Nosql:Not-Only SQL(泛指非关系型数据库),作为关系型数据库的补充
作用:应对基于海量用户和海量数据前提下的数据处理问题
redis:C语言开发的一个开源的高性能键值对数据库
特征:
1、数据之间没有必然的关联关系
2、内部采用单线程机制工作
3、高性能
4、多数据类型支持(string、list、hash、set、sorted_set)
5、支持持久化(可以进行数据灾难恢复)
redis应用:
1、为热点数据加速查询(热点商品、热点新闻等)
2、任务队列(秒杀、抢购、购票排队等)
3、即时信息查询(各类排行榜、网站访问统计等)
4、时效性信息控制(验证码控制)
5、分布式数据共享(分布式集群架构中的session共享)
6、消息队列
7、分布式锁
数据类型相关命令:
string:字符串
| 命令 | 说明 |
|---|---|
| set [key] [value] | 添加、修改数据 |
| get [key] | 获取数据 |
| del [key] | 删除数据 |
| mset [key1] [value1] [key2] [value2] ... | 添加、修改多个数据 |
| mget [key1] [key2] ... | 获取多个数据 |
| strlen [key] | 获取数据字符个数(字符串长度) |
| append [key] [value] | 追加信息到原信息尾部(如果原来信息存在就追加,否则新建) |
| incr [key] | 数据自增1 |
| incrby [key] [increment] | 数据增加指定整数范围 |
| incrbyfloat [key] [increment] | 数据增加指定小数范围 |
| decr [key] | 数据自减1 |
| decrby [key] [increment] | 数据减去自定范围整数 |
| setex [key] [seconds] [value] | 设置数据具有制定的生命周期(秒) |
| psetex [key] [milliseconds] [value] | 设置数据具有制定的生命周期(毫秒) |
hash:哈希表结构
| 命令 | 说明 |
|---|---|
| hset [key] [field] [vaule] | 添加、修改数据 |
| hget [key] [field] | 获取数据 |
| hgetall [key] | 获取全部数据 |
| hdel [key] [field1] [field2] ... | 删除数据 |
| hlen [key] | 获取哈希表中字段的数量 |
| hexists [key] [field] | 哈希表中是否存在该字段(返回存在的个数) |
| hkeys [key] | 获取哈希表中所有字段名 |
| hvals [key] | 获取哈希表中所有字段值 |
| hincrby [key] [field] [increment] | 设置指定字段的数值数据增加指定范围的值(整数) |
| hincrbyfloat [key] [field] [increment] | 设置指定字段的数值数据增加指定范围的值(小数) |
| hsetnx [key] [field] [value] | 存在字段不更新,不存在新增 |
list:有序的双向链表
| 命令 | 说明 |
|---|---|
| lpush [key] [value1] [value2] ... | 添加、修改数据(左) |
| rpush [key] [value1] [value2] ... | 添加、修改数据(右) |
| lrange [key] [start] [stop] | 从左边获取数据,start(从0)开始,stop(-1代表倒1位置)结束 |
| lindex [key] [index] | 从左边读取index位置的数据,index从0开始 |
| llen [key] | 获取数据个数 |
| lpop [key] | 从左边获取一个数据并移除 |
| rpop [key] | 从右边获取一个数据并移除 |
| blpop [key1] [key2] ... [timeout] | 规定时间内从左边获取并移除数据,timeout秒级 |
| brpop [key1] [key2] ... [timeout] | 规定时间内从右边获取并移除数据,timeout秒级 |
| lrem [key] [count] [value] | 从左移除指定数据,count移除个数,value移除的数据 |
set:数据不重复
| 命令 | 说明 |
|---|---|
| sadd [key] [member1] [member2] ... | 添加数据 |
| smembers [key] | 获取全部数据 |
| srem [key] [member1] [member2] ... | 删除数据 |
| scard [key] | 获取集合数据总量 |
| sismember [key] [member] | 判断集合中是否包含指定数据,返回个数 |
| srandmember [key] [count] | 随机从集合中抽取count个数据,原集合不变 |
| spop [key] | 随机获取集合中的某个数据,并移出集合 |
| sinter [key1] [key2] | 求两个集合的交集 |
| sunion [key1] [key2] | 求两个集合的并集 |
| sdiff [key1] [key2] | 求两个集合的差集,有顺序的,key1 - key2的差集 |
| sinterstore [key3] [key1] [key2] | 求(key1,key2)两个集合的交集,并存储到key3中 |
| sunionstore [key3] [key1] [key2] | 求(key1,key2)两个集合的并集,并存储到key3中 |
| sdiffstore [key3] [key1] [key2] | 求(key1,key2)两个集合的差集,并存储到key3中 |
| smove [source] [destination] [member] | 把数据member从集合source移动到集合destination中 |
sorted_set:有序的set集合
| 命令 | 说明 |
|---|---|
| zadd [key] [score1] [member1] [score1] [member1] ... | 添加(多个)数据,按照score排序 |
| zrange [key] [start] [stop] [withscores] | 获取数据(升序),withscores会展示score值,start、stop为索引 |
| zrevrange [key] [start] [stop] [withscores] | 获取数据(降序) |
| zrem [key] [member1] [member2] ... | 删除(多个)数据 |
| zrangebyscore [key] [min] [max] [withscores] [limit] | 按条件升序获取,min < score值 < max,limit限制条数 |
| zrevrangebyscore [key] [max] [min] [withscores] [limit] | 按条件降序获取 |
| zremrangebyrank [key] [start] [stop] | 根据索引范围删除 |
| zremrangebyscore [key] [min] [max] | 根据score值范围删除 |
| zcard [key] | 获取集合数据总量 |
| zcount [key] [min] [max] | 获取指定的score值范围中的数据条数 |
| zinterstore [destination] [keynumber] [key1] [key2] ... | 集合交集,keynumber为要操作的集合个数 |
| zunionstore [destination] [keynumber] [key1] [key2] ... | 集合并集,keynumber为要操作的集合个数 |
| zrank [key] [member] | 获取指定数据的索引(升序) |
| zrevrank [key] [member] | 获取指定数据的索引(降序) |
| zscore [key] [member] | 获取指定数据的score值 |
| zincrby [key] [increment] [member] | 给指定的member数据的score值增加increment |
key通用操作:
| 命令 | 说明 |
|---|---|
| del [key] | 删除指定key |
| exists [key] | 获取key是否存在 |
| type [key] | 获取key的类型 |
| expire [key] [second] | 为指定key设置有效期,秒级 |
| pexpire [key] [milliseconds] | 为指定key设置有效期,毫秒级 |
| ttl [key] | 获取key的有效时间(秒),返回-2说明key不存在,返回-1说明key存在 |
| pttl [key] | 获取key的有效时间(毫秒) |
| persist [key] | 切换key从时效性转换为永久性 |
| rename [key] [newkey] | 为key改名,newkey如果已存在会覆盖原先的值 |
| renamenx | 为key改名,newkey如果已存在不会改名 |
| sort | 排序 |
key查询模式规则:
keys pattern

db基本操作:
| 命令 | 说明 |
|---|---|
| select [index] | 切换数据库(0-16) |
| ping | 返回pong说明数据库是连通的 |
| quit | 退出 |
| move [key] [dbindex] | 数据移动 |
| dbsize | 当前库中key的总量 |
| flushdb | 清除当前库的数据 |
| flushall | 清除所有库的数据 |
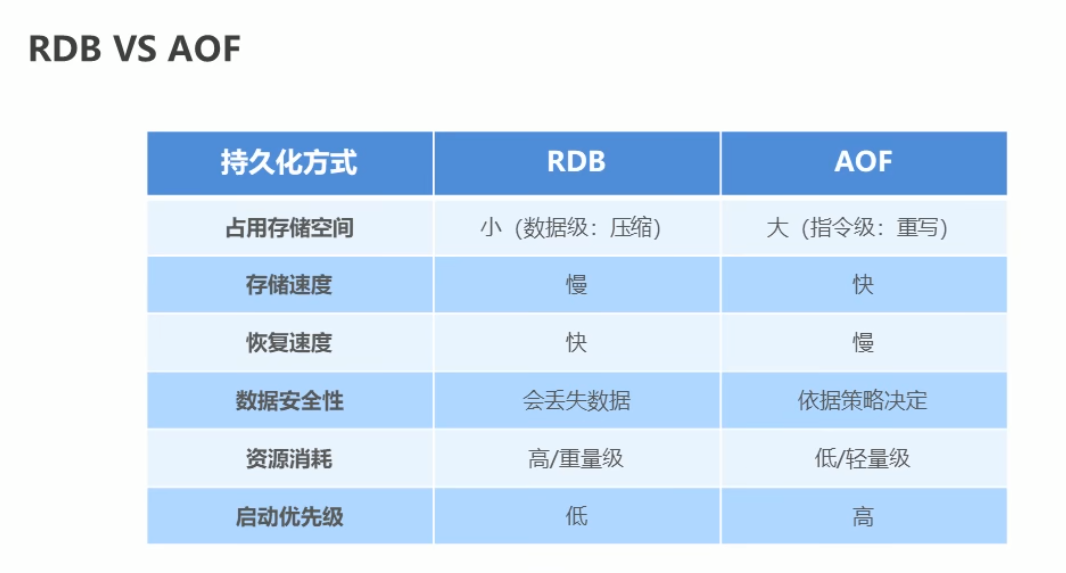
redis持久化:
1、rdb:以快照的形式记录数据
save:保存命令
bgsave:后台保存,会开启子进程进行数据保存
save [second] [count]:自动保存,在second(秒)时间内,改变count次
2、aof:记录历史命令,后台会重写
重写的作用:
1)、降低磁盘占用量,提高磁盘利用率
2)、提高持久化效率,降低持久化写时间,提高IO性能
3)、降低数据恢复用时,提高数据恢复效率
重写规则:
1、已超时的数据不再写入
2、忽略无效指令,只保留最终数据的写入命令
3、对同一数据的多条写命令合并为一条命令(list,set,hash,zset指令一次性最多写入64个元素)
bgrewriteaof:手动重写

redis事务:
multi:开启事务(设定事务的开启位置,此命令执行后,后续的所有命令均加入到该事务中)
exec:执行事务(设定事务的结束位置,同时执行事务。与multi成对使用)
discard:取消事务(终止当前事务,发生在multi之后)
redis监控锁:
watch [key1] [key2] ... :对key添加监视锁,在执行exec前如果key发生变化,终止事务执行
unwatch:取消对所有key的监视
redis:分布式锁(公共锁):
setnx lock-[key] value:设置公共锁
del lock-[key]:释放锁
expire lock-[key] [second]:为锁key添加时间限定,到时不释放,自动释放锁(秒)
pexpire lock-[key] [milliseconds]:为锁key添加时间限定,到时不释放,自动释放锁(毫秒)
redis删除策略:
1、定时删除:用时间换空间
好:节约内存,无占用
坏:不分时段占用CPU资源,频度高
2、惰性删除:访问某个key时,判断该key是否过期,过期则清除
好:延时执行,CPU利用率高
坏:内存占用严重
3、定期删除:每隔一定的时间,扫描一定数量的key,并清除其中过期的key。
redis同时使用惰性删除和定期删除这两种过期策略
redis逐出策略:
相关配置
maxmemory:最大可使用内存
maxmemory-samples:每次选取待删除的数据个数



哨兵模式:
定义:监控主从结构中各个redis服务器工作过程,当master出现故障时,通过投票机制选出新的master,并将所有的slave连接到新的master
工作原理:
1、监控master和各个slave
2、各个哨兵之间互通信息
3、当一个哨兵发现master出现故障,会通知其他哨兵复核,超出一半的哨兵发现master故障,会投票选出一个哨兵进行故障处理,选出一台slave作为新master,通知其他slave连接到新的master
缓存预热:系统启动前,提前将相关的缓存数据直接加载到缓存系统,避免在用户请求的时候,直接查询数据库,再将数据进行缓存的问题。让用户直接查询事先被预热的缓存数据。
缓存雪崩:一段时间内,大量的缓存数据过期,请求直接访问数据库,导致数据库服务器造成大量压力。
解决:
1、热点数据使用永久key
2、为key设置不同的有效期
缓存击穿:单个key数据过期瞬间,数据访问量较大,大量对数据库访问,导致对数据库服务器造成压力。
解决:
1、热点数据使用永久key
2、为key设置不同的有效期
缓存穿透:大量访问不存在的数据,对数据库服务器造成压力。
解决:
1、返回结果为null也进行缓存,有效时间短
2、采用布隆过滤器
布隆过滤器:二进制数组,key经过多个hash函数得出的值就是数组的索引,索引对应位置的值会设置为1。新的key经过同样步骤得出索引值,如果对应位置的值不全是1,说明这个key不存在,直接过滤掉。
问题:存在误判。不同的值hash后可能结果一致,会导致不存在的key判断为存在。
如何保证redis和数据库数据一致性
1、先更新数据库,再删除redis(下次读取时重新加载)
2、更新redis,同步更新数据库(两步操作在同一个事务中)
3、更新redis,发送消息同步到数据库(redis挂了,未同步数据容易丢失)
4、更新数据库,Canal监听Binglog,通过MQ更新redis
5、延迟双删,更新数据库前后删除redis(第二次删除延迟500ms)
6、分布式锁,加锁,更新数据库和删除缓存,释放锁








![[特殊字符] 革命性AI提示词优化平台正式开源!](https://i-blog.csdnimg.cn/img_convert/8adcd90bf88b441532d598df1bd2466f.png)