爬虫接口类型判断与表单需求识别全解析
在爬虫开发中,准确判断目标接口的类型以及是否需要表单提交,是实现高效、稳定爬取的关键一步。本文将通过实际案例,详细介绍如何通过浏览器开发者工具和代码验证来判断接口类型及表单需求。
一、接口类型判断方法
1. GET与POST接口区分
GET接口特征:
- 参数直接附加在URL中(如
https://api.example.com/users?page=1&size=10) - 请求通常用于获取数据,无敏感信息传递
- 浏览器可直接访问URL触发请求
POST接口特征:
- 参数包含在请求体中,不直接显示在URL
- 常用于提交数据(如登录、表单提交)
- 请求体格式多样(表单、JSON、XML等)
判断方法:
使用浏览器开发者工具(如Chrome的DevTools),在Network面板中观察请求的Method和Params/Payload:
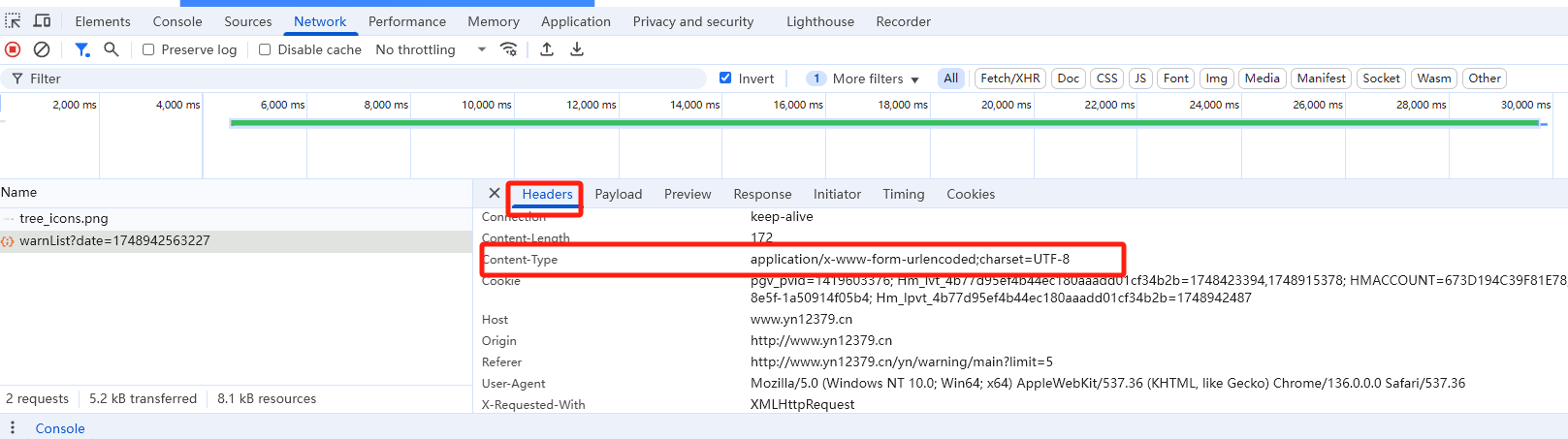
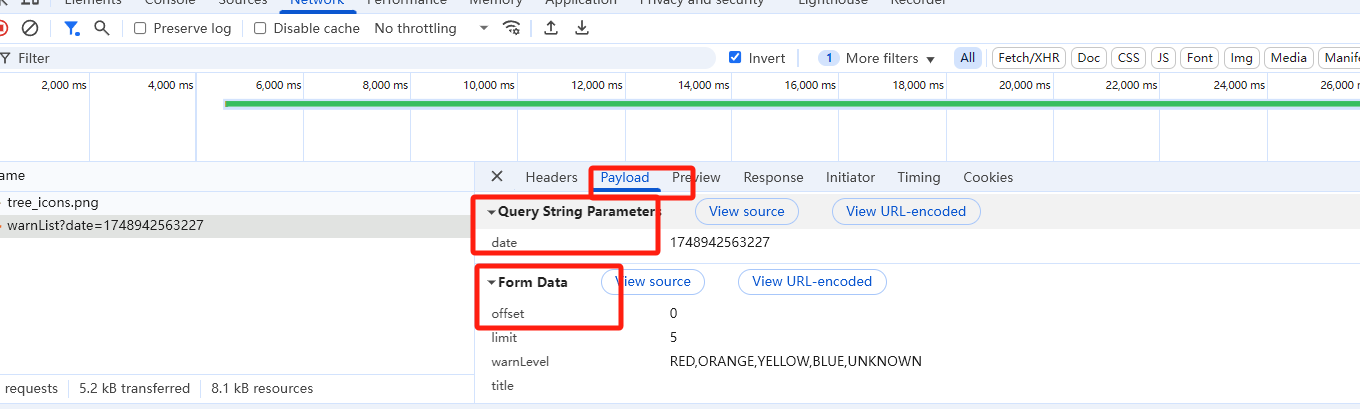 、
、
2. 返回数据格式识别
常见格式及判断方法:
- JSON:响应头
Content-Type为application/json,内容为键值对结构 - HTML:返回完整HTML页面,包含
<html>、<body>标签 - XML:响应头为
application/xml,内容为标签嵌套结构 - 二进制数据:如图片、文件,响应头包含
Content-Type: image/jpeg等
验证示例:
import requests
url = "https://api.example.com/data"
response = requests.get(url)
# 判断响应格式
if response.headers.get('Content-Type') == 'application/json':
data = response.json() # 处理JSON数据
print(f"JSON数据: {data.keys()}")
elif 'text/html' in response.headers.get('Content-Type'):
print(f"HTML页面: {response.text[:100]}") # 打印前100个字符
else:
print(f"其他格式: {response.headers.get('Content-Type')}")
二、判断接口是否需要表单
1. 浏览器开发者工具分析
关键步骤:
- 在Network面板中找到目标请求
- 查看
Request Headers中的Content-Type字段:application/x-www-form-urlencoded:普通表单数据multipart/form-data:含文件上传的表单application/json:JSON格式数据(非传统表单)
- 检查
Request Payload或Form Data是否包含参数
2. 代码验证方法
测试流程:
- 尝试直接GET请求接口
- 构造可能的表单数据进行POST请求
- 比较两种请求的响应结果
示例代码:
import requests
url = "https://api.example.com/login"
# 1. 尝试GET请求
response_get = requests.get(url)
print(f"GET请求状态码: {response_get.status_code}")
print(f"GET响应内容: {response_get.text[:100]}")
# 2. 构造表单数据尝试POST请求
form_data = {
"username": "test_user",
"password": "test_password"
}
response_post = requests.post(url, data=form_data)
print(f"POST请求状态码: {response_post.status_code}")
print(f"POST响应内容: {response_post.text[:100]}")
# 3. 判断是否需要表单
if response_post.status_code == 200 and "登录成功" in response_post.text:
print("结论: 该接口需要表单提交")
else:
print("结论: 该接口可能不需要表单,或需要其他参数")
三、动态参数识别与处理
许多接口需要动态参数(如CSRF Token、时间戳)才能正常工作。识别方法如下:
1. CSRF Token识别
特征:
- 参数名通常包含
csrf、token、session等关键词 - 值为随机字符串,每次页面加载时动态生成
- 可能存储在Cookie、HTML隐藏字段或JavaScript变量中
提取方法:
import requests
from bs4 import BeautifulSoup
# 1. 先访问页面获取CSRF Token
session = requests.Session()
response = session.get("https://example.com/login_page")
# 从HTML中提取Token
soup = BeautifulSoup(response.text, 'html.parser')
csrf_token = soup.find('input', {'name': 'csrf_token'})['value']
# 2. 使用Token进行登录请求
login_data = {
"username": "user",
"password": "pass",
"csrf_token": csrf_token
}
response = session.post("https://example.com/login", data=login_data)
2. 时间戳参数处理
特征:
- 参数名可能是
t、timestamp、time等 - 值为当前时间的毫秒数或秒数
- 用于防止请求缓存或验证请求时效性
生成方法:
import time
# 生成毫秒级时间戳
timestamp = int(time.time() * 1000)
# 添加到请求参数中
params = {
"page": 1,
"timestamp": timestamp
}
response = requests.get(url, params=params)
四、实战案例:判断某API是否需要表单
目标:判断天气预警API(示例URL:https://api.weather.com/warn/list)是否需要表单
步骤:
-
浏览器抓包分析
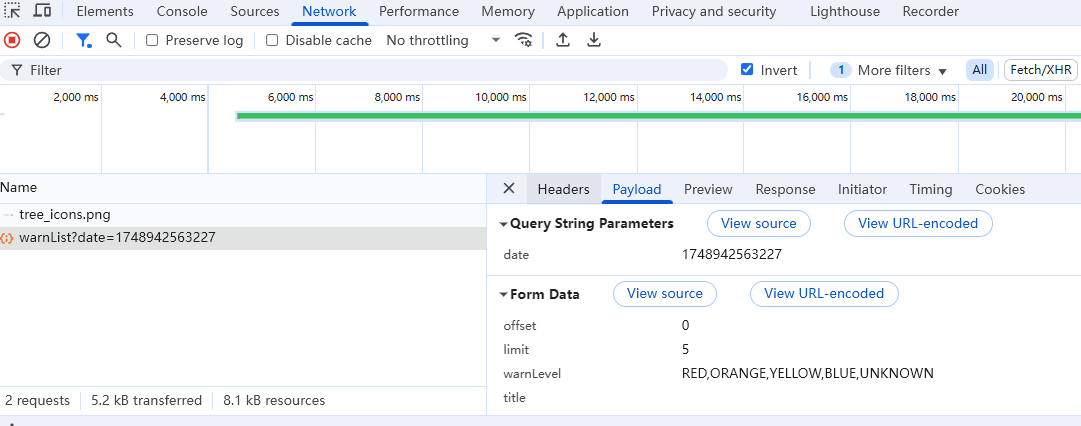
图3:天气API请求的开发者工具分析
- 请求方法:POST
- Content-Type:application/x-www-form-urlencoded
- 请求体参数:
offset、limit、areaCode等
-
代码验证
import requests
url = "https://api.weather.com/warn/list"
# 构造表单数据
form_data = {
"offset": 0,
"limit": 10,
"areaCode": "110000", # 北京地区代码
"warnLevel": "RED",
"timeRange": "2025-06-01~2025-06-04"
}
# 发送POST请求
response = requests.post(url, data=form_data)
# 处理响应
if response.status_code == 200:
data = response.json()
print(f"获取到{len(data['list'])}条预警信息")
else:
print(f"请求失败,状态码: {response.status_code}")
print(f"错误信息: {response.text}")
五、总结与避坑指南
-
判断接口类型的核心逻辑:
- 看请求方法(GET/POST)
- 分析参数位置(URL/请求体)
- 检查响应格式(JSON/HTML/XML)
-
表单识别注意事项:
- 注意动态参数(CSRF、时间戳)的提取
- 处理特殊编码(如URL编码、Base64)
- 考虑请求头(Headers)的影响(如User-Agent、Referer)
-
合规提醒:
- 爬取前查看网站
robots.txt规则 - 控制请求频率,避免对目标服务器造成压力
- 商业用途需获取网站方授权
- 爬取前查看网站
通过以上方法,你可以准确判断爬虫接口的类型及表单需求,为后续的爬取工作打下坚实基础。实践中多观察、多尝试,逐步积累经验,就能轻松应对各类复杂接口!
(注:本文示例仅用于技术学习,请勿用于非法爬取行为)