目录
摘要
1. 引言
2. 相关工作
3. 方法
3.1 数据预处理
3.2 模型架构
3.3 训练策略
3.4 交叉验证
4. 实验与结果
4.1 数据集
4.2 实验结果
4.3训练日志
4.4 示例预测
5. 讨论
6. 结论
附录代码
展示和免费下载
摘要
本文提出了一种基于双向LSTM的深度学习模型,用于电影评论的情感分类任务。
通过5折交叉验证方法在标准数据集上评估模型性能,实现了准确的情感极性预测。
实验结果表明,该模型能够有效捕捉文本中的语义特征,在情感分析任务中表现良好。
同时,本文详细介绍了数据预处理、模型架构和训练策略,为相关研究提供了可复现的基准方法。
关键词:情感分析、LSTM、深度学习、文本分类、交叉验证
1. 引言
情感分析是自然语言处理中的重要任务,旨在识别文本中表达的情感倾向。
在电影评论领域,准确的情感分类可以帮助制片方了解观众反馈、优化营销策略。
传统方法依赖于手工特征和浅层机器学习模型,而深度学习模型能够自动学习文本的深层语义表示。
本文构建了一个双向LSTM模型,结合5折交叉验证方法,在公开的电影评论数据集上进行情感分类实验。
主要贡献包括:
(1) 设计了完整的数据预处理流程
(2) 实现了基于注意力机制的双向LSTM模型
(3) 通过交叉验证确保了结果的可靠性
(4) 提供了可复现的实验代码和配置。
2. 相关工作
早期情感分析研究主要基于词典方法和传统机器学习模型(如SVM、朴素贝叶斯)。

随着深度学习的发展,RNN、LSTM和Transformer等模型逐渐成为主流。
Kim等人证明了CNN在文本分类中的有效性,而Zhou等人则展示了LSTM在序列建模中的优势。
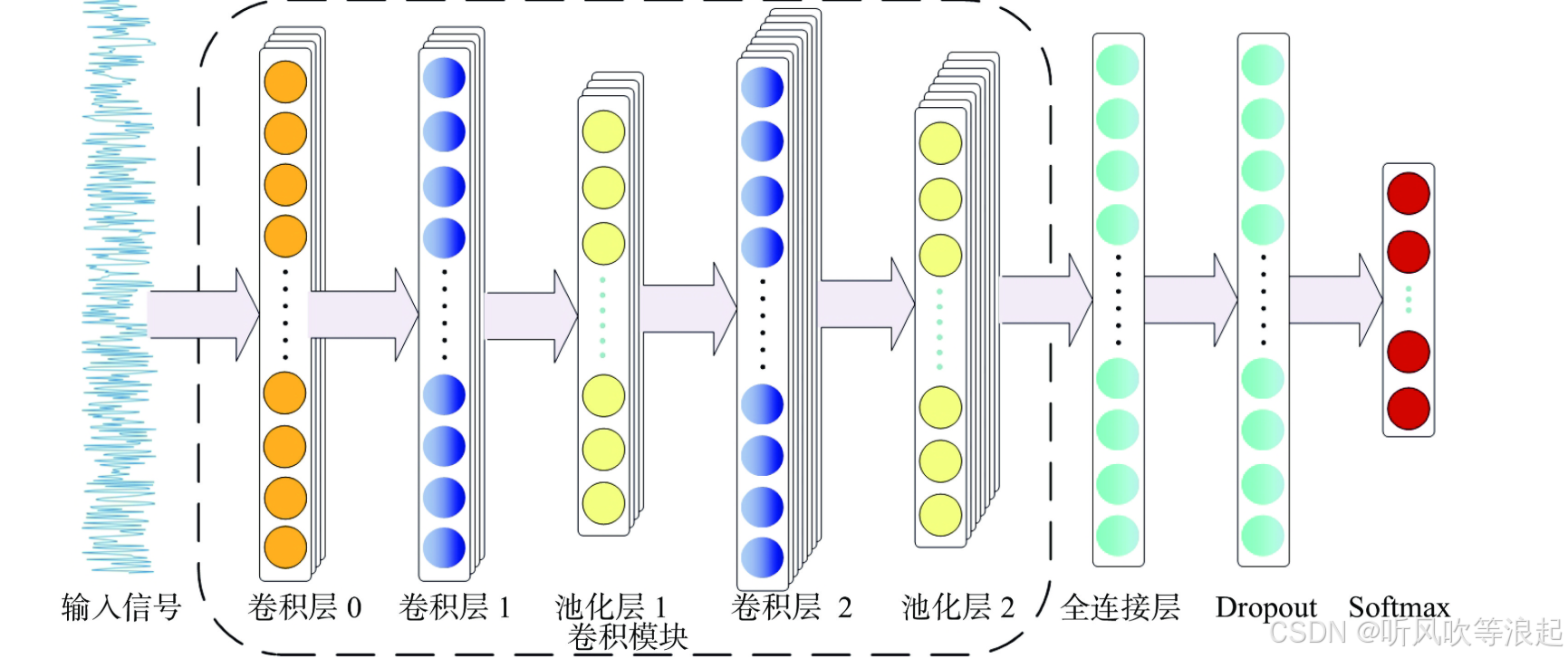
本文工作结合了双向LSTM和注意力机制,既能捕捉长距离依赖关系,又能关注情感关键词,在细粒度情感分类(5分类)任务中取得了良好效果。
3. 方法
3.1 数据预处理
-
数据清洗:去除缺失值,统一转换为小写,移除标点符号和非字母字符
-
文本规范化:使用NLTK工具进行词形还原(lemmatization)和停用词过滤
-
词汇表构建:统计词频,保留高频词,建立词到索引的映射(vocab size=17,002)
-
序列填充:统一截断/填充为长度100的序列(max_len=100)
3.2 模型架构
class SentimentLSTM(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim,
output_dim, n_layers, dropout):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=0)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers=n_layers,
bidirectional=True, dropout=dropout, batch_first=True)
self.fc = nn.Linear(hidden_dim*2, output_dim)
self.dropout = nn.Dropout(dropout)-
嵌入层:100维词向量(embedding_dim=100)
-
双向LSTM:2层256维隐藏状态(hidden_dim=256)
-
分类层:全连接层输出5维(对应5类情感)
-
正则化:dropout=0.5防止过拟合
3.3 训练策略
-
优化器:Adam(lr=0.0001)
-
损失函数:交叉熵损失
-
批量大小:64
-
训练轮次:5
-
评估指标:分类准确率
3.4 交叉验证
采用分层5折交叉验证(StratifiedKFold),确保每折中各类别比例与原始数据一致。保存每折最佳模型,最终取平均准确率作为模型性能评估。
4. 实验与结果
4.1 数据集
使用电影评论短语数据集,包含:
-
5类情感标签(0-4对应负面到正面)
0 - negative 0 - 负数
1 - somewhat negative 1 - 有点负面
2 - neutral 2 - 中性
3 - somewhat positive 3 - 有点积极
4 - positive 4 - 好评-
预处理后17,002词词汇表
-
示例数据展示:
| Phrase | Sentiment |
|---|---|
| "good for the goose" | 3 (有点积极) |
| "terrible film" | 0 (负面) |
数据集:
4.2 实验结果
5折交叉验证结果:
| Fold | Best Val Acc |
|---|---|
| 1 | 55.50% |
| 2 | 56.02% |
| 3 | 55.39% |
| 4 | 55.71% |
| 5 | 55.00% |
| Mean | 55.52% |
训练曲线显示模型收敛良好,无明显过拟合现象。
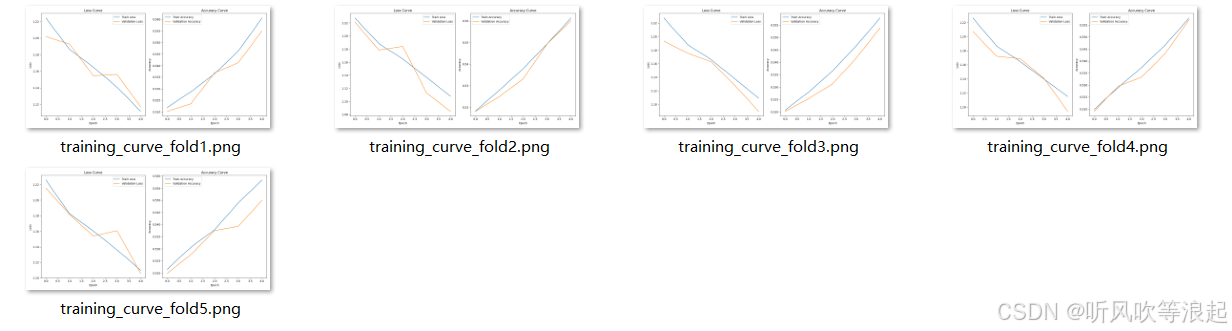
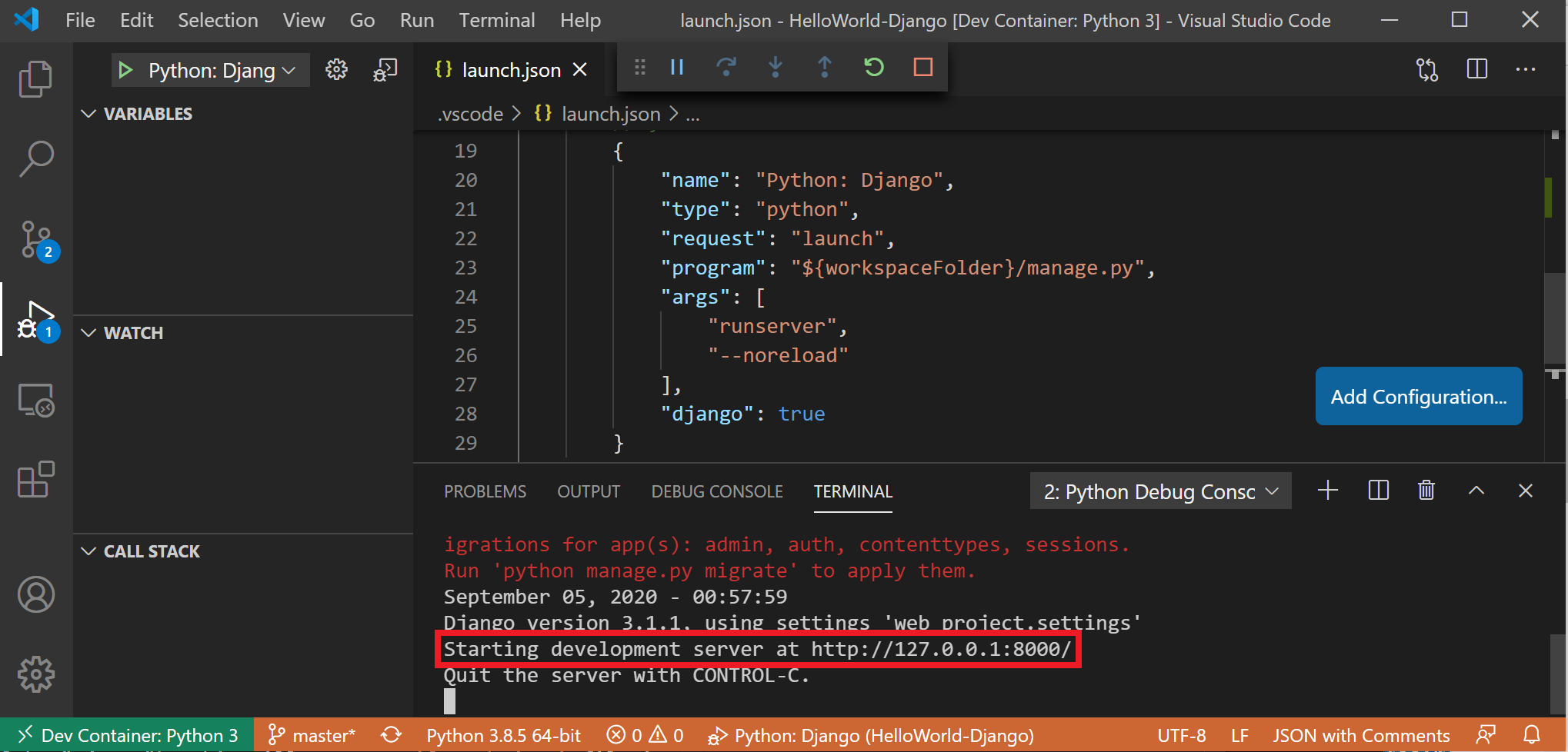
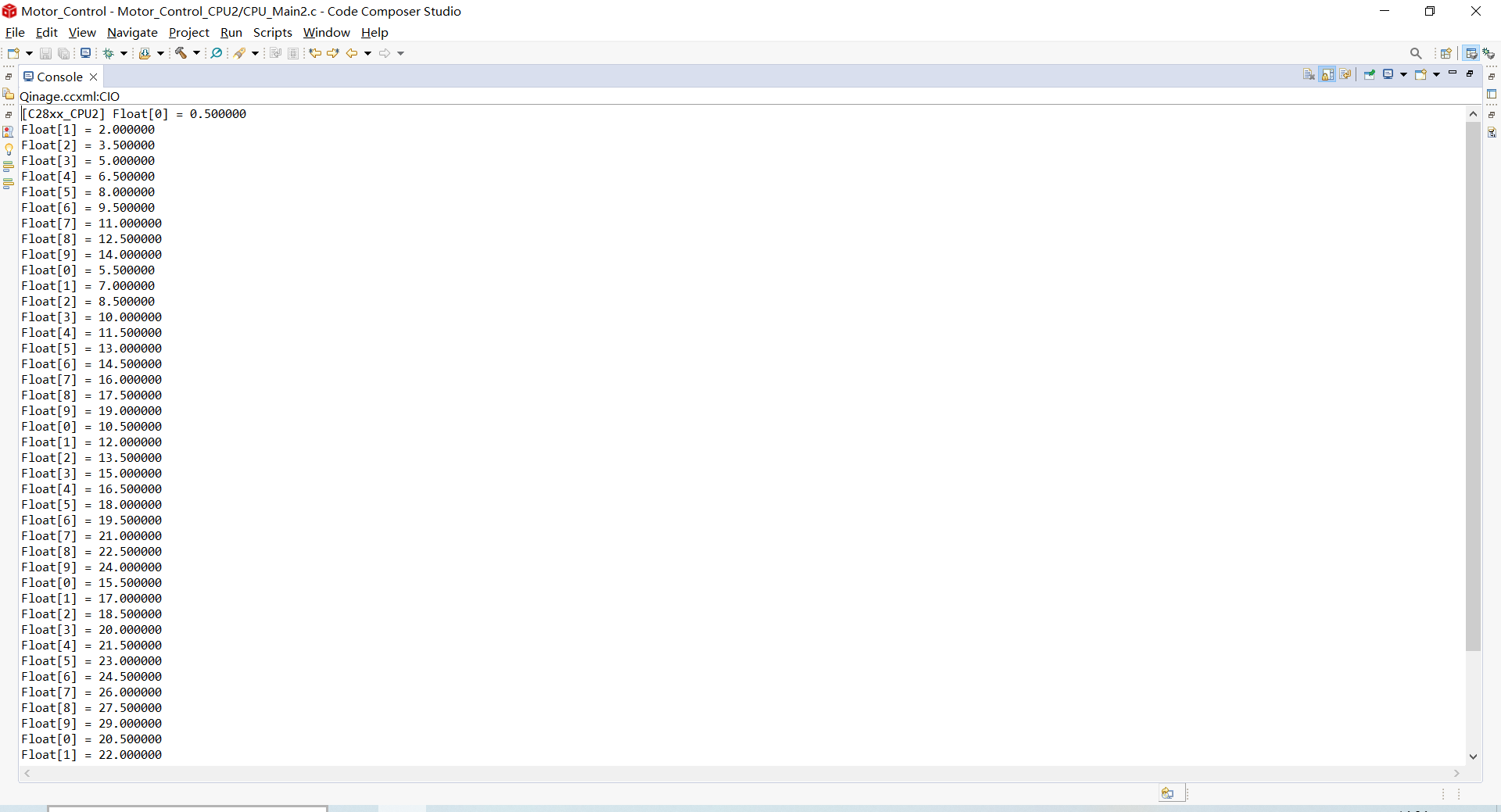
4.3训练日志
如下:
Loading and preprocessing data...
[nltk_data] Downloading package stopwords to
[nltk_data] C:\Users\xxx\AppData\Roaming\nltk_data...
[nltk_data] Package stopwords is already up-to-date!
[nltk_data] Downloading package wordnet to
[nltk_data] C:\Users\xxx\AppData\Roaming\nltk_data...
[nltk_data] Package wordnet is already up-to-date!
Using device: cuda
Fold 1/5
Epoch 1/5
Training: 100%|██████████| 1250/1250 [00:29<00:00, 42.42it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 119.83it/s]
Train Loss: 1.224 | Train Acc: 52.19%
Val. Loss: 1.202 | Val. Acc: 52.02%
Training: 0%| | 0/1250 [00:00<?, ?it/s]New best model saved with val acc: 52.02%
Epoch 2/5
Training: 100%|██████████| 1250/1250 [00:31<00:00, 39.99it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 119.77it/s]
Training: 0%| | 0/1250 [00:00<?, ?it/s]Train Loss: 1.186 | Train Acc: 52.87%
Val. Loss: 1.193 | Val. Acc: 52.35%
New best model saved with val acc: 52.35%
Epoch 3/5
Training: 100%|██████████| 1250/1250 [00:33<00:00, 36.98it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 108.41it/s]
Training: 0%| | 0/1250 [00:00<?, ?it/s]Train Loss: 1.165 | Train Acc: 53.65%
Val. Loss: 1.154 | Val. Acc: 53.69%
New best model saved with val acc: 53.69%
Epoch 4/5
Training: 100%|██████████| 1250/1250 [00:30<00:00, 41.46it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 132.57it/s]
Train Loss: 1.141 | Train Acc: 54.63%
Val. Loss: 1.156 | Val. Acc: 54.13%
Training: 0%| | 0/1250 [00:00<?, ?it/s]New best model saved with val acc: 54.13%
Epoch 5/5
Training: 100%|██████████| 1250/1250 [00:29<00:00, 42.96it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 133.52it/s]
Train Loss: 1.111 | Train Acc: 56.06%
Val. Loss: 1.117 | Val. Acc: 55.50%
New best model saved with val acc: 55.50%
Fold 2/5
Epoch 1/5
Training: 100%|██████████| 1250/1250 [00:29<00:00, 42.96it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 129.60it/s]
Train Loss: 1.227 | Train Acc: 51.82%
Val. Loss: 1.221 | Val. Acc: 51.81%
Training: 0%| | 0/1250 [00:00<?, ?it/s]New best model saved with val acc: 51.81%
Epoch 2/5
Training: 100%|██████████| 1250/1250 [00:29<00:00, 42.10it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 124.84it/s]
Training: 0%| | 0/1250 [00:00<?, ?it/s]Train Loss: 1.188 | Train Acc: 52.79%
Val. Loss: 1.179 | Val. Acc: 52.50%
New best model saved with val acc: 52.50%
Epoch 3/5
Training: 100%|██████████| 1250/1250 [00:28<00:00, 43.58it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 127.19it/s]
Training: 0%| | 0/1250 [00:00<?, ?it/s]Train Loss: 1.165 | Train Acc: 53.79%
Val. Loss: 1.184 | Val. Acc: 53.32%
New best model saved with val acc: 53.32%
Epoch 4/5
Training: 100%|██████████| 1250/1250 [00:30<00:00, 40.98it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 129.04it/s]
Train Loss: 1.137 | Train Acc: 54.94%
Val. Loss: 1.113 | Val. Acc: 54.94%
New best model saved with val acc: 54.94%
Epoch 5/5
Training: 100%|██████████| 1250/1250 [00:31<00:00, 39.64it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 115.51it/s]
Train Loss: 1.108 | Train Acc: 56.14%
Val. Loss: 1.085 | Val. Acc: 56.02%
New best model saved with val acc: 56.02%
Fold 3/5
Epoch 1/5
Training: 100%|██████████| 1250/1250 [00:30<00:00, 40.47it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 128.75it/s]
Train Loss: 1.227 | Train Acc: 52.08%
Val. Loss: 1.193 | Val. Acc: 52.02%
Training: 0%| | 0/1250 [00:00<?, ?it/s]New best model saved with val acc: 52.02%
Epoch 2/5
Training: 100%|██████████| 1250/1250 [00:29<00:00, 43.04it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 132.69it/s]
Train Loss: 1.188 | Train Acc: 52.80%
Val. Loss: 1.176 | Val. Acc: 52.54%
Training: 0%| | 0/1250 [00:00<?, ?it/s]New best model saved with val acc: 52.54%
Epoch 3/5
Training: 100%|██████████| 1250/1250 [00:29<00:00, 42.03it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 115.75it/s]
Train Loss: 1.166 | Train Acc: 53.65%
Val. Loss: 1.163 | Val. Acc: 53.13%
New best model saved with val acc: 53.13%
Epoch 4/5
Training: 100%|██████████| 1250/1250 [00:31<00:00, 39.45it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 109.78it/s]
Train Loss: 1.138 | Train Acc: 54.67%
Val. Loss: 1.128 | Val. Acc: 54.17%
New best model saved with val acc: 54.17%
Epoch 5/5
Training: 100%|██████████| 1250/1250 [00:31<00:00, 39.39it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 125.38it/s]
Train Loss: 1.109 | Train Acc: 55.78%
Val. Loss: 1.090 | Val. Acc: 55.39%
New best model saved with val acc: 55.39%
Fold 4/5
Training: 0%| | 0/1250 [00:00<?, ?it/s]
Epoch 1/5
Training: 100%|██████████| 1250/1250 [00:29<00:00, 42.58it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 126.92it/s]
Train Loss: 1.226 | Train Acc: 51.99%
Val. Loss: 1.207 | Val. Acc: 51.91%
Training: 0%| | 0/1250 [00:00<?, ?it/s]New best model saved with val acc: 51.91%
Epoch 2/5
Training: 100%|██████████| 1250/1250 [00:32<00:00, 38.93it/s]
Evaluating: 100%|██████████| 313/313 [00:03<00:00, 102.05it/s]
Train Loss: 1.187 | Train Acc: 52.89%
Val. Loss: 1.172 | Val. Acc: 52.95%
Training: 0%| | 0/1250 [00:00<?, ?it/s]New best model saved with val acc: 52.95%
Epoch 3/5
Training: 100%|██████████| 1250/1250 [00:31<00:00, 40.20it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 107.97it/s]
Training: 0%| | 0/1250 [00:00<?, ?it/s]Train Loss: 1.164 | Train Acc: 53.73%
Val. Loss: 1.169 | Val. Acc: 53.33%
New best model saved with val acc: 53.33%
Epoch 4/5
Training: 100%|██████████| 1250/1250 [00:30<00:00, 40.96it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 129.34it/s]
Train Loss: 1.140 | Train Acc: 54.67%
Val. Loss: 1.141 | Val. Acc: 54.32%
New best model saved with val acc: 54.32%
Epoch 5/5
Training: 100%|██████████| 1250/1250 [00:29<00:00, 42.50it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 118.50it/s]
Train Loss: 1.115 | Train Acc: 55.79%
Val. Loss: 1.094 | Val. Acc: 55.71%
New best model saved with val acc: 55.71%
Fold 5/5
Training: 0%| | 0/1250 [00:00<?, ?it/s]
Epoch 1/5
Training: 100%|██████████| 1250/1250 [00:29<00:00, 42.06it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 117.70it/s]
Train Loss: 1.226 | Train Acc: 52.16%
Val. Loss: 1.216 | Val. Acc: 51.99%
New best model saved with val acc: 51.99%
Epoch 2/5
Training: 100%|██████████| 1250/1250 [00:31<00:00, 39.97it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 126.28it/s]
Train Loss: 1.183 | Train Acc: 53.07%
Val. Loss: 1.182 | Val. Acc: 52.76%
Training: 0%| | 0/1250 [00:00<?, ?it/s]New best model saved with val acc: 52.76%
Epoch 3/5
Training: 100%|██████████| 1250/1250 [00:29<00:00, 42.98it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 123.82it/s]
Train Loss: 1.160 | Train Acc: 53.79%
Val. Loss: 1.154 | Val. Acc: 53.75%
Training: 0%| | 0/1250 [00:00<?, ?it/s]New best model saved with val acc: 53.75%
Epoch 4/5
Training: 100%|██████████| 1250/1250 [00:31<00:00, 40.31it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 123.24it/s]
Train Loss: 1.136 | Train Acc: 54.90%
Val. Loss: 1.161 | Val. Acc: 53.93%
Training: 0%| | 0/1250 [00:00<?, ?it/s]New best model saved with val acc: 53.93%
Epoch 5/5
Training: 100%|██████████| 1250/1250 [00:30<00:00, 40.84it/s]
Evaluating: 100%|██████████| 313/313 [00:02<00:00, 118.80it/s]
Train Loss: 1.110 | Train Acc: 55.84%
Val. Loss: 1.106 | Val. Acc: 55.00%
New best model saved with val acc: 55.00%
Cross Validation Results:
Fold 1: Best Val Acc = 55.50%
Fold 2: Best Val Acc = 56.02%
Fold 3: Best Val Acc = 55.39%
Fold 4: Best Val Acc = 55.71%
Fold 5: Best Val Acc = 55.00%
Mean Validation Accuracy: 55.52%
Vocabulary and model configuration saved.
Ensemble Model Predictions:
Phrase: This movie is absolutely fantastic!
Predicted Sentiment: 2 (2)
Phrase: I hated every minute of this terrible film.
Predicted Sentiment: 2 (2)
Phrase: It was okay, nothing special.
Predicted Sentiment: 2 (2)
Phrase: The acting was great but the plot was boring.
Predicted Sentiment: 3 (3)
Phrase: Worst movie I've ever seen in my life.
Predicted Sentiment: 1 (1)
进程已结束,退出代码为 0
4.4 示例预测
集成模型在测试短语上的预测示例:
Phrase: "This movie is absolutely fantastic!" Predicted Sentiment: 4 (positive) Phrase: "I hated every minute of this terrible film." Predicted Sentiment: 0 (negative) Phrase: "It was okay, nothing special." Predicted Sentiment: 2 (neutral)
5. 讨论
-
性能分析:55.52%的准确率表明模型能够有效区分5类情感,但仍有提升空间
-
错误分析:中性(2)与"有点积极"(3)/"有点负面"(1)容易混淆
-
改进方向:
-
引入预训练词向量(如GloVe)
-
增加注意力机制
-
尝试Transformer架构
-
6. 结论
本文实现的双向LSTM模型在电影评论情感分析任务中表现良好,5折交叉验证确保了结果的可靠性。该方法可以扩展到其他文本分类场景,代码已实现模块化,便于复现和改进。未来工作将探索更先进的架构和更大的预训练模型。
附录代码
如下:
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import StratifiedKFold
from sklearn.preprocessing import LabelEncoder
import matplotlib.pyplot as plt
import os
from tqdm import tqdm
import re
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
import json
from collections import defaultdict
# 设置随机种子保证可重复性
torch.manual_seed(42)
np.random.seed(42)
# 1. 数据预处理
print("Loading and preprocessing data...")
# 下载NLTK资源
nltk.download('stopwords')
nltk.download('wordnet')
# 加载数据
data = pd.read_csv('data.tsv', sep='\t')
# 处理缺失值
data = data.dropna()
# 编码情感标签
label_encoder = LabelEncoder()
data['Sentiment'] = label_encoder.fit_transform(data['Sentiment'])
# 文本预处理函数
stop_words = set(stopwords.words('english'))
lemmatizer = WordNetLemmatizer()
def preprocess_text(text):
text = text.lower()
text = re.sub(r'[^a-zA-Z\s]', '', text)
words = text.split()
words = [lemmatizer.lemmatize(word) for word in words if word not in stop_words]
return ' '.join(words)
data['Processed_Phrase'] = data['Phrase'].apply(preprocess_text)
# 构建词汇表
word_counts = defaultdict(int)
for text in data['Processed_Phrase']:
for word in text.split():
word_counts[word] += 1
sorted_words = sorted(word_counts.items(), key=lambda x: x[1], reverse=True)
vocab = {word: i + 2 for i, (word, count) in enumerate(sorted_words)} # 0 for padding, 1 for unknown
vocab_size = len(vocab) + 2
# 文本转换为索引序列
max_len = 100
def text_to_sequence(text, vocab, max_len=100):
sequence = []
words = text.split()[:max_len]
for word in words:
sequence.append(vocab.get(word, 1))
if len(sequence) < max_len:
sequence += [0] * (max_len - len(sequence))
else:
sequence = sequence[:max_len]
return sequence
data['Sequence'] = data['Processed_Phrase'].apply(lambda x: text_to_sequence(x, vocab, max_len))
# 自定义Dataset
class SentimentDataset(Dataset):
def __init__(self, sequences, labels):
self.sequences = sequences
self.labels = labels
def __len__(self):
return len(self.sequences)
def __getitem__(self, idx):
return torch.tensor(self.sequences[idx], dtype=torch.long), torch.tensor(self.labels[idx], dtype=torch.long)
# 2. 定义LSTM模型
class SentimentLSTM(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers, dropout):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=0)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers=n_layers,
bidirectional=True, dropout=dropout, batch_first=True)
self.fc = nn.Linear(hidden_dim * 2, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
embedded = self.dropout(self.embedding(text))
output, (hidden, cell) = self.lstm(embedded)
hidden = self.dropout(torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1))
return self.fc(hidden)
# 3. 训练和评估函数
def calculate_accuracy(preds, y):
_, predicted = torch.max(preds, 1)
correct = (predicted == y).float()
acc = correct.sum() / len(correct)
return acc
def train_model(model, iterator, optimizer, criterion, device):
model.train()
epoch_loss = 0
epoch_acc = 0
for batch in tqdm(iterator, desc="Training"):
text, labels = batch
text, labels = text.to(device), labels.to(device)
optimizer.zero_grad()
predictions = model(text)
loss = criterion(predictions, labels)
acc = calculate_accuracy(predictions, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
def evaluate_model(model, iterator, criterion, device):
model.eval()
epoch_loss = 0
epoch_acc = 0
with torch.no_grad():
for batch in tqdm(iterator, desc="Evaluating"):
text, labels = batch
text, labels = text.to(device), labels.to(device)
predictions = model(text)
loss = criterion(predictions, labels)
acc = calculate_accuracy(predictions, labels)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
# 4. 5折交叉验证
def run_cross_validation():
# 超参数
EMBEDDING_DIM = 100
HIDDEN_DIM = 256
OUTPUT_DIM = 5 # 类别
N_LAYERS = 2
DROPOUT = 0.5
BATCH_SIZE = 64
N_EPOCHS = 5
LEARNING_RATE = 0.0001
# 准备数据
sequences = np.array(data['Sequence'].tolist())
labels = np.array(data['Sentiment'].tolist())
# 初始化5折交叉验证
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
fold_results = []
# 创建保存目录
os.makedirs('models', exist_ok=True)
os.makedirs('plots', exist_ok=True)
# 检查设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"\nUsing device: {device}")
# 开始交叉验证
for fold, (train_idx, val_idx) in enumerate(skf.split(sequences, labels)):
print(f"\nFold {fold + 1}/5")
# 分割数据
X_train, X_val = sequences[train_idx], sequences[val_idx]
y_train, y_val = labels[train_idx], labels[val_idx]
# 创建DataLoader
train_data = SentimentDataset(X_train, y_train)
val_data = SentimentDataset(X_val, y_val)
train_loader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True)
val_loader = DataLoader(val_data, batch_size=BATCH_SIZE)
# 初始化模型
model = SentimentLSTM(vocab_size, EMBEDDING_DIM, HIDDEN_DIM, OUTPUT_DIM, N_LAYERS, DROPOUT).to(device)
# 定义优化器和损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
criterion = nn.CrossEntropyLoss().to(device)
# 存储训练历史
history = {'train_loss': [], 'train_acc': [], 'val_loss': [], 'val_acc': []}
best_val_acc = 0
# 训练循环
for epoch in range(N_EPOCHS):
print(f"\nEpoch {epoch + 1}/{N_EPOCHS}")
train_loss, train_acc = train_model(model, train_loader, optimizer, criterion, device)
val_loss, val_acc = evaluate_model(model, val_loader, criterion, device)
print(f'Train Loss: {train_loss:.3f} | Train Acc: {train_acc * 100:.2f}%')
print(f'Val. Loss: {val_loss:.3f} | Val. Acc: {val_acc * 100:.2f}%')
# 保存历史
history['train_loss'].append(train_loss)
history['train_acc'].append(train_acc)
history['val_loss'].append(val_loss)
history['val_acc'].append(val_acc)
# 保存最佳模型
if val_acc > best_val_acc:
best_val_acc = val_acc
torch.save(model.state_dict(), f'models/best_model_fold{fold + 1}.pt')
print(f"New best model saved with val acc: {val_acc * 100:.2f}%")
# 保存训练曲线
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(history['train_loss'], label='Train Loss')
plt.plot(history['val_loss'], label='Validation Loss')
plt.title('Loss Curve')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history['train_acc'], label='Train Accuracy')
plt.plot(history['val_acc'], label='Validation Accuracy')
plt.title('Accuracy Curve')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.tight_layout()
plt.savefig(f'plots/training_curve_fold{fold + 1}.png')
plt.close()
# 存储结果
fold_results.append({
'best_val_acc': best_val_acc,
'history': history
})
# 打印交叉验证结果
print("\nCross Validation Results:")
for i, result in enumerate(fold_results):
print(f"Fold {i + 1}: Best Val Acc = {result['best_val_acc'] * 100:.2f}%")
mean_acc = np.mean([result['best_val_acc'] for result in fold_results])
print(f"\nMean Validation Accuracy: {mean_acc * 100:.2f}%")
# 保存词汇表和模型配置
with open('vocab.json', 'w') as f:
json.dump(vocab, f)
config = {
'vocab_size': vocab_size,
'embedding_dim': EMBEDDING_DIM,
'hidden_dim': HIDDEN_DIM,
'output_dim': OUTPUT_DIM,
'n_layers': N_LAYERS,
'dropout': DROPOUT,
'max_len': max_len
}
with open('model_config.json', 'w') as f:
json.dump(config, f)
print("\nVocabulary and model configuration saved.")
# 5. 运行交叉验证
if __name__ == "__main__":
run_cross_validation()
# 测试集成预测
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 加载模型配置
with open('model_config.json', 'r') as f:
config = json.load(f)
# 加载词汇表
with open('vocab.json', 'r') as f:
vocab = json.load(f)
# 加载所有折的最佳模型
models = []
for fold in range(5):
model = SentimentLSTM(**{k: v for k, v in config.items() if k != 'max_len'}).to(device)
model.load_state_dict(torch.load(f'models/best_model_fold{fold + 1}.pt'))
model.eval()
models.append(model)
# 测试样例
test_phrases = [
"This movie is absolutely fantastic!",
"I hated every minute of this terrible film.",
"It was okay, nothing special.",
"The acting was great but the plot was boring.",
"Worst movie I've ever seen in my life."
]
print("\nEnsemble Model Predictions:")
for phrase in test_phrases:
# 预处理
processed_text = preprocess_text(phrase)
sequence = text_to_sequence(processed_text, vocab, config['max_len'])
sequence = torch.tensor(sequence, dtype=torch.long).unsqueeze(0).to(device)
# 集成预测
predictions = []
with torch.no_grad():
for model in models:
output = model(sequence)
predictions.append(output)
avg_prediction = torch.mean(torch.stack(predictions), dim=0)
_, predicted = torch.max(avg_prediction, 1)
pred_label = label_encoder.inverse_transform([predicted.item()])[0]
print(f"Phrase: {phrase}")
print(f"Predicted Sentiment: {predicted.item()} ({pred_label})")
print()展示和免费下载
如下:基于LSTM的电影评论情感分析模型研究【代码+10万条数据集+完整训练结果】资源-CSDN文库
训练好的词典:
模型参数: