目录
一、矩阵定义
二、MADlib 中的矩阵表示
1. 稠密
2. 稀疏
三、MADlib 中的矩阵运算函数
1. 矩阵操作函数分类
(1)表示函数
(2)计算函数
(3)提取函数
(4)归约函数(指定维度的聚合)
(5)创建函数
(6)转换函数
2. 矩阵操作函数示例
(1)由稠密矩阵表生成稀疏表示的表
(2)矩阵转置
(3)提取矩阵的主对角线
(4)创建对角矩阵
(5)创建单位矩阵
(6)提取指定下标的行或列
(7)获取指定维度的最大最小值及其对应的下标
(8)按指定维度求和
(9)按指定维度求均值
(10)创建元素为全 0 的矩阵
(11)创建元素为全 1 的矩阵
(12)获取行列维度数
(13)矩阵相加
(14)标量与矩阵相乘
(15)矩阵乘法
(16)两矩阵元素相乘
(17)求矩阵的秩
(18)求逆矩阵
(19)求广义逆矩阵
(20)提取矩阵的特征值
(21)求矩阵范数
(22)求矩阵核范数
四、矩阵与数据分析
矩阵可以用来表示数据集,描述数据集上的变换,是 MADlib 中数据的基本格式,通常使用二维数组数据类型。MADlib 中的向量是一维数组,可看作是矩阵的一种特殊形式。MADlib 的矩阵运算模块(matrix_ops)实现 SQL 中的矩阵操作。本篇介绍矩阵的概念,说明 MADlib 矩阵运算相关函数,并举出一些简单的函数调用示例。
一、矩阵定义
矩阵(matrix)是把数集合汇聚成行和列的一种表表示。术语“m × n 矩阵”通常用来说明矩阵具有 m 行和 n 列。例如,下面所示的矩阵 A 是 2 × 3 矩阵。如果 m=n,则我们称该矩阵为方阵(square matrix)。矩阵 A 的转置记作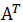 ,它通过交换 A 的行和列得到。
,它通过交换 A 的行和列得到。
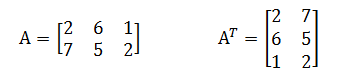
矩阵的元素用带小标的小写字母表示,例如,对于矩阵 A,![]() 是其第 i 行第 j 列的元素。行自上而下编号,列自左向右编号,编号从 1 开始,例如,
是其第 i 行第 j 列的元素。行自上而下编号,列自左向右编号,编号从 1 开始,例如,![]() = 7 是矩阵 A 的第 2 行第 1 列的元素。
= 7 是矩阵 A 的第 2 行第 1 列的元素。
矩阵的每一行或列定义一个向量。对于矩阵 A,其第 i 个行向量(row vector)可以用 ![]() 表示,而第 j 个列向量(column vector)用
表示,而第 j 个列向量(column vector)用 ![]() 表示。使用前面的例子,
表示。使用前面的例子,![]() = [7 5 2],而
= [7 5 2],而 ![]() =
= ![]() 。注意:行向量和列向量都是矩阵,必须加以区分,即元素个数相同并且值相同的行向量和列向量代表不同的矩阵。
。注意:行向量和列向量都是矩阵,必须加以区分,即元素个数相同并且值相同的行向量和列向量代表不同的矩阵。
二、MADlib 中的矩阵表示
MADlib 支持稠密和稀疏两种矩阵表示形式,所有矩阵运算都以任一种表示形式工作。
1. 稠密
矩阵被表示为一维数组的行集合,例如 3x10 的矩阵如下表:
row_id | row_vec
-------+-------------------------
1 | {9,6,5,8,5,6,6,3,10,8}
2 | {8,2,2,6,6,10,2,1,9,9}
3 | {3,9,9,9,8,6,3,9,5,6}row_id 列表示每一行的行号,是从 1 到 N 没有重复值的连续整型序列,N 为矩阵的行数。row_vec 列对应构成矩阵每行的一维数组(行向量)。
2. 稀疏
使用行列下标指示矩阵中每一个非零项,例如:
row_id | col_id | value
-------+--------+-------
1 | 1 | 9
1 | 5 | 6
1 | 6 | 6
2 | 1 | 8
3 | 1 | 3
3 | 2 | 9
4 | 7 | 0常用这种方式表示包含多个零元素的稀疏矩阵,上面的例子只用 6 行表示一个 4x7 的矩阵中的非零元素。矩阵的行列元素个数分别由 row_id 和 col_id 的最大值指定。注意最后一行,即使 value 为 0 也要包含此行,它指出了矩阵的维度,而且指示矩阵的第 4 行与第 7 列的元素值都是 0。
对于稀疏矩阵表,row_id 和 col_id 列逻辑类似于关系数据库的联合主键,要求非空且唯一。value 列应该是标量(非数组)数据类型。上面矩阵对应的稠密表示如下:
row_id | row_vec
--------+-------------------------
1 | {9,0,0,0,6,6,0}
2 | {8,0,0,0,0,0,0}
3 | {3,9,0,0,0,0,0}
4 | {0,0,0,0,0,0,0}三、MADlib 中的矩阵运算函数
与数组操作相同,矩阵运算函数支持的元素数据类型也包括 SMALLINT、INTEGER、BIGINT、FLOAT8 和 NUMERIC(内部被转化为 FLOAT8,可能丢失精度)。
1. 矩阵操作函数分类
MADlib 的矩阵操作函数可分为表示、计算、提取、归约、创建、转换六类。下面列出每一类中所包含的函数名称及其参数。
(1)表示函数
-- 转为稀疏矩阵
matrix_sparsify( matrix_in, in_args, matrix_out, out_args)
-- 转为稠密矩阵
matrix_densify( matrix_in, in_args, matrix_out, out_args)
-- 获取矩阵的维度
matrix_ndims( matrix_in, in_args )
(2)计算函数
-- 矩阵转置
matrix_trans( matrix_in, in_args, matrix_out, out_args)
-- 矩阵相加
matrix_add( matrix_a, a_args, matrix_b, b_args, matrix_out, out_args)
-- 矩阵相减
matrix_sub( matrix_a, a_args, matrix_b, b_args, matrix_out, out_args)
-- 矩阵乘法
matrix_mult( matrix_a, a_args, matrix_b, b_args, matrix_out, out_args)
-- 数组元素相乘
matrix_elem_mult( matrix_a, a_args, matrix_b, b_args, matrix_out, out_args)
-- 标量乘矩阵
matrix_scalar_mult( matrix_in, in_args, scalar, matrix_out, out_args)
-- 向量乘矩阵
matrix_vec_mult( matrix_in, in_args, vector)
(3)提取函数
-- 从行下标提取行
matrix_extract_row( matrix_in, in_args, index)
-- 从列下标提取列
matrix_extract_col( matrix_in, in_args, index)
-- 提取主对角线元素
matrix_extract_diag( matrix_in, in_args)
(4)归约函数(指定维度的聚合)
-- 获取指定维度的最大值。如果 fetch_index = True,返回对应的下标。
matrix_max( matrix_in, in_args, dim, matrix_out, fetch_index)
-- 获取指定维度的最小值。如果 fetch_index = True,返回对应的下标。
matrix_min( matrix_in, in_args, dim, matrix_out, fetch_index)
-- 获取指定维度的和
matrix_sum( matrix_in, in_args, dim)
-- 获取指定维度的均值
matrix_mean( matrix_in, in_args, dim)
-- 获取矩阵范数
matrix_norm( matrix_in, in_args, norm_type)
(5)创建函数
-- 创建一个指定行列维度的矩阵,用 1 初始化元素值。
matrix_ones( row_dim, col_dim, matrix_out, out_args)
-- 创建一个指定行列维度的矩阵,用 0 初始化元素值。
matrix_zeros( row_dim, col_dim, matrix_out, out_args)
-- 创建单位矩阵
matrix_identity( dim, matrix_out, out_args)
-- 用给定对角元素初始化矩阵
matrix_diag( diag_elements, matrix_out, out_args)
(6)转换函数
-- 矩阵求逆
matrix_inverse( matrix_in, in_args, matrix_out, out_args)
-- 广义逆矩阵
matrix_pinv( matrix_in, in_args, matrix_out, out_args)
-- 矩阵特征提取
matrix_eigen( matrix_in, in_args, matrix_out, out_args)
-- Cholesky分解
matrix_cholesky( matrix_in, in_args, matrix_out_prefix, out_args)
-- QR分解
matrix_qr( matrix_in, in_args, matrix_out_prefix, out_args)
-- LU分解
matrix_lu( matrix_in, in_args, matrix_out_prefix, out_args)
-- 求矩阵的核范数
matrix_nuclear_norm( matrix_in, in_args)
-- 求矩阵的秩
matrix_rank( matrix_in, in_args)
注意:矩阵转换函数仅基于内存操作实现。单一节点的矩阵数据被用于分解计算。这种操作只适合小型矩阵,因为计算不是分布到个多个节点执行的。
2. 矩阵操作函数示例
先执行下面的脚本创建两个稠密表示的矩阵测试表并添加数据。mat_a 矩阵 4 行 4 列,mat_b 矩阵 5 行 4 列。
drop table if exists mat_a;
create table mat_a (row_id integer, row_vecinteger[]);
insert into mat_a (row_id, row_vec)values
(1, '{9,6,5,8}'), (2, '{8,2,2,6}'), (3,'{3,9,9,9}'), (4, '{6,4,2,2}');
drop table if exists mat_b;
create table mat_b (row_id integer, vectorinteger[]);
insert into mat_b (row_id, vector)values
(1, '{9,10,2,4}'), (2, '{5,3,5,2}'), (3,'{0,1,2,3}'), (4, '{2,9,0,4}'), (5,'{3,8,7,7}');(1)由稠密矩阵表生成稀疏表示的表
drop table if exists mat_a_sparse;
select madlib.matrix_sparsify('mat_a','row=row_id, val=row_vec',
'mat_a_sparse','col=col_id, val=val');
drop table if exists mat_b_sparse;
select madlib.matrix_sparsify('mat_b','row=row_id, val=vector',
'mat_b_sparse','col=col_id, val=val'); madlib.matrix_sparsify 函数将稠密表示矩阵表转为稀疏表示的矩阵表,四个参数分别指定输入表名、输入表参数(代表行 ID 的列名、存储矩阵元素值的列名等)、输出表名、输出表参数(代表列 ID 的列名、存储矩阵元素值的列名等)。
上面的例子将稠密矩阵转为稀疏表示,并新建表存储转换结果。源表的两列类型分别是整型和整型数组,输出表包含三列,行 ID 列名与源表相同,列 ID 列和值列由参数指定。由于 mat_a 表的矩阵中不存在 0 值元素,生成的稀疏矩阵表共有 16 条记录,而 mat_b 中有两个 0 值,因此稀疏表中只有 18 条记录。
dm=# select * from mat_a_sparse order by row_id, col_id;
row_id | col_id | val
--------+--------+-----
1 | 1 | 9
1 | 2 | 6
…
4 | 3 | 2
4 | 4 | 2
(16 rows)
dm=# select * from mat_b_sparse;
row_id | col_id | val
--------+--------+-----
1 | 1 | 9
1 | 2 | 10
…
4 | 2 | 9
4 | 4 | 4
(18 rows)(2)矩阵转置
matrix_trans 函数的第一个参数是源表名,第二个参数指定行、列或值的字段名,第三个参数为输出表名。
-- 稠密格式
drop table if exists mat_a_r;
select madlib.matrix_trans('mat_a','row=row_id, val=row_vec','mat_a_r');
select * from mat_a_r order by row_id;结果:
row_id | row_vec
--------+-----------
1 | {9,8,3,6}
2 | {6,2,9,4}
3 | {5,2,9,2}
4 | {8,6,9,2}
(4 rows)-- 稀疏格式
drop table if exists mat_b_sparse_r;
select madlib.matrix_trans('mat_b_sparse', 'row=row_id, col=col_id, val=val','mat_b_sparse_r');
select * from mat_b_sparse_r order byrow_id, col_id; 结果:
col_id | row_id | val
--------+--------+-----
1 | 1 | 9
2 | 1 | 5
…
4 | 4 | 4
5 | 4 | 7
(18 rows)源矩阵 5 行 4 列,转置后的矩阵为 4 行 5 列。
(3)提取矩阵的主对角线
select madlib.matrix_extract_diag('mat_b', 'row=row_id, val=vector'),
madlib.matrix_extract_diag
('mat_b_sparse_r', 'row=row_id, col=col_id,val=val');结果:
matrix_extract_diag | matrix_extract_diag
---------------------+---------------------
{9,3,2,4} | {9,3,2,4}
(1 row)matrix_extract_diag 函数的返回值是由对角线元素组成的数组。可以看到,矩阵和其对应的转置矩阵具有相同的主对角线,也就是说,矩阵转置实际上是沿着主对角线的元素对折操作。
(4)创建对角矩阵
drop table if exists mat_r;
select madlib.matrix_diag(array[9,6,3,10], 'mat_r', 'row=row_id, col=col_id, val=val');
select * from mat_r order by row_id;结果:
row_id | col_id | val
--------+--------+-----
1 | 1 | 9
2 | 2 | 6
3 | 3 | 3
4 | 4 | 10
(4 rows)madlib.matrix_diag 函数输出的是一个稀疏表示的对角矩阵表,如果不指定“col=col_id”,输出表中代表列的列名为 col。
(5)创建单位矩阵
drop table if exists mat_r;
select madlib.matrix_identity(4, 'mat_r');
select * from mat_r; 结果:
row | col | val
-----+-----+-----
4 | 4 | 1
2 | 2 | 1
1 | 1 | 1
3 | 3 | 1
(4 rows)matrix_identity 函数创建一个稀疏表示的单位矩阵表。主对角线上的元素都为 1,其余元素全为 0 的方阵称为单位矩阵。
(6)提取指定下标的行或列
select madlib.matrix_extract_row('mat_a','row=row_id, val=row_vec', 2) as row,
madlib.matrix_extract_col
('mat_b_sparse','row=row_id, col=col_id, val=val', 3) as col;结果返回两个向量,即 mat_a 的第 2 行,mat_b_sparse 的第 3 列:
row | col
-----------+-------------
{8,2,2,6} | {2,5,2,0,7}
(1 row)(7)获取指定维度的最大最小值及其对应的下标
drop table if exists mat_max_r,mat_min_r;
select madlib.matrix_max
('mat_a','row=row_id, val=row_vec', 2, 'mat_max_r', true),
madlib.matrix_min
('mat_b_sparse','row=row_id, col=col_id', 1, 'mat_min_r', true);
select * from mat_max_r, mat_min_r;结果:
index | max | index | min
-----------+-----------+-----------+-----------
{1,1,2,1} | {9,8,9,6} | {3,3,4,2} | {0,1,0,2}
(1 row)matrix_max 和 matrix_min 函数分别返回指定维度的最大值和最小值,其中维度参数的取值只能是 1 或 2,分别代表行和列。返回值为数组类型,如果最后一个参数为‘true’,表示结果中包含最大最小值对应的下标数组列。
(8)按指定维度求和
select madlib.matrix_sum('mat_b_sparse', 'row=row_id, col=col_id,val=val', 1),
madlib.matrix_sum('mat_b_sparse', 'row=row_id, col=col_id,val=val', 2); 结果:
matrix_sum | matrix_sum
---------------+-----------------
{19,31,16,20} | {25,15,6,15,25}
(1 row)matrix_sum 函数按指定维度求和,第三个参数的值只能是 1 或 2,分别表示按行或列求和。函数返回的结果是一个向量。
(9)按指定维度求均值
select madlib.matrix_mean('mat_b_sparse', 'row=row_id, col=col_id,val=val', 1),
madlib.matrix_mean('mat_b_sparse', 'row=row_id, col=col_id,val=val', 2); 结果:
matrix_mean | matrix_mean
-----------------+---------------------------
{3.8,6.2,3.2,4} | {6.25,3.75,1.5,3.75,6.25}
(1 row)matrix_mean 函数按指定维度求均值,第三个参数的值只能是 1 或 2,分别表示行或列。函数返回的结果是一个向量。
(10)创建元素为全 0 的矩阵
drop table if exists mat_r01, mat_r02;
select madlib.matrix_zeros(3, 2, 'mat_r01','row=row_id, col=col_id, val=entry'),
madlib.matrix_zeros(3, 2, 'mat_r02', 'fmt=dense');
select * from mat_r01;
select * from mat_r02;结果分别为:
row_id | col_id | entry
--------+--------+-------
3 | 2 | 0
(1 row)
row | val
-----+-------
1 | {0,0}
3 | {0,0}
2 | {0,0}
(3 rows)注意因为元素值全为 0,稀疏表示的矩阵表只有 1 行。fmt=dense 指示结果表是稠密格式。
(11)创建元素为全 1 的矩阵
drop table if exists mat_r11, mat_r12;
select madlib.matrix_ones(3, 2, 'mat_r11','row=row_id, col=col_id, val=entry'),
madlib.matrix_ones(3, 2, 'mat_r12', 'fmt=dense');
select * from mat_r11 order by row_id;
select * from mat_r12 order by row;结果分别为:
row_id | col_id | entry
-------+--------+-------
1 | 2 | 1
1 | 1 | 1
2 | 2 | 1
2 | 1 | 1
3 | 2 | 1
3 | 1 | 1
(6 rows)
row | val
-----+-------
1 | {1,1}
2 | {1,1}
3 | {1,1}
(3 rows)注意因为元素值全为 1,稀疏表示的矩阵表有 6 行。
(12)获取行列维度数
select madlib.matrix_ndims('mat_a','row=row_id, val=row_vec'),
madlib.matrix_ndims('mat_a_sparse', 'row=row_id, col=col_id');结果:
matrix_ndims | matrix_ndims
--------------+--------------
{4,4} | {4,4}
(1 row)(13)矩阵相加
与向量一样,矩阵也可以通过将对应元素(分量)相加来求和。MADlib 的矩阵相加函数要求两个矩阵具有相同的行数和列数。更明确地说,假定 A 和 B 都是 m × n 的矩阵,A 和 B 的和是 m × n 矩阵 C,其元素由下式计算:
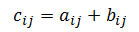
drop table if exists mat_r;
select madlib.matrix_add('mat_b','row=row_id, val=vector',
'mat_b_sparse','row=row_id, col=col_id',
'mat_r', 'val=vector,fmt=dense');
select * from mat_r order by row_id;结果:
row_id | vector
--------+--------------
1 | {18,20,4,8}
2 | {10,6,10,4}
3 | {0,2,4,6}
4 | {4,18,0,8}
5 | {6,16,14,14}
(5 rows)madlib.matrix_add 函数有三组参数,分别是两个相加的矩阵表和结果矩阵表。相加的两个矩阵表不必有相同的表示形式,如上面的函数调用中,两个矩阵一个为稠密形式,一个为稀疏形式。但两个矩阵必须具有相同的行列数,否则会报如下错误:
Matrix error: The dimensions of the two matrices don't match矩阵加法具有如下性质:
- 矩阵加法的交换律。加的次序不影响结果:A + B = B + A。
- 矩阵加法的结合律。相加时矩阵分组不影响结果:(A + B) + C = A + (B + C)。
- 矩阵加法单位元的存在性。存在一个零矩阵(zero matrix),其元素均为 0 并简记为 0,是单位元。对于任意矩阵 A,有 A + 0 = A。
- 矩阵加法逆元的存在性。对于每个矩阵 A,都存在一个矩阵 -A,使得A + (-A) = 0。-A 的元素为
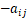 。
。
(14)标量与矩阵相乘
与向量一样,也可以用标量乘以矩阵。标量 α 和矩阵 A 的乘积是矩阵 B =αA,其元素由下式给出:
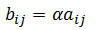
如下面 matrix_scalar_mult 函数执行结果是由原矩阵的每个元素乘以 3 构成的矩阵表。
drop table if exists mat_r;
select madlib.matrix_scalar_mult('mat_a','row=row_id, val=row_vec', 3, 'mat_r');
select * from mat_r order by row_id;结果:
row_id | row_vec
--------+---------------
1 | {27,18,15,24}
2 | {24,6,6,18}
3 | {9,27,27,27}
4 | {18,12,6,6}
(4 rows)矩阵的标量乘法具有与向量的标量乘法非常相似的性质:
- 标量乘法的结合律。被两个标量乘的次序不影响结果:α(βA) = (αβ)A。
- 标量加法对标量与矩阵乘法的分配率。两个标量相加后乘以一个矩阵等于每个标量乘以该矩阵之后的结果矩阵相加:(α+β)A =αA +βA。
- 标量乘法对矩阵加法的分配率。两个矩阵相加之后的和与一个标量相乘等于每个矩阵与该标量相乘然后相加:α(A + B)=αA + αB。
- 标量单位元的存在性。如果 α=1,则对于任意矩阵 A,有 αA =A。
我们可以认为矩阵由行向量或列向量组成,因此矩阵相加或用标量乘以矩阵等于对应行向量或列向量相加或用标量乘它们。
(15)矩阵乘法
我们可以定义矩阵的乘法运算。先定义矩阵与向量的乘法,矩阵与列向量的乘法 m × n 矩阵 A 乘以 n ×1 的列矩阵 u 的积是 m ×1 的列矩阵 v=Au,其元素由下式给出:
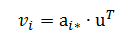
换言之,我们取 A 的每个行向量与 u 的转置的点积。注意,在下面的例子中,u 的行数必然与 A 的列数相等。
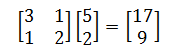
类似地,我们可以定义矩阵被行向量左乘。矩阵与行向量的乘法 1 × m 的行矩阵 u 乘以 m × n 矩阵 A 的积是1 × n 的行矩阵 v=uA,其元素由下式给出:
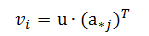
换言之,我们取该行向量与矩阵 A 的每个列向量的转置的点积。下面给出一个例子:
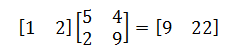
MADlib 的 matrix_vec_mult 函数用于计算一个m × n 矩阵乘以一个 1 × n 的矩阵(向量),结果是一个1 × m 的矩阵。如下面的 5 × 4 的矩阵 mat_b 乘以一个 1 × 4 的矩阵,结果一个 1 × 5 的矩阵。
dm=# select * from mat_b;
row_id | vector
--------+------------
1 | {9,10,2,4}
2 | {5,3,5,2}
3 | {0,1,2,3}
4 | {2,9,0,4}
5 | {3,8,7,7}
(5 rows)
dm=# select madlib.matrix_vec_mult('mat_b', 'row=row_id, val=vector',
dm(# array[1,2,3,4]);
matrix_vec_mult
------------------
{51,34,20,36,68}
(1 row)可以用下面的查询验证矩阵乘以向量的结果。
dm=# select array_agg(madlib.array_dot(vector,array[1,2,3,4])) from mat_b;
array_agg
------------------
{51,34,20,36,68}
(1 row)我们定义两个矩阵的乘积,作为上述概念的推广。m × n 矩阵 A 与 n × p 矩阵 B 的积是 m × p 矩阵 C=AB,其元素由下式给出:
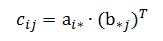
换言之,C 的第 ij 个元素是 A 的第 i 个行向量与 B 的第 j 个列向量转置的点积。
matrix_mult 函数用于矩阵相乘。如前所述,第一组参数中的矩阵列数应该与第二组参数中的矩阵行数相同,否则会报错:
dm=# select * from mat_a;
row_id | row_vec
--------+-----------
1 | {9,6,5,8}
2 | {8,2,2,6}
3 | {3,9,9,9}
4 | {6,4,2,2}
(4 rows)
dm=# select * from mat_b;
row_id | vector
--------+------------
1 | {9,10,2,4}
2 | {5,3,5,2}
3 | {0,1,2,3}
4 | {2,9,0,4}
5 | {3,8,7,7}
(5 rows)
dm=# drop table if exists mat_r;
NOTICE: table "mat_r" does not exist, skipping
DROP TABLE
dm=# select madlib.matrix_mult('mat_a', 'row=row_id, val=row_vec',
dm(# 'mat_b', 'row=row_id, val=vector',
dm(# 'mat_r');
ERROR: plpy.Error: Matrix error: Dimension mismatch for matrix multiplication. (plpython.c:4663)
DETAIL: Left matrix, col dimension = 4, Right matrix, row dimension = 5
CONTEXT: Traceback (most recent call last):
PL/Python function "matrix_mult", line 26, in <module>
matrix_out, out_args)
PL/Python function "matrix_mult", line 1633, in matrix_mult
PL/Python function "matrix_mult", line 49, in _assert
PL/Python function "matrix_mult"
dm=#可以对 mat_b 先进行转置,再与 mat_a 相乘。matrix_mult 函数调用时的 trans=true 参数表示先对 mat_b 表行列转置再进行矩阵乘法。这次的矩阵乘法计算将正常执行。
drop table if exists mat_r;
select madlib.matrix_mult('mat_a', 'row=row_id,val=row_vec',
'mat_b', 'row=row_id, val=vector, trans=true',
'mat_r');
select * from mat_r order by row_id;结果是一个 4 × 5 矩阵:
row_id | row_vec
--------+----------------------
1 | {183,104,40,104,166}
2 | {120,68,24,58,96}
3 | {171,105,54,123,207}
4 | {106,56,14,56,78}
(4 rows)执行结果与下面的查询相同。
drop table if exists mat_r;
select madlib.matrix_mult('mat_a', 'row=row_id, val=row_vec',
'mat_b_sparse_r', 'row=row_id, col=col_id, val=val',
'mat_r');
select * from mat_r order by row_id;矩阵乘法具有如下性质:
- 矩阵乘法的结合律。矩阵乘的次序不影响计算结果:(AB)C=A(BC)。
- 矩阵乘法的分配率。矩阵乘法对矩阵加法是可分配的:A(B + C) = AB + AC 并且 (B + C)A = BA + CA。
- 矩阵乘法单位元的存在性。如果
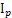 是 p × p 矩阵的单位矩阵,则对于任意 m × n 矩阵 A,A
是 p × p 矩阵的单位矩阵,则对于任意 m × n 矩阵 A,A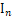 =A 并且
=A 并且 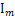 A=A。
A=A。
一般地,矩阵乘法是不可交换的,即 AB≠![]() BA。
BA。
如果我们有一个 n × 1 列向量 u,则我们可以把 m × n 矩阵 A 被该向量右乘看作 u 到 m 维列向量 v=Au 的变换。类似地,如果我们用一个(行)向量 u=[![]() ] 左乘 A,则我们可以将它看作 u 到 n 维行向量 v=uA 的变换。这样,我们可以把一个任意 m × n 矩阵 A 看作一个把一个向量映射到另一个向量空间的函数。
] 左乘 A,则我们可以将它看作 u 到 n 维行向量 v=uA 的变换。这样,我们可以把一个任意 m × n 矩阵 A 看作一个把一个向量映射到另一个向量空间的函数。
在许多情况下,可以用更容易理解的术语描述变换矩阵。
- 缩放矩阵(scaling matrix)不改变向量的方向,而是改变向量的长度。这等价于乘以一个乘了标量的单位矩阵得到的矩阵。
- 旋转矩阵(rotation matrix)改变向量的方向但不改变向量的量值。这相当于改变坐标系。
- 反射矩阵(reflection matrix)将一个向量从一个或多个坐标轴反射。这等价于用 -1 乘该向量的某些元素,而保持其他元素不变。
- 投影矩阵(projection matrix)把向量置于较低维子空间。最简单的例子是修改单位矩阵,将对角线上的一个或多个 1 改为 0。这样的矩阵消除对应于 0 元素的向量分量,而保留其他分量。
当然,单个矩阵可能同时进行两种类型的变换,如缩放和旋转。
(16)两矩阵元素相乘
与矩阵乘法定义不同,MADlib 的两矩阵元素相乘定义为 C=AB,A、B、C 均为 m × n 矩阵,C 的元素由下式给出:
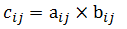
MADlib 的 matrix_elem_mult 函数执行两矩阵元素相乘,并输出结果矩阵。
drop table if exists mat_r;
select madlib.matrix_elem_mult('mat_b','row=row_id, val=vector',
'mat_b_sparse','row=row_id, col=col_id, val=val',
'mat_r','fmt=dense');
select * from mat_r order by row_id;结果:
row_id | vector
--------+---------------
1 | {81,100,4,16}
2 | {25,9,25,4}
3 | {0,1,4,9}
4 | {4,81,0,16}
5 | {9,64,49,49}
(5 rows)(17)求矩阵的秩
select madlib.matrix_rank('mat_a','row=row_id, val=row_vec');结果:
matrix_rank
------------
4
(1 row)注意,当矩阵以稀疏形式表示,并且列数大于行数时,matrix_rank 函数会报错。
dm=#select madlib.matrix_rank('mat_b_sparse_r', 'row=row_id, col=col_id, val=val');
ERROR: plpy.SPIError: Function"madlib.__matrix_compose_sparse_transition(doubleprecision[],integer,integer,integer,integer,double precision)": Invalidcol id. (UDF_impl.hpp:210) (seg20hdp4:40000 pid=123035) (plpython.c:4663)
CONTEXT: Traceback (most recent call last):
PL/Python function "matrix_rank",line 23, in <module>
returnmatrix_ops.matrix_rank(schema_madlib, matrix_in, in_args)
PL/Python function "matrix_rank",line 2702, in matrix_rank
PL/Python function "matrix_rank",line 2672, in matrix_eval_helper
PL/Pythonfunction "matrix_rank"
dm=# 矩阵的秩(rank of a matrix)常常用来刻画矩阵。设矩阵 A=![]() ,在 A 中任取 k 行 k 列交叉处元素按原相对位置组成的 k 阶行列式,称为 A 的一个 k 阶子式。m × n 矩阵 A 共有
,在 A 中任取 k 行 k 列交叉处元素按原相对位置组成的 k 阶行列式,称为 A 的一个 k 阶子式。m × n 矩阵 A 共有 ![]() 个 k 阶子式。若 A 有 r 阶子式不为 0,任何 r+1 阶子式(如果存在的话)全为 0,称 r 为矩阵 A 的秩,记作 R(A)。
个 k 阶子式。若 A 有 r 阶子式不为 0,任何 r+1 阶子式(如果存在的话)全为 0,称 r 为矩阵 A 的秩,记作 R(A)。
矩阵的秩具有以下基本性质:
- 0 矩阵的秩为 0。
- 如果 R(A)=r,则 A 中至少有一个 r 阶子式
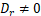 ,所有 r+1 阶子式为 0,且更高阶子式均为 0,r 是 A 中非零的子式的最高阶数。
,所有 r+1 阶子式为 0,且更高阶子式均为 0,r 是 A 中非零的子式的最高阶数。 - 矩阵转置,秩不变。
- 0≤
 R(A)≤
R(A)≤ min(m,n)。
min(m,n)。 - 如果 A 是n × n 方阵,并且 |A|≠0,则 R(A)=n;反之,如果 R(A)=n,则 |A|≠0。
矩阵的秩(rank of a matrix)是行空间和列空间的最小维度,此维度中的向量组是线性无关的。例如,如果把一个 1 × n 的行向量复制 m 次,产生一个 m × n 的矩阵,则我们只有一个秩为 1 的矩阵。
(18)求逆矩阵
drop table if exists mat_r;
select madlib.matrix_inverse('mat_a','row=row_id, val=row_vec', 'mat_r');
select row_vec from mat_r order byrow_id;结果:
row_vec
--------------------------------------------------------------
{-1.2,0.900000000000001,0.333333333333334,0.600000000000001}
{3.20000000000001,-2.4,-1,-1.1}
{-5.00000000000001,3.50000000000001,1.66666666666667,2}
{2.2,-1.4,-0.666666666666668,-1.1}
(4 rows)设 A、B 是两个矩阵,若 AB=BA=E,则称 B 是 A 的逆矩阵,而 A 则被称为可逆矩阵。其中 E 是单位矩阵。
一个实际和理论问题是矩阵是否像实数一样具有乘法逆元。首先,由于矩阵乘法的性质(即维必须匹配),如果矩阵具有逆矩阵(inverse matrix),它必须是方阵。这样,对于一个 m × m 的矩阵 A,我们会问是否可以找到一个矩阵 ![]() 使得
使得 ![]() 。答案是某些方阵有逆矩阵,而有些没有。
。答案是某些方阵有逆矩阵,而有些没有。
一个 m × m 矩阵 A 有逆矩阵,当且仅当矩阵的秩 R(A)=m,此时方阵 A 的行列式不为零,即 |A|≠0,称 A 为非奇异矩阵或满秩矩阵,否则称 A 为奇异矩阵或降秩矩阵。满秩方阵的行、列向量组都是线性无关的。从概念上讲,一个 m × m 矩阵有逆矩阵,当且仅当它把每个非零 m 维行(列)向量都映射到一个唯一的非零 m 维行(列)向量。在求解各种矩阵方程时,逆矩阵的存在性是很重要的。
下面看一个不可逆矩阵的例子。
create table t1 (a int, b int[]);
insert into t1 values
(1,'{1,2,3}'),(2,'{2,4,6}'),(3,'{3,6,9}');
select madlib.matrix_rank('t1', 'row=a,val=b');
select madlib.matrix_inverse('t1', 'row=a,val=b', 't2');
select * from t2 order by a;3 阶矩阵 t1 的秩为 1,用 matrix_inverse 求 t1 的逆矩阵,结果如下:
a | b
---+--------------------------
1 |{NaN,NaN,NaN}
2 |{-Infinity,Infinity,NaN}
3 |{Infinity,-Infinity,NaN}
(3 rows)如果求逆的矩阵不是方阵,则 matrix_inverse 函数会报如下错误:
Matrix error: Inverse operation is onlydefined for square matrices(19)求广义逆矩阵
把逆矩阵推广到不可逆方阵(奇异矩阵)或长方矩阵上,这就是所谓的广义逆矩阵。广义逆矩阵具有逆矩阵的部分性质,并且在方阵可逆时,它通常与逆矩阵一致。
drop table if exists mat_r;
select madlib.matrix_pinv('mat_a','row=row_id, val=row_vec', 'mat_r');
select row_vec from mat_r order byrow_id;结果:
row_vec
---------------------------------------------------------------------------
{-1.20000000000001,0.900000000000004,0.333333333333335,0.600000000000003}
{3.20000000000002,-2.40000000000001,-1,-1.10000000000001}
{-5.00000000000003,3.50000000000002,1.66666666666667,2.00000000000001}
{2.20000000000001,-1.40000000000001,-0.66666666666667,-1.1}
(4 rows)matrix_pinv 函数用于求矩阵的广义逆矩阵。还以上面的不可逆方阵为例,求它的广义逆矩阵。
drop table if exists t1,t2;
create table t1 (a int, b int[]);
insert into t1 values
(1,'{1,2,3}'),(2,'{2,4,6}'),(3,'{3,6,9}');
select madlib.matrix_pinv('t1', 'row=a,val=b', 't2');
select * from t2 order by a;结果:
a | b
---+-------------------------------------------------------------
1 |{0.00510204081632653,0.0102040816326531,0.0153061224489796}
2 |{0.0102040816326531,0.0204081632653061,0.0306122448979592}
3 |{0.0153061224489796,0.0306122448979592,0.0459183673469388}
(3 rows)再看一个长方矩阵的例子。
drop table if exists mat_r;
select madlib.matrix_ndims('mat_b','row=row_id, val=vector'),
madlib.matrix_pinv('mat_b', 'row=row_id, val=vector', 'mat_r');
select * from mat_r order by row_id;mat_b 是一个 5 × 4 矩阵,它的广义逆矩阵如下:
row_id | vector
--------+----------------------------------------------------------------------------------------------------
1 |{0.169405974490348,-0.000368687326811998,0.153584606426279,-0.123375654346853,-0.0920196750284563}
2 |{-0.0977762692158761,0.0690615737096675,-0.292887943436732,0.173906300749372,0.0622886509652684}
3 | {-0.145985550968097,0.18130052991488,-0.238906461684316,0.0186947883412873,0.123325910818632}
4 |{0.167425011631207,-0.222818819439771,0.534239640910248,-0.134386530622994,-0.0413193154120082}
(4 rows)设 A 为 m × n 矩阵,如果存在 n × m 阶矩阵 G,满足条件 ① AGA=A,② GAG=G,③ (AG)*=AG,④ (GA)*=GA,式中 * 表示共轭后再转置,则称 G 为 A 的广义矩阵。
(20)提取矩阵的特征值
drop table if exists mat_r;
select madlib.matrix_eigen('mat_a','row=row_id, val=row_vec', 'mat_r');
select * from mat_r order by row_id;结果:
row_id | eigen_values
--------+------------------------
1 | (22.2561699851212,0)
2 | (-0.325748023524478,0)
3 | (2.91179834025418,0)
4 | (-2.8422203018509,0)
(4 rows)特征值和特征向量,连同相关的奇异值和奇异向量概念,捕获了矩阵的结构,使得我们可以分解矩阵,并用标准形式表示它们。因此,这些概念可以用于数学方程求解、维归约和降低噪声。
n 阶方阵 A 的特征值和特征向量分别是标量值 λ 和向量 u,它们是如下方程的解:
Au=λu
换言之,特征向量(eigenvector)是被 A 乘时除量值外并不改变的向量。特征值(eigenvalue)是缩放因子。该方程也可以写成 (A-λE)u = 0,其中 E 为单位矩阵。|A-λE| 是一个 n 次多项式,它的全部根就是 n 阶方阵 A 的全部特征值。如果 n 阶矩阵 A 的全部特征值为 ![]() 、
、![]() …
…![]() ,则 |A|=
,则 |A|=![]() *
*![]() *…*
*…*![]() 。
。
(21)求矩阵范数
matrix_norm 函数用于求矩阵范数,支持的类型值有‘fro’、‘one’、‘inf’、‘max’、‘spec’,分别代表 frobenius 范数、1 范数、infinity 范数、max 范数和 spectral 范数,缺省为 frobenius 范数。
select madlib.matrix_norm('mat_b_sparse','row=row_id, col=col_id, val=val','fro');结果:
matrix_norm
---------------
23.4520787991
(1 row) F-范数的公式为:![]() 。依据公式下面查询的结果与 matrix_norm 函数的返回值相等。
。依据公式下面查询的结果与 matrix_norm 函数的返回值相等。
select sqrt(sum(power(val,2))) frommat_b_sparse;(22)求矩阵核范数
select madlib.matrix_nuclear_norm('mat_a','row=row_id, val=row_vec');结果:
matrix_nuclear_norm
---------------------
34.322635238
(1 row)矩阵的核范数是指矩阵奇异值的和,关于矩阵奇异值,在讨论 MADlib 的矩阵分解函数时再进行详细说明。
四、矩阵与数据分析
我们可以把数据集表示成数据矩阵,其中每一行存放一个数据对象,而每一列是一个属性。(同样,我们也可以用行表示属性,列表示对象。)矩阵表示为我们的数据提供了紧凑、结构良好的表示,使得我们可以很容易地通过各种矩阵运算对数据对象或属性进行操作。
线性方程组是使用数据的矩阵表示的很常见的例子。线性方程组可以写成一个矩阵方程 Ax=b,并使用矩阵运算求解。
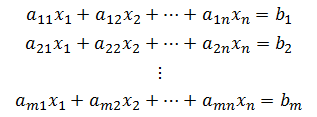
特殊地,如果 A 有逆矩阵,则该方程组的解为 ![]() 。如果 A 没有逆矩阵,则该方程组或者没有解,或者有无穷多个解。注意,在这种情况下,行(数据对象)是方程,列是变量(属性)。
。如果 A 没有逆矩阵,则该方程组或者没有解,或者有无穷多个解。注意,在这种情况下,行(数据对象)是方程,列是变量(属性)。
对于许多统计学和数据分析问题,我们希望解线性方程组,但是这些线性方程组不能使用刚才介绍的方法求解。例如,我们可能有一个数据矩阵,其中行代表病人,而列代表病人的特征(身高、体重和年龄)和他们对特定药物治疗的反应(如血压的变化)。我们想把血压(因变量)表示成其它(自)变量的线性函数,并且可以用上面的方法写一个矩阵方程。然而,如果我们的病人比变量多(通常如此),则矩阵的逆不存在。
在这种情况下,我们仍然想找出该方程的最好解。这意味着我们想找出自变量的最好线性组合来预测因变量。使用线性代数的术语,我们想找尽可能接近向量 b 的向量 Ax;换句话说,我们希望最小化向量 b-Ax 的长度 ‖b-Ax‖。这称作最小二乘(least square)问题,许多统计学技术(例如线性回归)都需要解最小二乘问题。可以证明,方程 Ax=b 的最小二乘解是 ![]() 。
。
在分析数据时,特别是对于维归约,奇异值和特征向量分解也非常有用。维归约还可以带来降低噪声的效果。