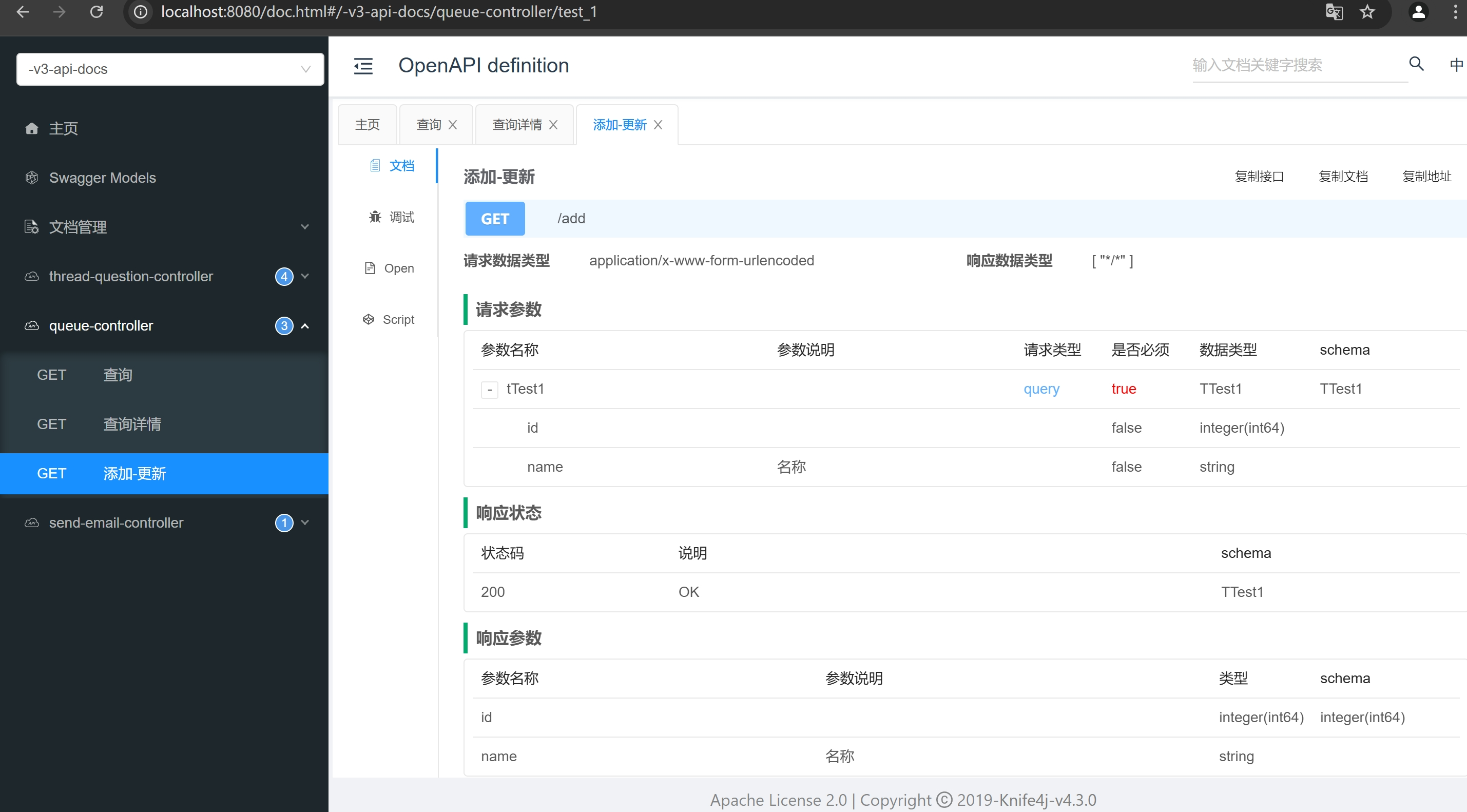
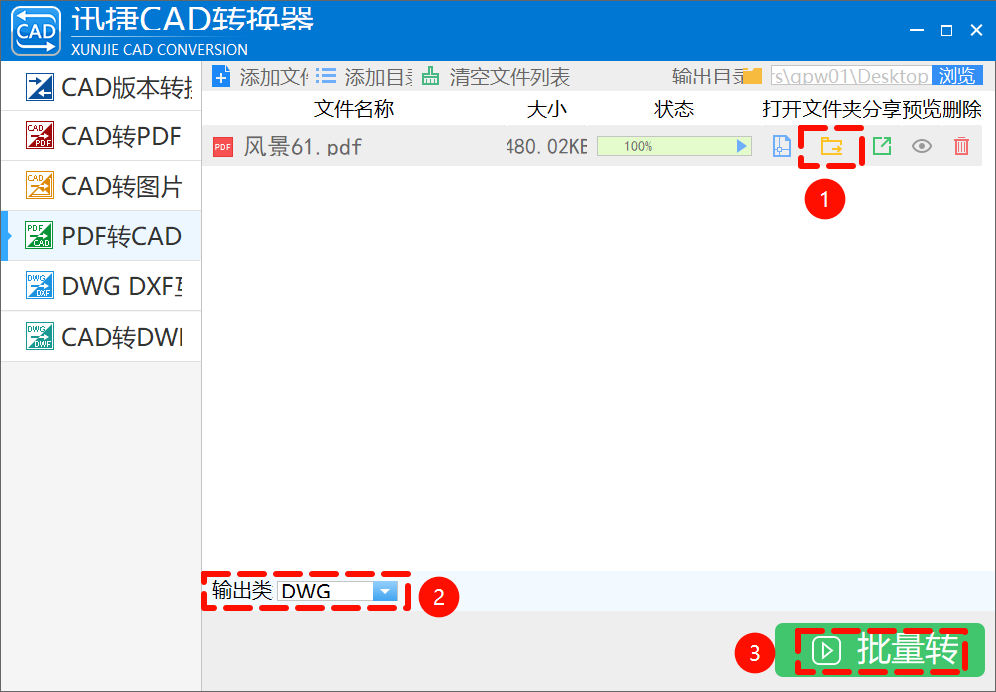
1. 请求与网络库
最基础的 HTTP 请求库,用于发送 GET/POST 请求获取网页内容。
示例:获取视频页面 HTML 或 API 响应。
import requests
response = requests.get('https://example.com/video/123')
aiohttp
异步 HTTP 请求库,适合大规模并发下载视频片段(如 m3u8 流)。
优势:大幅提升下载速度。
import aiohttp
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
data = await response.read()
selenium
自动化浏览器工具,用于处理 JavaScript 渲染的动态内容(如加密视频链接)。
需配合浏览器驱动(如 ChromeDriver)使用。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://example.com/video-player')
video_element = driver.find_element_by_tag_name('video')
2. 解析与提取库
BeautifulSoup (bs4)
HTML/XML 解析库,用于从网页中提取视频链接或元数据。
示例:提取视频播放页面中的真实 URL。
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
video_url = soup.find('video')['src']
lxml
高性能 XML/HTML 解析库,速度比bs4更快。
配合 XPath:适合复杂结构的页面解析。
from lxml import etree
tree = etree.HTML(html_content)
video_url = tree.xpath('//video/@src')[0]
jsonpath
用于解析 JSON 数据,从 API 响应中提取视频信息。
import json
from jsonpath import jsonpath
data = json.loads(api_response)
video_url = jsonpath(data, '$.video_info.url')[0]
3. 视频处理与下载库
yt-dlp
功能强大的视频下载工具(基于youtube-dl),支持 1000 + 网站。
优势:直接调用即可下载,无需编写复杂爬虫逻辑。
import yt_dlp
ydl_opts = {}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
ydl.download(['https://www.youtube.com/watch?v=dQw4w9WgXcQ'])
m3u8
解析和处理 HLS 流媒体(.m3u8 格式)的库,可用于下载分段视频。
import m3u8
r = requests.get('https://example.com/stream.m3u8')
m3u8_obj = m3u8.loads(r.text)
for segment in m3u8_obj.segments:
download_url = segment.uri
ffmpeg-python
调用 FFmpeg 工具处理视频(合并片段、转码等)。
示例:合并下载的.ts 片段为完整视频。
import ffmpeg
ffmpeg.input('input.ts').output('output.mp4').run()
4. 异步与并发库
concurrent.futures
线程池 / 进程池库,用于加速视频下载(如多线程下载多片段)。
from concurrent.futures import ThreadPoolExecutor
with ThreadPoolExecutor(max_workers=10) as executor:
futures = [executor.submit(download_segment, url) for url in segment_urls]
asyncio
原生异步框架,与aiohttp结合实现高效并发。
import asyncio
async def download_task(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
data = await response.read()
5. 数据存储与管理
SQLite3
轻量级数据库,用于存储视频元数据(标题、URL、下载状态等)。
import sqlite3
conn = sqlite3.connect('videos.db')
conn.execute('CREATE TABLE IF NOT EXISTS videos (id TEXT, title TEXT, url TEXT)')
Pandas
用于数据分析和管理下载列表,支持导出为 CSV/Excel。
import pandas as pd
df = pd.DataFrame({'title': ['video1', 'video2'], 'url': ['url1', 'url2']})
df.to_csv('videos.csv')
6. 辅助工具库
fake-useragent
生成随机 User-Agent,避免被网站反爬机制识别。
from fake_useragent import UserAgent
ua = UserAgent()
headers = {'User-Agent': ua.random}
ProxyPool
代理池工具,轮换 IP 地址防止被封禁(需自行维护代理源)。
proxies = {'http': 'http://user:pass@proxy.example.com:8080'}
response = requests.get(url, proxies=proxies)
适用场景选择
简单视频下载:直接使用yt-dlp。
复杂网站爬取:requests + BeautifulSoup + selenium。
高性能下载:aiohttp + asyncio + m3u8。
视频处理:ffmpeg-python。


![[10-2]MPU6050简介 江协科技学习笔记(22个知识点)](https://i-blog.csdnimg.cn/direct/2e01d213a0ae424ab8b6724f0586ef31.png)