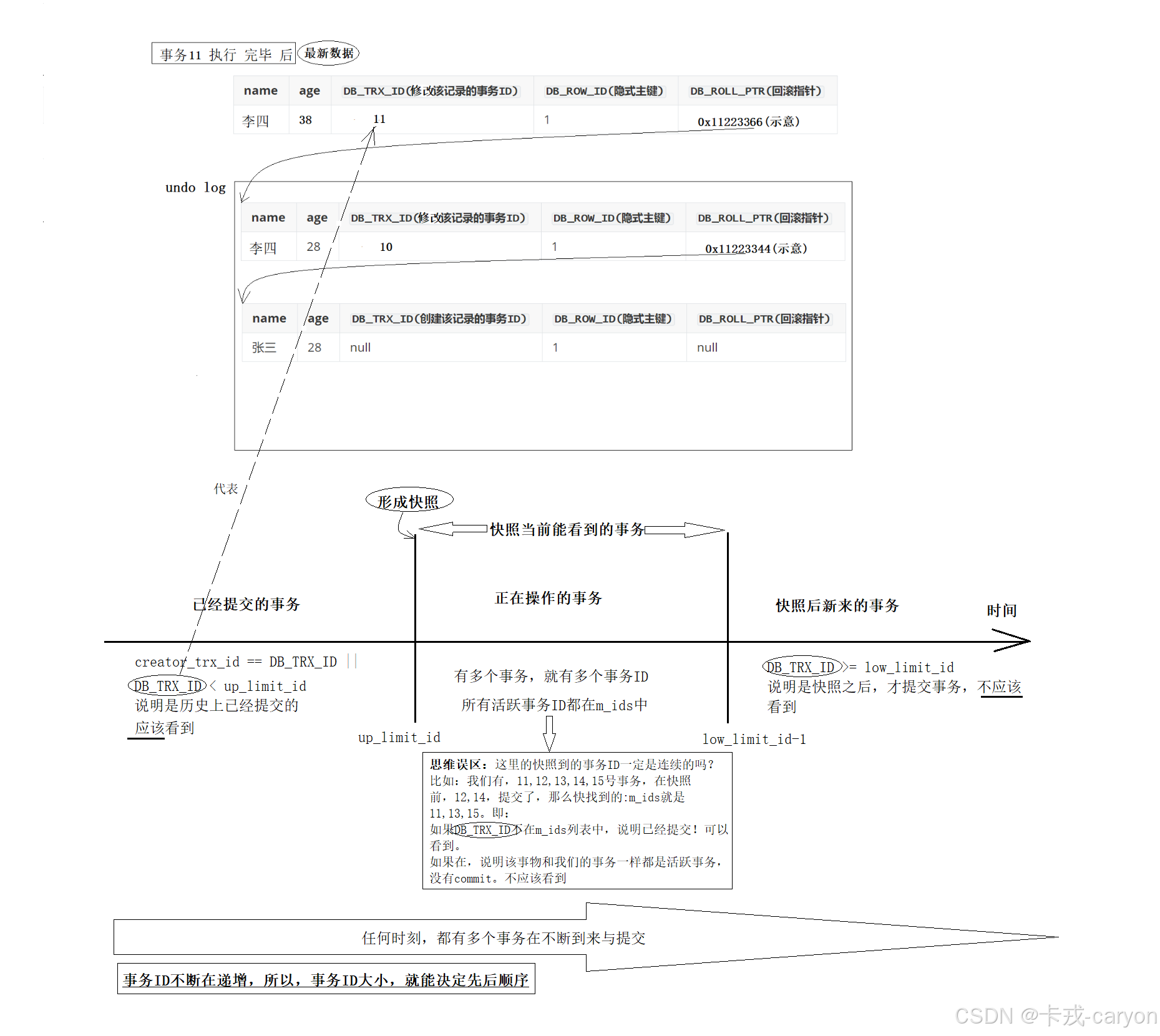
1)原子性:其保证一次操作是原子的,比如var = var +1,假设不是原子的将其分为三步,取值,增加,写回,此时如果有两个线程分别都循环一百次增加var操作,这样线程间就可能互相取到尚未写回(也就是增加了但是没有回)的数值,此时在这基础上增加,就会导致未写回的增加丢失,从而导致结果错误,可以参考下图:
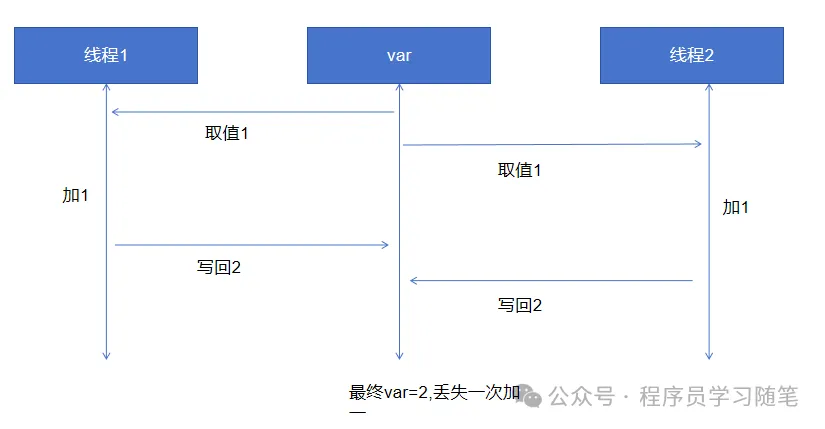
2)可见性:由于上面说的cpu多级缓存,可能存在没有同步到就读取的情况,比如通过bool值判断是否停止循环,这个bool在其他线程设置,此时就可能导致循环无法停止,cpu占用高。
3)有序性:是指执行的指令按照正常顺序执行不会因为重排带来问题,比如一个线程初始化数据,另一个线程使用,根据变量判断是否初始化完成,重排后可能存在问题,可以参考下面,假设这俩函数分别被两个线程执行,此时对于thread2来说,两个语句的先后不影响本身(也就是两个语句没有依赖关系),可能将bInit=true放到前面执行,a=new char[10]放到后面执行,此时thread1就可能出现使用到空指针情况。
char* a = nullptr;
int bInit = 0;
void thread1()
{
if(bInit)
{
//使用a
}
}
void thread2()
{
a = new char[10];
bInit = true;
}
上面三个特性都可以通过加锁保证,但是锁内容不是本文主题,下面将描述原子操作和内存顺序如何保证这三个特性,从而实现无锁的编程。
2.原子操作
C++11引入了头文件,提供标准的原子类型和操作,下面是两个线程对于一个变量循环加一的操作例子:
#include <thread>
#include <iostream>
std::atomic<int> counter(0); // 原子整型
void worker() {
for (int i = 0; i < 1000; ++i) {
counter.fetch_add(1, std::memory_order_relaxed); // 原子加1
}
}
int main() {
std::thread t1(worker);
std::thread t2(worker);
t1.join();
t2.join();
std::cout << "Final counter value: " << counter << std::endl; // 输出2000
}
2.1 原子操作的特性
1)不可分割性:原子操作不会被其他线程中断。
2)内存可见性:操作结果按指定的内存顺序规则对其他线程可见。
2.2 原子操作的分类
1)读操作:采用load()
2)写操作:采用store()
3)修改操作:fetch_add()、fetch_sub()、compare_exchange_strong() 等
每种操作都可以指定内存顺序参数,控制操作可见性和有序性。
3.内存顺序
原子操作本身保证原子性后,可见性和有序性可以通过指定其内存顺序参数来保证,主要可以分为三类:
3.1 顺序一致性
顺序一致性比较好理解,所有的线程看到的原子操作顺序都相同,其执行顺序清晰且可以预测,但其性能开销较大,例子如下:
std::atomic<int> x(0), y(0);
void thread1() {
x.store(1, std::memory_order_seq_cst); // 写x
y.store(1, std::memory_order_seq_cst); // 写y
}
void thread2() {
while (y.load(std::memory_order_seq_cst) == 0); // 等待y=1
// 下面使用x一定是1
}
3.2 释放-获取(Release-Acquire)
释放-获取操作用于保证其调用前后的顺序。
1)释放操作(store+release):确保之前的写操作(如data=42)对其他线程可见。
2)获取操作(load+acquire):确保后续所有读操作(如使用data的地方)能看到释放操作前的所有写。
可以简单理解就是释放操作前的写操作不能重排到释放操作之后,获取操作后的读操作不能重排序到获取操作前。其可以用于像生产者消费者模型,锁机制等。
std::atomic<bool> ready(false);
int data = 0;
void producer() {
data = 42; // 操作1
ready.store(true, std::memory_order_release); // 释放操作(操作2)
}
void consumer() {
while (!ready.load(std::memory_order_acquire)); // 获取操作(操作3)
if(data == 42) xxx; //一定为true
}
3.3 宽松顺序(Relaxed)
其特点是只保证原子性,不去保证顺序和可见性,性能开销最小,适用于无关顺序的场景,如计数器等。
std::atomic<int> counter(0);
void increment() {
counter.fetch_add(1, std::memory_order_relaxed);
}
3.4 内存顺序
除了上述基于原子操作的内存顺序,C++还显式的提供了内存屏障,其主要类型如下:
1)释放屏障:确保对于屏障前的所有写操作不会重排到屏障后。
2)获取屏障:防止屏障后的操作重排到屏障前。
3)全屏障:具有释放和获取的特性。
std::atomic<int> x(0), y(0);
void thread1() {
x.store(1, std::memory_order_relaxed);
std::atomic_thread_fence(std::memory_order_release); // 释放屏障
y.store(1, std::memory_order_relaxed);
}
void thread2() {
while (y.load(std::memory_order_relaxed) == 0) {}
std::atomic_thread_fence(std::memory_order_acquire); // 获取屏障
//x一定为1
}
4.无锁并发
有了上面的了解,可以来尝试实现一个无锁的队列,主要利用原子操作和内存顺序,去保证其原子性,可见性以及有序性,下面是一个简单的例子,可以参考。
#include <atomic>
#include <memory>
#include <iostream>
template<typename T>
class LockFreeQueue {
private:
// 队列节点结构
struct Node {
T data; // 节点数据
std::atomic<Node*> next; // 指向下一个节点的原子指针
Node(const T& value) : data(value), next(nullptr) {}
};
std::atomic<Node*> head; // 队头指针
std::atomic<Node*> tail; // 队尾指针
public:
// 构造函数:初始化队头和队尾指针指向一个虚拟节点
LockFreeQueue() {
Node* dummy = new Node(T()); // 创建虚拟节点
head.store(dummy, std::memory_order_relaxed);
tail.store(dummy, std::memory_order_relaxed);
}
// 析构函数:释放队列中所有节点的内存
~LockFreeQueue() {
while (head.load() != nullptr) {
Node* oldHead = head.load();
head.store(oldHead->next.load(), std::memory_order_relaxed);
delete oldHead;
}
}
// 入队操作
void enqueue(const T& value) {
Node* newNode = new Node(value); // 创建新节点
Node* oldTail = tail.load(std::memory_order_relaxed);
// 使用 CAS 循环尝试将新节点添加到队尾
while (true) {
// 先尝试更新 tail 的 next 指针
if (oldTail->next.compare_exchange_weak(
nullptr, newNode,
std::memory_order_release, // 释放语义:确保 newNode 的数据对其他线程可见
std::memory_order_relaxed)) {
// CAS 成功,更新 tail 指针指向新节点
tail.compare_exchange_strong(
oldTail, newNode,
std::memory_order_relaxed,
std::memory_order_relaxed);
return;
}
// CAS 失败,说明其他线程已经更新了 tail->next
// 更新 oldTail 为最新的 tail 值并重试
oldTail = tail.load(std::memory_order_relaxed);
}
}
// 出队操作
bool dequeue(T& value) {
Node* oldHead = head.load(std::memory_order_relaxed);
// 使用 CAS 循环尝试出队
while (true) {
if (oldHead == tail.load(std::memory_order_relaxed)) {
// 队列为空(只有虚拟节点)
return false;
}
Node* nextNode = oldHead->next.load(std::memory_order_acquire);
// 获取语义:确保能看到入队线程设置的 newNode 的数据
// 尝试更新 head 指针
if (head.compare_exchange_weak(
oldHead, nextNode,
std::memory_order_relaxed,
std::memory_order_relaxed)) {
// 获取数据(跳过虚拟节点)
value = nextNode->data;
delete oldHead; // 释放原头节点(虚拟节点或旧数据节点)
return true;
}
// CAS 失败,说明其他线程已经更新了 head
// 更新 oldHead 为最新的 head 值并重试
oldHead = head.load(std::memory_order_relaxed);
}
}
// 检查队列是否为空
bool empty() const {
return head.load(std::memory_order_relaxed) ==
tail.load(std::memory_order_relaxed);
}
};
5. 使用建议
无锁的编程虽然在一定程度上提高了性能,但其也带来了复杂性和问题排查的困难,可以在对性能有要求且有足够测试的场景下使用。
原文链接:https://mp.weixin.qq.com/s/thnlXKZnKE4foxZ5Vi3NYQ