复习日
作业:
kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化
进阶:并拆分成多个文件
找了个街头食物图像分类的数据集Popular Street Foods(其实写代码的时候就开始后悔了),原因在于:
1、如果是比较规整的图像分类数据集,自己划分了train和test目录,就可以直接用pytorch内置的ImageFolder类,不用自己再辛辛苦苦定义数据集类了,但很遗憾这个数据集不规整,图片在类别下面,标签用一个csv文件存储,所以不仅要自己定义数据类,训练测试的时候还要自己划分数据集
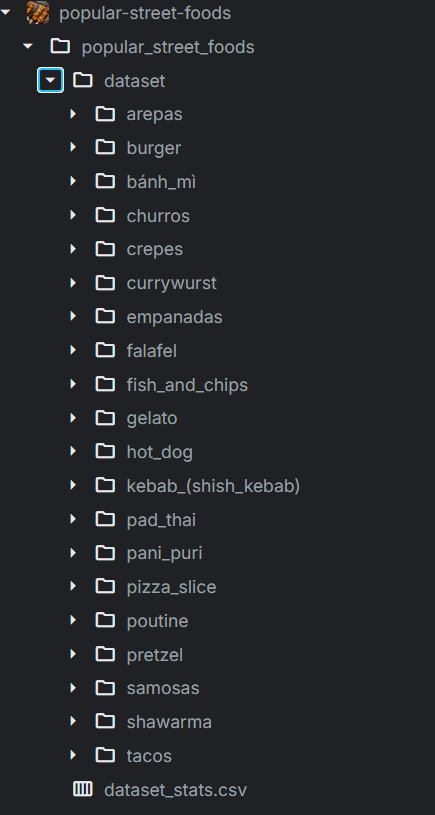
2、图片尺寸非常不统一,需要自己预先处理,遍历了一遍这个数据集,最后决定全部统一成140x140的
from PIL import Image
import os
from collections import defaultdict
# 替换为你的数据集路径
dataset_path = "/kaggle/input/popular-street-foods/popular_street_foods/dataset"
size_dict = defaultdict(int)
for root, _, files in os.walk(dataset_path):
for file in files:
if file.lower().endswith(('png', 'jpg', 'jpeg')):
try:
with Image.open(os.path.join(root, file)) as img:
size_dict[img.size] += 1 # (width, height)
except:
print(f"Error reading: {file}")
# 打印尺寸统计
print("Top 10 common sizes:")
for size, count in sorted(size_dict.items(), key=lambda x: x[1], reverse=True)[:10]:
print(f"{size}: {count} images")
# -----------------------------------------------------
Top 10 common sizes:
(140, 140): 851 images
(93, 140): 574 images
(162, 108): 548 images
(162, 121): 308 images
(162, 91): 295 images
(105, 140): 119 images
(112, 140): 90 images
(100, 140): 30 images
(154, 140): 28 images
(162, 85): 26 images完成代码:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets, transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import Dataset, DataLoader, random_split
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 1. 数据预处理
# 图像尺寸统一成140x140
class PhotoResizer:
def __init__(self, target_size=140, fill_color=114): # target_size: 目标正方形尺寸,fill_color: 填充使用的灰度值
self.target_size = target_size
self.fill_color = fill_color
# 预定义转换方法
self.to_tensor = transforms.ToTensor()
self.normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
def __call__(self, img):
"""
智能处理流程:
1. 对小图像进行填充,对大图像进行智能裁剪
2. 保持长宽比的情况下进行保护性处理
"""
w, h = img.size
if w == h == self.target_size: # 情况1:已经是目标尺寸
pass # 无需处理
elif min(w, h) < self.target_size: # 情况2:至少有一个维度小于目标尺寸(需要填充)
img = self.padding_resize(img)
else: # 情况3:两个维度都大于目标尺寸(智能裁剪)
img = self.crop_resize(img)
# 最终统一转换
return self.normalize(self.to_tensor(img))
def padding_resize(self, img): # 等比缩放后居中填充不足部分
w, h = img.size
scale = self.target_size / min(w, h)
new_w, new_h = int(w * scale), int(h * scale)
img = img.resize((new_w, new_h), Image.BILINEAR)
# 等比缩放 + 居中填充
# 计算需要填充的像素数(4个值:左、上、右、下)
pad_left = (self.target_size - new_w) // 2
pad_top = (self.target_size - new_h) // 2
pad_right = self.target_size - new_w - pad_left
pad_bottom = self.target_size - new_h - pad_top
return transforms.functional.pad(img, [pad_left, pad_top, pad_right, pad_bottom], self.fill_color)
def crop_resize(self, img): # 等比缩放后中心裁剪
w, h = img.size
ratio = w / h
# 计算新尺寸(保护长边)
if ratio < 0.9: # 竖图
new_size = (self.target_size, int(h * self.target_size / w))
elif ratio > 1.1: # 横图
new_size = (int(w * self.target_size / h), self.target_size)
else: # 近似正方形
new_size = (self.target_size, self.target_size)
img = img.resize(new_size, Image.BILINEAR)
return transforms.functional.center_crop(img, self.target_size)
# 训练集测试集预处理
train_transform = transforms.Compose([
PhotoResizer(target_size=140), # 自动处理所有情况
transforms.RandomHorizontalFlip(), # 随机水平翻转图像(概率0.5)
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), # 随机颜色抖动:亮度、对比度、饱和度和色调随机变化
transforms.RandomRotation(15), # 随机旋转图像(最大角度15度)
])
test_transform = transforms.Compose([
PhotoResizer(target_size=140)
])
# 2. 创建dataset和dataloader实例
class StreetFoodDataset(Dataset):
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.transform = transform
self.image_paths = []
self.labels = []
self.class_to_idx = {}
# 遍历目录获取类别映射
classes = sorted(entry.name for entry in os.scandir(root_dir) if entry.is_dir())
self.class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}
# 收集图像路径和标签
for class_name in classes:
class_dir = os.path.join(root_dir, class_name)
for img_name in os.listdir(class_dir):
if img_name.lower().endswith(('.png', '.jpg', '.jpeg')):
self.image_paths.append(os.path.join(class_dir, img_name))
self.labels.append(self.class_to_idx[class_name])
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
img_path = self.image_paths[idx]
image = Image.open(img_path).convert('RGB')
label = self.labels[idx]
if self.transform:
image = self.transform(image)
return image, label
# 数据集路径(Kaggle路径示例)
dataset_path = '/kaggle/input/popular-street-foods/popular_street_foods/dataset'
# 创建数据集实例
# 先创建基础数据集
full_dataset = StreetFoodDataset(root_dir=dataset_path)
# 分割数据集
train_size = int(0.8 * len(full_dataset))
test_size = len(full_dataset) - train_size
train_dataset, test_dataset = random_split(full_dataset, [train_size, test_size])
train_dataset.dataset.transform = train_transform
test_dataset.dataset.transform = test_transform
# 创建数据加载器
train_loader = DataLoader(
train_dataset,
batch_size=32,
shuffle=True,
num_workers=2,
pin_memory=True
)
test_loader = DataLoader(
test_dataset,
batch_size=32,
shuffle=False,
num_workers=2,
pin_memory=True
)
# 3. 定义CNN模型
class CNN(nn.Module):
def __init__(self, num_classes=20):
super(CNN, self).__init__()
# 第一个卷积块
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(32)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # 140x140 → 70x70
# 第二个卷积块
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2) # 70x70 → 35x35
# 第三个卷积块
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.relu3 = nn.ReLU()
self.pool3 = nn.MaxPool2d(kernel_size=2) # 35x35 → 17x17(下采样时尺寸向下取整)
# 第四个卷积块(新增,处理更大尺寸)
self.conv4 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
self.bn4 = nn.BatchNorm2d(256)
self.relu4 = nn.ReLU()
self.pool4 = nn.MaxPool2d(kernel_size=2) # 17x17 → 8x8
# 全连接层(分类器)
# 修改:计算展平后的特征维度 256通道 × 8x8尺寸 = 16384
self.fc1 = nn.Linear(256 * 8 * 8, 512)
self.dropout = nn.Dropout(p=0.5)
self.fc2 = nn.Linear(512, num_classes) # 使用num_classes参数
def forward(self, x):
# 输入尺寸:[batch_size, 3, 140, 140]
# 卷积块1处理
x = self.conv1(x) # [batch_size, 32, 140, 140]
x = self.bn1(x)
x = self.relu1(x)
x = self.pool1(x) # [batch_size, 32, 70, 70]
# 卷积块2处理
x = self.conv2(x) # [batch_size, 64, 70, 70]
x = self.bn2(x)
x = self.relu2(x)
x = self.pool2(x) # [batch_size, 64, 35, 35]
# 卷积块3处理
x = self.conv3(x) # [batch_size, 128, 35, 35]
x = self.bn3(x)
x = self.relu3(x)
x = self.pool3(x) # [batch_size, 128, 17, 17]
# 卷积块4处理(新增)
x = self.conv4(x) # [batch_size, 256, 17, 17]
x = self.bn4(x)
x = self.relu4(x)
x = self.pool4(x) # [batch_size, 256, 8, 8]
# 展平与全连接层
x = x.view(-1, 256 * 8 * 8) # [batch_size, 16384]
x = self.fc1(x) # [batch_size, 512]
x = self.relu3(x) # 复用relu3
x = self.dropout(x)
x = self.fc2(x) # [batch_size, num_classes]
return x
# 初始化模型
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)
# 4. 训练测试
# 定义损失函数、优化器、调度器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'max', patience=5, factor=0.5)
# 训练过程封装
def train_epoch(model, loader, criterion, optimizer):
model.train()
running_loss = 0.0
correct = 0
total = 0
for images, labels in loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
return running_loss/len(loader), 100.*correct/total
# 测试过程封装
def test(model, loader, criterion):
model.eval()
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for images, labels in loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
return running_loss/len(loader), 100.*correct/total
# 训练循环
epochs = 1000
best_acc = 0.0
patience = 10 # 早停耐心值
no_improve = 0 # 没有提升的epoch计数
# 创建保存目录
os.makedirs("checkpoints", exist_ok=True)
for epoch in range(epochs):
train_loss, train_acc = train_epoch(model, train_loader, criterion, optimizer)
test_loss, test_acc = test(model, test_loader, criterion)
scheduler.step(test_acc) # 根据测试准确率调整学习率
# 每200个epoch打印一次信息
if (epoch + 1) % 200 == 0 or epoch == 0 or (epoch + 1) == epochs:
print(f"\nEpoch {epoch+1}/{epochs}")
print(f"Train Loss: {train_loss:.4f} | Acc: {train_acc:.2f}%")
print(f"Test Loss: {test_loss:.4f} | Acc: {test_acc:.2f}%")
print(f"Current LR: {optimizer.param_groups[0]['lr']:.6f}")
print("-"*50)
# 保存最佳模型
if test_acc > best_acc:
best_acc = test_acc
torch.save(model.state_dict(), "checkpoints/best_model.pth")
no_improve = 0
else:
no_improve += 1
# 定期保存检查点
if (epoch + 1) % 200 == 0:
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'best_acc': best_acc,
}, f"checkpoints/checkpoint_{epoch+1}.pth")
# 早停检查
if no_improve >= patience:
print(f"\nEarly stopping at epoch {epoch+1}, no improvement for {patience} epochs")
print(f"Best test accuracy: {best_acc:.2f}%")
break
print(f"\n训练完成,最佳测试准确率: {best_acc:.2f}%")
# 5. Grad-CAM实现
model.eval()
# Grad-CAM实现
class GradCAM:
def __init__(self, model, target_layer):
self.model = model
self.target_layer = target_layer
self.gradients = None
self.activations = None
# 注册钩子,用于获取目标层的前向传播输出和反向传播梯度
self.register_hooks()
def register_hooks(self):
# 前向钩子函数,在目标层前向传播后被调用,保存目标层的输出(激活值)
def forward_hook(module, input, output):
self.activations = output.detach()
# 反向钩子函数,在目标层反向传播后被调用,保存目标层的梯度
def backward_hook(module, grad_input, grad_output):
self.gradients = grad_output[0].detach()
# 在目标层注册前向钩子和反向钩子
self.target_layer.register_forward_hook(forward_hook)
self.target_layer.register_backward_hook(backward_hook)
def generate_cam(self, input_image, target_class=None):
# 前向传播,得到模型输出
model_output = self.model(input_image)
if target_class is None:
# 如果未指定目标类别,则取模型预测概率最大的类别作为目标类别
target_class = torch.argmax(model_output, dim=1).item()
# 清除模型梯度,避免之前的梯度影响
self.model.zero_grad()
# 反向传播,构造one-hot向量,使得目标类别对应的梯度为1,其余为0,然后进行反向传播计算梯度
one_hot = torch.zeros_like(model_output)
one_hot[0, target_class] = 1
model_output.backward(gradient=one_hot)
# 获取之前保存的目标层的梯度和激活值
gradients = self.gradients
activations = self.activations
# 对梯度进行全局平均池化,得到每个通道的权重,用于衡量每个通道的重要性
weights = torch.mean(gradients, dim=(2, 3), keepdim=True)
# 加权激活映射,将权重与激活值相乘并求和,得到类激活映射的初步结果
cam = torch.sum(weights * activations, dim=1, keepdim=True)
# ReLU激活,只保留对目标类别有正贡献的区域,去除负贡献的影响
cam = F.relu(cam)
# 调整大小并归一化,将类激活映射调整为与输入图像相同的尺寸(140x140),并归一化到[0, 1]范围
cam = F.interpolate(cam, size=(140, 140), mode='bilinear', align_corners=False)
cam = cam - cam.min()
cam = cam / cam.max() if cam.max() > 0 else cam
return cam.cpu().squeeze().numpy(), target_class
# 选择一个随机图像
idx = np.random.randint(len(test_dataset))
image, label = test_dataset[idx]
classes = sorted(os.listdir('/kaggle/input/popular-street-foods/popular_street_foods/dataset'))
print(f"选择的图像类别: {classes[label]}")
# 转换图像以便可视化
def tensor_to_np(tensor):
img = tensor.cpu().numpy().transpose(1, 2, 0)
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
img = std * img + mean
img = np.clip(img, 0, 1)
return img
# 添加批次维度并移动到设备
input_tensor = image.unsqueeze(0).to(device)
# 初始化Grad-CAM(选择最后一个卷积层)
grad_cam = GradCAM(model, model.conv4 )
# 生成热力图
heatmap, pred_class = grad_cam.generate_cam(input_tensor)
# 可视化
plt.figure(figsize=(12, 4))
# 原始图像
plt.subplot(1, 3, 1)
plt.imshow(tensor_to_np(image))
plt.title(f"原始图像: {classes[label]}")
plt.axis('off')
# 热力图
plt.subplot(1, 3, 2)
plt.imshow(heatmap, cmap='jet')
plt.title(f"Grad-CAM热力图: {classes[pred_class]}")
plt.axis('off')
# 叠加的图像
plt.subplot(1, 3, 3)
img = tensor_to_np(image)
heatmap_resized = np.uint8(255 * heatmap)
heatmap_colored = plt.cm.jet(heatmap_resized)[:, :, :3]
superimposed_img = heatmap_colored * 0.4 + img * 0.6
plt.imshow(superimposed_img)
plt.title("叠加热力图")
plt.axis('off')
plt.tight_layout()
plt.savefig('grad_cam_result.png')
plt.show()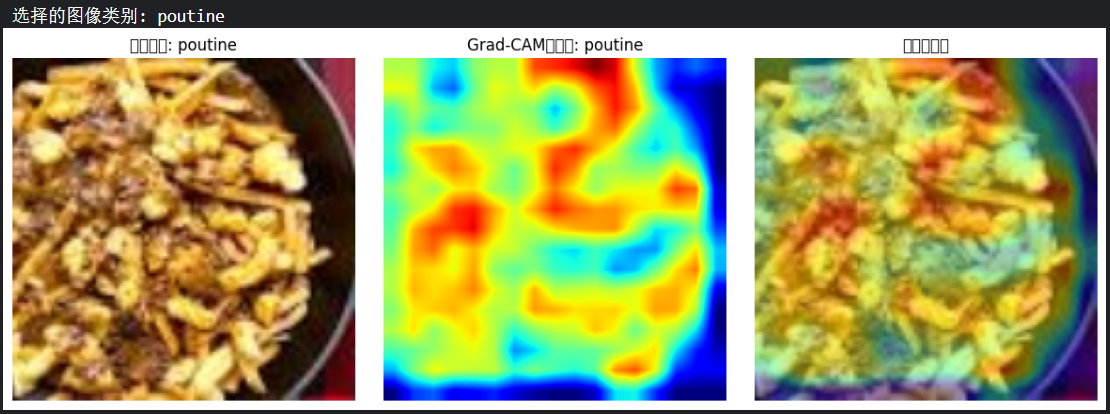
收获心得:
1、就是为了训练有更好的效果,所以图片尺寸处理的时候那么费劲(不然完全可以全部裁剪成一个更小的尺寸),但是最后训练出来的准确率还是不尽人意,可能是cnn结构的问题?下次再看看怎么调整
2、之前的数据集创建dataset和dataloader的时候都很轻松,到了这个数据集就成了比较困难的一个点了,首先是文件路径的问题,其次就是在数据集类的定义里对图像和标签的处理
3、训练的时候没有画损失曲线,所以过程比较简单,就想着加上早停策略,然后一直报错,debug有点de麻了,最后也不知道怎么就解决了,管他的能跑就行(
4、Grag-CAM部分的改动不大,之前的拿过来用,最后不想拆分文件了,比较懒
@浙大疏锦行