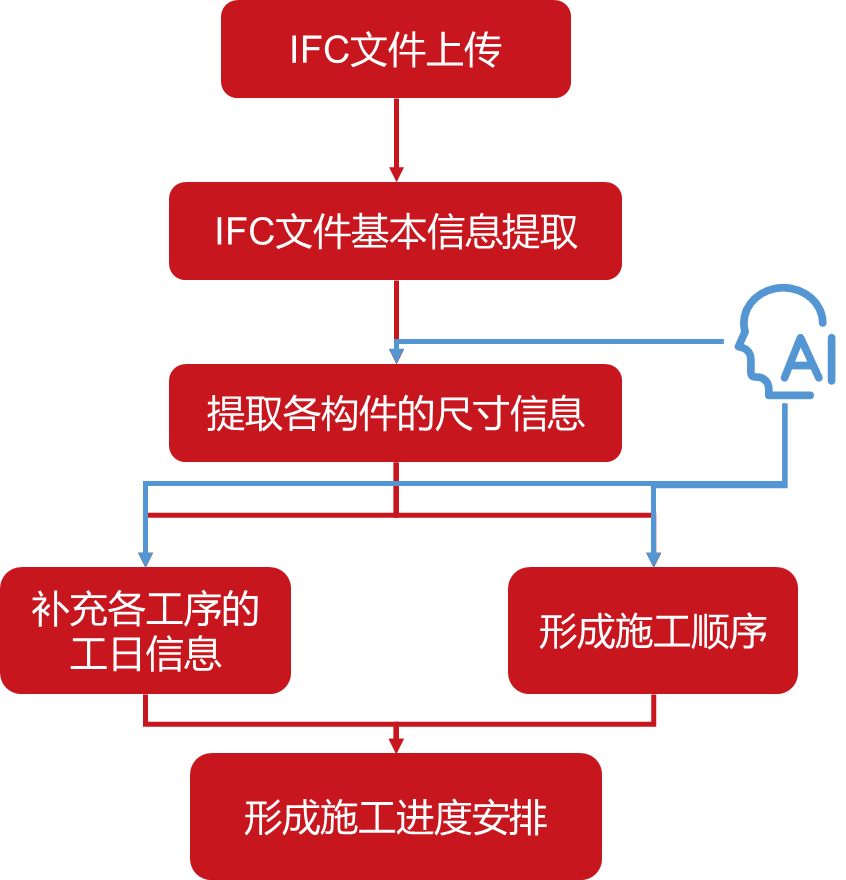
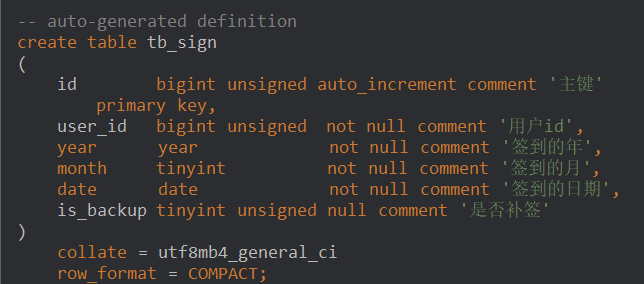
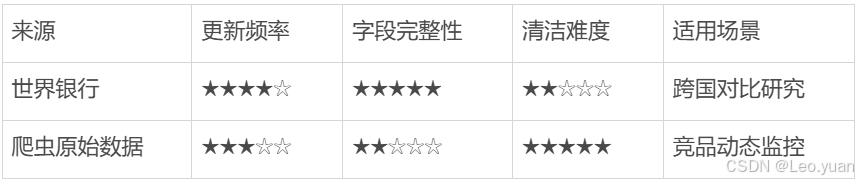
HDFS 写入流程细化
1. 主线流程速记口诀
“先找主脑定文件,分配块副找节点;流水传块多副本,写完通知主脑存。”
2. 详细流程拆解
1. 客户端请求上传(Create 文件)
关键方法:
org.apache.hadoop.fs.FileSystem#createorg.apache.hadoop.hdfs.DistributedFileSystem#create- RPC 调用:
ClientProtocol#create
内部逻辑:
- 客户端调用
FileSystem#create(path),通过 RPC 向 NameNode 发起“我要新建文件”请求。
源码片段:
// FileSystem.java
FSDataOutputStream out = fs.create(new Path("/user/hadoop/test.txt"));
// DistributedFileSystem.java
public FSDataOutputStream create(Path f, ...) {
return dfs.create(getPathName(f), ...);
}
// DFSClient.java
public OutputStream create(String src, ...) {
namenode.create(src, ...); // RPC 请求
}
口诀注释:
主脑即 NameNode,先发“新建”请求。
2. NameNode 检查与元数据创建
关键方法:
org.apache.hadoop.hdfs.server.namenode.FSNamesystem#startFileFSDirectory#addFile
内部逻辑:
- NameNode 检查目录和权限,文件是否已存在。
- 创建文件元数据,登记文件名、父目录、权限等。
源码片段:
// FSNamesystem.java
public void startFile(...) {
// 检查目录、权限
// 创建 INodeFile
// 记录日志
}
口诀注释:
主脑查目录权限,登记新文件元数据。
3. Block 分配与 DataNode 列表下发
关键方法:
org.apache.hadoop.hdfs.server.namenode.FSNamesystem#allocateBlockBlockManager#chooseTarget4NewBlock
内部逻辑:
- NameNode 根据副本策略,选择 DataNode 并分配块。
- 返回块 ID 和 DataNode 列表给客户端。
源码片段:
// FSNamesystem.java
LocatedBlock locatedBlock = allocateBlock(...);
// BlockManager.java
chooseTarget4NewBlock(...)
口诀注释:
分配块副本,选定存放节点。
4. 客户端流水线写数据块
关键方法:
org.apache.hadoop.hdfs.DFSOutputStream#writeChunkDataStreamer#run
内部逻辑:
- 客户端建立与第一个 DataNode 的连接,DataNode 之间串联成流水线。
- 数据块被切分成 packet,按顺序流向各 DataNode。
- 每个 DataNode 写磁盘并返回 ACK。
源码片段:
// DFSOutputStream.java
writeChunk(...); // 写入数据
// DataStreamer.java
run(); // 负责数据传输和 ACK 处理
口诀注释:
流水线传块,副本级联写入。
5. 块写入完成与确认
关键方法:
DataNode#blockReceivedAndDeletedNameNode#complete
内部逻辑:
- 所有块写入完毕后,客户端通知 NameNode。
- NameNode 更新文件状态为“已完成”,持久化元数据。
源码片段:
// DFSClient.java
namenode.complete(src, clientName, ...);
// FSNamesystem.java
completeFile(...); // 完成文件写入
口诀注释:
写完通知主脑,文件状态完成。
6. 写入流程图(Mermaid)
HDFS 读取流程细化
1. 主线流程速记口诀
“先问主脑要位置,选好节点取数据;分块并发快下载,组装文件得全局。”
2. 详细流程拆解
1. 客户端请求读取
关键方法:
org.apache.hadoop.fs.FileSystem#open- RPC:
ClientProtocol#getBlockLocations
内部逻辑:
- 客户端调用
open(path),通过 RPC 向 NameNode 请求块和 DataNode 的位置信息。
源码片段:
// FileSystem.java
FSDataInputStream in = fs.open(new Path("/user/hadoop/test.txt"));
// DFSClient.java
public LocatedBlocks getBlockLocations(String src, ...) {
return namenode.getBlockLocations(src, ...); // RPC
}
口诀注释:
主脑给出块位置,客户端拿到 DataNode 列表。
2. NameNode 返回块元数据
关键方法:
org.apache.hadoop.hdfs.server.namenode.FSNamesystem#getBlockLocations
内部逻辑:
- NameNode 查询文件块分布,返回每个块的 DataNode 列表。
源码片段:
// FSNamesystem.java
getBlockLocations(...);
口诀注释:
主脑查块分布,返回节点清单。
3. 客户端读取数据块
关键方法:
org.apache.hadoop.hdfs.DFSInputStream#readBlockReaderFactory#newBlockReader
内部逻辑:
- 客户端从 DataNode 读取数据块,可并发多线程读取不同块。
- 自动选择健康的 DataNode,若失败自动切换。
源码片段:
// DFSInputStream.java
BlockReader reader = new BlockReaderFactory(...).build();
reader.read(...);
口诀注释:
并发取块,健康优先,故障切换。
4. 数据组装
关键方法:
FSDataInputStream#read- 由客户端按块顺序拼接还原文件
内部逻辑:
- 客户端按文件逻辑顺序拼接所有块数据,得到完整文件。
源码片段:
// FSDataInputStream.java
int n = in.read(buffer);
口诀注释:
拼接数据块,文件得全局。
5. 读取流程图(Mermaid)
总结口诀速记
- 写入口诀:
“先找主脑定文件,分配块副找节点;流水传块多副本,写完通知主脑存。” - 读取口诀:
“先问主脑要位置,选好节点取数据;分块并发快下载,组装文件得全局。”
如需某个流程的源码更详细解析或更深入的注释,可以告诉我要哪个部分!