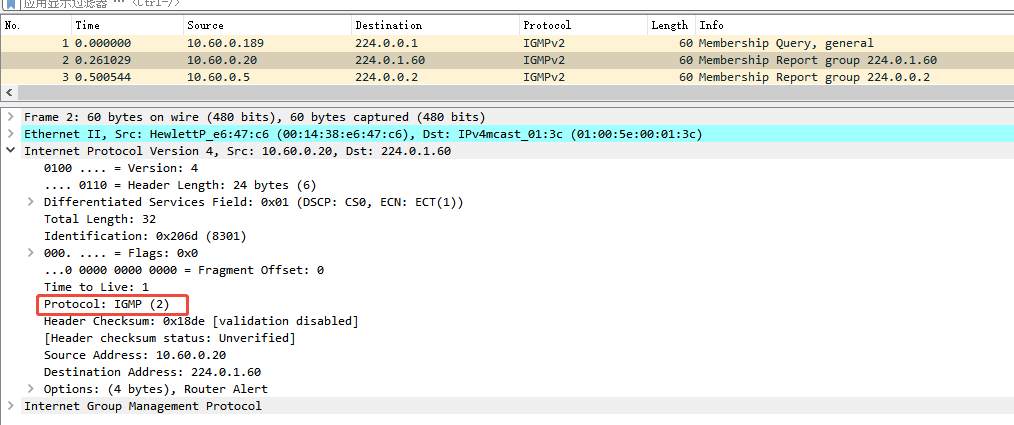
RT-DETR
- 1.模型介绍
- 📌 什么是 RT-DETR ?
- 📖 核心改进点
- 📊 结构示意
- 🎯 RT-DETR 优势
- ⚠️ RT-DETR 缺点
- 📈 应用场景
- 📑 论文 & 官方仓库
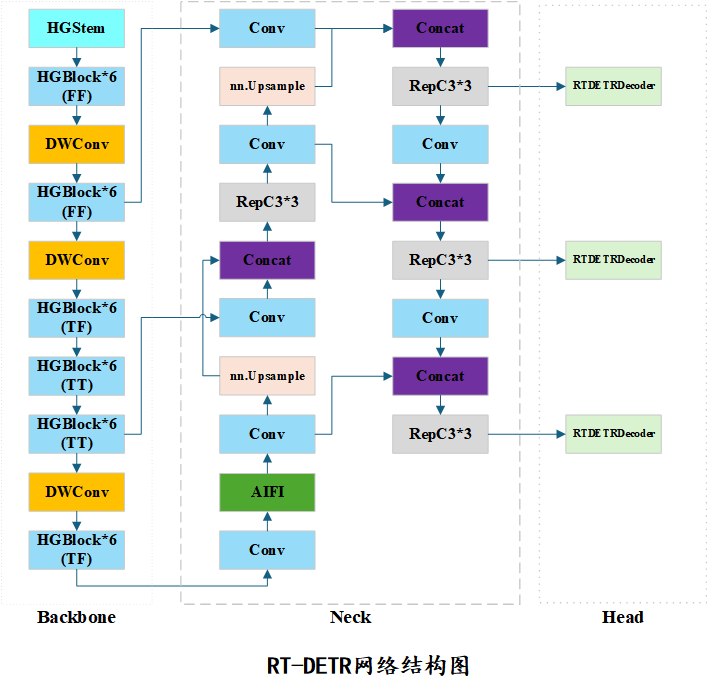
- 2.模型框架
- 3.Yaml配置文件
- 4.训练脚本
- 5.训练完成截图
- 6.总结与讨论
1.模型介绍
📌 什么是 RT-DETR ?
RT-DETR(Real-Time Detection Transformer) 是百度和视觉学界联合提出的一种端到端实时目标检测方法,是DETR 系列的加速优化版。
它解决了原始 DETR(2020) 推理慢、收敛慢的问题,让 Transformer-based 检测器能在实时速率下工作,同时保持高精度。
📖 核心改进点
| 模块 | 原始DETR | RT-DETR |
|---|---|---|
| 编码器 | Transformer Encoder | 精简型 Encoder + 动态特征增强 |
| 检测头 | 查询-匹配式 DETR Head | Group-DETR Head(分组预测更高效) |
| 匹配方式 | 匈牙利匹配 | 匈牙利匹配(保留,稳定可靠) |
| 上采样 | FPN特征拼接 | 多层特征解耦动态融合 |
| NMS | 不用(端到端预测) | 不用,直接输出 Top-N 框 |
| 收敛速度 | 极慢(500轮起步) | 极快(50轮左右) |
📊 结构示意
🌱 下图是简化结构
输入图像
│
Backbone(ResNet/ConvNext)
│
Neck(多层特征)
│
精简 Transformer Encoder
│
Group DETR Head(查询式)
│
匈牙利匹配 (训练时)
│
直接输出预测结果 (无需NMS)
🎯 RT-DETR 优势
✅ 实时速率,接近 YOLOv8 的 FPS
✅ 端到端,不用NMS、anchor
✅ 精度高,尤其是遮挡、细粒度目标表现优异
✅ 支持多种backbone(ResNet50、ResNet101、ConvNeXt)
✅ 高效、轻量,适合工程部署
⚠️ RT-DETR 缺点
⚠️ 对硬件要求较高(特别是显存)
⚠️ 动态查询 Head 复杂,不如 YOLO 系列直观
⚠️ 小目标场景需微调特征提取策略
📈 应用场景
📦 智能制造缺陷检测
📦 智慧城市交通分析
📦 卫星遥感小目标检测
📦 实时安全监控
📑 论文 & 官方仓库
- 📖 论文:RT-DETR: Real-Time Detection Transformer
- 📦 仓库:PaddleDetection-RT-DETR
2.模型框架
##3.数据集配置
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# COCO128 dataset https://www.kaggle.com/datasets/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Documentation: https://docs.ultralytics.com/datasets/detect/coco/
# Example usage: yolo train data=coco128.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco128 ← downloads here (7 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
train: /root/DATA/backup/images/train #
val: /root/DATA/backup/images/val
# Classes
names:
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
5: bus
6: train
7: truck
8: boat
9: traffic light
10: fire hydrant
11: stop sign
12: parking meter
13: bench
14: bird
15: cat
16: dog
17: horse
18: sheep
19: cow
20: elephant
21: bear
22: zebra
23: giraffe
24: backpack
25: umbrella
26: handbag
27: tie
28: suitcase
29: frisbee
30: skis
31: snowboard
32: sports ball
33: kite
34: baseball bat
35: baseball glove
36: skateboard
37: surfboard
38: tennis racket
39: bottle
40: wine glass
41: cup
42: fork
43: knife
44: spoon
45: bowl
46: banana
47: apple
48: sandwich
49: orange
50: broccoli
51: carrot
52: hot dog
53: pizza
54: donut
55: cake
56: chair
57: couch
58: potted plant
59: bed
60: dining table
61: toilet
62: tv
63: laptop
64: mouse
65: remote
66: keyboard
67: cell phone
68: microwave
69: oven
70: toaster
71: sink
72: refrigerator
73: book
74: clock
75: vase
76: scissors
77: teddy bear
78: hair drier
79: toothbrush
以COCO为例
3.Yaml配置文件
# Ultralytics YOLO 🚀, AGPL-3.0 license
# RT-DETR-l object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/rtdetr
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, HGStem, [32, 48]] # 0-P2/4
- [-1, 6, HGBlock, [48, 128, 3]] # stage 1
- [-1, 1, DWConv, [128, 3, 2, 1, False]] # 2-P3/8
- [-1, 6, HGBlock, [96, 512, 3]] # stage 2
- [-1, 1, DWConv, [512, 3, 2, 1, False]] # 4-P3/16
- [-1, 6, HGBlock, [192, 1024, 5, True, False]] # cm, c2, k, light, shortcut
- [-1, 6, HGBlock, [192, 1024, 5, True, True]]
- [-1, 6, HGBlock, [192, 1024, 5, True, True]] # stage 3
- [-1, 1, DWConv, [1024, 3, 2, 1, False]] # 8-P4/32
- [-1, 6, HGBlock, [384, 2048, 5, True, False]] # stage 4
head:
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 10 input_proj.2
- [-1, 1, AIFI, [1024, 8]]
- [-1, 1, Conv, [256, 1, 1]] # 12, Y5, lateral_convs.0
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [7, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 14 input_proj.1
- [[-2, -1], 1, Concat, [1]]
- [-1, 3, RepC3, [256]] # 16, fpn_blocks.0
- [-1, 1, Conv, [256, 1, 1]] # 17, Y4, lateral_convs.1
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [3, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 19 input_proj.0
- [[-2, -1], 1, Concat, [1]] # cat backbone P4
- [-1, 3, RepC3, [256]] # X3 (21), fpn_blocks.1
- [-1, 1, Conv, [256, 3, 2]] # 22, downsample_convs.0
- [[-1, 17], 1, Concat, [1]] # cat Y4
- [-1, 3, RepC3, [256]] # F4 (24), pan_blocks.0
- [-1, 1, Conv, [256, 3, 2]] # 25, downsample_convs.1
- [[-1, 12], 1, Concat, [1]] # cat Y5
- [-1, 3, RepC3, [256]] # F5 (27), pan_blocks.1
- [[21, 24, 27], 1, RTDETRDecoder, [nc]] # Detect(P3, P4, P5)
4.训练脚本
# @File: train.py
# @Author: chen_song
# @Time: 2025-06-03 17:55
# 10:43开始的
from ultralytics import RTDETR
# Load a COCO-pretrained RT-DETR-l model
weigth = r"/root/CS/ultralytics-main/ultralytics/cfg/models/rt-detr/rtdetr-l.yaml"
model = RTDETR(weigth)
# Display model information (optional)
model.info()
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="/root/CS/ultralytics-main/ultralytics/cfg/datasets/coco.yaml",
epochs=100,
batch=64,
imgsz=640,
workers=10,
amp=True,
project=r'/root/CS/ultralytics-main/runs/train',
name='exp',)
# Run inference with the RT-DETR-l model on the 'bus.jpg' image
# results = model("path/to/bus.jpg")
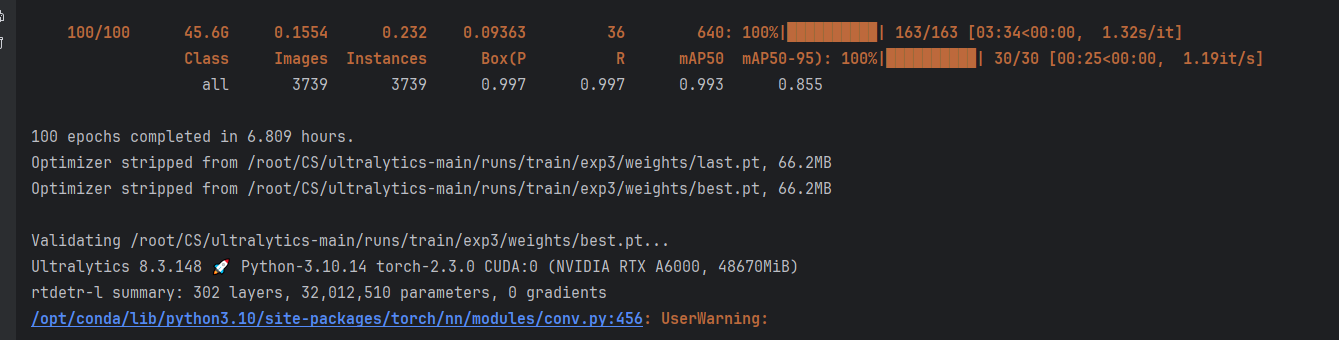
5.训练完成截图
6.总结与讨论
虽然RT-DETR比DETR精度更高,FPS更高,但是参数量依旧很大,普通显卡不够训练。未来考虑轻量化改进以及图像压缩等操作。