09.MySQL内外连接
文章目录
MySQL内外连接
内连接
外连接
左外连接
右外连接
简单案例
MySQL内外连接
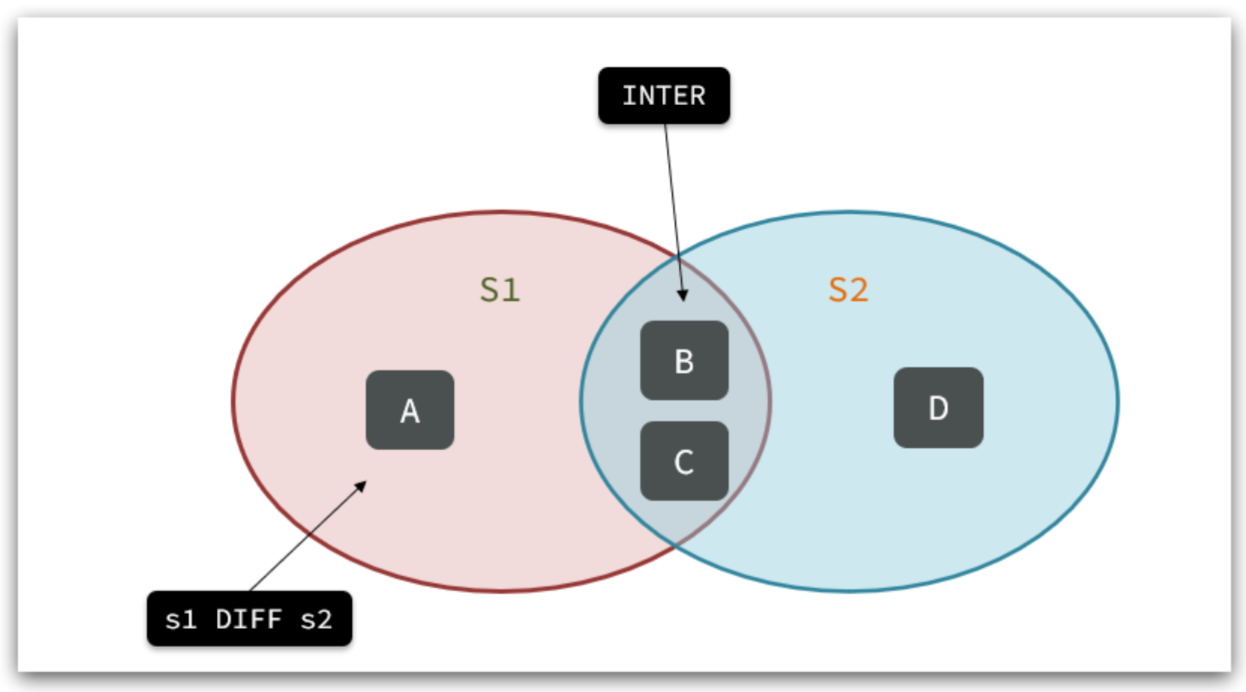
在数据库操作中,表的连接是一个非常重要的概念。简单来说,连接就是将两个或多个表中的数据按照某种规则结合起来,从而获取我们所需要的信息。而在实际开发中,最常用的两种连接方式是内连接和外连接。
那么,这两种连接到底有什么区别呢?又分别适用于哪些场景呢?
内连接
先从内连接说起。顾名思义,内连接(INNER JOIN)就是只返回两个表中满足连接条件的数据。也就是说,只有当左表和右表都存在匹配的数据时,才会出现在结果集中。
那具体怎么用呢?其实语法也不复杂:
SELECT ... FROM t1 INNER JOIN t2 ON 连接条件 [INNER JOIN t3 ON 连接条件] ... AND 其他条件;
其中,大写的 SELECT、FROM、INNER JOIN、ON 等都是 SQL 的关键字;而 [ ] 中的内容则是可选的,比如你可以根据需要添加更多的连接条件或者其他筛选条件。
举个例子吧,假设我们现在有两张表:一张员工表,记录了员工的基本信息,另一张部门表,记录了部门的编号和名称。现在我们要查询员工 “SMITH” 的名字和他的部门名称。
按照复合查询的做法,我们可能会先对两张表做笛卡尔积,然后在 WHERE 子句中指定筛选条件:员工的部门编号等于部门表的部门编号,并且员工姓名是 “SMITH”。但其实,这种写法本质上就是内连接,只不过标准的写法更直观一些:
SELECT ename, dname
FROM emp INNER JOIN dept ON emp.deptno = dept.deptno
AND ename = 'SMITH';
这样写的好处是逻辑更清晰,也更容易维护。
外连接
说完内连接,咱们再来看看外连接。外连接和内连接最大的区别在于:外连接可以返回不满足连接条件的行,而内连接不行。
外连接又分为左外连接(LEFT JOIN)和右外连接(RIGHT JOIN)。简单来说,左外连接会返回左表中的所有行,即使右表中没有匹配的数据;而右外连接则相反,会返回右表中的所有行。
左外连接
假设我们现在有一张学生表和一张成绩表。学生表记录了学生的学号和姓名,成绩表记录了学生的学号和考试成绩。现在有个需求:查询所有学生的成绩,即使这个学生没有成绩,也要显示他的个人信息。
如果直接用内连接的话,那些没有成绩的学生信息就查不出来。这时候就得用左外连接了:
SELECT student.name, score.score
FROM student LEFT JOIN score ON student.id = score.id;
这样,即使某个学生的学号在成绩表中找不到匹配记录,他的姓名依然会出现在结果中,而对应的成绩字段则会显示为 NULL。
右外连接
右外连接的使用场景和左外连接类似,只不过方向相反。比如,如果我们想查询所有的成绩记录,即使某个成绩对应的学号在学生表中不存在,也可以用右外连接:
SELECT student.name, score.score
FROM student RIGHT JOIN score ON student.id = score.id;
这时候,成绩表中的所有记录都会被保留,而学生表中没有匹配的字段会显示为 NULL。
简单案例
为了更好地理解这些连接方式的区别,咱们再来看一个实际案例。
需求:列出所有部门的名称,以及这些部门的员工信息(包括没有员工的部门)。
这里的关键是:即使某个部门没有员工,也要显示出来。这时候,内连接显然不够用了,因为内连接只会显示满足连接条件的记录。所以,我们需要用外连接。
假设部门表在左边,员工表在右边,我们可以这样写:
SELECT dept.dname, emp.ename
FROM dept LEFT JOIN emp ON dept.deptno = emp.deptno;
这样,所有部门名称都会被列出,而没有员工的部门对应的 ename 字段会是 NULL。
当然,如果你想用右外连接实现同样的效果,也可以把部门表放在右边:
SELECT dept.dname, emp.ename
FROM emp RIGHT JOIN dept ON dept.deptno = emp.deptno;
结果是一样的,只是写法不同罢了。
内连接
内连接的核心思想是“只保留有交集的数据”。换句话说,如果一张表的某条记录在另一张表中找不到匹配项,这条记录就不会出现在最终结果里。
举个生活中的例子:假设你有一个朋友列表,还有一个聚会的签到表。如果你想查哪些朋友参加了聚会,就可以用内连接,把朋友列表和签到表按名字关联起来。这样,结果里只会包含既在朋友列表里、又在签到表里的名字。
再回到数据库层面。内连接的语法结构其实挺固定的,核心就是 INNER JOIN ... ON ...。比如,如果我们想查询每个员工的姓名和他们所在部门的名称,就可以这样写:
SELECT emp.ename, dept.dname
FROM emp INNER JOIN dept ON emp.deptno = dept.deptno;
这里的关键是 ON emp.deptno = dept.deptno,它指定了两张表的关联条件。只有当员工的部门编号和部门表的部门编号一致时,这两条记录才会被合并成一条结果。
不过,有时候我们还需要加一些额外的筛选条件。比如,只想查某个特定部门的员工信息,这时候就可以在 AND 后面加条件:
SELECT emp.ename, dept.dname
FROM emp INNER JOIN dept ON emp.deptno = dept.deptno
AND dept.dname = 'SALES';
这样,结果就只会包含销售部的员工了。
内连接的本质
从底层原理来看,内连接其实就是对两个表进行笛卡尔积之后,再通过连接条件过滤出有效的组合。比如,如果员工表有 10 条记录,部门表有 5 条记录,它们的笛卡尔积就是 50 条记录。然后,数据库会根据 emp.deptno = dept.deptno 这个条件筛选出符合条件的数据。
不过,虽然内连接的逻辑简单,但在实际开发中一定要注意连接条件的准确性。如果连接条件写错了,比如把 emp.deptno = dept.deptno 错写成 emp.deptno = dept.loc,那结果就会完全错误,甚至可能导致性能问题。
内连接的优化
在大数据量场景下,内连接的性能优化也很重要。比如:
- 尽量在连接条件上使用索引:如果
emp.deptno或dept.deptno上有索引,数据库的查询效率会高很多。 - 避免不必要的字段参与连接:比如,如果只需要查询员工姓名和部门名称,就不要把整个员工表和部门表的所有字段都选出来。
- 合理使用子查询:有时候,先通过子查询过滤数据,再做内连接,效果会更好。
举个例子,假设我们想查薪资高于平均值的员工信息,可以这样写:
SELECT emp.ename, emp.sal
FROM emp INNER JOIN (
SELECT AVG(sal) AS avg_sal FROM emp
) AS avg_table ON emp.sal > avg_table.avg_sal;
这样,先算出平均薪资,再和员工表做连接,效率会比直接写 WHERE emp.sal > (SELECT AVG(sal) FROM emp) 更高。
外连接
外连接的核心思想是“保留一张表的所有数据,即使另一张表没有匹配项”。这在统计报表、数据分析等场景下特别有用。
左外连接
左外连接(LEFT JOIN)的规则是:保留左表的所有记录,右表中没有匹配的部分用 NULL 补齐。
比如,我们之前提到的学生表和成绩表的例子。学生表记录了所有学生的信息,成绩表记录了考试成绩。如果想查所有学生的成绩,即使有人没参加考试,也要显示他们的名字,这时候左外连接就是最佳选择。
具体 SQL 如下:
SELECT student.name, score.score
FROM student LEFT JOIN score ON student.id = score.id;
执行这条语句后,结果中会包含所有学生的名字,有成绩的显示具体分数,没成绩的则显示 NULL。
左外连接的陷阱
虽然左外连接很实用,但新手常犯的一个错误是:在 ON 条件之外加 WHERE 条件时,不小心过滤掉了 NULL 值。
比如,假设我们想查所有学生的成绩,并且只显示成绩大于 60 分的学生。如果这样写:
SELECT student.name, score.score
FROM student LEFT JOIN score ON student.id = score.id
WHERE score.score > 60;
结果就会变成:只有成绩大于 60 的学生会被显示,而那些没有成绩的学生(score 是 NULL)会被过滤掉。这时候,左外连接的效果就失效了。
正确的做法应该是:把筛选条件放在 ON 子句里,或者在 WHERE 中允许 NULL 值存在:
SELECT student.name, score.score
FROM student LEFT JOIN score ON student.id = score.id
AND score.score > 60;
这样,即使成绩小于 60,学生的名字也会被保留下来,只是对应的 score 字段是 NULL。
右外连接
右外连接(RIGHT JOIN)和左外连接的逻辑是一样的,只不过方向相反。它会保留右表的所有记录,左表中没有匹配的部分用 NULL 补齐。
比如,如果我们想查所有的成绩记录,即使某个成绩对应的学号在学生表里找不到,也可以用右外连接:
SELECT student.name, score.score
FROM student RIGHT JOIN score ON student.id = score.id;
这时候,成绩表中的所有记录都会被保留,而学生表中找不到匹配项的部分会用 NULL 补齐。
不过,在实际开发中,右外连接的使用频率比左外连接低得多。因为大多数时候,我们更关注主表(比如学生表)的数据完整性,而成绩表通常是附属表。所以,左外连接已经能满足大部分需求了。
全外连接
MySQL 本身不支持全外连接(FULL OUTER JOIN),但可以通过左外连接和右外连接的联合查询来实现。
比如,如果我们想同时保留学生表和成绩表的所有记录,可以这样写:
SELECT student.name, score.score
FROM student LEFT JOIN score ON student.id = score.id
UNION
SELECT student.name, score.score
FROM student RIGHT JOIN score ON student.id = score.id;
这样,结果中会包含学生表和成绩表中所有记录的并集,没有匹配的地方用 NULL 补齐。
简单案例
为了让大家更直观地理解连接的用法,咱们再来看几个实际案例。
案例 1:列出所有部门及其员工信息
需求:显示每个部门的名称,以及该部门的所有员工姓名,包括没有员工的部门。
这时候,显然要用外连接。因为内连接会过滤掉没有员工的部门,而外连接可以保留这些部门信息。
SQL 写法如下:
SELECT dept.dname, emp.ename
FROM dept LEFT JOIN emp ON dept.deptno = emp.deptno;
执行结果中,每个部门都会被列出来,有员工的显示员工姓名,没有员工的 ename 字段是 NULL。
案例 2:查找没有订单的客户
假设我们有客户表 customers 和订单表 orders,现在想查哪些客户还没有下过订单。
这时候可以用左外连接:
SELECT customers.name
FROM customers LEFT JOIN orders ON customers.id = orders.customer_id
WHERE orders.order_id IS NULL;
这里的关键是 WHERE orders.order_id IS NULL,它表示在订单表中找不到匹配记录的客户。
案例 3:合并多个表的数据
有时候,我们需要同时连接多个表。比如,查询每个员工的姓名、部门名称以及薪资等级。
假设薪资等级存储在另一张表 salgrade 中,那么 SQL 可以这样写:
SELECT emp.ename, dept.dname, salgrade.grade
FROM emp
INNER JOIN dept ON emp.deptno = dept.deptno
INNER JOIN salgrade ON emp.sal BETWEEN salgrade.losal AND salgrade.hisal;
这样,就能把三张表的数据关联起来,获取更丰富的信息。