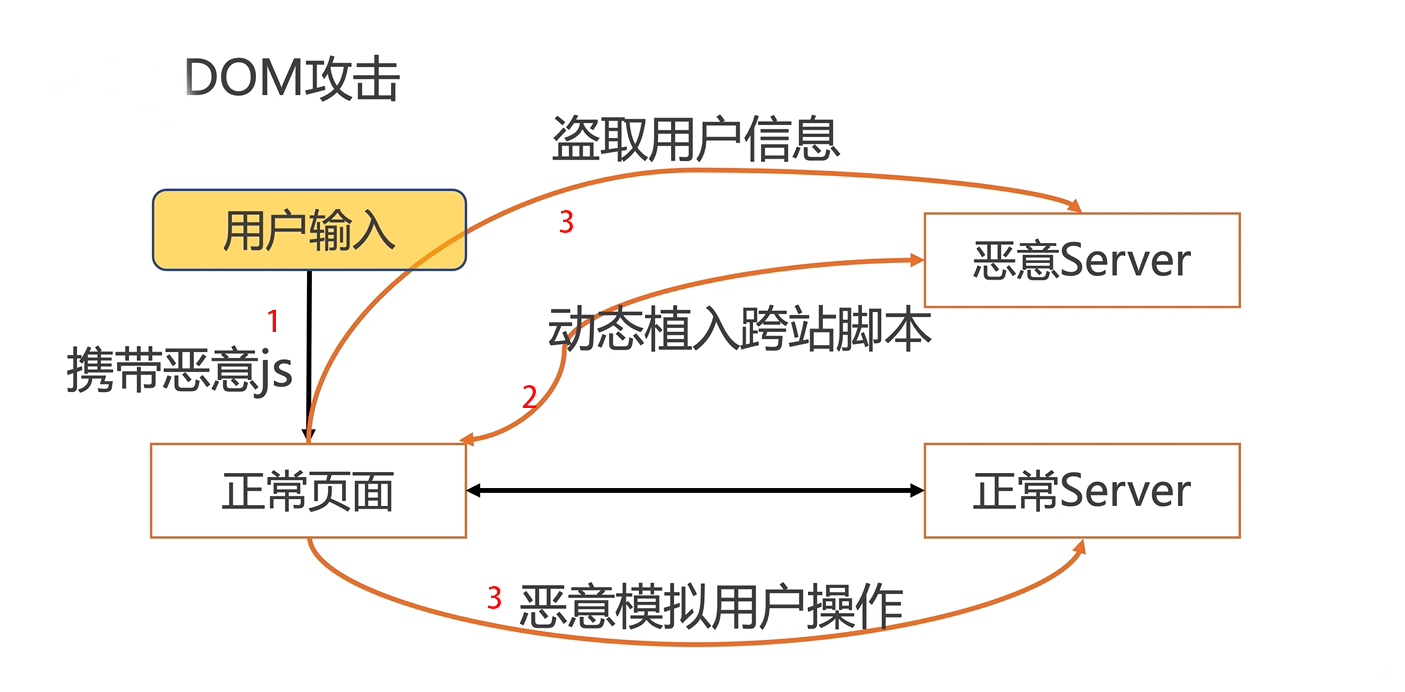
1.网络优化存在的难点
(1)结构差异大:没有通用的优化算法;超参数多
(2)非凸优化问题:参数初始化,逃离局部最优
(3)梯度消失(爆炸)
2.网络优化方法-梯度下降法
(1)批量梯度下降法(bgd)
使用所有样本进行更新参数
(2)随机梯度下降法(sgd)
使用一个样本更新参数
(3)小批量梯度下降法(mbgd)
利用部分样本更新参数

3.网络优化算法 -学习率
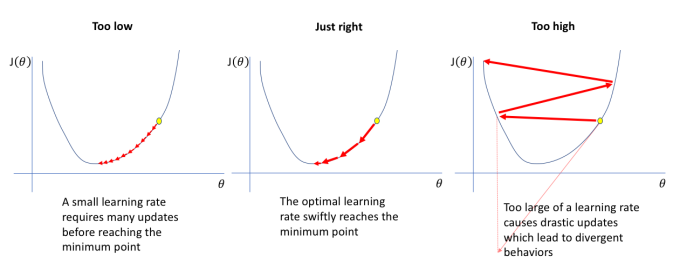
太低导致迭代慢,太高导致迭代远离局部最优
学习率的改进策略
按迭代次数进行衰减

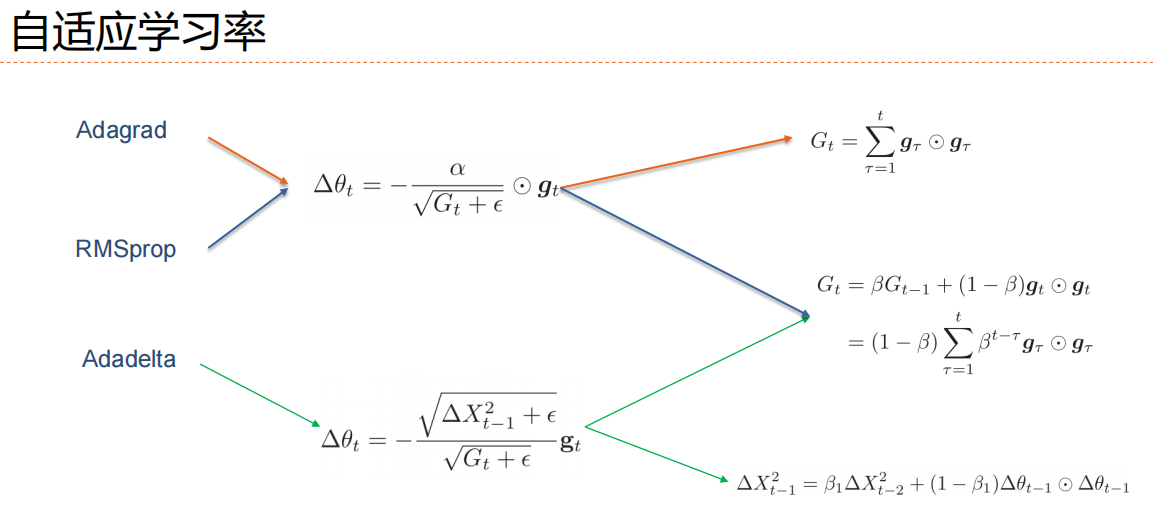
自适应,根据梯度进行自我调整
4.网络优化方法-梯度方向优化
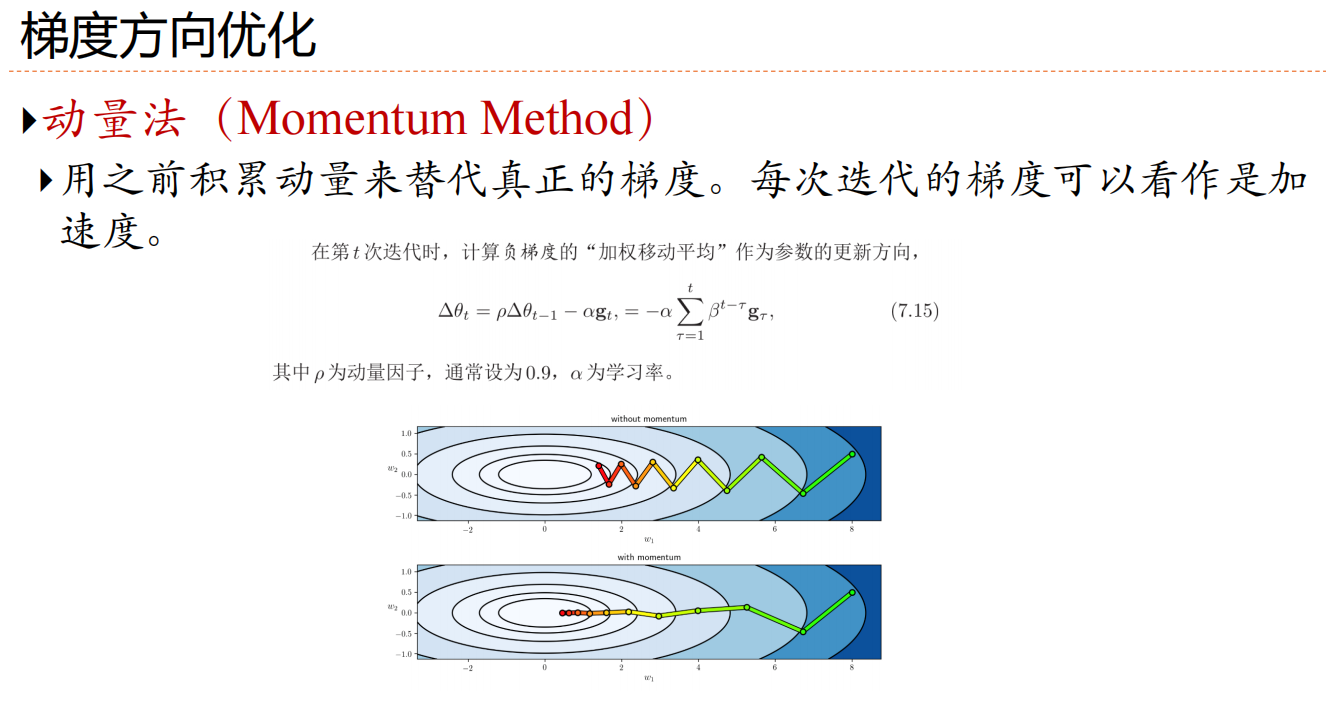
动量法
梯度截断

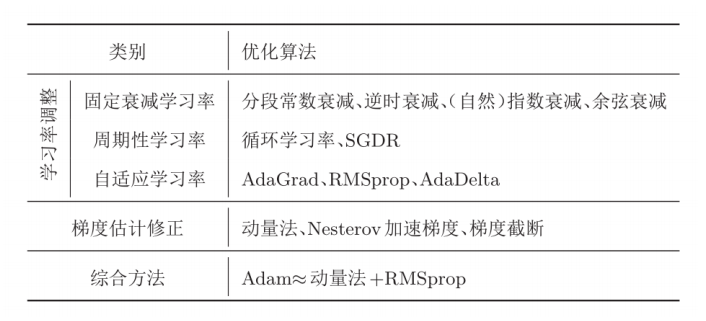
5.学习率+梯度优化Adam

6.参数初始化、数据预处理,逐层归一化
参数初始化的作用:
- 避免梯度消失 / 爆炸:合理初始化参数(如 Xavier、He 初始化)可维持网络中梯度的稳定流动,防止因参数值过大或过小导致梯度在反向传播中消失或爆炸,确保模型能有效学习。
- 加速收敛速度:合适的初始值能让模型从更优的起点开始迭代,减少训练过程中陷入局部最优的概率,使模型更快收敛到较优解。
- 保证网络对称性破缺:若参数初始化为相同值,网络各层神经元会学习到相同特征,失去对称性破缺。随机初始化可使神经元以不同起点学习,提升网络表达能力。
- 影响模型泛化能力:不当初始化可能导致模型陷入不良局部最优,而合理初始化能让模型学习到更具泛化性的特征表示,提升在未知数据上的表现。
数据预处理的作用:
- 提升模型性能:清洗噪声、处理缺失值等操作可让数据更 “干净”,使模型能更好地学习数据中的模式和特征,避免因数据质量问题导致模型训练效果不佳。
- 保证数据一致性:对数据进行标准化、归一化等处理,统一数据的尺度和分布,防止不同特征因量纲差异影响模型训练,确保模型对各特征的学习公平合理。
- 增强数据适用性:通过数据增强(如旋转、裁剪等)扩充数据集规模和多样性,减少模型过拟合风险,提升模型在不同场景下的泛化能力。
- 适配模型输入要求:将原始数据(如图像、文本等)转换为模型可接受的格式和维度,例如将图像 Resize 到固定尺寸、把文本转换为向量表示,使数据能顺利输入模型进行训练和推理。
逐层归一化的作用:
- 缓解内部协变量偏移:通过对每层输入数据归一化,稳定数据分布,减少因参数更新导致的分布变化,使模型训练更稳定。
- 加速训练收敛:归一化后的数据分布更易被模型学习,可使用更大学习率,减少梯度震荡,显著提升训练速度。
- 抑制梯度消失 / 爆炸:归一化维持了梯度传播的稳定性,避免深层网络中梯度因数据分布波动而异常,增强网络训练可行性。
- 增强模型泛化能力:归一化过程具有一定正则化效果(如 Batch Norm 的随机性),可减少过拟合,提升模型对不同输入的适应性。
- 降低参数初始化敏感性:归一化后的数据对参数初始值的要求更宽松,无需精细调参即可实现有效训练。
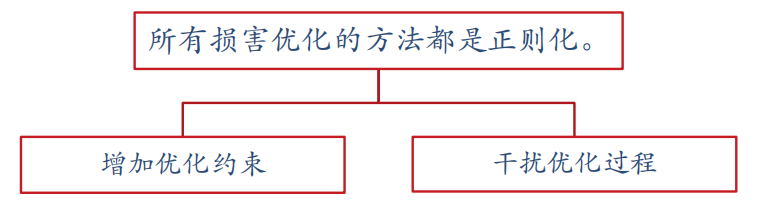
7.网络正则化的机理
1. 抑制过拟合
通过约束模型复杂度,避免模型过度拟合训练数据中的噪声或局部特征,增强对未知数据的泛化能力。
2. 参数约束与简化
- L1/L2 正则化:通过在损失函数中添加参数范数惩罚项(如 L1 的绝对值和、L2 的平方和),迫使模型参数趋近于 0(L1 更易产生稀疏解),减少无效特征的影响。
- 权重衰减:类似 L2 正则化,通过限制权重大小,降低模型对输入微小变化的敏感性。
3. 引入随机性与噪声
- Dropout:训练时随机丢弃部分神经元,迫使模型学习更鲁棒的特征组合,避免依赖特定神经元,类似 “集成学习” 效果。
- 数据增强:通过扩充训练数据(如旋转、翻转图像),增加输入多样性,使模型学习更普适的特征。
4. 约束网络表示
- Batch Normalization:归一化层输入分布,缓解内部协变量偏移,同时因噪声注入(如批量统计量的随机性)产生正则化效果。
- 早停(Early Stopping):在验证集性能未恶化时提前终止训练,避免模型过度拟合训练数据的后期迭代。
5. 集成与平滑化
- 标签平滑(Label Smoothing):将硬标签(如 one-hot)软化(如均匀分布),防止模型对某一类别过度自信,增强泛化性。
- 集成学习(如模型平均):结合多个模型的预测结果,降低单一模型的方差,提升稳定性。




![BUUCTF[极客大挑战 2019]Secret File 1题解](https://i-blog.csdnimg.cn/direct/4e960ed3ae804fbcba81a699421a7b72.png)