note
- 构建一个成功的 MAS,不仅仅是提升底层 LLM 的智能那么简单,它更像是在构建一个组织。如果组织结构、沟通协议、权责分配、质量控制流程设计不当,即使每个成员(智能体)都很“聪明”,整个系统也可能像一个管理混乱的公司一样,效率低下、错误频出,甚至彻底崩溃。
文章目录
- note
- 一、Why Do Multi-Agent LLM Systems Fail?
- 多智能体MAS
- 二、五种主流的agent框架及其实际表现
- 三大失败类别
- 类别一:规范与系统设计失败
- 类别二:智能体间协作失调
- 类别三:任务验证与终止失败
- 三、改进方法
- 1.战术性方法 :
- 2.结构性方法:
- Reference
一、Why Do Multi-Agent LLM Systems Fail?
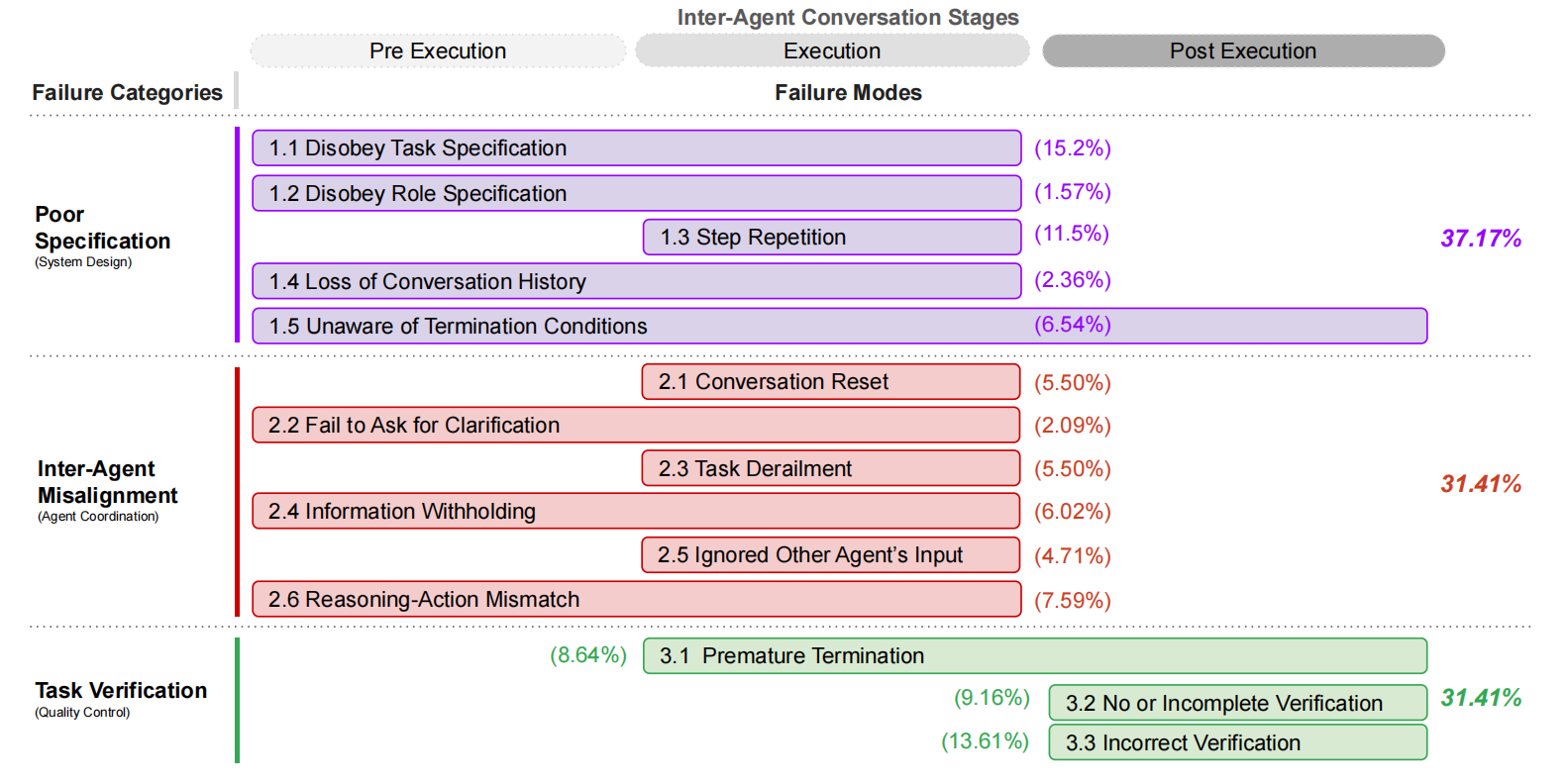
《Why Do Multi-Agent LLM Systems Fail?》(https://arxiv.org/pdf/2503.13657),通过对对5种流行MAS框架、150多个对话轨迹的分析,经过6位专业标注,确定3类共14种故障模式。
多智能体MAS
多智能体系统 (MAS):
这是由多个 LLM 智能体组成的集合。这些智能体被设计成可以相互沟通、协调,共同完成一个更大的目标。设计 MAS 的初衷是为了利用“分工协作”的力量,例如:
- 任务分解: 将复杂任务拆分成小块,交给专门的智能体处理。
- 并行处理: 多个智能体同时工作,提高效率。
- 上下文隔离/专业化: 每个智能体专注于自己的领域,避免信息过载,提升专业度。
- 多样化推理/讨论: 不同智能体可能提出不同见解,通过讨论或辩论产生更好的解决方案。
论文中研究的 MAS 系统(如 MetaGPT, ChatDev, HyperAgent, AppWorld, AG2)就模拟了软件公司、研究团队等协作模式。例如,ChatDev 模拟一个软件开发公司,包含 CEO、CTO、程序员、测试员等不同角色的 AI 智能体,它们通过对话来完成软件开发任务。
二、五种主流的agent框架及其实际表现
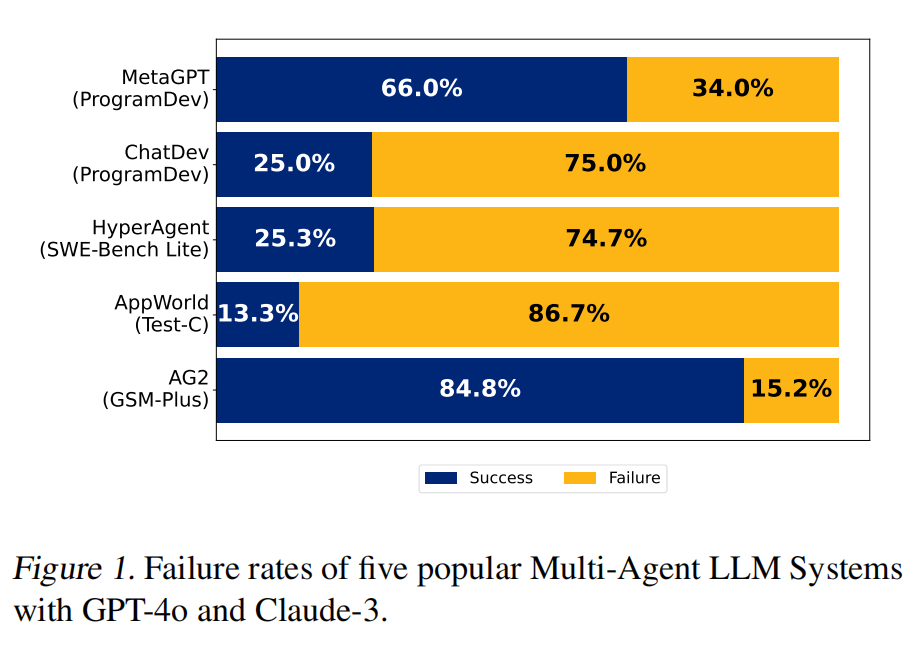
几个框架的实际表现:
AG2(https://github.com/ag2ai/ag2),用于构建代理并管理它们的交互。使用此框架,可以构建各种灵活的对话模式,整合工具使用并自定义终止策略。
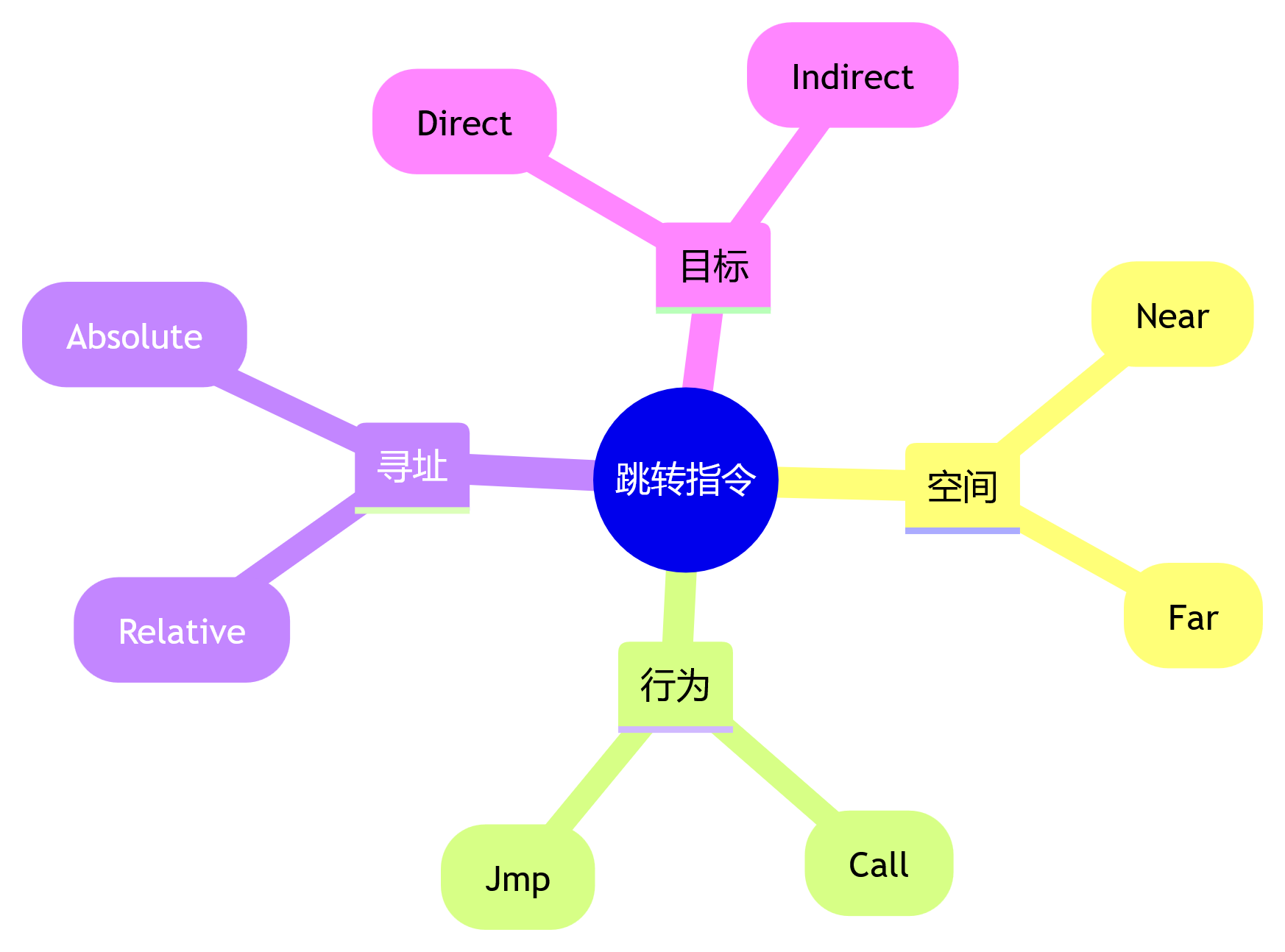
三大失败类别
类别一:规范与系统设计失败
类别一:规范与系统设计失败 (Specification and System Design Failures, 占总失败的 37.17%)
FM-1.1: 不遵从任务规范 (Disobey task specification, 15.2%):
FM-1.2: 不遵从角色规范 (Disobey role specification, 1.57%):
FM-1.3: 步骤重复 (Step repetition, 11.5%):
FM-1.4: 对话历史丢失 (Loss of conversation history, 2.36%):
FM-1.5: 不清楚终止条件 (Unaware of termination conditions, 6.54%):
类别二:智能体间协作失调
类别二:智能体间协作失调 (Inter-Agent Misalignment, 占总失败的 31.41%)
FM-2.1: 对话重置 (Conversation reset, 5.50%):
FM-2.2: 未能请求澄清 (Fail to ask for clarification, 2.09%):
FM-2.3: 任务偏离 (Task derailment, 5.50%):
FM-2.4: 信息隐瞒 (Information withholding, 6.02%):
FM-2.5: 忽略其他智能体输入 (Ignored other agent’s input, 4.71%):
FM-2.6: 推理-行动不匹配 (Reasoning-action mismatch, 7.59%):
类别三:任务验证与终止失败
类别三:任务验证与终止失败 (Task Verification and Termination, 占总失败的 31.41%)
FM-3.1: 过早终止 (Premature termination, 8.64%):
FM-3.2: 无验证或验证不完整 (No or incomplete verification, 9.16%):
FM-3.3: 验证不正确 (Incorrect verification, 13.61%):
三、改进方法
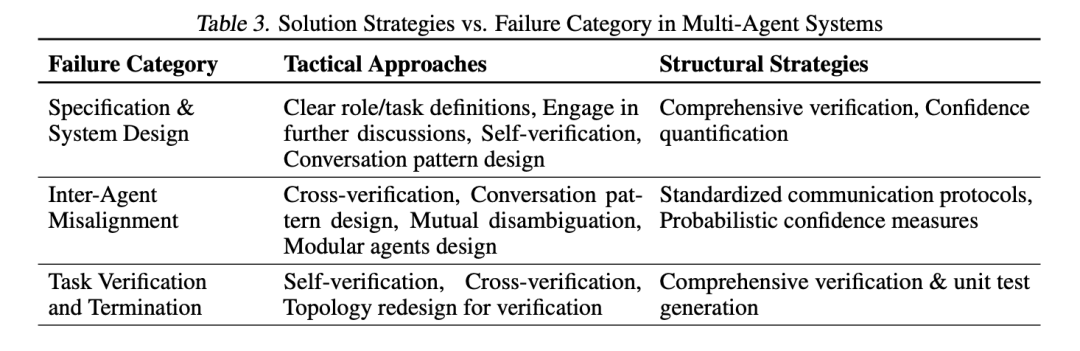
1.战术性方法 :
这些是相对直接、针对特定失败模式的“小修小补”。例如:
- 改进提示 (Prompt Engineering): 给出更清晰的任务指令和角色定义
- 优化智能体拓扑/沟通模式: 改变智能体之间的连接方式和对话规则 (如从线性流程变为循环反馈,或加入专门的协调者)。
- 加入自我验证/重试机制: 让智能体在完成任务后自查,或在遇到不一致时尝试重新沟通 (Appendix E.5)。
- 多数投票/重采样: 多次运行或让多个智能体给出答案,选择最一致的结果。
研究者们在两个案例(AG2-MathChat 和 ChatDev, Sec 6)中尝试了这些战术方法。结果显示:这些方法确实能带来一些改进(例如,改进后的 ChatDev 在 ProgramDev 任务上的准确率从 25% 提升到 40.6%),但效果有限且不稳定。对于 AG2,改进提示在 GPT-4 上效果显著,但在 GPT-4o 上,新拓扑结构反而效果不佳。这说明这些“头痛医头,脚痛医脚”的方法,并不能根治所有问题。
2.结构性方法:
这些是更根本、更系统性的变革,旨在从基础架构层面提升 MAS 的鲁棒性和可靠性。这通常需要更深入的研究和更复杂的实现。
- 强大的验证机制: 设计通用的、跨领域的验证框架(不仅仅是代码测试,可能涉及逻辑验证、事实核查、QA 标准等)。论文特别强调了验证的重要性,认为它是抵御失败的“最后一道防线”,但构建通用验证机制极具挑战。
- 标准化沟通协议: 定义清晰的、结构化的智能体间通信语言和格式,减少歧义,实现类似计算机网络协议那样的可靠交互。
- 不确定性量化: 让智能体能够评估并表达自己对信息或结论的“置信度”,在低置信度时主动寻求更多信息或采取更保守的行动。
- 增强的记忆和状态管理: 改进智能体记录、检索和利用长期/短期记忆的方式,确保上下文连贯性。
- 基于强化学习的协作训练: 通过奖励期望的行为(如有效沟通、遵守角色、成功协作)和惩罚不良行为,来“训练”智能体学会更好地团队合作。
这些结构性方法被认为是未来解决 MAS 失败问题的关键,但它们也带来了新的研究挑战。
Reference
[1] Multi-Agent多智能体为什么会失效?R1类推理模型训练及推理的2个有趣实验结论