在当今数据驱动的时代,向量数据库(Vector Database)作为一种新兴的数据库技术,正逐渐成为软件开发领域的重要组成部分。特别是在 .NET 生态系统中,向量数据库的应用为开发者提供了构建智能、高效应用程序的新途径。
一、什么是向量数据库?
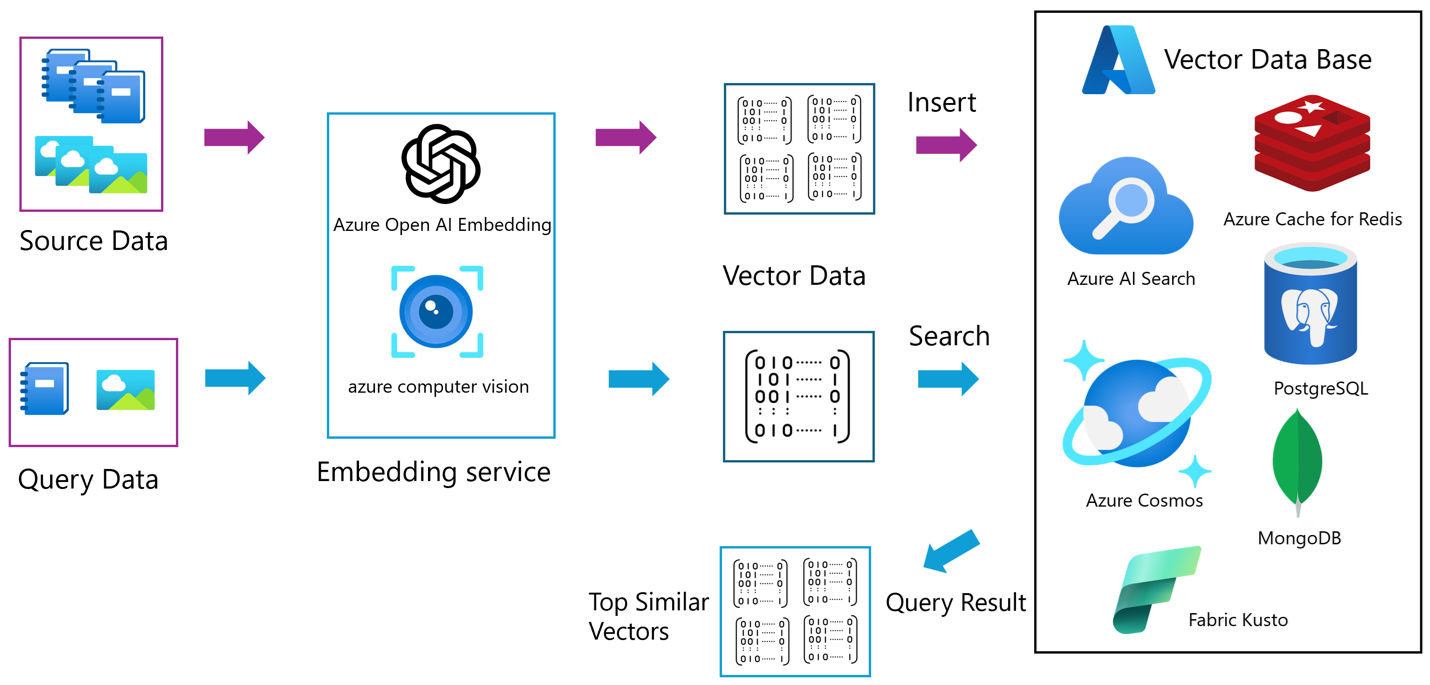
向量数据库是一种专门用于存储、索引和查询高维向量数据的数据库系统。这些高维向量通常是由机器学习模型生成的嵌入(embeddings),用于表示文本、图像、音频等复杂数据的语义特征。与传统的关系型数据库(如 SQL Server)或 NoSQL 数据库(如 MongoDB)不同,向量数据库针对非结构化数据的处理进行了优化,尤其擅长高效的相似性搜索。
1.1 数据库演进
数据库技术的发展历程——从 SQL 到 NoSQL 再到向量数据库——反映了在日益复杂和数据丰富的世界中,数据管理需求的不断变化:
SQL 数据库:结构化的基石
SQL 数据库以其结构化的方法奠定了数据管理的基础。它通过严格的表结构和关系模型,确保了数据的完整性,并支持复杂的查询操作。这种技术在传统企业应用中占据主导地位,为数据的可靠存储和检索提供了坚实保障。
NoSQL 数据库:灵活与扩展的突破
随着互联网和大数据的兴起,NoSQL 数据库应运而生,带来了灵活性和可扩展性。它能够处理大量非结构化数据,适应现代网络应用和实时分析的需求。NoSQL 数据库打破了传统 SQL 的刚性结构,支持分布式架构,推动了高并发、高吞吐量场景下的数据管理发展。
向量数据库:AI 驱动的新前沿
向量数据库作为 AI 驱动应用的关键工具崭露头角。它通过高效存储和检索高维向量数据,为高级相似性搜索提供了支持,并通过上下文理解增强了 AI 模型的功能。向量数据库(如 Milvus 和 Zilliz Cloud——完全托管的 Milvus)在图像识别、自然语言处理等领域表现出色,成为数据管理的新方向。
三种数据库的全方位对比
| 特性 | SQL 数据库 | NoSQL 数据库 | 向量数据库 |
|---|---|---|---|
| 数据模型 | 关系型(表、行和列) | 非关系型(文档、键值、图等) | 基于向量(高维嵌入) |
| 模式 | 严格、预定义模式 | 灵活、动态模式 | 无模式;侧重于向量嵌入 |
| 查询语言 | 结构化查询语言(SQL) | 各异(NoSQL 查询语言、API) | 向量搜索方法(ANN、余弦相似度) |
| 数据类型关注 | 结构化数据 | 半结构化和非结构化数据 | 表示为向量的非结构化数据 |
| 可扩展性 | 垂直扩展(有限的水平扩展) | 水平扩展 | 高度可扩展,支持水平分布 |
| 用例示例 | 事务系统、分析 | 大数据、实时 Web 应用、分布式系统 | AI/ML 应用、相似性搜索 |
| 性能 | 针对复杂查询、连接优化 | 针对速度和可扩展性优化 | 针对高维向量相似性搜索优化 |
| 典型应用 | 银行、ERP、CRM 系统 | 社交网络、物联网、内容管理 | 图像检索、推荐引擎、NLP、RAG |
| 存储格式 | 行和列 | 各异(JSON、BSON 等) | 高维向量 |
这个表格清晰地比较了三种数据库类型在数据模型、模式、查询语言、数据类型关注、可扩展性、用例示例、性能、典型应用和存储格式等方面的差异,通过这张表格可以更好地理解它们的优势和适用场景。
二、向量数据库的技术原理与优化
2.1 向量数据库的核心特点
- 高维数据支持:能够存储和处理数百甚至数千维的向量数据。
- 相似性搜索:通过近似最近邻(Approximate Nearest Neighbor, ANN)算法,快速找到与查询向量最相似的向量。
- 高性能与可扩展性:支持大规模数据集的存储和查询,具备分布式部署能力。
- 与 AI 集成:无缝对接机器学习模型,便于嵌入生成和数据检索。
2.2 向量数据库的技术原理
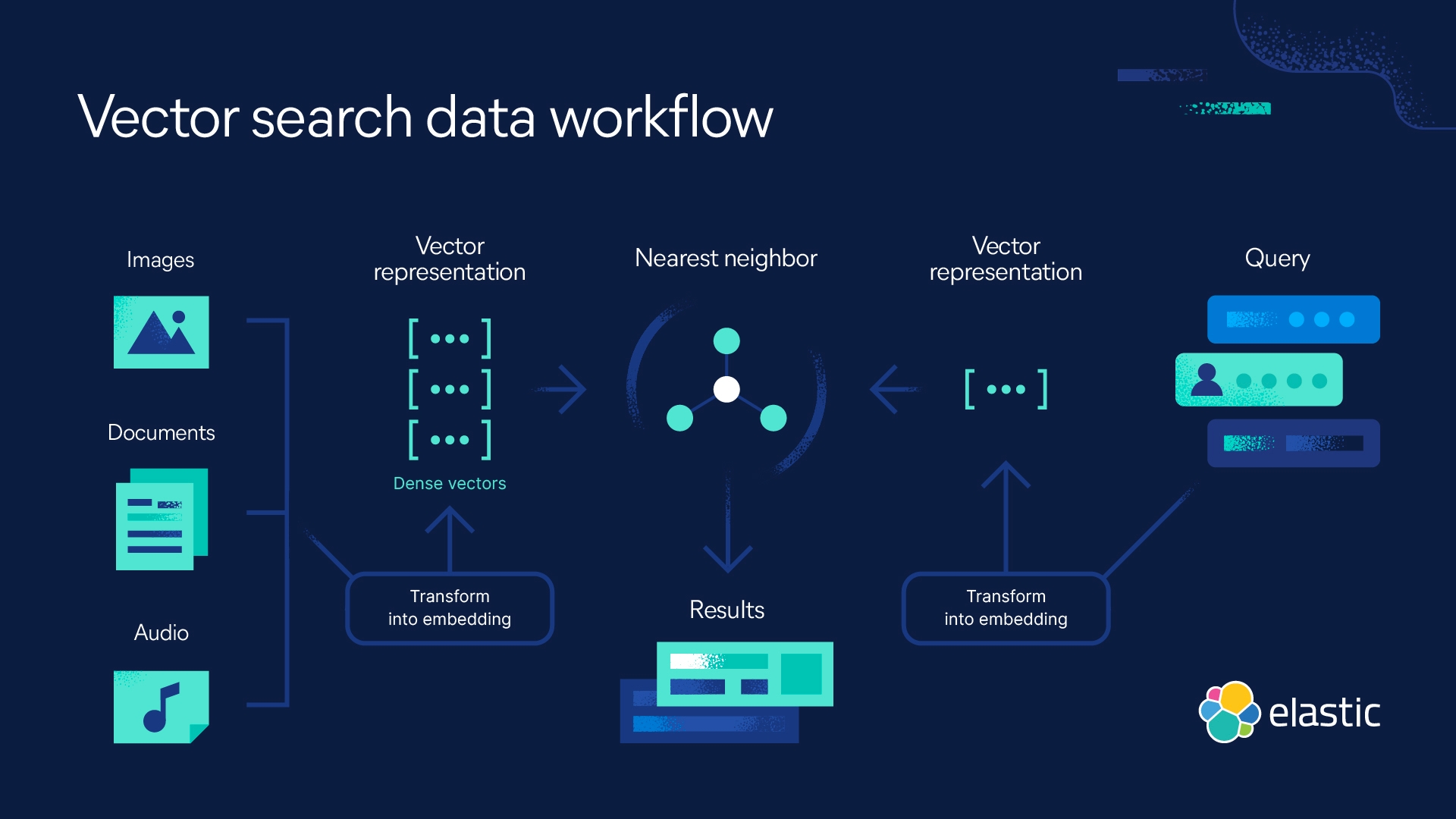
向量数据库的核心在于将复杂数据转化为向量形式,并利用高效的算法和数据结构实现快速的相似性搜索和分析。其技术原理主要包括以下几个方面:
向量表示
- 数据项(如图像、文本、用户行为等)通过特征提取被转换为高维向量。这些向量通常是多维空间中的点,捕捉了数据的特征和语义信息。例如,深度学习模型(如BERT或CNN)可以将文本或图像编码为固定长度的向量。
索引结构
- 为了加速高维向量的搜索,向量数据库依赖专门的索引结构。常见的索引包括:
- KD树:通过递归分割空间来组织向量,适用于低维数据。
- Ball树:基于球形分割,优化高维空间的查询。
- 层次聚类:将向量分组以减少搜索范围。
- 近似最近邻(ANN)算法:如HNSW(层次可导航小世界图),在效率和准确性间取得平衡。
相似性度量
- 向量之间的相似性通过数学度量来计算,常用的包括:
- 欧氏距离:衡量两点间的直线距离。
- 余弦相似度:计算向量夹角的余弦值,常用于语义相似性。
- 曼哈顿距离:基于坐标差值的绝对和。
- 选择合适的度量标准直接影响搜索的准确性和效率。
分布式存储
- 面对大规模数据,向量数据库通常采用分布式架构,将向量数据分散存储在多个节点上,并通过并行计算加速查询。这种设计确保了系统的高扩展性和处理能力。
2.3 向量数据库的优化策略
为了在处理大规模高维数据时保持高效性和准确性,向量数据库在索引、查询、存储和算法层面进行了多方面的优化。以下是具体的优化策略:
索引优化
- 量化技术:
- 例如产品量化(PQ),将高维向量分割为多个子空间,对每个子空间进行量化编码,从而减少存储需求和计算开销。
- 图索引:
- 如HNSW,通过构建多层图结构,利用图的导航特性实现高效的近似最近邻搜索,特别适合动态数据集。
查询优化
- 缓存机制:
- 将热门查询的结果缓存起来,避免重复计算,提升响应速度。
- 并行处理:
- 利用多核CPU或GPU并行执行向量计算,显著缩短查询时间。
存储优化
- 压缩技术:
- 对向量数据进行压缩,减少存储空间需求,同时保持数据的可用性。
- 数据分片:
- 根据数据访问模式将向量分片存储到不同节点,优化数据局部性,提高检索效率。
算法优化
- 近似搜索:
- 使用如**局部敏感哈希(LSH)**的近似算法,在保证一定准确率的前提下大幅提升搜索速度。
- 自适应算法:
- 根据数据分布和查询模式动态调整索引结构和搜索策略,确保系统在不同场景下的最优性能。
向量数据库通过将数据表示为高维向量,并结合高效的索引结构、相似性度量和分布式存储技术,实现了对大规模高维数据的快速检索和分析能力。在优化方面,它通过量化、图索引、缓存、并行处理、压缩和近似搜索等策略,进一步提升了性能和效率。这些技术原理和优化手段共同保障了向量数据库在实际应用中的高可用性和扩展性,使其成为现代AI和大数据领域的关键基础设施。
三、向量数据库在 .NET 中的应用
在 .NET 生态系统中,向量数据库的应用正在迅速扩展,尤其是在人工智能(AI)和机器学习(ML)的推动下。以下是一些典型的应用场景:
3.1 语义搜索
语义搜索是向量数据库在 .NET 中最常见的应用之一。通过将文本转换为向量嵌入,开发者可以实现超越关键词匹配的智能搜索。例如,Microsoft 的 Semantic Kernel 提供了一个开源框架,支持与多种向量数据库集成,使得在 .NET 应用中实现语义搜索变得更加简单。
3.2 推荐系统
推荐系统利用向量数据库存储用户和物品的向量表示,通过相似性搜索快速找到相似的用户偏好或推荐内容。例如,一个基于 .NET 的电商平台可以通过向量数据库为用户推荐相似的产品。
3.3 图像和视频检索
将图像或视频内容转换为向量嵌入后,向量数据库可以支持高效的多媒体检索。这种功能在 .NET 构建的内容管理系统或多媒体应用中尤为有用。
3.4 自然语言处理(NLP)
在 NLP 任务中,向量数据库可用于存储词向量或句子向量,支持文本分类、情感分析和问答系统等功能。例如,一个基于 .NET 的智能客服系统可以通过向量数据库快速检索知识库中的相关回答。
四、向量数据库的种类
目前,市场上有多种向量数据库可供选择,每种都有其独特优势和适用场景。以下是一些常见的向量数据库:
41 Chroma
Chroma 是一个开源的向量数据库,专为 AI 应用设计,支持高效的向量存储和相似性搜索。它提供了 C# SDK,方便与 .NET 集成。Chroma 的特点包括轻量级部署和易用性,适合中小型项目。

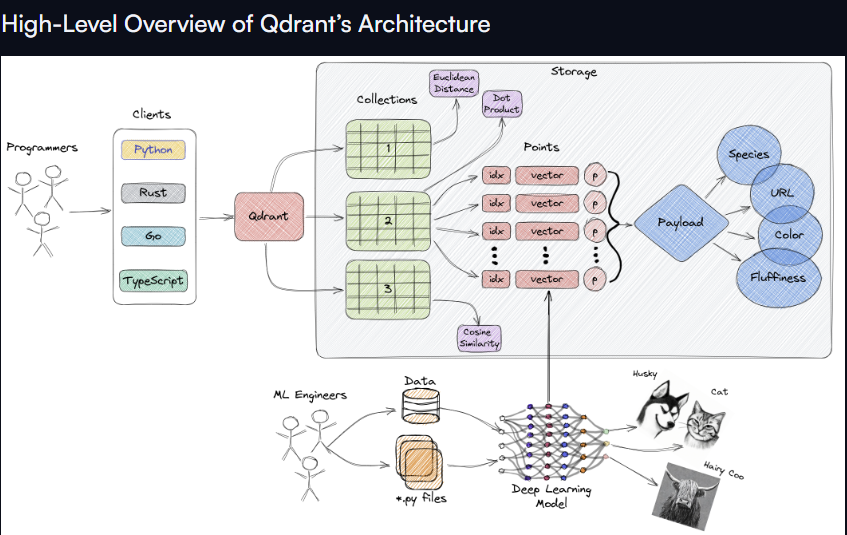
4.2 Qdrant
Qdrant 是一个高性能的向量数据库,支持实时搜索和过滤功能。它通过 REST API 和客户端库与 .NET 应用集成,适用于需要高吞吐量的场景,如实时推荐系统。
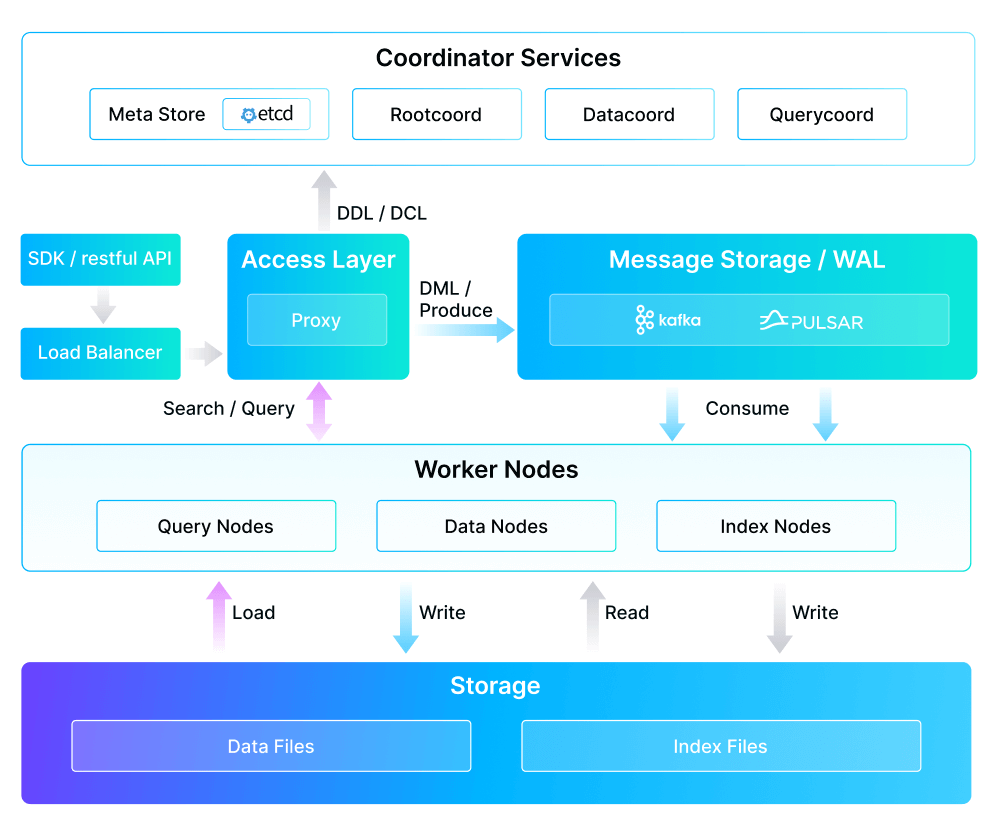
4.3 Milvus
Milvus 是一个开源的分布式向量数据库,专为大规模数据设计,支持多种索引类型(如 HNSW、IVF)。它提供了 C# 客户端,适合需要处理海量向量数据的 .NET 应用。
4.4 Pinecone
Pinecone 是一个托管的向量数据库服务,强调高可用性和易用性。虽然没有官方的 C# SDK,但开发者可以通过 REST API 使用 .NET 的 HTTP 客户端与之交互,适合快速原型开发。

4.5 weaviate
Weaviate 是一个开源的向量数据库,专门设计用于存储和查询高维嵌入向量(embeddings)。它广泛应用于语义搜索、问答系统和推荐系统等场景,提供高效的数据管理和查询解决方案。

4.6 Faiss
Faiss 是由 Facebook 开发的向量搜索库,虽然不是完整的数据库,但其高效的搜索算法被许多向量数据库采用。开发者可以在 .NET 中通过Semantic Kernel集成使用 Faiss。

五、向量数据库与 .NET 的结合方式
在 .NET 生态系统中,向量数据库的集成可以通过多种方式实现:
5.1 集成SDK
许多向量数据库提供了官方或社区支持的 C# 客户端库。例如,Chroma 和 Qdrant 都有相应的 SDK,开发者可以直接在 .NET 项目中调用这些库进行数据操作。
假设我们要开发一个基于 .NET 的文档管理系统,支持语义搜索功能。用户输入查询“什么是向量数据库”,系统返回语义相似的文档。
5.2 Semantic Kernel
Semantic Kernel 是 Microsoft 推出的开源框架,旨在帮助开发者构建 AI 驱动的应用。它提供了与多种向量数据库的连接器(如 Chroma、Qdrant),通过统一的 API 简化集成过程。开发者只需在 .NET 项目中配置 Semantic Kernel,即可使用向量数据库的功能。
5.3 REST API
对于没有专用 C# SDK 的向量数据库(如 Pinecone),开发者可以使用 .NET 的 HttpClient 调用 REST API。这种方式灵活性高,但需要手动处理请求和响应。
5.4 Microsoft.Extensions.VectorData
Microsoft.Extensions.VectorData 是 .NET 生态系统中用于处理向量数据的一个扩展组件。它通过抽象层屏蔽了不同向量数据库的实现细节,提供了一致的 API。开发者可以轻松切换底层数据库(如从 Chroma 切换到 Qdrant),而无需修改大量代码,并与 .NET 的依赖注入机制无缝集成。其主要特点包括:
- 统一接口:支持多种向量数据库的连接。
- 依赖注入:与 .NET 的服务提供者模型集成。
- 灵活性:允许开发者根据需求选择合适的数据库。
以下是一个与Qdrant结合的简单示例:
using Microsoft.Extensions.AI;
using Microsoft.Extensions.VectorData;
using Microsoft.SemanticKernel.Connectors.Qdrant;
using Qdrant.Client;
var vectorStore = new QdrantVectorStore(new QdrantClient("localhost"));
// get movie list
var movies = vectorStore.GetCollection<ulong, MovieVector<ulong>>("movies");
await movies.CreateCollectionIfNotExistsAsync();
var movieData = MovieFactory<ulong>.GetMovieVectorList();
// get embeddings generator and generate embeddings for movies
IEmbeddingGenerator<string, Embedding<float>> generator =
new OllamaEmbeddingGenerator(new Uri("http://localhost:11434/"), "all-minilm");
……
六、未来向量数据库在软件开发中的畅想
随着人工智能技术的不断进步,向量数据库在未来软件开发中的作用将愈发显著。以下是我对向量数据库未来发展趋势的一些畅想:
6.1 数据库技术的融合:直接采用向量数据库?
目前,数据库领域的主流仍是关系型数据库和 NoSQL 数据库,但向量数据库的崛起可能引发一场变革。未来,我们可能会看到一种混合型数据库的出现,将向量数据库的功能直接融入传统数据库中。例如,一个数据库系统可能同时支持 SQL 查询和向量相似性搜索,开发者无需在多个数据库之间切换即可处理结构化和非结构化数据。这种融合将极大简化开发流程,尤其是在需要同时处理元数据和嵌入的应用中。
6.2 大模型与 RAG 技术赋能 C 端用户
检索增强生成(Retrieval-Augmented Generation, RAG)技术是大模型与向量数据库结合的产物。它通过从向量数据库中检索相关信息,再由大模型生成自然语言回答,为用户提供更准确、更丰富的体验。未来,这种技术可能广泛应用于 C 端产品,例如:
- 智能搜索:用户输入模糊查询(如“找一张猫的图片”),系统通过向量数据库检索相似图像,并由大模型生成描述性文本。
- 个性化助手:一个基于 .NET 的手机应用,通过 RAG 技术为用户提供定制化的建议和回答。
- 内容创作工具:向量数据库存储大量素材,大模型根据用户需求生成文章或设计草稿。
6.3 向量数据库的普及与生态完善
随着工具和 SDK 的不断发展,向量数据库的入门门槛将进一步降低。未来,中小型开发团队也能轻松集成向量数据库,推动其在教育、医疗、金融等领域的广泛应用。例如,一个基于 .NET 的医疗系统可以通过向量数据库存储患者病历的向量表示,实现快速的病例匹配和诊断辅助。
七、结尾
向量数据库作为一种创新技术,正在为 .NET 开发者提供构建智能应用的强大工具。通过与 .NET 生态系统的紧密集成,它在语义搜索、推荐系统和多媒体检索等领域展现出巨大潜力。未来,随着数据库技术融合、大模型与 RAG 的广泛应用,以及工具生态的完善,向量数据库将成为软件开发的重要支柱,为 C 端用户带来更智能、更个性化的体验。
八、参考链接
- https://devblogs.microsoft.com/dotnet/tag/vectordb/
- https://learn.microsoft.com/zh-cn/semantic-kernel/concepts/vector-store-connectors/?pivots=programming-language-csharp
- https://github.com/microsoft/semantic-kernel/tree/main/dotnet/samples/Demos/VectorStoreRAG
- https://devblogs.microsoft.com/dotnet/tag/vectordb/
- https://devblogs.microsoft.com/dotnet/announcing-chroma-db-csharp-sdk/
- https://devblogs.microsoft.com/dotnet/vector-data-qdrant-ai-search-dotnet/
- https://thenewstack.io/sql-nosql-and-vectors-oh-my/