引言
在人工智能快速发展的今天,如何构建一个能够进行深度研究、自主学习和迭代优化的AI系统成为了技术前沿的重要课题。Gemini开源的DeepResearch一周收获7.9k Star,Google的开源项目Gemini DeepResearch技术通过结合LangGraph框架和Gemini大语言模型,实现了一个具备自主研究能力的智能代理系统。本文将深入分析这一技术的核心原理和具体实现方式。
开源项目 Gemini Fullstack LangGraph Quickstart
技术架构概览
Gemini DeepResearch采用了基于状态图(StateGraph)的多节点协作架构,通过LangGraph框架实现了一个完整的研究工作流。整个系统包含以下核心组件:
1. 状态管理系统
系统定义了多种状态类型来管理不同阶段的数据流:
class OverallState(TypedDict):
messages: Annotated[list, add_messages]
search_query: Annotated[list, operator.add]
web_research_result: Annotated[list, operator.add]
sources_gathered: Annotated[list, operator.add]
initial_search_query_count: int
max_research_loops: int
research_loop_count: int
reasoning_model: str
这种设计允许系统在不同节点间传递和累积信息,确保研究过程的连续性和完整性。
2. 核心工作流程
整个研究流程分为五个关键阶段:
阶段一:查询生成(Query Generation)
系统首先分析用户输入,使用Gemini 2.0 Flash模型生成多个优化的搜索查询:
def generate_query(state: OverallState, config: RunnableConfig) -> QueryGenerationState:
llm = ChatGoogleGenerativeAI(
model=configurable.query_generator_model,
temperature=1.0,
max_retries=2,
api_key=os.getenv("GEMINI_API_KEY"),
)
structured_llm = llm.with_structured_output(SearchQueryList)
formatted_prompt = query_writer_instructions.format(
current_date=current_date,
research_topic=get_research_topic(state["messages"]),
number_queries=state["initial_search_query_count"],
)
result = structured_llm.invoke(formatted_prompt)
return {"query_list": result.query}
关键特点:
- 多样化查询生成:系统会生成多个不同角度的搜索查询,确保信息收集的全面性
- 结构化输出:使用Pydantic模型确保输出格式的一致性
- 时效性考虑:查询中包含当前日期信息,确保获取最新数据
阶段二:并行网络研究(Parallel Web Research)
系统使用LangGraph的Send机制实现并行搜索:
def continue_to_web_research(state: QueryGenerationState):
return [
Send("web_research", {"search_query": search_query, "id": int(idx)})
for idx, search_query in enumerate(state["query_list"])
]
每个搜索查询都会启动一个独立的web_research节点,实现真正的并行处理。
阶段三:智能网络搜索(Web Research)
这是系统的核心功能之一,集成了Google Search API和Gemini模型:
def web_research(state: WebSearchState, config: RunnableConfig) -> OverallState:
response = genai_client.models.generate_content(
model=configurable.query_generator_model,
contents=formatted_prompt,
config={
"tools": [{"google_search": {}}],
"temperature": 0,
},
)
# 处理搜索结果和引用
resolved_urls = resolve_urls(
response.candidates[0].grounding_metadata.grounding_chunks, state["id"]
)
citations = get_citations(response, resolved_urls)
modified_text = insert_citation_markers(response.text, citations)
return {
"sources_gathered": sources_gathered,
"search_query": [state["search_query"]],
"web_research_result": [modified_text],
}
技术亮点:
- 原生Google Search集成:直接使用Google的搜索API获取实时信息
- 自动引用处理:系统自动提取和格式化引用信息
- URL优化:将长URL转换为短链接以节省token消耗
阶段四:反思与知识缺口分析(Reflection)
这是DeepResearch的核心创新之一,系统会自动评估已收集信息的充分性:
def reflection(state: OverallState, config: RunnableConfig) -> ReflectionState:
formatted_prompt = reflection_instructions.format(
current_date=current_date,
research_topic=get_research_topic(state["messages"]),
summaries="\n\n---\n\n".join(state["web_research_result"]),
)
llm = ChatGoogleGenerativeAI(
model=reasoning_model,
temperature=1.0,
max_retries=2,
api_key=os.getenv("GEMINI_API_KEY"),
)
result = llm.with_structured_output(Reflection).invoke(formatted_prompt)
return {
"is_sufficient": result.is_sufficient,
"knowledge_gap": result.knowledge_gap,
"follow_up_queries": result.follow_up_queries,
"research_loop_count": state["research_loop_count"],
"number_of_ran_queries": len(state["search_query"]),
}
反思机制的核心功能:
- 知识缺口识别:自动分析当前信息是否足够回答用户问题
- 后续查询生成:针对发现的知识缺口生成新的搜索查询
- 迭代控制:决定是否需要进行下一轮研究
阶段五:答案综合(Answer Finalization)
最终阶段将所有收集的信息综合成完整的答案:
def finalize_answer(state: OverallState, config: RunnableConfig):
formatted_prompt = answer_instructions.format(
current_date=current_date,
research_topic=get_research_topic(state["messages"]),
summaries="\n---\n\n".join(state["web_research_result"]),
)
llm = ChatGoogleGenerativeAI(
model=reasoning_model,
temperature=0,
max_retries=2,
api_key=os.getenv("GEMINI_API_KEY"),
)
result = llm.invoke(formatted_prompt)
# 处理引用链接
unique_sources = []
for source in state["sources_gathered"]:
if source["short_url"] in result.content:
result.content = result.content.replace(
source["short_url"], source["value"]
)
unique_sources.append(source)
return {
"messages": [AIMessage(content=result.content)],
"sources_gathered": unique_sources,
}
技术创新点
1. 自适应研究循环
系统通过evaluate_research函数实现智能的研究循环控制:
def evaluate_research(state: ReflectionState, config: RunnableConfig) -> OverallState:
configurable = Configuration.from_runnable_config(config)
max_research_loops = (
state.get("max_research_loops")
if state.get("max_research_loops") is not None
else configurable.max_research_loops
)
if state["is_sufficient"] or state["research_loop_count"] >= max_research_loops:
return "finalize_answer"
else:
return [
Send(
"web_research",
{
"search_query": follow_up_query,
"id": state["number_of_ran_queries"] + int(idx),
},
)
for idx, follow_up_query in enumerate(state["follow_up_queries"])
]
这种设计确保了系统既能深入研究复杂问题,又能避免无限循环。
2. 智能引用管理
系统实现了完整的引用管理机制:
- URL解析:将复杂的搜索结果URL转换为简洁的引用格式
- 引用插入:自动在文本中插入引用标记
- 去重处理:确保最终答案中只包含实际使用的引用源
3. 多模型协作
系统巧妙地使用不同的Gemini模型处理不同任务:
- Gemini 2.0 Flash:用于查询生成和网络搜索,速度快
- Gemini 2.5 Flash:用于反思分析,平衡速度和质量
- Gemini 2.5 Pro:用于最终答案生成,确保高质量输出
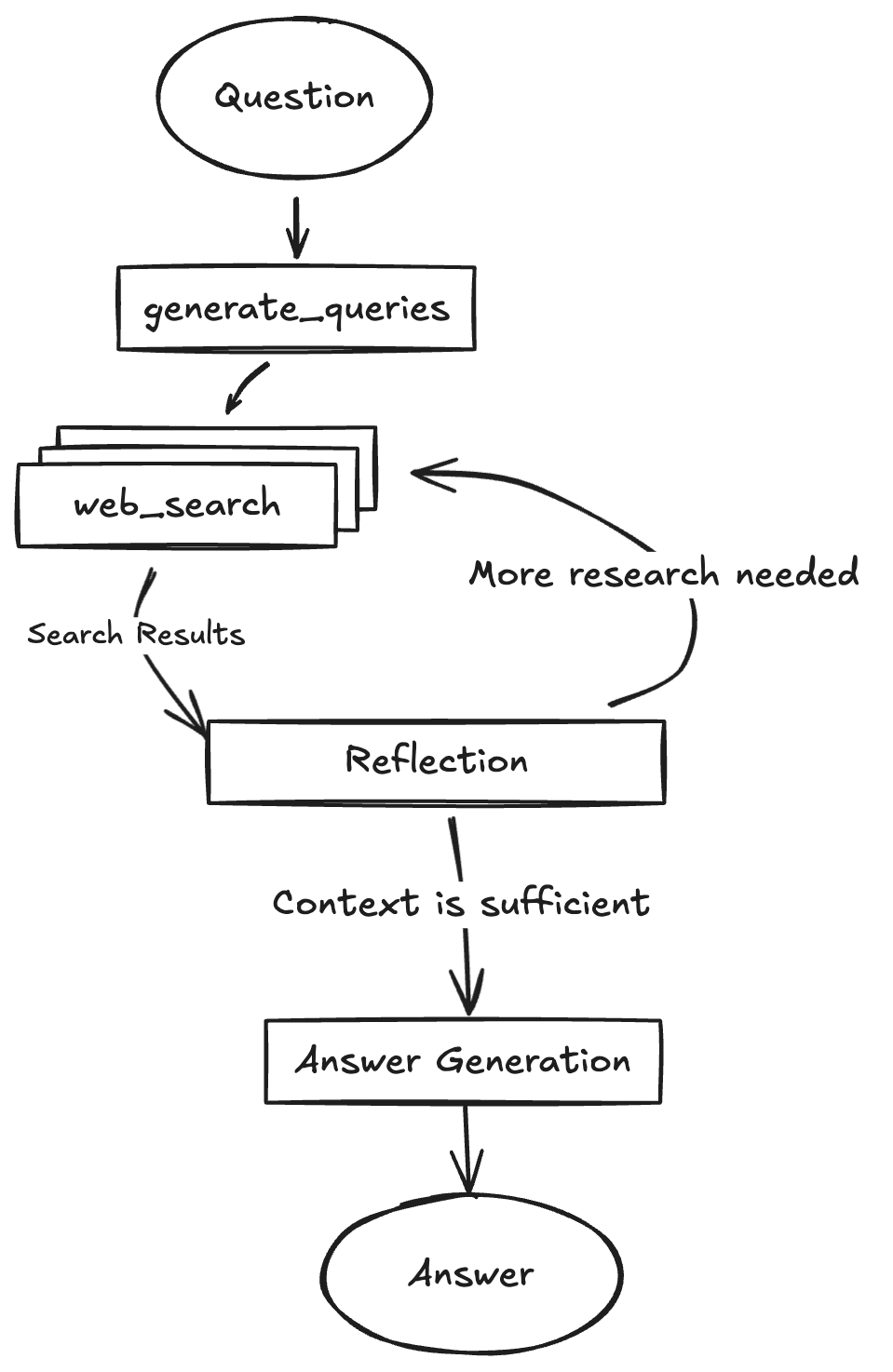
系统架构图
用户输入 → 查询生成 → 并行网络搜索 → 反思分析 → 评估决策
↓ ↓ ↓ ↓
多个搜索查询 收集网络信息 知识缺口分析 继续研究/结束
↓ ↓
生成后续查询 答案综合
↓ ↓
返回搜索 最终答案



![[yolov11改进系列]基于yolov11引入注意力机制SENetV1或者SENetV2的python源码+训练源码](https://i-blog.csdnimg.cn/direct/9bd5c0d5cf2d41218c19c204ae272763.jpeg)