一、ES集群部署
| 操作系统 | Ubuntu22.04LTS | / |
| 主机名 | IP地址 | 主机配置 |
| elk91 | 10.0.0.91/24 | 4Core8GB100GB磁盘 |
| elk92 | 10.0.0.92/24 | 4Core8GB100GB磁盘 |
| elk93 | 10.0.0.93/24 | 4Core8GB100GB磁盘 |
1. 什么是ElasticStack?
# 官网
https://www.elastic.co/ElasticStack早期名称为elk。
elk分别代表了3个组件:
- ElasticSearch
负责数据存储和检索。
- Logstash:
负责数据的采集,将源数据采集到ElasticSearch进行存储。
- Kibana:
负责数据的展示。
由于Logstash是一个重量级产品,很多同学只是用于采集日志,于是使用其他采集工具代替,比如flume,fluentd等产品替代。
后来elastic公司也发现了这个问题,于是开发了一堆beats产品,其中典型代表就是Filebeat,metricbeat,heartbeat等。
而后,对于安全而言,又推出了xpack等相关组件,以及云环境的组件。
后期名称命名为elk stack,后来公司为了宣传ElasticStack
2. 基于deb包安装ES单点
# 下载对应的软件包
[root@elk91 ~]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.28-amd64.deb
# 安装ES
[root@elk91 ~]# dpkg -i elasticsearch-7.17.28-amd64.deb
# 修改配置文件
[root@elk91 ~]# egrep -v '^#|^$' /etc/elasticsearch/elasticsearch.yml
cluster.name: CFC_ElasticStack
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.type: single-node3. 启动ES并测试访问
# 启动ES
[root@elk91 ~]# systemctl enable --now elasticsearch.service
[root@elk91 ~]# !netstat
netstat -nltup |grep -E '9[2|3]00'
tcp6 0 0 :::9300 :::* LISTEN 2618/java
tcp6 0 0 :::9200 :::* LISTEN 2618/java
# 访问测试
[root@elk91 ~]# !curl
curl http://10.0.0.91:9200/_cat/nodes
10.0.0.91 19 97 7 0.66 0.27 0.14 cdfhilmrstw * elk91
[root@elk91 ~]# curl http://10.0.0.91:9200
{
"name" : "elk91",
"cluster_name" : "CFC_ElasticStack",
"cluster_uuid" : "wxGXcKgsR2eLVcrDJRNifw",
"version" : {
"number" : "7.17.28",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "139cb5a961d8de68b8e02c45cc47f5289a3623af",
"build_date" : "2025-02-20T09:05:31.349013687Z",
"build_snapshot" : false,
"lucene_version" : "8.11.3",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
[root@elk91 ~]# curl http://10.0.0.91:9200/_cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1741694467 12:01:07 CFC_ElasticStack green 1 1 3 3 0 0 0 0 - 100.0%
[root@elk91 ~]# curl http://10.0.0.91:9200/_cat/nodes?v
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.0.0.91 39 97 0 0.03 0.14 0.11 cdfhilmrstw * elk91
二、ES集群框架
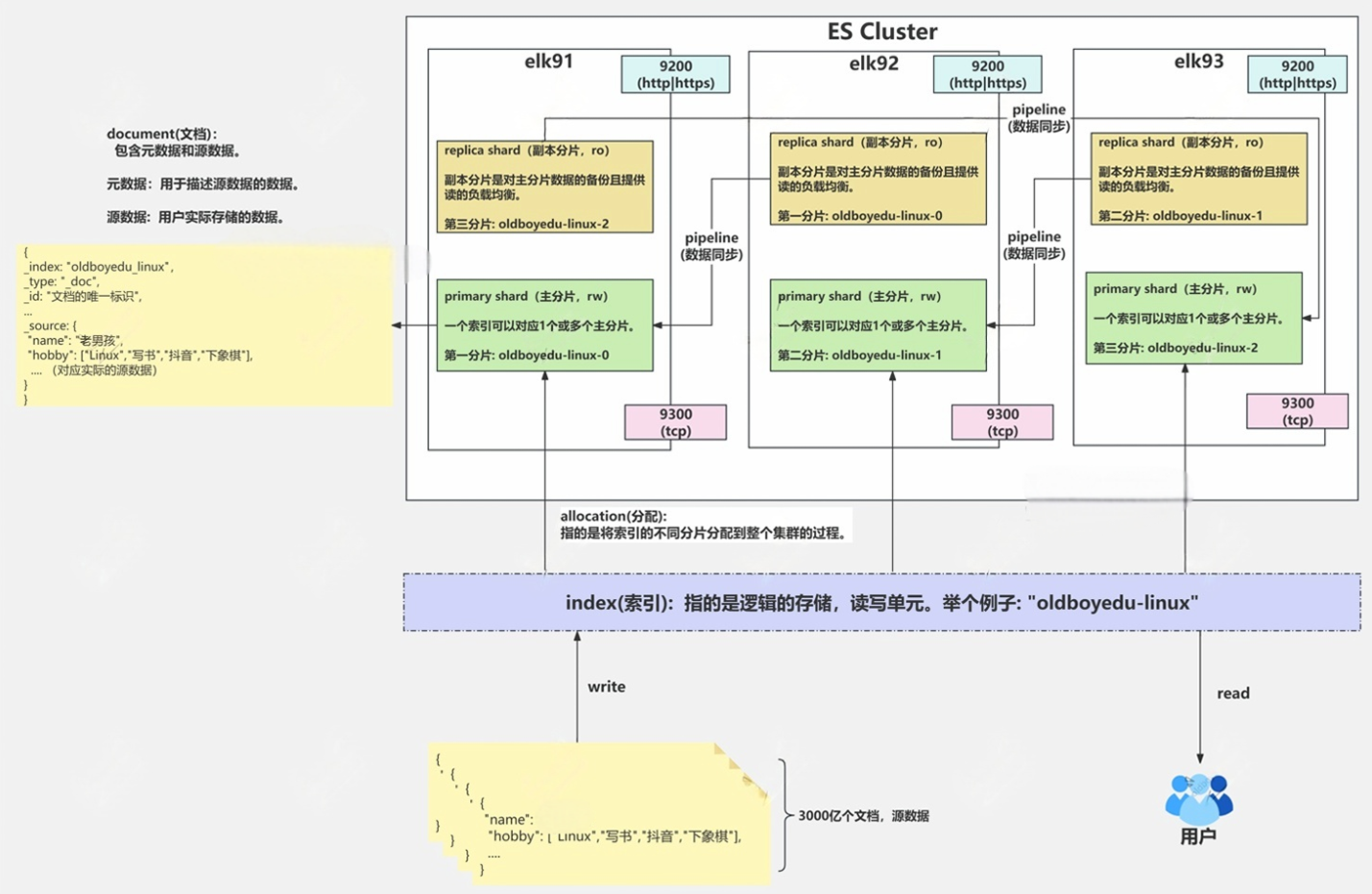
1. ES常用术语
- 索引: Index
用户进行数据的读写单元。
- 分片: Shard
一个索引至少要有一个分片,如果一个索引仅有一个分片,意味着该索引的数据只能全量存储在某个节点上,且分片是不可拆分的,隶属于某个节点。
换句话说,分片是ES集群最小的调度单元。
一个索引数据也可以被分散的存储在不同的分片上,且这些分片可以放在不同的节点,从而实现数据的分布式存储。
- 副本: replica
副本是针对分片来说的,一个分片可以有0个或多个副本。
当副本数量为0时,意味着只有主分片(priamry shard),当主分片所在的节点宕机时,数据就无法访问了。
当副本数量大于0时,意味着同时存在主分片和副本分片(replica shard):
- 主分片负责数据的读写(read write,rw)
- 副本分片负责数据的读的负载均衡(read only,ro)
- 文档: document:
指的是用户存储的数据。其中包含元数据和源数据。- 元数据:
用于描述源数据的数据。- 源数据:
用户实际存储的数据。
- 分配: allocation
指的是将索引的不同分片(包含主分片和副本分片)分配到整个集群的过程。
三、ES集群环境部署
1. 先停止91服务
# 停止91单点ES服务
[root@elk91 ~]# !kill
kill `ps -ef |grep java|grep -v grep |awk '{print $2}'`
# 拷贝软件包给其他两个节点
[root@elk91 ~]# scp elasticsearch-7.17.28-amd64.deb 10.0.0.92:~
[root@elk91 ~]# scp elasticsearch-7.17.28-amd64.deb 10.0.0.93:~
# 其他节点安装ES环境
[root@elk92 ~]# dpkg -i elasticsearch-7.17.28-amd64.deb
[root@elk93 ~]# dpkg -i elasticsearch-7.17.28-amd64.deb2. 修改91配置文件为集群模式
记得修改完91配置文件一同拷贝到其他92/93节点哦~
[root@elk91 ~]# !egrep
egrep -v '^#|^$' /etc/elasticsearch/elasticsearch.yml
cluster.name: CFC_ElasticStack
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["10.0.0.91", "10.0.0.92", "10.0.0.93"]
# 拷贝配置文件给其他两个节点使用
[root@elk91 ~]# scp /etc/elasticsearch/elasticsearch.yml 10.0.0.92:/etc/elasticsearch/elasticsearch.yml
[root@elk91 ~]# scp /etc/elasticsearch/elasticsearch.yml 10.0.0.93:/etc/elasticsearch/elasticsearch.yml3. 启动ES集群
[root@elk91 ~]# systemctl enable --now elasticsearch.service
[root@elk92 ~]# systemctl enable --now elasticsearch.service
[root@elk93 ~]# systemctl enable --now elasticsearch.service
# 查看集群状态
[root@elk91 ~]# for i in 91 92 93;do curl -s http://10.0.0.$i:9200; done |grep cluster_uuid
"cluster_uuid" : "wxGXcKgsR2eLVcrDJRNifw",
"cluster_uuid" : "wxGXcKgsR2eLVcrDJRNifw",
"cluster_uuid" : "wxGXcKgsR2eLVcrDJRNifw",
[root@elk91 ~]# curl http://10.0.0.92:9200/_cat/nodes?v
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.0.0.93 7 97 0 0.06 0.15 0.07 cdfhilmrstw - elk93
10.0.0.92 6 97 0 0.09 0.13 0.06 cdfhilmrstw - elk92
10.0.0.91 15 97 0 0.14 0.15 0.11 cdfhilmrstw * elk91
# ‘ * ’号在哪谁就是master节点部署彩蛋
快速部署校验ES集群解决方案:
报错信息: 集群缺少master,并且看到curl的返回结果的UUID为_na_这样就代表我们的集群搭建有问题
[root@elk3 ~]# curl http://10.0.0.92:9200/_cat/nodes?v
{"error":{"root_cause":[{"type":"master_not_discovered_exception","reason":null}],"type":"master_not_discovered_exception","reason":null},"status":503}
[root@elk3 ~]# curl 10.0.0.91:9200
{
"name" : "elk91",
"cluster_name" : "novacao-linux96",
"cluster_uuid" : "_na_",
...
}
### 解决方案:
- 停止集群的ES服务
[root@elk91 ~]# systemctl stop elasticsearch.service
[root@elk92 ~]# systemctl stop elasticsearch.service
[root@elk93 ~]# systemctl stop elasticsearch.service
- 删除数据,日志,和临时数据
[root@elk91 ~]# rm -rf /var/{lib,log}/elasticsearch/* /tmp/*
[root@elk92 ~]# rm -rf /var/{lib,log}/elasticsearch/* /tmp/*
[root@elk93 ~]# rm -rf /var/{lib,log}/elasticsearch/* /tmp/*
- 检查集群各节点的配置----->并且可以选择启动cluster.initial_master_nodes配置,自己初始化一下。
[root@elk91 ~]# yy /etc/elasticsearch/elasticsearch.yml
cluster.name: novacao-linux96
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["10.0.0.91", "10.0.0.92","10.0.0.93"]
cluster.initial_master_nodes: ["10.0.0.91","10.0.0.92","10.0.0.93"]
[root@elk91 ~]#
[root@elk91 ~]# scp /etc/elasticsearch/elasticsearch.yml 10.0.0.92:/etc/elasticsearch/
[root@elk91 ~]# scp /etc/elasticsearch/elasticsearch.yml 10.0.0.93:/etc/elasticsearch/
- 启动ES服务
[root@elk91 ~]# systemctl restart elasticsearch.service
[root@elk92 ~]# systemctl restart elasticsearch.service
[root@elk93 ~]# systemctl restart elasticsearch.service
- 测试验证
[root@elk91 ~]# for i in `seq 91 93`; do curl -s 10.0.0.$i:9200 | grep cluster_uuid; done
"cluster_uuid" : "-5ly4d8-Tl6biIMmp4pzKw",
"cluster_uuid" : "-5ly4d8-Tl6biIMmp4pzKw",
"cluster_uuid" : "-5ly4d8-Tl6biIMmp4pzKw",
[root@elk91 ~]#
[root@elk91 ~]# curl 10.0.0.93:9200/_cat/nodes
10.0.0.91 11 94 4 0.43 0.36 0.29 cdfhilmrstw - elk91
10.0.0.93 11 96 2 0.47 0.43 0.28 cdfhilmrstw - elk93
10.0.0.92 5 97 3 0.32 0.44 0.33 cdfhilmrstw * elk92
[root@elk91 ~]# 四、ES的master选举流程
- 0.启动时会检查集群是否有master,如果有则不发起选举master;
- 1.刚开始启动,所有节点均为人自己是master,并向集群的其他节点发送信息(包含ClusterStateVersion,ID等)
- 2.基于类似gossip协议获取所有可以参与master选举的节点列表;
- 3.先比较"ClusterStateVersion",谁最大,谁优先级高,会被选举出master;
- 4.如果比不出来,则比较ID,谁的ID小,就优先成为master;
- 5.当集群半熟以上节点参与选举完成后,则完成master选举,比如有N个节点,仅需要"(N/2)+1"节点就可以确认master;
- 6.master选举完成后,会向集群列表通报最新的master节点,此时才意味着选举完成;五、Kibana部署与实践
1. Kibana部署与实践
kibana是针对ES做的一款可视化工具。将来的操作都可以在ES中完成。
# 下载Kibana
[root@elk91 ~]# wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.28-amd64.deb
# 安装Kibana
[root@elk91 ~]# dpkg -i kibana-7.17.28-amd64.deb
# 修改Kibana配置文件
[root@elk91 ~]# vim /etc/kibana/kibana.yml
[root@elk91 ~]# egrep -v '^#|^$' /etc/kibana/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://10.0.0.91:9200","http://10.0.0.92:9200","http://10.0.0.93:9200"]
i18n.locale: "zh-CN"
相关参数说明:
server.port
kibana监听的端口。
server.host
kibana监听的IP地址。
elasticsearch.hosts
kibana管理的ES集群信息。
i18n.locale
安装时选择的语言。
# 启动Kibana
[root@elk91 ~]# systemctl enable --now kibana.service
[root@elk91 ~]# netstat -nltup|grep 5601
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 3598/node
# webUI页面访问测试
http://10.0.0.91:56012. 创建一些数据
# 创建一个数据
[root@elk91 ~]# curl --location --request POST 'http://10.0.0.91:9200/_bulk' \
--header 'Content-Type: application/json' \
--data-raw '
{ "create" : { "_index" : "cfc-linux96", "_id" : "3" } }
{ "name" : "猪八戒","hobby": ["猴哥","高老庄"] }
{ "create" : { "_index" : "cfc-linux96", "_id" : "2" } }
{ "name" : "沙和尚","hobby": ["流沙河","挑行李"] }
{ "create" : { "_index" : "cfc-linux96", "_id" : "1" } }
{ "name" : "白龙马","hobby": ["大师兄,师傅被妖怪抓走啦"] }
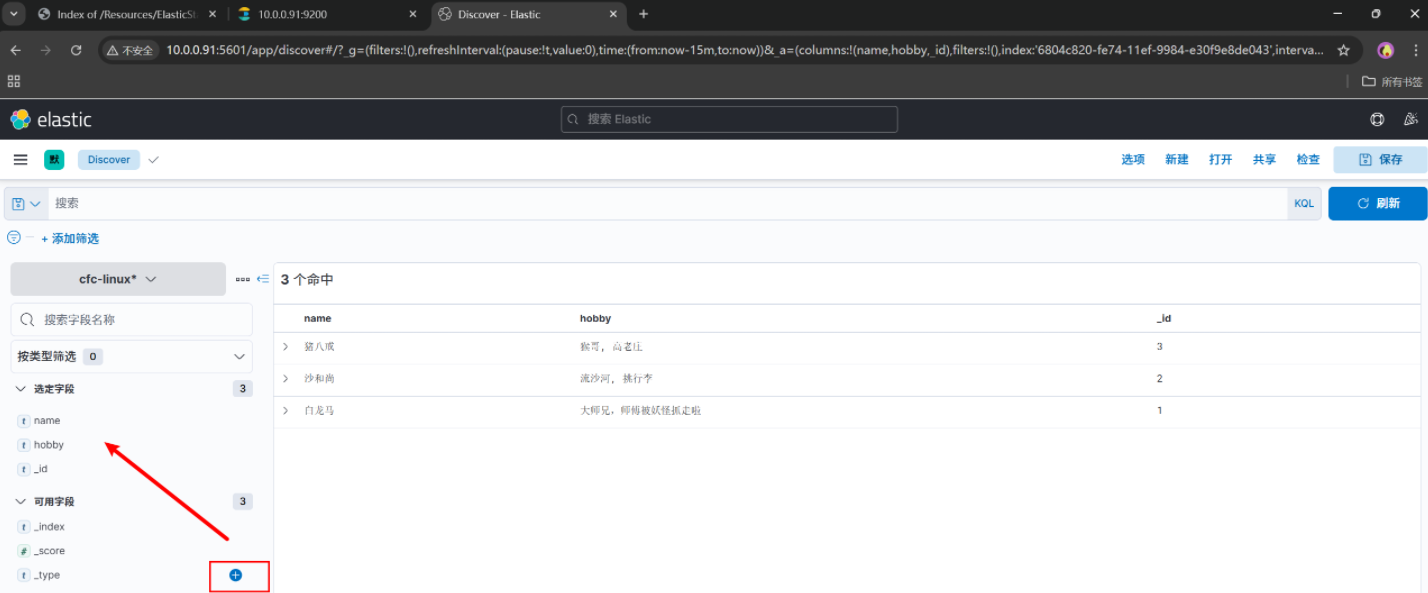
'3. 访问测试
10.0.0.91:5601
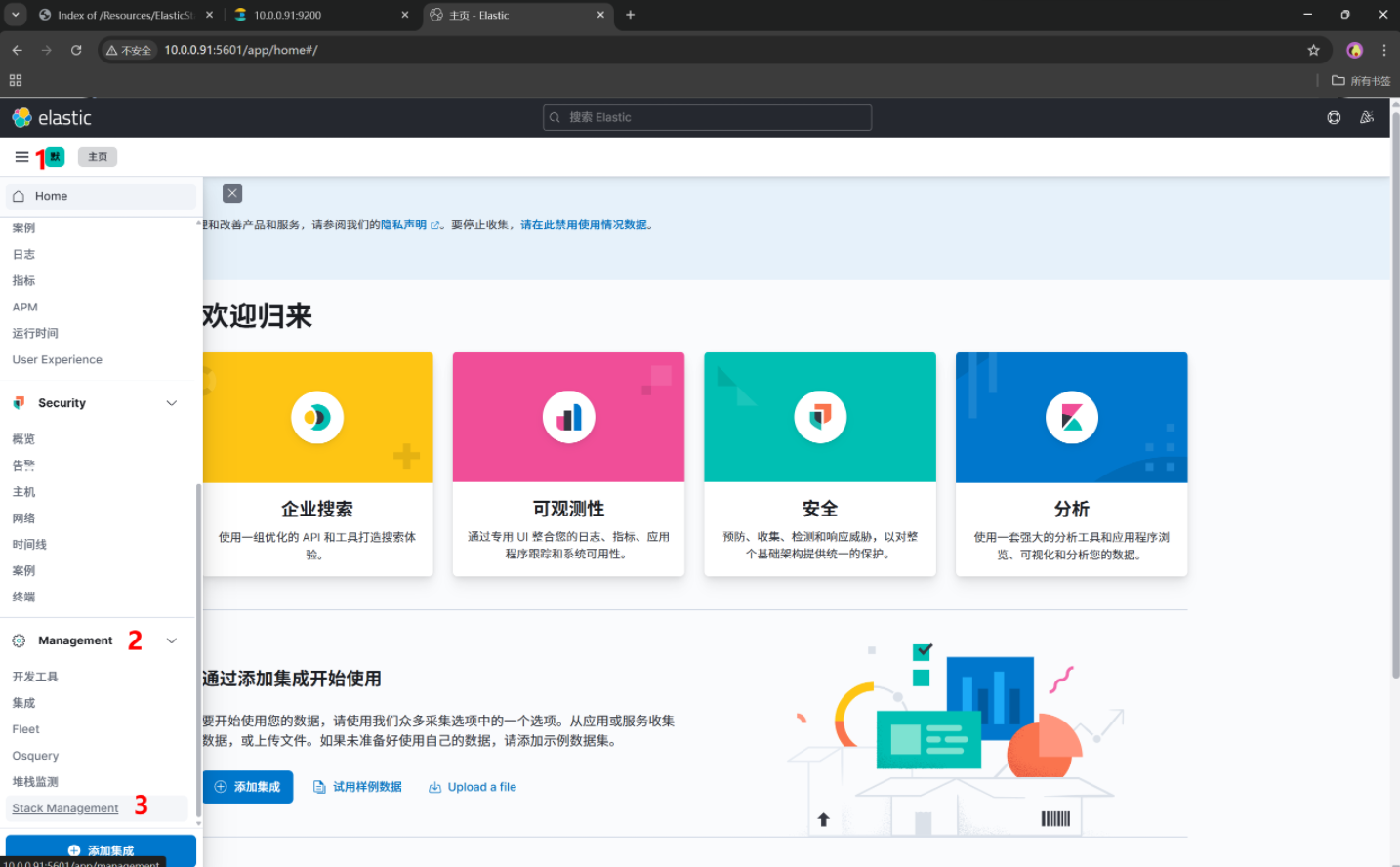 可以看到我们刚刚创建了一个索引
可以看到我们刚刚创建了一个索引
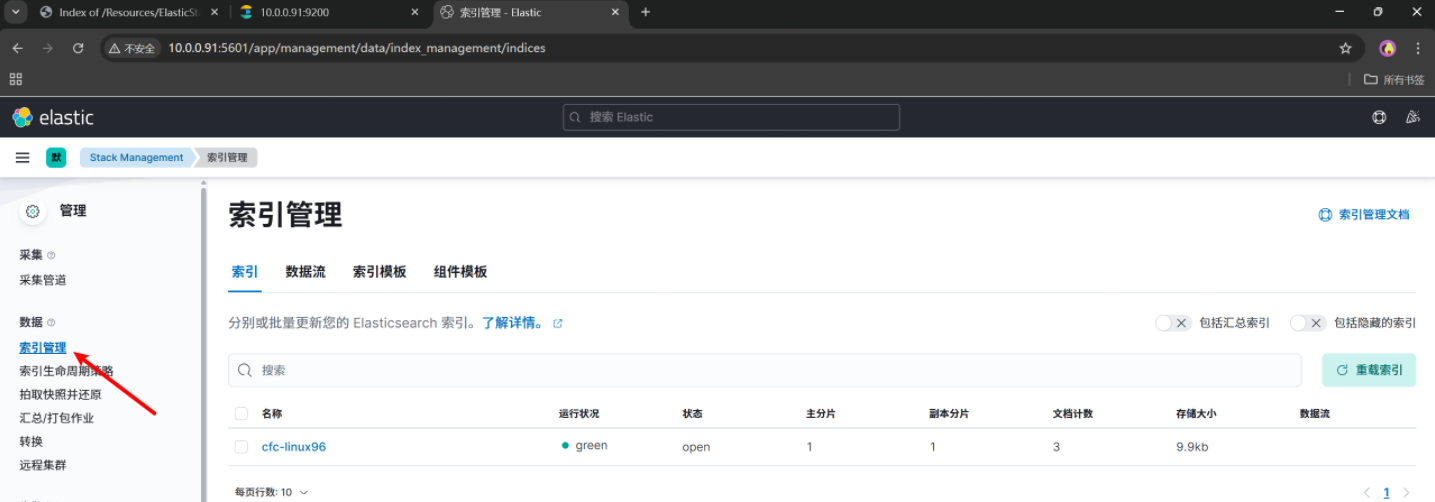 创建一个索引模式,引入ES的索引数据,我们要直观的查看数据内容
创建一个索引模式,引入ES的索引数据,我们要直观的查看数据内容
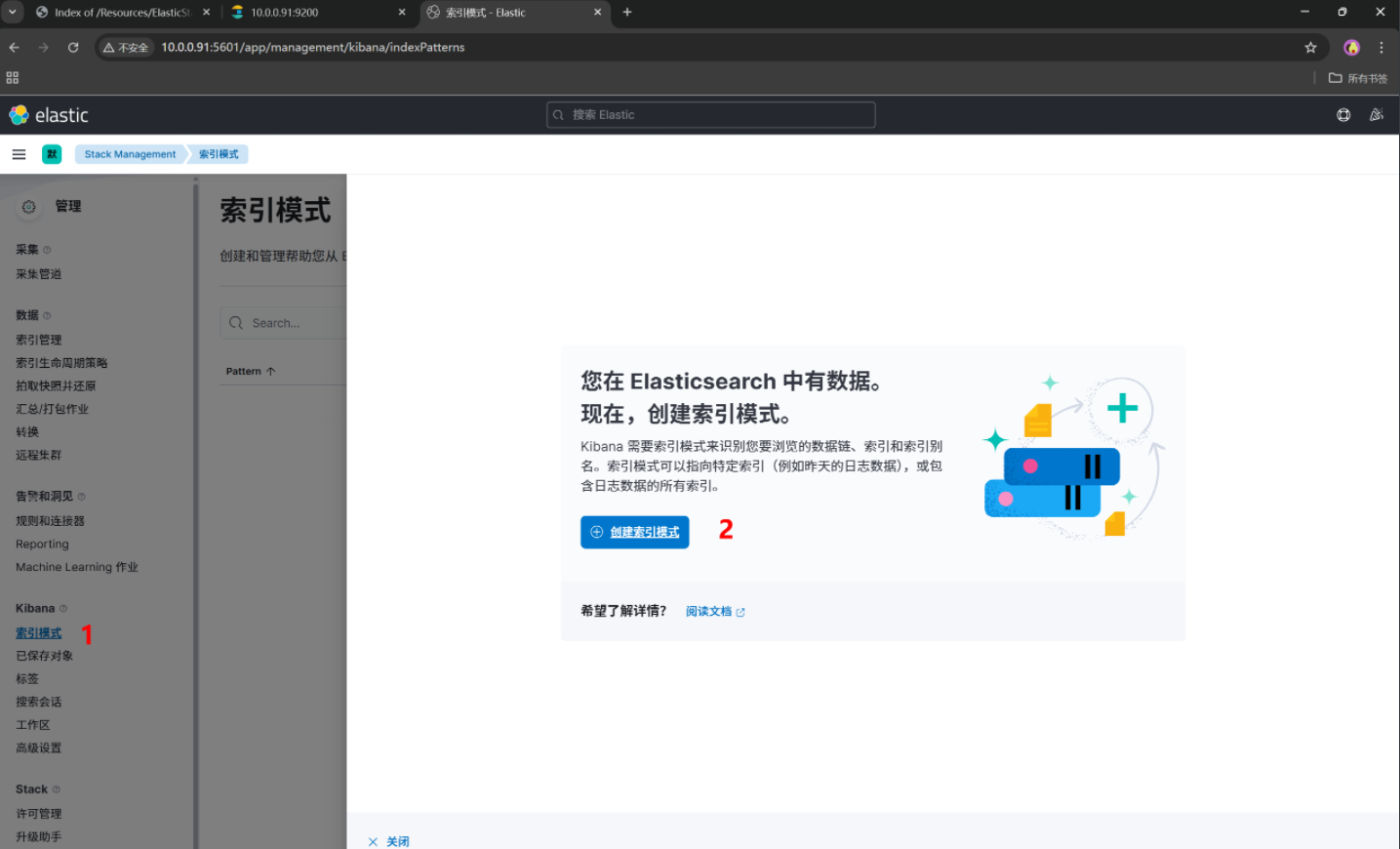
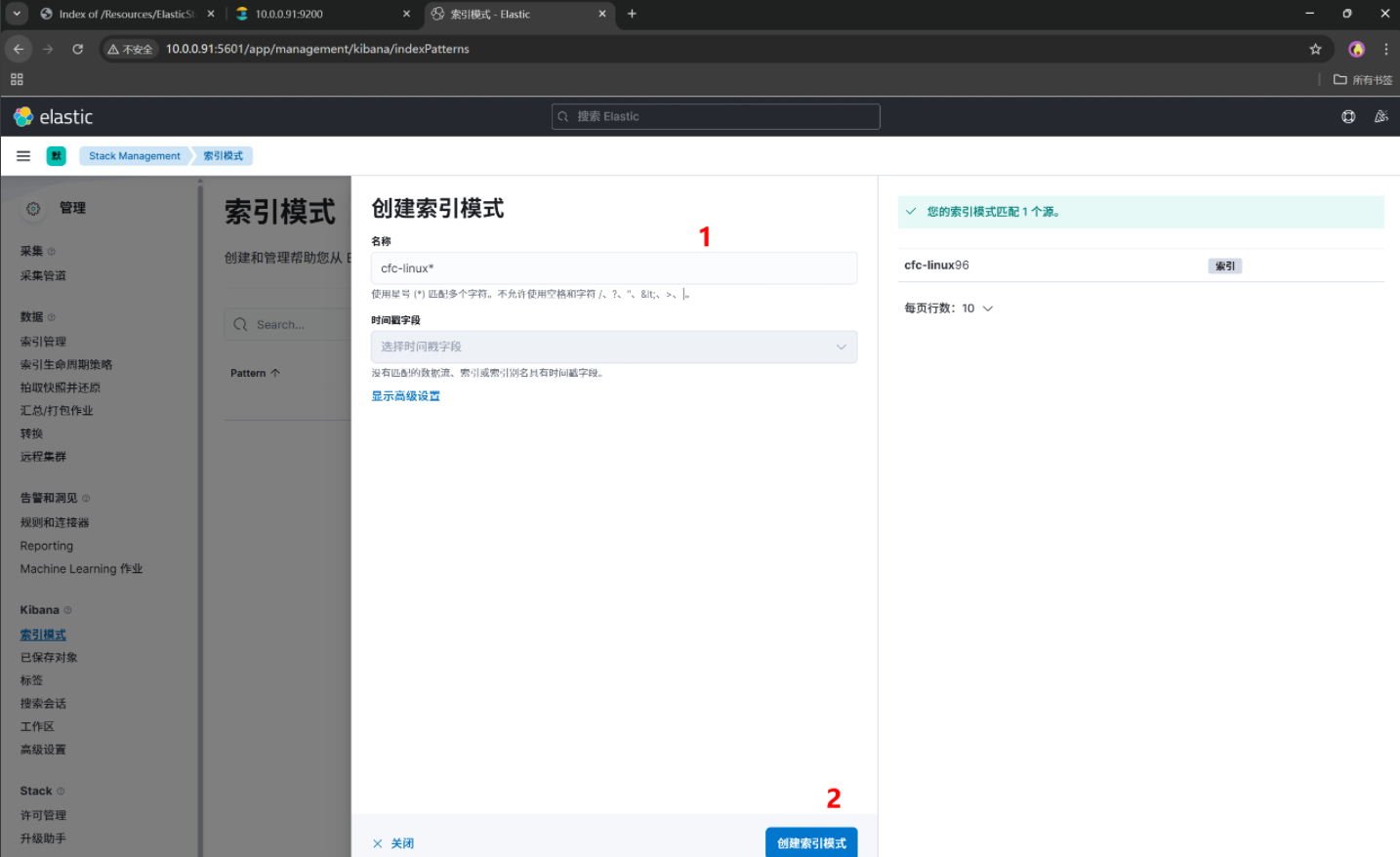
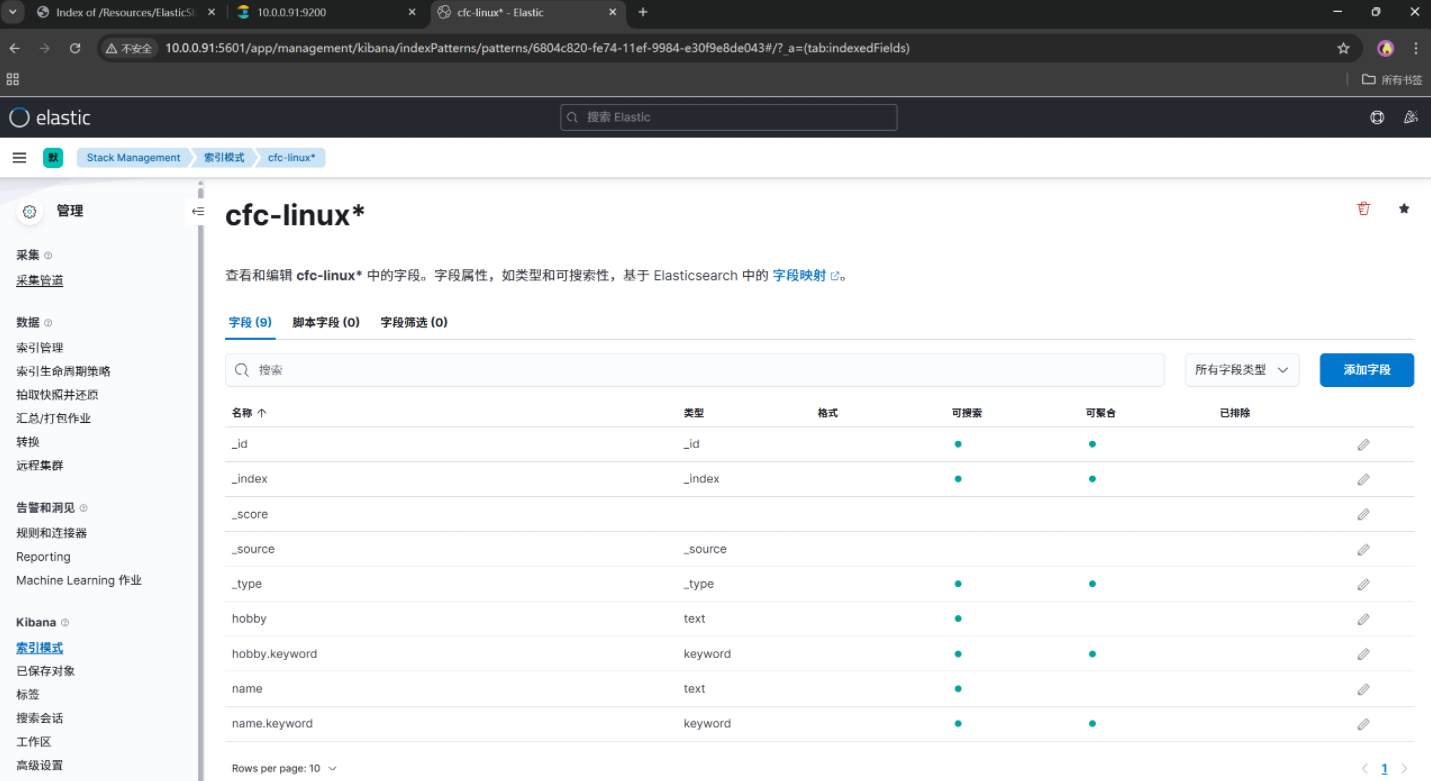
想看什么自己选择
KQL(Kabana Query Language)语句
也可以选择
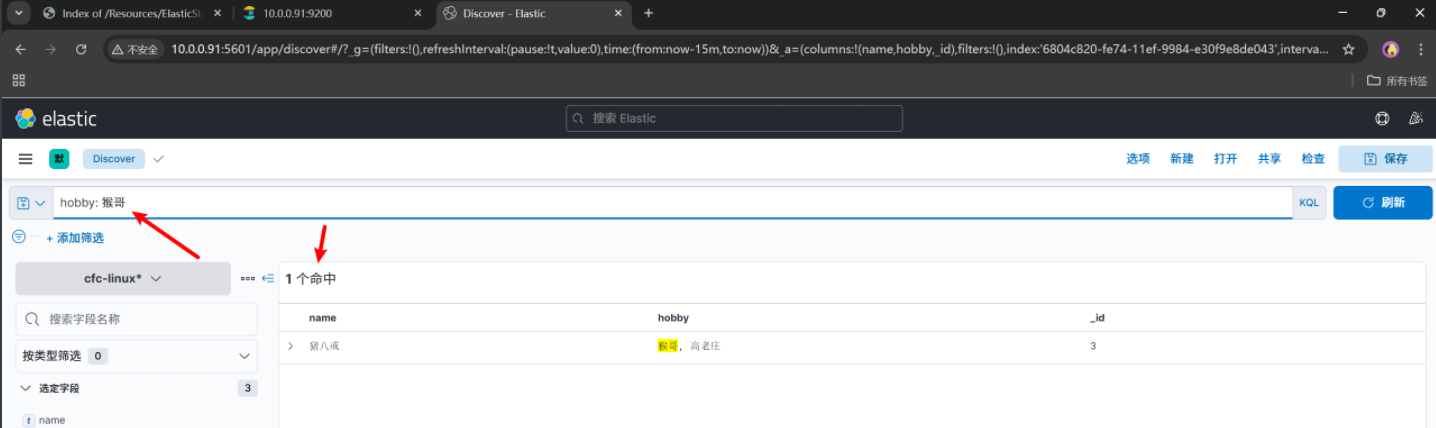
这就是Kibana的KQL(Kabana Query Language)语句
六、Filebeat部署与实践
1.部署Filebeat
# 下载Filebeat软件包
[root@elk92 ~]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.28-amd64.deb
# 安装Filebeat
[root@elk92 ~]# dpkg -i filebeat-7.17.28-amd64.deb 2.log类型底层逻辑验证
# 编写Filebeat配置文件
可以参考官网
https://www.elastic.co/guide/en/beats/filebeat/7.17/filebeat-input-log.html
[root@elk92 ~]# mkdir -p /etc/filebeat/config/
[root@elk92 ~]# vim /etc/filebeat/config/01-log-to-console.yaml
[root@elk92 ~]# cat /etc/filebeat/config/01-log-to-console.yaml
# 定义数据从哪里来
filebeat.inputs:
# 指定数据源的类型是log,表示从文件读取数据
- type: log
# 指定文件的路径
paths:
- /tmp/student.log
# 定义数据到终端
output.console:
pretty: true
# 启动Filebeta实例
[root@elk92 ~]# filebeat -e -c /etc/filebeat/config/01-log-to-console.yaml
这时候我们克隆一个终端去验证我们的Filebeat,向源数据文件("/tmp/student.log")写入测试数据
[root@elk92 ~]# echo cao >> /tmp/student.log
# 再次去启动实例的节点查看是否监测到有数据写入
{
"@timestamp": "2025-03-11T12:51:21.469Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "7.17.28"
},
"input": {
"type": "log" ## log类型
},
"agent": {
"ephemeral_id": "ce656c96-a6f1-4ea2-ad01-278cfc71977b",
"id": "e1554509-9551-4ad8-b369-1435a928e950",
"name": "elk92",
"type": "filebeat",
"version": "7.17.28",
"hostname": "elk92"
},
"ecs": {
"version": "1.12.0"
},
"host": {
"name": "elk92"
},
"log": {
"offset": 0, ### 看这里我们当前的位置点是0,因为这是新插入的数据
"file": {
"path": "/tmp/student.log" ### 数据路径
}
},
"message": "cao"
}
# 我们再插入进行测试
....
"input": {
"type": "log"
},
"ecs": {
"version": "1.12.0"
},
"host": {
"name": "elk92"
},
"agent": {
"type": "filebeat",
"version": "7.17.28",
"hostname": "elk92",
"ephemeral_id": "ce656c96-a6f1-4ea2-ad01-278cfc71977b",
"id": "e1554509-9551-4ad8-b369-1435a928e950",
"name": "elk92"
},
"log": {
"offset": 4, ### 位置点变成了4
"file": {
"path": "/tmp/student.log"
}
},
"message": "123"
}
这里解释一下为什么变成了4,而不是3呢,我明明cao不是三个字符吗?
因为我们echo插入数据的时候默认是有一个换行符存在的
[root@elk92 ~]# cat -A /tmp/student.log
cao$
123$
看到我们结尾的$我们就可以理解这是一个换行符
# 那我们们如果取消换行符再插入呢?
[root@elk92 ~]# echo -n can >> /tmp/student.log
[root@elk92 ~]# cat /tmp/student.log -A
cao$
123$
can[root@elk92 ~]#
[root@elk92 ~]# echo -n cancan >> /tmp/student.log
[root@elk92 ~]# cat /tmp/student.log -A
cao$
123$
cancancan[root@eecho -n cancan666 >> /tmp/student.log
[root@elk92 ~]# cat /tmp/student.log -A
cao$
123$
cancancancancan666[root@elk92 ~]#
我们可以发现这里我们取消了换行符进行插入数据
我们就可以发现我们的filebeat并没有记入我们的检测里
那我们如果再进行换行追加呢?
[root@elk92 ~]# echo fafa666 >> /tmp/student.log
[root@elk92 ~]# cat /tmp/student.log -A
cao$
123$
cancancancancan666fafa666$
....
},
"log": {
"offset": 8,
"file": {
"path": "/tmp/student.log"
}
},
"message": "cancancancancan666fafa666",
"input": {
"type": "log"
}
}
嘿,我们发现记录到了,并且从8的位置点开始记录
我们的filebeat的数据都记录到了log.json文件下面
[root@elk92 ~]# cat /var/lib/filebeat/registry/filebeat/log.json
即使我们删除目录
[root@elk92 ~]# rm -fr /var/lib/filebeat/
再重启
[root@elk92 ~]# filebeat -e -c /etc/filebeat/config/01-log-to-console.yaml
依然会按照行的形式去读取并返回相应的数据点
有时在同一个文件中二次加载同一个文件会发生已经加载过数据不能及时更新的问题,这是我们删除一下加载目录,让filebeat重新加载一下就好了。
### 数据流走向
echo ---> /tmp/student.log ---> filebeat ---> ES集群 ---> Kibana温馨提示:
- 1.filebeat默认是按行采集数据;
- 2.filebeat默认会在"/var/lib/filebeat"目录下记录已经采集的文件offset信息,以便于下一次采集接着该位置继续采集数据;七、EFK数据流走向初体验
1. 编写filebeat配置文件
# 编写配置文件
[root@elk92 ~]# vim /etc/filebeat/config/02-log-to-es.yaml
[root@elk92 ~]# cat /etc/filebeat/config/02-log-to-es.yaml
filebeat.inputs:
- type: log
paths:
- /tmp/student.log
# 将数据写入到ES集群
output.elasticsearch:
hosts:
- 10.0.0.91:9200
- 10.0.0.92:9200
- 10.0.0.93:9200
# 指定索引的名称
index: caofacan-linux-tmp-%{+yyyy.MM.dd}
# 禁用索引生命周期管理(index lifecycle management,ILM)
# 如果启用了此配置,则忽略自定义索引的所有信息
setup.ilm.enabled: false
# 定义索引模板(就是创建索引的规则)的名称
setup.template.name: "caofacan-linux"
# 定义索引模板的匹配模式,表示当前索引模板针对哪些索引生效。
setup.template.pattern: "caofacan-linux-*"
# 如果索引模板存在,是否覆盖,默认值为false,如果明确需要,则可以将其设置为ture。
# 但是官方建议将其设置为false,原因是每次写数据时,都会建立tcp链接,消耗资源。
setup.template.overwrite: true
# 定义索引模板的规则信息
setup.template.settings:
# 指定索引能够创建的分片的数量
index.number_of_shards: 5
# 指定每个分片有多少个副本
index.number_of_replicas: 0
[root@elk92 ~]# rm -rf /var/lib/filebeat/
[root@elk92 ~]# filebeat -e -c /etc/filebeat/config/02-log-to-es.yaml 这里我们去Kibana查看我们的数据
流程依旧是先找到Stack Managerment---->点击索引模式----->创建我们的索引模式---->找到我们编写的filebeat的yml对应的索引名称---->再去discover查看我们的监控的/tmp/student.log的文件变化
找不到可以参考我们Kibana部署时走的流程,这里不再赘述.
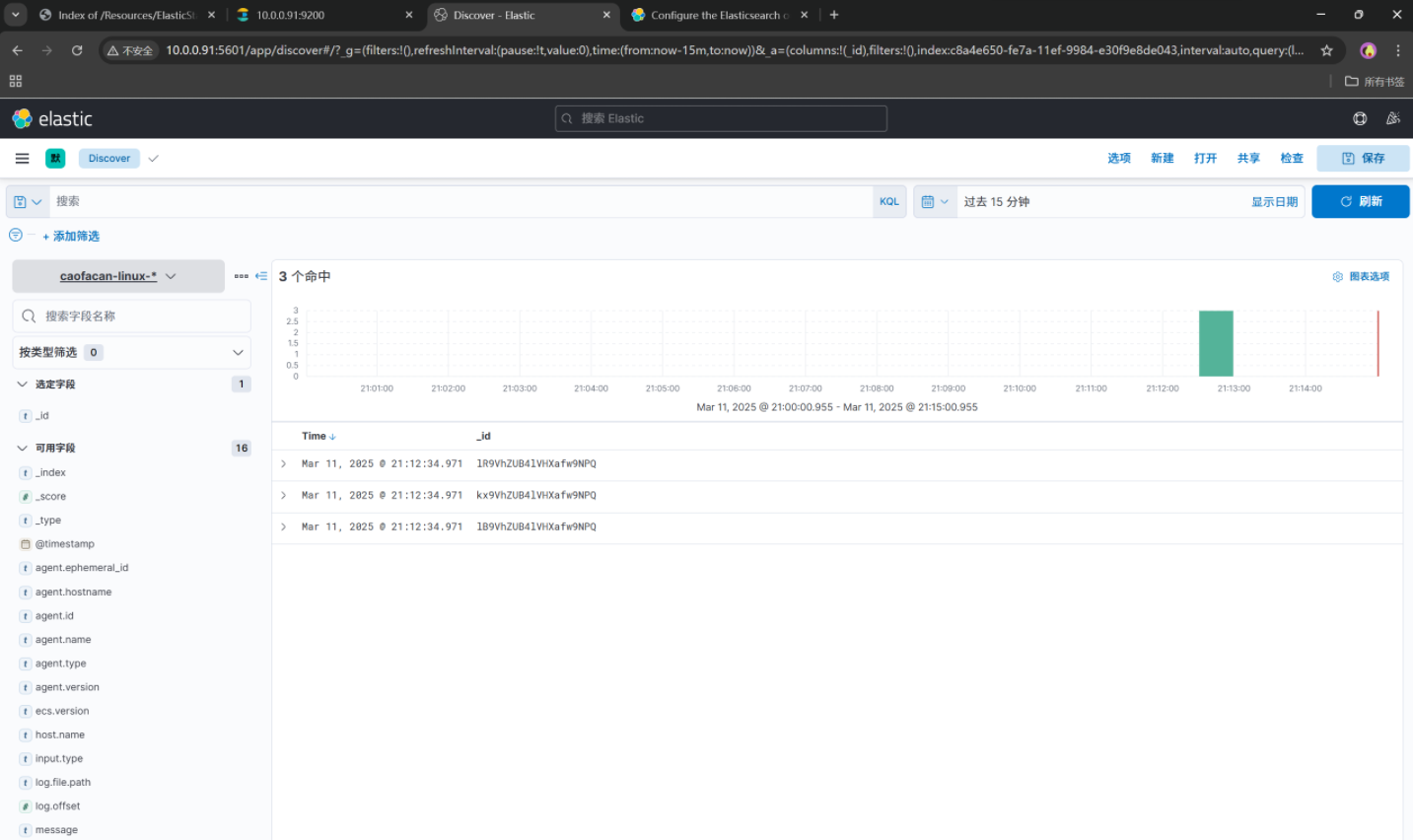
设置一秒刷新,不要我们手动刷新了
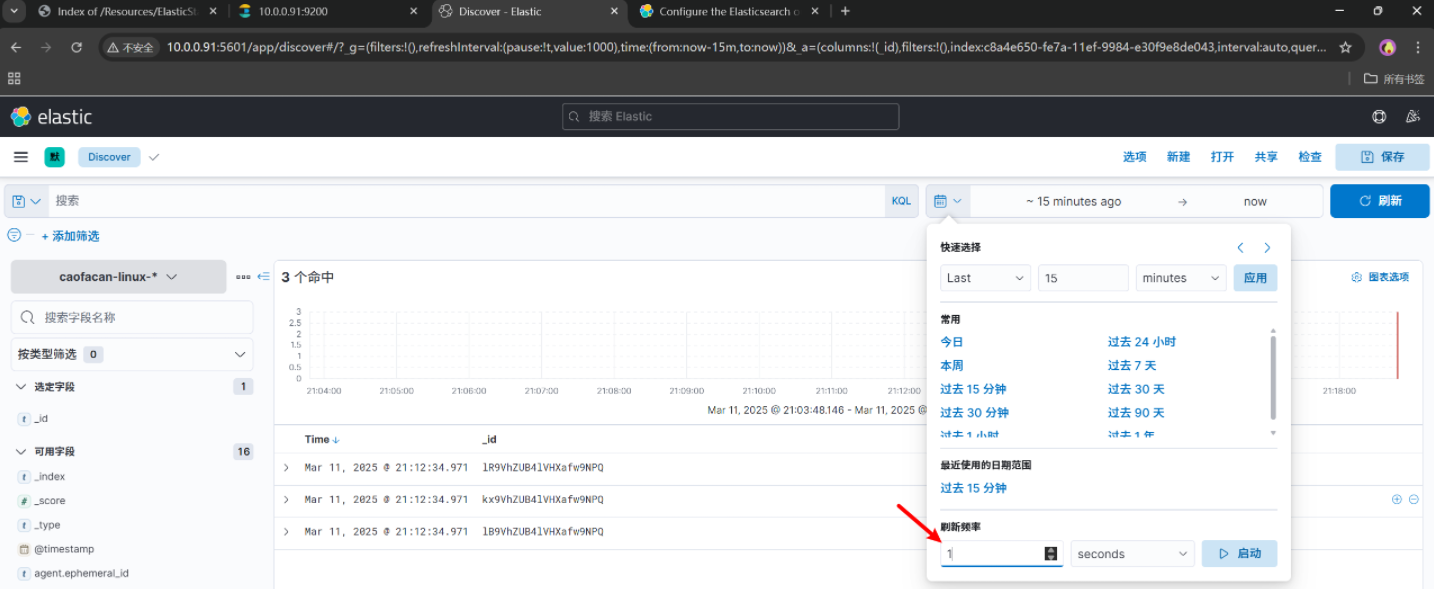
八、项目案例filebeat采集nginx实战案例
1. 安装NGINX服务
# 安装nginx服务
[root@elk92 ~]# apt install nginx -y
# 启动nginx
[root@elk92 ~]# systemctl enable --now nginx
# 访问nginx
[root@elk92 ~]# curl localhost
<!DOCTYPE html>
.......
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
.......
<p><em>Thank you for using nginx.</em></p>
</body>
</html>2. 编写filebeat配置
# 让我们的Filebeat检测我们的nginx访问日志
[root@elk92 ~]# vim 03-nginxlog-to-es.yaml
[root@elk92 ~]# cat 03-nginxlog-to-es.yaml
filebeat.inputs:
- type: log
paths:
- /var/log/nginx/access.log*
# 将数据写入到ES集群
output.elasticsearch:
hosts:
- 10.0.0.91:9200
- 10.0.0.92:9200
- 10.0.0.93:9200
# 指定索引的名称
index: nginx92-log-tmp-%{+yyyy.MM.dd}
# 禁用索引生命周期管理(index lifecycle management,ILM)
# 如果启用了此配置,则忽略自定义索引的所有信息
setup.ilm.enabled: false
# 定义索引模板(就是创建索引的规则)的名称
setup.template.name: "nginx92-log"
# 定义索引模板的匹配模式,表示当前索引模板针对哪些索引生效。
setup.template.pattern: "nginx92-log-*"
# 如果索引模板存在,是否覆盖,默认值为false,如果明确需要,则可以将其设置为ture。
# 但是官方建议将其设置为false,原因是每次写数据时,都会建立tcp链接,消耗资源。
setup.template.overwrite: true
# 定义索引模板的规则信息
setup.template.settings:
# 指定索引能够创建的分片的数量
index.number_of_shards: 3
# 指定每个分片有多少个副本
index.number_of_replicas: 1
# 启动Filebeta实例
[root@elk92 ~]# filebeat -e -c /etc/filebeat/config/03-nginxlog-to-es.yaml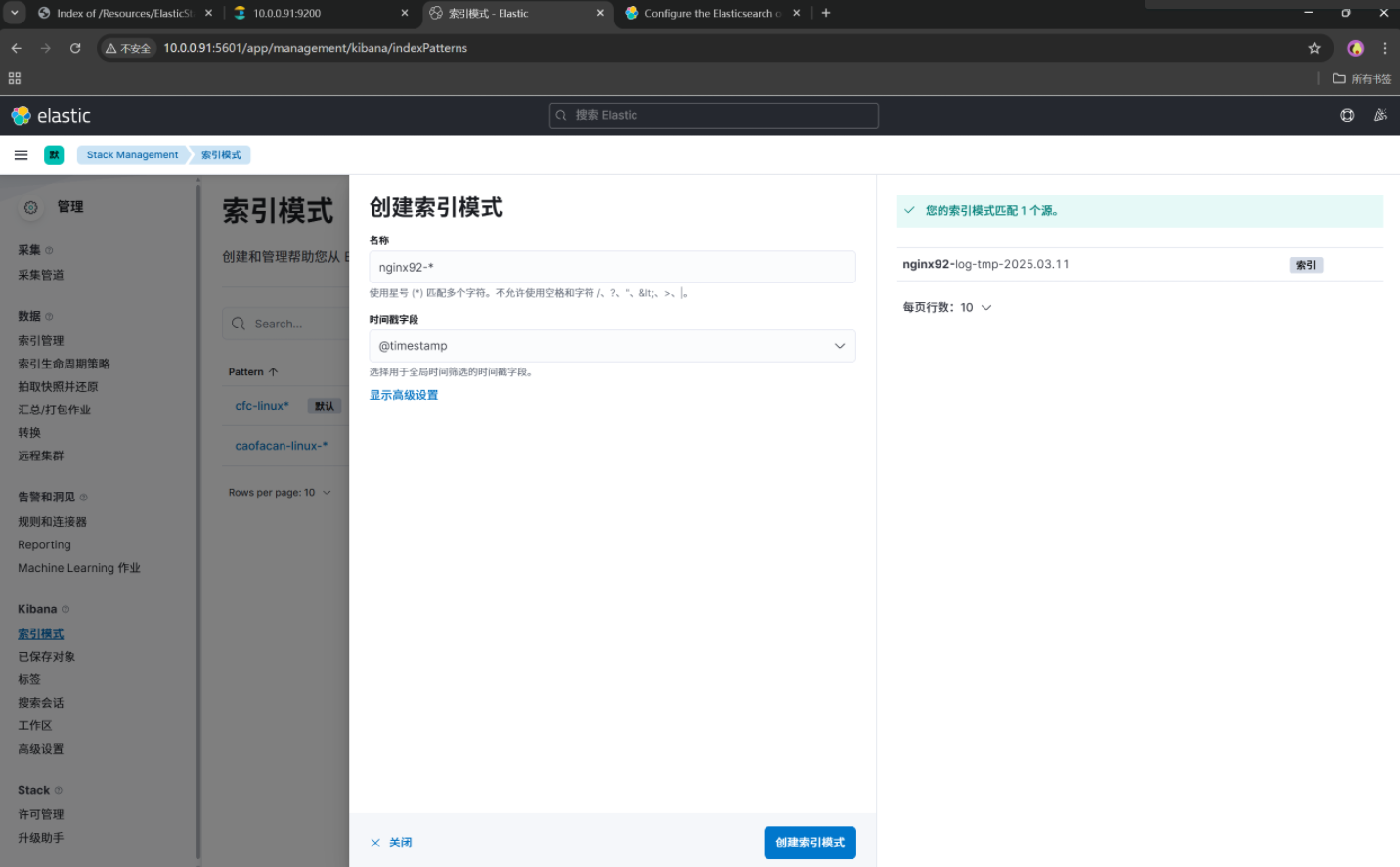
 3. 整点访问数据
3. 整点访问数据
浏览器访问一下
http://10.0.0.92/
其他节点访问一下
[root@elk91 ~]# curl 10.0.0.92
自己访问几十下
[root@elk92 ~]# for i in `seq 50`;do curl 10.0.0.92;done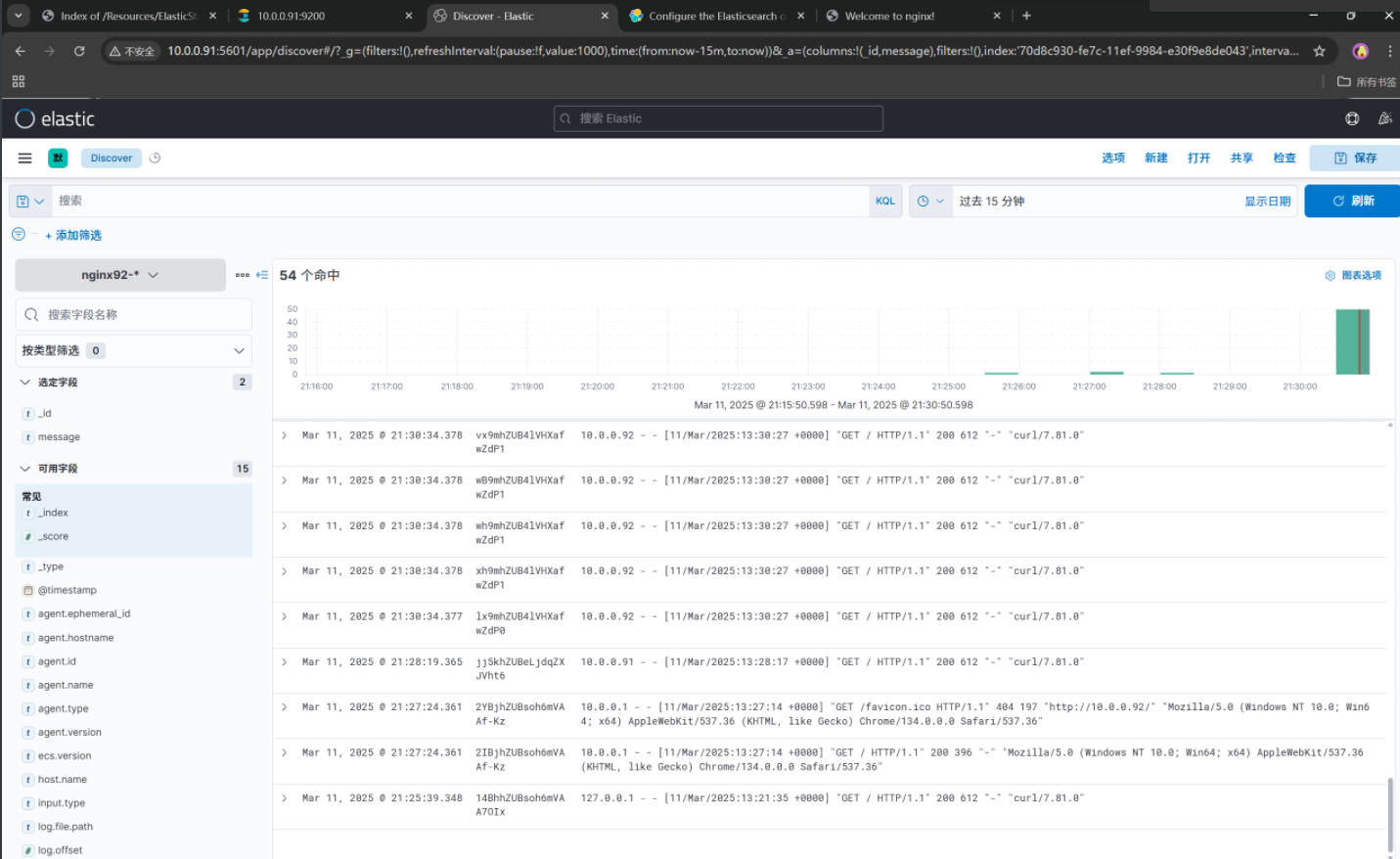
九、filebeat多实例
1.启动实例1
filebeat -e -c /etc/filebeat/config/01-log-to-console.yaml --path.data /tmp/xixi
2.启动实例2
filebeat -e -c /etc/filebeat/config/02-log-to-es.yaml --path.data /tmp/haha
只要数据目录不同即可。1.使用Filebeat采集ES集群所有节点系统日志
采集所以的ES集群那么就要在三个节点安装Filebeat,然后执行。
- /var/log/syslog
- /var/log/auth.log2. 编写第一个filebeat采集syslog日志
[root@elk92 ~]# cat /etc/filebeat/config/04-elk92-syslog-to-es.yml
filebeat.inputs:
- type: log
paths:
- /var/log/syslog
# 将数据写入到ES集群
output.elasticsearch:
hosts:
- 10.0.0.91:9200
- 10.0.0.92:9200
- 10.0.0.93:9200
# 指定索引的名称
index: elk92-syslog-%{+yyyy.MM.dd}
# 禁用索引生命周期管理(index lifecycle management,ILM)
# 如果启用了此配置,则忽略自定义索引的所有信息
setup.ilm.enabled: false
# 定义索引模板(就是创建索引的规则)的名称
setup.template.name: "elk92-syslog"
# 定义索引模板的匹配模式,表示当前索引模板针对哪些索引生效。
setup.template.pattern: "elk92-syslog-*"
# 如果索引模板存在,是否覆盖,默认值为false,如果明确需要,则可以将其设置为ture。
# 但是官方建议将其设置为false,原因是每次写数据时,都会建立tcp链接,消耗资源。
setup.template.overwrite: true
# 定义索引模板的规则信息
setup.template.settings:
# 指定索引能够创建的分片的数量
index.number_of_shards: 3
# 指定每个分片有多少个副本
index.number_of_replicas: 1
# 启动Filebeat
[root@elk92 ~]# filebeat -e -c /etc/filebeat/config/04-elk92-syslog-to-es.yml --path.data /tmp/elk-syslog2. 编写第二个filebeat采集auth.log日志
[root@elk92 ~]# cat /etc/filebeat/config/05-elk92-authlog-to-es.yml
filebeat.inputs:
- type: log
paths:
- /var/log/auth.log
# 将数据写入到ES集群
output.elasticsearch:
hosts:
- 10.0.0.91:9200
- 10.0.0.92:9200
- 10.0.0.93:9200
# 指定索引的名称
index: elk92-authlog-%{+yyyy.MM.dd}
# 禁用索引生命周期管理(index lifecycle management,ILM)
# 如果启用了此配置,则忽略自定义索引的所有信息
setup.ilm.enabled: false
# 定义索引模板(就是创建索引的规则)的名称
setup.template.name: "elk92-authlog"
# 定义索引模板的匹配模式,表示当前索引模板针对哪些索引生效。
setup.template.pattern: "elk92-authlog-*"
# 如果索引模板存在,是否覆盖,默认值为false,如果明确需要,则可以将其设置为ture。
# 但是官方建议将其设置为false,原因是每次写数据时,都会建立tcp链接,消耗资源。
setup.template.overwrite: true
# 定义索引模板的规则信息
setup.template.settings:
# 指定索引能够创建的分片的数量
index.number_of_shards: 3
# 指定每个分片有多少个副本
index.number_of_replicas: 1
# 启动Filebeat
[root@elk92 ~]# filebeat -e -c /etc/filebeat/config/05-elk92-authlog-to-es.yml --path.data /tmp/elk-authlog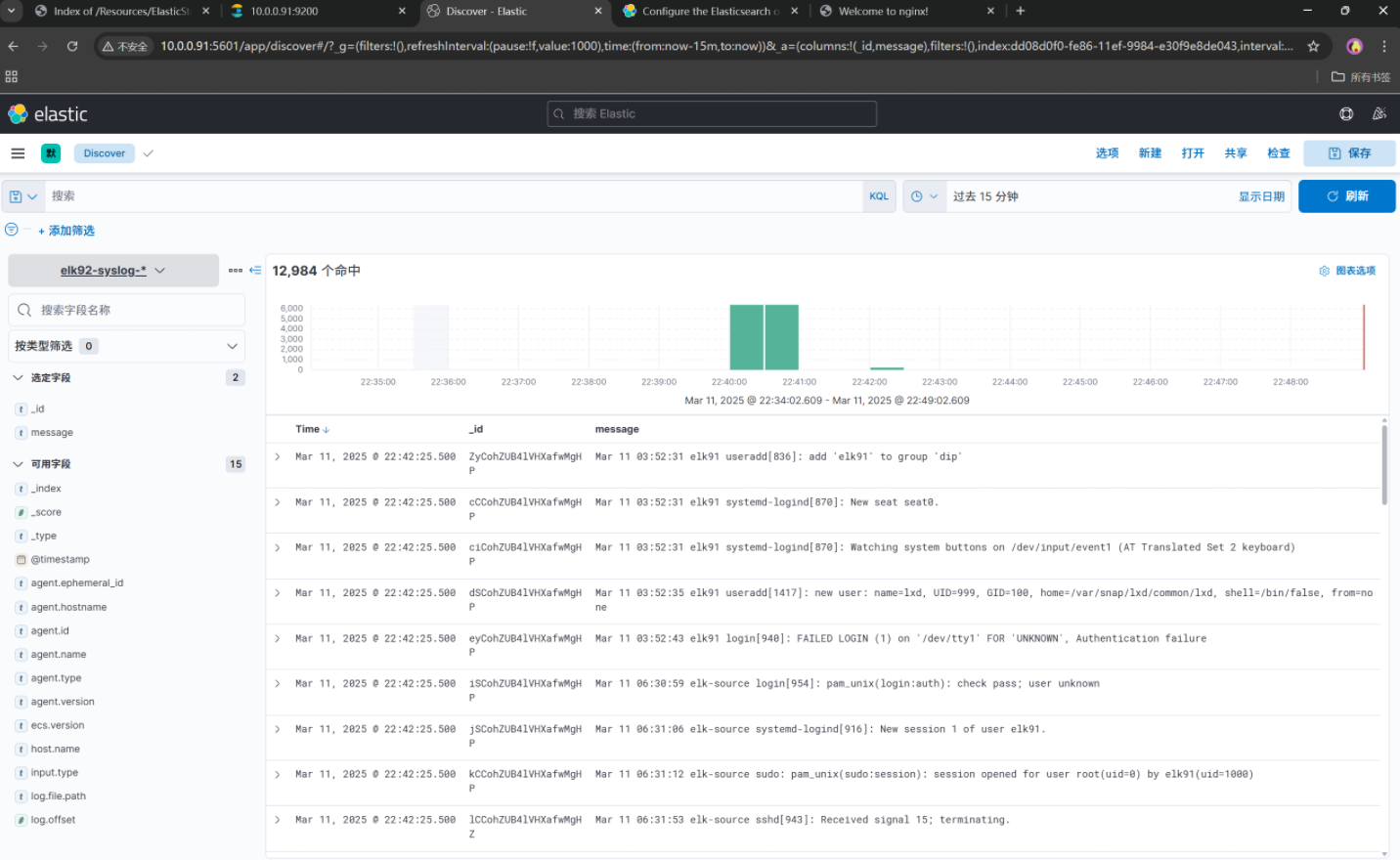
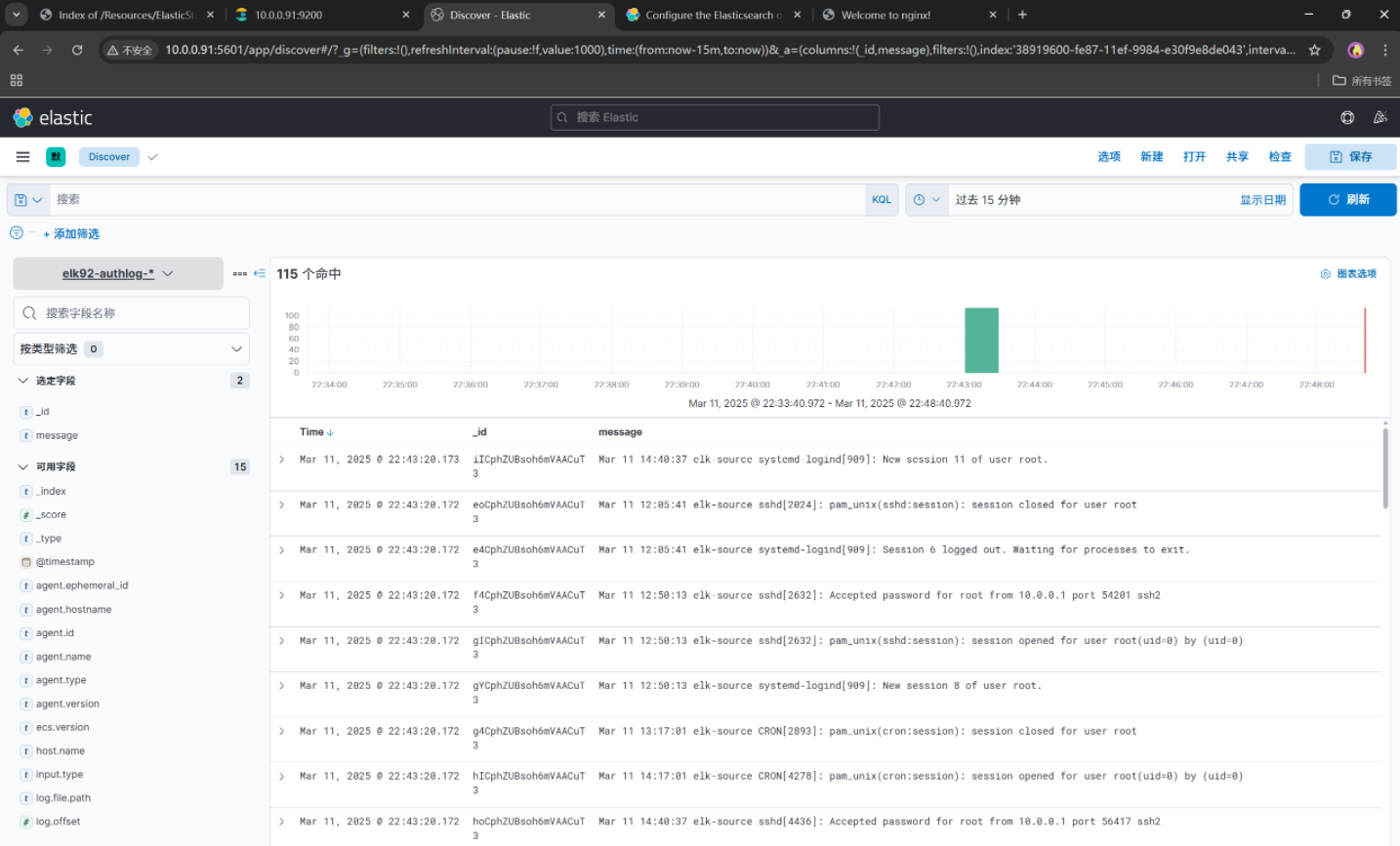
十、总结
EFK 指的是 Elasticsearch、Filebeat 和 Kibana 这三个工具组合。
Elasticsearch 是一个基于 Lucene 构建的开源、分布式、高性能的全文搜索引擎,能够快速存储、搜索和分析大量数据,为数据的检索和分析提供强大的引擎支持。
Filebeat 属于 Beats 系列,它是一款轻量级的数据采集器。主要负责从各种日志文件中收集日志数据,然后将其发送到 Elasticsearch 或 Logstash(数据处理工具)进行后续处理,起到数据传输的桥梁作用。
Kibana 则是一个开源的数据可视化平台,它与 Elasticsearch 紧密集成,能够直观地展示 Elasticsearch 中的数据。通过 Kibana,用户可以创建各种图表、仪表盘,方便对数据进行分析和监测。
EFK 组合在日志管理和分析、数据监控等领域广泛应用,帮助用户高效地处理和理解大量数据。








![[MySQL初阶]MySQL(7) 表的内外连接](https://i-blog.csdnimg.cn/direct/d7158761e5f4465c81ae59cdc52428af.png#pic_center)
