最近需要训练图卷积神经网络(Graph Convolution Neural Network, GCNN),在配置GCNN环境上总结了一些经验。
我觉得对于初学者而言,图神经网络的训练会有2个难点:
①环境配置
②数据集制作
一、环境配置
我最初光想到要给GCNN配环境就觉得有些困难,感觉相比于目标检测、分类识别这些任务用规则数据,图神经网络的模型、数据都是图,所以内心觉得会比较难。
我之前更有一个误区,就是觉得不规则结构的图数据不能用CUDA进行并行加速。实际上,图,在电脑里也是以张量这种规则结构数据存在的,完全能用CUDA进行加速计算,训练GCN前配置CUDA完全OK。
以下是我配置的环境,可用CUDA成功运行link_pred.py
几个关键包的版本:
torch 2.4.1
torch-geometric 2.3.1
torchaudio 2.4.1
torchvision 0.14.0
torchviz 0.0.2pandas 1.0.3
numpy 1.20.0
CUDA: 11.8
注意要先安装好CUDA,显示了:
再安装GPU版本的torch,不然python检测安装的是cpu版本的torch。这时,就得卸载重新安装了
环境配置成功:
print(torch.__version__)
print(torch.cuda.is_available())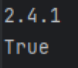
如果CUDA环境安装失败,会打印:
2.4.1+cpu
False其实只安装torch和CUDA还好,如果你的python中有numpy和pandas可能解决版本之间的冲突会耗费不少时间,我就是在numpy和pandas版本上试了很久,最终找到现在的版本是相互兼容的。
CUDA的版本切换可以参考我的另一篇博客:
CUDA版本切换
二、数据集制作
掌握图数据集制作的关键在于掌握slices切片:
for ...
data = Data(x=X, edge_index=Edge_index, edge_label_index=Edge_label_index, edge_label=Edge_label)
data_list.append(data)
data_, slices = self.collate(data_list) # 将不同大小的图数据对齐,填充
torch.save((data_, slices), self.processed_paths[0])和CNN不同的是,GCN没有样本维度,需要把所有样本拼成一张大图喂给GCN进行训练
数据集生成代码:
#作者:zhouzhichao
#创建时间:2025/5/30
#内容:生成200个样本的PYG数据集
import h5py
import hdf5storage
import numpy as np
import torch
from torch_geometric.data import InMemoryDataset, Data
from torch_geometric.utils import negative_sampling
base_dir = "D:\\无线通信网络认知\\论文1\\experiment\\直推式拓扑推理实验\\拓扑生成\\200样本\\"
N = 30
grapg_size = N
train_n = 31
M = 3000
class graph_data(InMemoryDataset):
def __init__(self, root, signals=None, tp_list = None, transform=None, pre_transform=None):
# self.Signals = Signals
# self.Tp_list = Tp_list
self.signals = signals
self.tp_list = tp_list
super().__init__(root, transform, pre_transform)
# self.data, self.slices = torch.load(self.processed_paths[0])
self.data = torch.load(self.processed_paths[0])
# 返回process方法所需的保存文件名。你之后保存的数据集名字和列表里的一致
@property
def processed_file_names(self):
return ['gcn_data.pt']
# 生成数据集所用的方法
def process(self):
# data_list = []
# for k in range(200):
# signals = self.Signals[:, :, k]
# tp_list = np.array(mat_file[self.Tp_list[0, k]])
signals = self.signals
tp_list =self.tp_list
# tp = Tp[:,:,k]
X = torch.tensor(signals, dtype=torch.float)
# 所有的边
Edge_index = torch.tensor(tp_list, dtype=torch.long)
# 所有的边1标签
edge_label = np.ones((tp_list.shape[1]))
# edge_label = np.zeros((tp_list.shape[1]))
Edge_label = torch.tensor(edge_label, dtype=torch.float)
neg_edge_index = negative_sampling(
edge_index=Edge_index, num_nodes=grapg_size,
num_neg_samples=Edge_index.shape[1], method='sparse')
# 拼接正负样本索引
# c = 0
# for i in range(31):
# for i in range(31):
# if torch.equal(Edge_index[:, i], neg_edge_index[:, i]):
# c = c + 1
# print("c: ",c)
Edge_label_index = Edge_index
perm = torch.randperm(Edge_index.size(1))
Edge_index = Edge_index[:, perm]
Edge_index = Edge_index[:, :train_n]
Edge_label_index = torch.cat(
[Edge_label_index, neg_edge_index],
dim=-1,
)
# 拼接正负样本
Edge_label = torch.cat([
Edge_label,
Edge_label.new_zeros(neg_edge_index.size(1))
], dim=0)
# Edge_label = torch.cat([
# Edge_label,
# Edge_label.new_ones(neg_edge_index.size(1))
# ], dim=0)
data = Data(x=X, edge_index=Edge_index, edge_label_index=Edge_label_index, edge_label=Edge_label)
torch.save(data, self.processed_paths[0])
# data_list.append(data)
# data_, slices = self.collate(data_list) # 将不同大小的图数据对齐,填充
# torch.save((data_, slices), self.processed_paths[0])
for snr in [0,20,40]:
print("snr: ", snr)
mat_file = h5py.File(base_dir + str(N) + '_nodes_dataset_snr-' + str(snr) + '_M_' + str(M) + '.mat', 'r')
# mat_file = hdf5storage.loadmat(base_dir + str(N) + '_nodes_dataset_snr-' + str(snr) + '_M_' + str(M) + '.mat', 'r')
# 获取数据集
Signals = mat_file["Signals"][()]
# signals = np.swapaxes(signals, 1, 0)
Tp = mat_file["Tp"][()]
Tp_list = mat_file["Tp_list"][()]
# tp_list = tp_list - 1
# 关闭文件
# mat_file.close()
# graph_data("gcn_data")
# n = Signals.shape[2]
n = 10
for i in range(n):
signals = Signals[:,:,i]
tp_list = np.array(mat_file[Tp_list[0, i]])
root = "gcn_data-"+str(i)+"_N_"+str(N)+"_snr_"+str(snr)+"_train_n_"+str(train_n)+"_M_"+str(M)
graph_data(root, signals = signals, tp_list = tp_list)
print("")
print("...图数据生成完成...")
训练代码:
#作者:zhouzhichao
#创建时间:25年5月29日
#内容:统计图中有关系节点和无关系节点的GCN特征欧式距离
import sys
import torch
import random
import numpy as np
import pandas as pd
from torch_geometric.nn import GCNConv
from sklearn.metrics import roc_auc_score
sys.path.append('D:\无线通信网络认知\论文1\experiment\直推式拓扑推理实验\GCN推理')
from gcn_dataset import graph_data
print(torch.__version__)
print(torch.cuda.is_available())
mode = "gcn"
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = GCNConv(Input_L, 1000)
self.conv2 = GCNConv(1000, 20)
def encode(self, x, edge_index):
x1 = self.conv1(x, edge_index)
x1_1 = x1.relu()
x2 = self.conv2(x1_1, edge_index)
x2_2 = x2.relu()
return x2_2
def decode(self, z, edge_label_index):
# 节点和边都是矩阵,不同的计算方法致使:节点->节点,节点->边
# nodes_relation = (z[edge_label_index[0]] * z[edge_label_index[1]]).sum(dim=-1)
# distances = torch.norm(z[edge_label_index[0]] - z[edge_label_index[1]], dim=-1)
distance_squared = torch.sum((z[edge_label_index[0]] - z[edge_label_index[1]]) ** 2, dim=-1)
# print("distance_squared: ",distance_squared)
return distance_squared
def decode_all(self, z):
prob_adj = z @ z.t() # 得到所有边概率矩阵
return (prob_adj > 0).nonzero(as_tuple=False).t() # 返回概率大于0的边,以edge_index的形式
@torch.no_grad()
def test(self,input_data):
model.eval()
z = model.encode(input_data.x, input_data.edge_index)
out = model.decode(z, input_data.edge_label_index).view(-1)
out = 1 - out
N = 30
train_n = 31
M = 3000
# snr = -20
# for train_n in range(1,51):
# for M in range(3000, 499, -100):
for snr in [0,20,40]:
print("snr: ", snr)
for I in range(10):
root = "gcn_data-"+str(I)+"_N_"+str(N)+"_snr_"+str(snr)+"_train_n_"+str(train_n)+"_M_"+str(M)
gcn_data = graph_data(root)
Input_L = gcn_data.x.shape[1]
model = Net()
# model = Net().to(device)
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.01)
criterion = torch.nn.BCEWithLogitsLoss()
def train():
model.train()
optimizer.zero_grad()
z = model.encode(gcn_data.x, gcn_data.edge_index)
# out = model.decode(z, train_data.edge_label_index).view(-1).sigmoid()
out = model.decode(z, gcn_data.edge_label_index).view(-1)
out = 1 - out
loss = criterion(out, gcn_data.edge_label)
loss.backward()
optimizer.step()
return loss
min_loss = 99999
count = 0#早停
for epoch in range(10000):
loss = train()
if loss<min_loss:
min_loss = loss
count = 0
count = count + 1
if count>100:
break
print("epoch: ",epoch," loss: ",round(loss.item(),2), " min_loss: ",round(min_loss.item(),2))
z = model.encode(gcn_data.x, gcn_data.edge_index)
out = model.decode(z, gcn_data.edge_label_index).view(-1)
list_0 = []
list_1 = []
for i in range(len(gcn_data.edge_label)):
true_label = gcn_data.edge_label[i].item()
euclidean_distance_value = out[i].item()
if true_label==1:
list_1.append(euclidean_distance_value)
if true_label==0:
list_0.append(euclidean_distance_value)
minlength = min(len(list_1), len(list_0))
list_1 = random.sample(list_1, minlength)
list_0 = random.sample(list_0, minlength)
value = list_1 + list_0
large_class = list(np.full(len(value), snr))
small_class = list(np.full(len(list_1), 1)) + list(np.full(len(list_0), 0))
data = {
'large_class': large_class,
'small_class': small_class,
'value': value
}
# 创建一个 DataFrame
df = pd.DataFrame(data)
#
# # 保存到 Excel 文件
file_path = 'D:\无线通信网络认知\论文1\大修意见\图聚类、阈值相似性图实验补充\\' + mode + '_similarity_' + str(snr) + 'db_'+str(I)+'.xlsx'
df.to_excel(file_path, index=False)