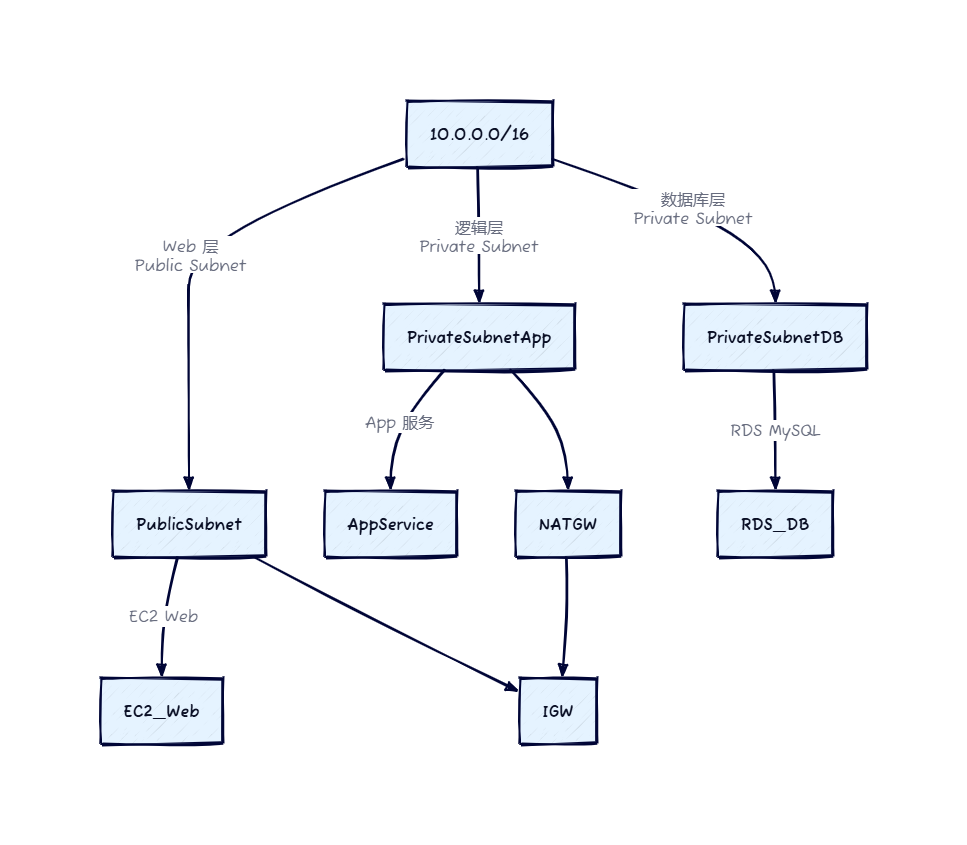
美团面试追魂七连问:关于Object o = New Object() ,1请解释一下对象的创建过程(半初始化) 2,加问DCL要不要volatile 问题(指令重排) 3.对象在内存中的存储布局(对象与数组的存储不同),4.对象头具体包括什么.5.对象怎么定位.6.对象怎么分配(栈-线程本地-Eden-Old)7.在内存中占用多少字节
1. 请解释一下对象的创建过程(包括“半初始化”问题)
在 Java 中,当我们执行 Object o = new Object(); 时,JVM 会经历以下步骤来创建一个对象:
1. 类加载检查
- 首先检查这个类是否已经被加载、解析和初始化。
- 如果没有,则进行类加载(ClassLoader.loadClass -> 验证 -> 准备 -> 解析 -> 初始化)
2. 分配内存
- 在堆中为对象分配内存空间。
- 内存分配方式取决于 GC 算法:
- 指针碰撞(适用于 Serial / ParNew)
- 空闲列表(适用于 CMS)
3. 初始化零值
- 将分配到的内存空间初始化为默认值(如 int=0,boolean=false,引用=null)
4. 设置对象头
- 设置对象头信息(Mark Word、Klass Pointer 等),用于支持 JVM 的运行时机制。
5. 执行构造函数 <init>
- 调用类的构造方法,对对象进行初始化。
关键点:指令重排导致“半初始化”问题
- 在多线程环境下,由于 CPU 和编译器的指令重排序,可能导致对象未完全初始化就被其他线程访问。
- 例如,在 DCL(Double Check Locking)单例模式中,如果不对实例变量加
volatile,可能会看到一个“半初始化”的对象。
2. 加问 DCL 要不要 volatile?为什么?
DCL 示例代码:
public class Singleton {
private static Singleton instance;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) { // 第一次检查
synchronized (Singleton.class) {
if (instance == null) { // 第二次检查
instance = new Singleton(); // 创建对象
}
}
}
return instance;
}
}回答:需要 volatile
-
因为
instance = new Singleton()这个操作不是原子的,它分为三个步骤:- 分配内存空间
- 调用构造函数初始化对象
- 将 instance 引用指向该内存地址
-
如果不加
volatile,可能发生指令重排,变成顺序是:- 分配内存 → 指向地址 → 构造函数(还没完成构造)
- 此时另一个线程读取到 instance != null,但对象尚未构造完毕,出现“半初始化”状态。
解决办法:
使用 volatile 关键字修饰 instance 变量:
private static volatile Singleton instance;作用:
- 禁止指令重排序
- 保证可见性
3. 对象在内存中的存储布局(对象 vs 数组)
Java 对象在堆内存中的布局由三部分组成:
1. 对象头(Object Header)
- 存储元数据信息,比如哈希码、GC 分代年龄、锁状态标志、线程持有的锁、偏向线程 ID 等。
- 大小通常是 12~16 字节(32/64位系统不同)
2. 实例数据(Instance Data)
- 对象真正存储的有效数据,即我们在类中定义的各种字段内容。
- 包括从父类继承下来的字段。
3. 对齐填充(Padding)
- 为了满足 JVM 的内存对齐要求(通常 8 字节对齐),可能添加一些填充字节。
数组对象的特殊布局:
除了上述三部分外,数组对象还有一个额外的部分:
长度字段(Length)
- 表示数组长度,占用 4 字节(int 类型)
所以数组对象结构如下:
| 对象头 | 长度字段 | 实例数据 | 填充 |
|---|---|---|---|
| MarkWord + KlassPointer | 4字节 | 数组元素 | 8字节对齐 |
4. 对象头具体包括什么?
对象头主要包含两个部分:
1. Mark Word(标记字段)
- 用于存储对象自身的运行时数据,如:
- 哈希码(HashCode)
- GC 分代年龄(Age)
- 锁状态标志(biased, lightweight, heavyweight)
- 线程持有的锁
- 偏向线程 ID(Biased Locking)
- 持有锁的计数器等
以 HotSpot VM 为例(64位系统):
| 状态 | 内容 | 大小 |
|---|---|---|
| 无锁态 | 哈希码 + 分代年龄 + 01 | 64 bits |
| 偏向锁 | 线程ID + 时间戳 + 分代年龄 + 101 | 64 bits |
| 轻量级锁 | 指向栈中锁记录的指针 | 64 bits |
| 重量级锁 | 指向互斥量(monitor)的指针 | 64 bits |
| GC 标记 | 空 | 64 bits |
2. Klass Pointer(类型指针)
- 指向对象对应的 Class 对象(元数据),用于确定对象是哪个类的实例。
- 占用 4 或 8 字节(取决于是否开启压缩指针
-XX:+UseCompressedOops)
5. 对象怎么定位?
在 Java 中,当我们通过一个引用变量(如 Object o = new Object();)来访问对象时,JVM 是如何定位堆中的对象的?这个问题涉及到 JVM 的对象访问方式和内存模型。
一、Java 对象的访问机制
Java 堆中存储的是对象的实例,而栈上的局部变量表中保存的是对象的引用(reference)。这个引用并不是直接指向对象本身,而是通过某种机制找到对象的实际地址。
JVM 规范并没有强制规定引用如何实现,不同的虚拟机可以有不同的实现方式,但主流的 HotSpot 虚拟机中通常使用以下两种方式:
1. 句柄访问(Handle)
结构:
- 栈中的 reference 指向一个句柄池中的句柄。
- 句柄中包含两个指针:
- 对象实例指针:指向堆中真正的对象
- 类型指针:指向方法区中的类元数据(Class 对象)
优点:
- 在对象被移动(GC 时)时,只需要修改句柄中的对象实例指针,不需要修改栈上的引用。
缺点:
- 多了一次间接访问,效率略低。
栈引用 --> [句柄] --> 实例数据 | 类型指针2. 直接指针访问(Direct Pointer,HotSpot 默认)
结构:
- 栈中的 reference 直接指向堆中的对象实例。
- 对象头中包含一个指向类元数据的指针(Klass Pointer)。
优点:
- 访问速度快,省去一次中间跳转。
缺点:
- 如果对象被 GC 移动,所有引用都需要更新(由 GC 算法自动处理)。
栈引用 --> 对象实例(包含对象头、实例数据)HotSpot 中的对象定位方式
HotSpot 使用的是直接指针访问的方式。对象布局简述:
| 内容 | 描述 |
|---|---|
| 对象头(Object Header) | 包含 Mark Word 和 Klass Pointer |
| 实例数据(Instance Data) | 成员变量等实际数据 |
| 对齐填充(Padding) | 保证对象大小为 8 字节的倍数 |
- 其中 Klass Pointer 指向方法区中的类元数据(即 Class 对象)。
- 所以,当引用变量指向对象后,JVM 就可以通过这个引用来访问对象的实例数据以及其类型信息。
| 方式 | 定位方式 | 是否需要句柄池 | 访问速度 | GC 移动代价 |
|---|---|---|---|---|
| 句柄访问 | reference → 句柄池 → 对象 | 需要 | 稍慢 | 小 |
| 直接指针访问 | reference → 对象实例 | 不需要 | 快 | 大(需更新引用) |
🔍 HotSpot 使用直接指针访问,这是为了提高性能。虽然 GC 时需要更新引用,但现代 GC 算法已经能高效地完成这项任务。
补充:数组对象的定位
数组对象与普通对象略有不同,除了对象头、实例数据外,还多了一个长度字段(Length),位于对象头之后、实例数据之前。
例如一个 int[4] 数组的布局如下:
| 对象头 | 长度字段(4) | 数据部分(4个 int) | 填充 |
|---|
这样就可以通过引用快速获取数组长度。
Java 中通过引用变量访问对象时,JVM 使用直接指针访问方式(HotSpot),引用直接指向堆中的对象实例,对象头中包含指向类元数据的指针,从而实现对象的快速定位和访问。
6. 对象怎么分配?(栈、线程本地、Eden、Old)
Java 中的对象主要分配在堆中,但根据对象的大小、生命周期、线程使用等特性,JVM 会采取不同的分配策略。
我们按以下几个维度来分析:
一、栈上分配(Stack Allocation)
场景:
- 小对象
- 作用域明确且不会逃逸出方法的作用域(即不会被其他线程访问或返回给外部)
- 开启了 逃逸分析(Escape Analysis)
原理:
- 如果一个对象只在方法内部使用,并且没有“逃逸”出去(比如被返回或赋值给全局变量),JVM 可以通过逃逸分析优化,将这个对象分配在当前线程的栈上。
- 这样做的好处是:不走堆分配流程,减少 GC 压力,提升性能。
如何开启?
-XX:+DoEscapeAnalysis -XX:+UseCompressedOops注意:默认情况下 HotSpot 是开启了逃逸分析的(JDK 6u23+),但是否启用栈上分配取决于具体实现和 JVM 版本。
二、线程本地分配(Thread Local Allocation Buffer, TLAB)
场景:
- 多线程环境下,为每个线程预先分配一小块内存空间(TLAB)
- 线程优先在自己的 TLAB 中分配对象
原理:
- 每个线程都有一个私有的 TLAB(位于 Eden 区)
- 线程创建对象时优先尝试在 TLAB 中分配
- 避免多线程竞争 Eden 区的锁(
eden_lock),提高并发性能
相关参数:
-XX:+UseTLAB # 是否启用 TLAB,默认开启
-XX:TLABSize= # 设置初始 TLAB 大小
-XX:+ResizeTLAB # 是否动态调整 TLAB 大小小结:
- TLAB 是线程私有的 Eden 区域
- 提高多线程下对象分配效率
- 不适合大对象(超过 TLAB 剩余空间的对象会被直接分配到 Eden)
三、Eden 区分配(Young Generation)
场景:
- 普通对象默认分配在 Eden 区(属于新生代的一部分)
- Eden 区满了之后触发 Minor GC
原理:
- 新生对象大多数都分配在 Eden 区
- 经过一次 GC 后仍然存活的对象会被移动到 Survivor 区
- 经历多次 GC 后晋升到老年代(Tenured/OLD)
分配过程:
- 线程尝试在 TLAB 中分配
- TLAB 不够 → 分配到 Eden 区(需加锁)
- Eden 区不够 → 触发 Minor GC
- GC 后仍存活的对象进入 Survivor 区
- 经过一定年龄(MaxTenuringThreshold)后晋升到老年代
四、老年代分配(Old Generation / Tenured)
场景:
- 大对象(如长数组、大字符串)
- 存活时间较长的对象(经过多次 GC 依然存活)
- 动态年龄判断(Survivor 区相同年龄对象总和大于一半,该年龄及以上的对象直接进入老年代)
原理:
- 老年代存放的是生命周期较长的对象
- GC 类型是 Full GC 或 Mixed GC(G1 收集器)
- 老年代空间不足时可能触发 Full GC,代价较高
五、大对象直接分配:
- 使用
-XX:PretenureSizeThreshold参数设置阈值,大于该值的对象直接分配到老年代(仅适用于 Serial 和 ParNew 收集器) - 示例:
-XX:PretenureSizeThreshold=1048576 # 大于 1MB 的对象直接进老年代
| 分配方式 | 条件 | 优点 | 缺点 |
|---|---|---|---|
| 栈上分配 | 小对象 + 未逃逸 | 快速、无 GC | 依赖逃逸分析,有限制 |
| TLAB | 线程局部分配 | 减少锁竞争,提高并发 | 占用 Eden 空间,不适合大对象 |
| Eden 区 | 普通对象 | 生命周期短,GC 效率高 | 需要频繁 GC |
| Survivor 区 | Minor GC 存活对象 | 年龄增长后晋升老年代 | 临时过渡区 |
| 老年代 | 大对象、长期存活对象 | 稳定存储 | Full GC 成本高 |
对象创建
↓
是否可栈上分配? → 是 → 分配在栈上
↓否
是否可TLAB分配? → 是 → 分配在TLAB(Eden)
↓否
是否为大对象? → 是 → 分配在老年代(Old)
↓否
分配到 Eden 区
↓
Minor GC → 存活 → Survivor 区
↓
再次 GC → 存活 → 晋升到老年代六、补充说明
-
分配担保机制(Handle Promotion Failure):
- 当 Minor GC 发生时,如果 Survivor 区无法容纳所有存活对象,JVM 会向老年代发起分配担保,将部分对象提前晋升到老年代。
-
动态年龄判定(Adaptive Tenuring):
- Survivor 区中相同年龄的对象总和 ≥ Survivor 区容量的一半时,这些对象都会晋升到老年代,而不需要等到 MaxTenuringThreshold。
Java 对象的分配遵循栈上 > TLAB > Eden > Old 的顺序,结合逃逸分析、TLAB 技术、GC 算法与对象生命周期进行智能调度,以达到性能最优。
7. 在内存中占用多少字节?
我们以 HotSpot 虚拟机为例来分析。Java 对象在堆中的内存结构主要由三部分组成:
一、对象头(Object Header)
1. Mark Word(标记字段)
- 存储对象运行时信息,如哈希码、GC 分代年龄、锁状态标志等。
- 占用 8 字节(64位系统) / 4 字节(32位系统)
2. Klass Pointer(类型指针)
- 指向该对象对应的类元数据(Class 对象)。
- 默认是 8 字节(64位系统)
- 如果开启压缩指针(
-XX:+UseCompressedOops),则为 4 字节
⚠️
UseCompressedOops是 JDK 6 及以后版本默认开启的。
📌 对象头总大小:
| 系统 | UseCompressedOops | 对象头大小 |
|---|---|---|
| 64位 | 开启 | 12 字节 |
| 64位 | 关闭 | 16 字节 |
| 32位 | - | 8 字节 |
二、实例数据(Instance Data)
这部分是你定义的对象字段所占用的空间。
class Person {
int age;
boolean isMale;
}int age:4 字节boolean isMale:1 字节
合计:5 字节
但 JVM 会对字段进行排序并填充,以满足对齐要求(通常是 8 字节对齐)。
三、对齐填充(Padding)
为了提高访问效率,JVM 要求对象大小是 8 字节的整数倍。
所以即使实际数据只有 5 字节,也会补到 8 字节。
示例分析:计算一个对象的实际大小
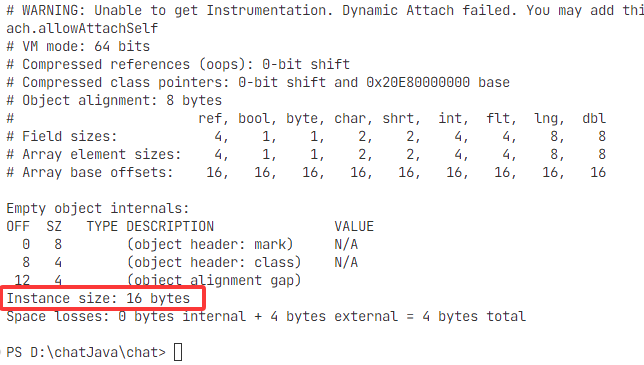
示例 1:空对象
class Empty {}- 对象头:12 字节(64位 + 压缩指针)
- 实例数据:0 字节
- 对齐后:12 → 不是 8 的倍数,需要填充4个字节
- 总大小:16 字节
验证:(需要导入https://mvnrepository.com/artifact/org.openjdk.jol/jol-core)
import org.openjdk.jol.vm.VM;
import org.openjdk.jol.info.ClassLayout;
public class Test {
static class Empty {}
public static void main(String[] args) {
System.out.println(VM.current().details());
System.out.println(ClassLayout.parseClass(Empty.class).toPrintable());
}
}
示例 2:简单字段对象
class Person {
int age; // 4B
boolean isMale; // 1B
}- 对象头:12 字节
- 实例数据:4 + 1 = 5 字节
- 总计:12 + 5 = 17 字节
- 对齐填充:+7 字节(使总大小为 24 字节)
总大小:24 字节
示例 3:包含引用类型的对象
class User {
String name; // 引用类型,默认 4 字节(压缩指针)
int age;
}- 对象头:12 字节
- 实例数据:4 (name) + 4 (age) = 8 字节
- 总计:20 字节
- 对齐填充:+4 字节(使总大小为 24 字节)
总大小:24 字节
示例 4:数组对象(特别注意长度字段)
int[] arr = new int[10]; // 10个元素 × 4B = 40B 数据- 对象头:12 字节
- 长度字段:4 字节(int 类型)
- 实例数据:10 × 4 = 40 字节
- 总计:12 + 4 + 40 = 56 字节
- 对齐检查:56 已是 8 的倍数
总大小:56 字节
如何验证?使用 Instrumentation.getObjectSize()
你可以通过以下方式验证对象大小:
步骤:
- 编写一个 Agent 类获取
Instrumentation - 使用
getObjectSize()方法查看对象大小
示例代码:
public class ObjectSizeAgent {
private static Instrumentation inst;
public static void premain(String args, Instrumentation i) {
inst = i;
}
public static long sizeOf(Object o) {
return inst.getObjectSize(o);
}
}public class Main {
public static void main(String[] args) {
int[] arr = new int[10]; // 10个元素 × 4B = 40B 数据
String str = "Hello, World!";
long size = ObjectSizeFetcher.getObjectSize(str);
System.out.println("Size of string: " + size + " bytes");
long size2 = ObjectSizeFetcher.getObjectSize(arr);
System.out.println("Array of int[10]: " + size2 + " bytes");
}
}
需要把他们打成jar包. (我已经做了一份jar包.下载地址https://download.csdn.net/download/chxii/90938677?spm=1001.2101.3001.9500)
然后通过命令行启动程序并指定 agent 参数即可。

补充:字段重排序优化
JVM 会自动对字段进行重排序,以减少填充空间,提升空间利用率。
class Example {
byte b1;
int i;
byte b2;
}实际存储顺序可能变为:
b1 | b2 | padding(2) | i(4)这样可以减少填充空间,节省内存。
一个 Java 对象的大小 = 对象头(12~16字节)+ 实例数据 + 对齐填充;数组还额外包含长度字段(4字节);合理设计字段顺序和类型可以有效降低内存开销。
降到这里,就不在深入下去了.如果你还想了解更多.可以通过 JOL(Java Object Layout)工具分析对象内存布局