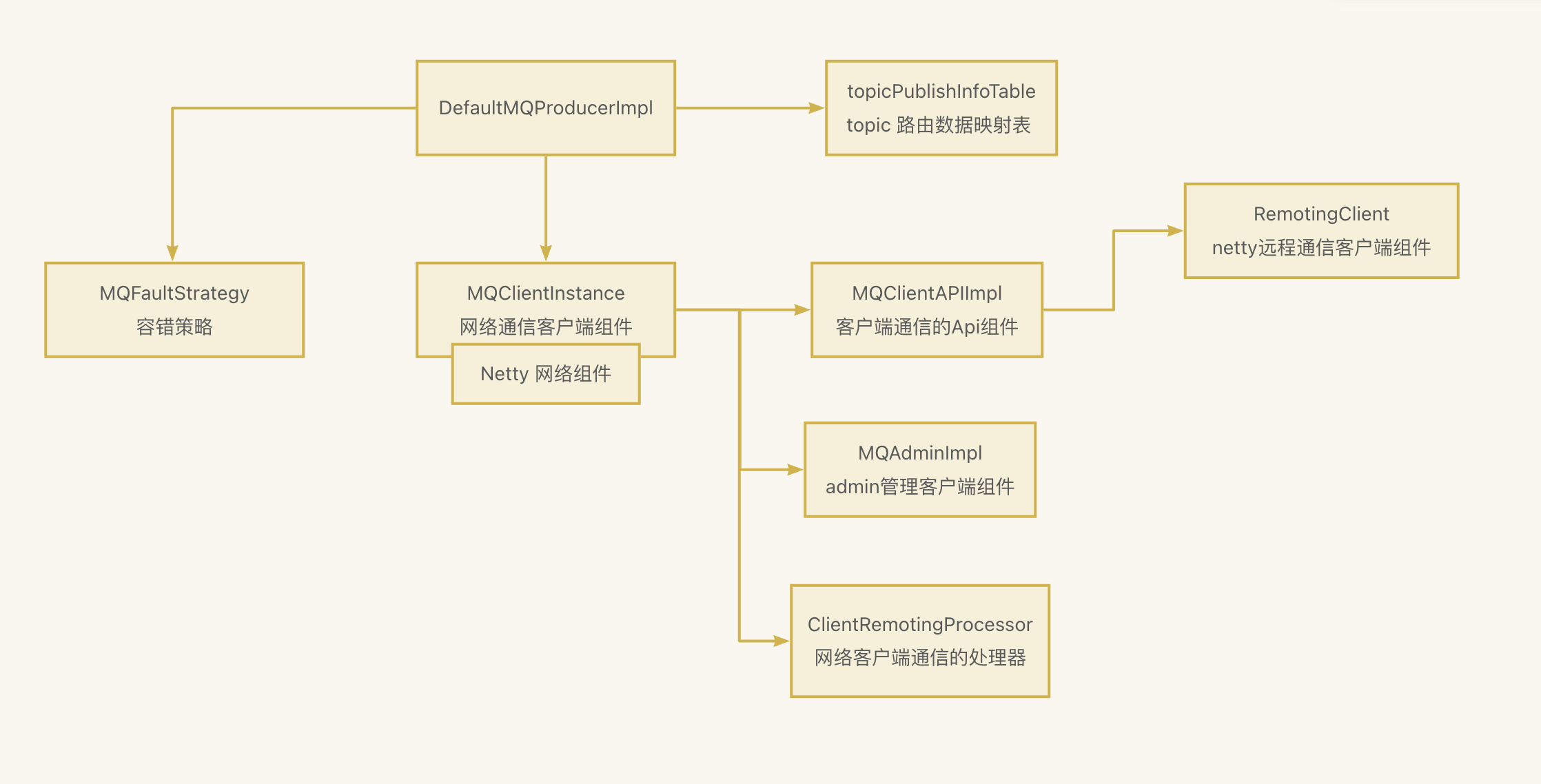
文章目录
- 一、张量运算的计算量
- 1. FLOPs定义
- 2. 张量计算顺序对计算量的影响
- 二、MLA第一次矩阵吸收的计算量分析
- 1. 原始注意力计算
- 2. MLA源代码中的吸收方式
- 3. 提前吸收
- 4. 比较分析
- 4.1 比较顺序1和顺序2
- 4.2 比较顺序2和顺序3
- 三、MLA第二次矩阵吸收的计算量分析
- 1. 原始输出计算
- 2. MLA源代码中的吸收方式
- 3. 提前吸收
- 4. 比较分析
- 4.1 比较顺序1和顺序2
- 4.2 比较顺序2和顺序3
- 参考链接
一、张量运算的计算量
1. FLOPs定义
FLOPs:Floating Point Operations 指的是浮点运算次数,一般特指乘加运算次数,理解为计算量,可以用来衡量算法/模型时间的复杂度。更大的计算量单位通常包括:
- MFLOPs:百万次浮点运算( 10 6 10^6 106 FLOPs)。
- GFLOPs:十亿次浮点运算( 10 9 10^9 109 FLOPs)。
- TFLOPs:万亿次浮点运算( 10 12 10^{12} 1012 FLOPs)。
张量运算的计算量通常与运算维度和操作类型有关,以pytorch中线性层nn.Linear的计算为例,设输入张量的维度为
B
×
S
×
D
B \times S \times D
B×S×D,线性层内部权重矩阵维度为
D
×
O
D \times O
D×O:
- 若不考虑
bias,两个张量相乘的结果维度为 B × S × O B \times S \times O B×S×O,结果中的每个元素是由原始张量分别沿着 D D D维度进行了 D D D次乘法和 D − 1 D-1 D−1次加法而来的,因此总计算量为:
( 2 D − 1 ) × B × S × O (2D-1)\times B \times S \times O (2D−1)×B×S×O
- 若考虑
bias,则每个元素由原始张量分别沿着 D D D维度进行 D D D次乘法和 D − 1 D-1 D−1次加法后,还需加上bias,因此一共也执行了 D D D次加法,总计算量为:
2 D × B × S × O 2D \times B \times S \times O 2D×B×S×O
为了简单起见,后续分析时均以考虑bias来分析,这样FLOPs的计算可直接由相关维度的相乘而来。
2. 张量计算顺序对计算量的影响
张量计算顺序的不同会影响计算量。以下是一个例子:
假设有三个张量 A A A、 B B B 和 C C C,它们的形状分别为:
- A A A: ( m , n ) (m, n) (m,n)
- B B B: ( n , p ) (n, p) (n,p)
- C C C: ( p , q ) (p, q) (p,q)
我们需要计算 A × B × C A \times B \times C A×B×C,其中 × \times × 表示矩阵乘法。
计算顺序 1:先计算 A × B A \times B A×B,再乘以 C C C
- 计算
A
×
B
A \times B
A×B:
- 结果形状为 ( m , p ) (m, p) (m,p)。
- 每个元素的计算量为 2 n 2n 2n( n n n 次乘法和 n n n 次加法)。
- 总计算量: m × p × 2 n = 2 m n p m \times p \times 2n = 2mnp m×p×2n=2mnp。
- 计算
(
A
×
B
)
×
C
(A \times B) \times C
(A×B)×C:
- 结果形状为 ( m , q ) (m, q) (m,q)。
- 每个元素的计算量为 2 p 2p 2p( p p p 次乘法和 p p p 次加法)。
- 总计算量: m × q × 2 p = 2 m p q m \times q \times 2p = 2mpq m×q×2p=2mpq。
- 总计算量: 2 m n p + 2 m p q 2mnp + 2mpq 2mnp+2mpq。
计算顺序 2:先计算 B × C B \times C B×C,再乘以 A A A
- 计算
B
×
C
B \times C
B×C:
- 结果形状为 ( n , q ) (n, q) (n,q)。
- 每个元素的计算量为 2 p 2p 2p( p p p 次乘法和 p p p 次加法)。
- 总计算量: n × q × 2 p = 2 n p q n \times q \times 2p = 2npq n×q×2p=2npq。
- 计算
A
×
(
B
×
C
)
A \times (B \times C)
A×(B×C):
- 结果形状为 ( m , q ) (m, q) (m,q)。
- 每个元素的计算量为 2 n 2n 2n( n n n 次乘法和 n n n 次加法)。
- 总计算量: m × q × 2 n = 2 m n q m \times q \times 2n = 2mnq m×q×2n=2mnq。
- 总计算量: 2 n p q + 2 m n q 2npq + 2mnq 2npq+2mnq。
比较两种计算顺序:
-
计算顺序 1的总计算量为 2 m n p + 2 m p q 2mnp + 2mpq 2mnp+2mpq。
-
计算顺序 2的总计算量为 2 n p q + 2 m n q 2npq + 2mnq 2npq+2mnq。
-
将上述两式相减,有:
2 [ m n ( p − q ) + p q ( m − n ) ] 2[mn(p-q)+pq(m-n)] 2[mn(p−q)+pq(m−n)]
可见如果 p < q , m < n p<q,m<n p<q,m<n则必定计算顺序1的计算量更小,如果 p > q , m > n p>q,m>n p>q,m>n则反之,其余情况 则需根据具体数值分析。
二、MLA第一次矩阵吸收的计算量分析
我们比较三种计算顺序:
假设原始序列 h \mathbf{h} h经Q低秩压缩后得到 c Q \mathbf{c}^Q cQ,经KV低秩压缩得到 c K V \mathbf{c}^{KV} cKV,它们的上投影矩阵分别为 W U Q W^{UQ} WUQ和 W U K W^{UK} WUK。
1. 原始注意力计算
原始注意力计算如下:
(
W
U
Q
c
Q
)
T
(
W
U
K
c
K
V
)
(W^{UQ}\mathbf{c}^Q)^T (W^{UK}\mathbf{c}^{KV})
(WUQcQ)T(WUKcKV)
上述张量的形状如下,箭头右边是简记的符号,并将n_heads × qk_nope_head_dim进行了拆分:
-
W
U
Q
W^{UQ}
WUQ :
(q_lora_rank, n_heads × qk_nope_head_dim) -> (q, h, d) -
c
Q
\mathbf{c}^Q
cQ :
(bsz, q_seq_len, q_lora_rank) -> (b, s, q) -
W
U
K
W^{UK}
WUK :
(kv_lora_rank, n_heads × qk_nope_head_dim) -> (k, h, d) -
c
K
V
\mathbf{c}^{KV}
cKV :
(bsz, k_seq_len, kv_lora_rank) -> (b, t, k) - Step 1:
W
U
Q
c
Q
W^{UQ}\mathbf{c}^Q
WUQcQ:
(bsz, q_seq_len, n_heads, qk_nope_head_dim) -> (b, s, h, d) - Step 2:
W
U
K
c
K
V
W^{UK}\mathbf{c}^{KV}
WUKcKV:
(bsz, k_seq_len, n_heads, qk_nope_head_dim) -> (b, t, h, d) - Step 3:
(
W
U
Q
c
Q
)
T
(
W
U
K
c
K
V
)
(W^{UQ}\mathbf{c}^Q)^T (W^{UK}\mathbf{c}^{KV})
(WUQcQ)T(WUKcKV):
(bsz, n_heads, q_seq_len, k_seq_len) -> (b, h, s, t)
这里区分q_seq_len和k_seq_len,训练或prefill时二者是一致的,decode时q_seq_len是1,k_seq_len是cache的长度。
根据张量计算量分析的规则,计算量如下:
FLOPs
order
1
=
2
b
s
h
d
q
+
2
b
t
h
d
k
+
2
b
h
s
t
d
\text{FLOPs}_{\text{order}_1}=2bshdq+2bthdk+2bhstd
FLOPsorder1=2bshdq+2bthdk+2bhstd
2. MLA源代码中的吸收方式
[ ( W U Q c Q ) T W U K ] c K V [(W^{UQ}\mathbf{c}^Q)^T W^{UK}]\mathbf{c}^{KV} [(WUQcQ)TWUK]cKV
- Step 1:
W
U
Q
c
Q
W^{UQ}\mathbf{c}^Q
WUQcQ:
(bsz, q_seq_len, n_heads, qk_nope_head_dim) -> (b, s, h, d) - Step 2:
(
W
U
Q
c
Q
)
T
W
U
K
(W^{UQ}\mathbf{c}^Q)^TW^{UK}
(WUQcQ)TWUK:
(bsz, q_seq_len, n_heads, kv_lora_rank) -> (b, s, h, k) - Step 3:
[
(
W
U
Q
c
Q
)
T
W
U
K
]
c
K
V
[(W^{UQ}\mathbf{c}^Q)^T W^{UK}]\mathbf{c}^{KV}
[(WUQcQ)TWUK]cKV:
(bsz, n_heads, q_seq_len, k_seq_len) -> (b, h, s, t)
计算量如下:
FLOPs
order
2
=
2
b
s
h
d
q
+
2
b
s
h
k
d
+
2
b
h
s
t
k
\text{FLOPs}_{\text{order}_2}=2bshdq+2bshkd+2bhstk
FLOPsorder2=2bshdq+2bshkd+2bhstk
3. 提前吸收
c Q T ( W U Q T W U K ) c K V {\mathbf{c}^Q}^T(W^{UQ^T} W^{UK})\mathbf{c}^{KV} cQT(WUQTWUK)cKV
- Step 1:
W
U
Q
T
W
U
K
W^{UQ^T} W^{UK}
WUQTWUK:
(n_heads, q_lora_rank, kv_lora_rank) -> (h, q, k) - Step 2:
c
Q
T
(
W
U
Q
T
W
U
K
)
{\mathbf{c}^Q}^T(W^{UQ^T} W^{UK})
cQT(WUQTWUK):
(bsz, q_seq_len, n_heads, kv_lora_rank) -> (b, s, h, k) - Step 3:
c
Q
T
(
W
U
Q
T
W
U
K
)
c
K
V
{\mathbf{c}^Q}^T(W^{UQ^T} W^{UK})\mathbf{c}^{KV}
cQT(WUQTWUK)cKV:
(bsz, n_heads, q_seq_len, k_seq_len) -> (b, h, s, t)
计算量如下:
FLOPs
order
3
=
2
h
q
k
d
+
2
b
s
h
k
q
+
2
b
h
s
t
k
\text{FLOPs}_{\text{order}_3}=2hqkd+2bshkq+2bhstk
FLOPsorder3=2hqkd+2bshkq+2bhstk
4. 比较分析
4.1 比较顺序1和顺序2
首先比较
FLOPs
order
1
\text{FLOPs}_{\text{order}_1}
FLOPsorder1和
FLOPs
order
2
\text{FLOPs}_{\text{order}_2}
FLOPsorder2,有:
FLOPs
order
1
−
FLOPs
order
2
=
2
b
h
d
k
(
t
−
s
)
+
2
b
h
s
t
(
d
−
k
)
\text{FLOPs}_{\text{order}_1}-\text{FLOPs}_{\text{order}_2}= 2bhdk(t-s)+2bhst(d-k)
FLOPsorder1−FLOPsorder2=2bhdk(t−s)+2bhst(d−k)
其中:
t:k_seq_lens:q_seq_lend:qk_nope_head_dim = 128k:kv_lora_rank = 512h:n_heads = 128b:bsz由于第一项和第二项都有b,为简单起见,设为1
在训练或prefill阶段,t=s,上式结果为
−
98304
s
2
-98304s^2
−98304s2,此时顺序1的计算量更优。
在decode阶段,t是缓存长度,而s=1,上式结果为
16777216
(
t
−
1
)
−
98304
t
=
16678912
t
−
16777216
16777216(t-1)-98304t=16678912t-16777216
16777216(t−1)−98304t=16678912t−16777216,可见,推理时随着缓存长度t的变大,顺序1需要花费更大的计算量,因此才需要把
W
U
K
W^{UK}
WUK吸收进
W
U
Q
c
Q
W^{UQ}\mathbf{c}^Q
WUQcQ(也就是代码中的q_nope)中,避免产生的中间量需要大量的计算。
4.2 比较顺序2和顺序3
然后比较
FLOPs
order
2
\text{FLOPs}_{\text{order}_2}
FLOPsorder2和
FLOPs
order
3
\text{FLOPs}_{\text{order}_3}
FLOPsorder3,有:
FLOPs
order
2
−
FLOPs
order
3
=
2
h
d
q
(
b
s
−
k
)
+
2
b
s
h
k
(
d
−
q
)
\text{FLOPs}_{\text{order}_2}-\text{FLOPs}_{\text{order}_3}= 2hdq(bs-k)+2bshk(d-q)
FLOPsorder2−FLOPsorder3=2hdq(bs−k)+2bshk(d−q)
其中:
q:q_lora_rank = 1536b:bsz第一项的b无法作为因子提出,因此先不假定具体值
上式结果中不包含t,结果为
50331648
(
b
s
−
512
)
−
184549376
b
s
=
−
134217728
b
s
−
25769803776
50331648(bs-512)-184549376bs=-134217728bs-25769803776
50331648(bs−512)−184549376bs=−134217728bs−25769803776,恒小于0,因此顺序2的计算量优于顺序3。其原因是
(
W
U
Q
T
W
U
K
)
(W^{UQ^T} W^{UK})
(WUQTWUK)充当了新的
W
U
Q
′
W^{UQ'}
WUQ′,其形状为(h, q, k),具有100663296个元素。而
W
U
Q
W^{UQ}
WUQ和
W
U
K
W^{UK}
WUK的形状分别为(q, h, d)和(k, h, d),二者之和只有33554432个元素,约为
W
U
Q
′
W^{UQ'}
WUQ′的33%,这就解释了虽然公式上直接将
W
U
K
W^{UK}
WUK吸收进了
W
U
Q
W^{UQ}
WUQ,但为什么代码实现上不这么做的原因。不论是从参数量占用还是计算量上,顺序3都没有优势。
三、MLA第二次矩阵吸收的计算量分析
同样比较三种计算顺序:
假设得到的score形状大小为(bsz, n_heads, q_seq_len, k_seq_len),
c
K
V
\mathbf{c}^{KV}
cKV向value的上投影矩阵为
W
U
V
W^{UV}
WUV,输出维度变换 矩阵为
W
O
W^O
WO。
1. 原始输出计算
原始计算顺序如下:
W
O
[
s
c
o
r
e
(
W
U
V
c
K
V
)
]
W^O[score(W^{UV} \mathbf{c}^{KV})]
WO[score(WUVcKV)]
上述张量的形状如下,将n_heads × v_head_dim进行了拆分:
-
s
c
o
r
e
score
score:
(bsz, n_heads, q_seq_len, k_seq_len) -> (b, h, s, t) -
c
K
V
\mathbf{c}^{KV}
cKV:
(bsz, k_seq_len, kv_lora_rank) -> (b, t, k) -
W
U
V
W^{UV}
WUV:
(kv_lora_rank, n_heads × v_head_dim) -> (k, h, v) -
W
O
W^O
WO:
(n_heads × v_head_dim, dim) -> (h, v, e) - Step 1:
W
U
V
c
K
V
W^{UV} \mathbf{c}^{KV}
WUVcKV:
(bsz, k_seq_len, n_heads, v_head_dim) -> (b, t, h, v) - Step 2:
[
s
c
o
r
e
(
W
U
V
c
K
V
)
]
[score(W^{UV} \mathbf{c}^{KV})]
[score(WUVcKV)]:
(bsz, n_heads, q_seq_len, v_head_dim) -> (b, h, s, v) - Step 3:
W
O
[
s
c
o
r
e
(
W
U
V
c
K
V
)
]
W^O[score(W^{UV} \mathbf{c}^{KV})]
WO[score(WUVcKV)]:
(bsz, n_heads, q_seq_len, dim) -> (b, h, s, e)
计算量如下:
FLOPs
order
1
=
2
b
t
h
v
k
+
2
b
h
s
v
t
+
2
b
h
s
e
v
\text{FLOPs}_{\text{order}_1}=2bthvk+2bhsvt+2bhsev
FLOPsorder1=2bthvk+2bhsvt+2bhsev
2. MLA源代码中的吸收方式
W O [ W U V ( s c o r e c K V ) ] W^O[W^{UV} (score\mathbf{c}^{KV})] WO[WUV(scorecKV)]
- Step 1:
s
c
o
r
e
c
K
V
score\mathbf{c}^{KV}
scorecKV:
(bsz, n_heads, q_seq_len, kv_lora_rank) -> (b, h, s, k) - Step 2:
[
W
U
V
(
s
c
o
r
e
c
K
V
)
]
[W^{UV} (score\mathbf{c}^{KV})]
[WUV(scorecKV)]:
(bsz, n_heads, q_seq_len, v_head_dim) -> (b, h, s, v) - Step 3:
W
O
[
W
U
V
(
s
c
o
r
e
c
K
V
)
]
W^O[W^{UV} (score\mathbf{c}^{KV})]
WO[WUV(scorecKV)]:
(bsz, n_heads, q_seq_len, dim) -> (b, h, s, e)
计算量如下:
FLOPs
order
2
=
2
b
h
s
k
t
+
2
b
h
s
v
k
+
2
b
h
s
e
v
\text{FLOPs}_{\text{order}_2}=2bhskt+2bhsvk+2bhsev
FLOPsorder2=2bhskt+2bhsvk+2bhsev
3. 提前吸收
( W O W U V ) ( s c o r e c K V ) (W^OW^{UV})(score\mathbf{c}^{KV}) (WOWUV)(scorecKV)
- Step 1:
W
O
W
U
V
W^OW^{UV}
WOWUV:
(n_heads, kv_lora_rank, dim) -> (h, k, e) - Step 2:
s
c
o
r
e
c
K
V
score\mathbf{c}^{KV}
scorecKV:
(bsz, n_heads, q_seq_len, kv_lora_rank) -> (b, h, s, k) - Step 3:
(
W
O
W
U
V
)
(
s
c
o
r
e
c
K
V
)
(W^OW^{UV})(score\mathbf{c}^{KV})
(WOWUV)(scorecKV):
(bsz, n_heads, q_seq_len, dim) -> (b, h, s, e)
计算量如下:
FLOPs
order
3
=
2
h
k
e
v
+
2
b
h
s
k
t
+
2
b
h
s
e
k
\text{FLOPs}_{\text{order}_3}=2hkev+2bhskt+2bhsek
FLOPsorder3=2hkev+2bhskt+2bhsek
4. 比较分析
4.1 比较顺序1和顺序2
首先比较
FLOPs
order
1
\text{FLOPs}_{\text{order}_1}
FLOPsorder1和
FLOPs
order
2
\text{FLOPs}_{\text{order}_2}
FLOPsorder2,有:
FLOPs
order
1
−
FLOPs
order
2
=
2
b
h
v
k
(
t
−
s
)
+
2
b
h
s
t
(
v
−
k
)
\text{FLOPs}_{\text{order}_1}-\text{FLOPs}_{\text{order}_2}=2bhvk(t-s)+2bhst(v-k)
FLOPsorder1−FLOPsorder2=2bhvk(t−s)+2bhst(v−k)
其中:
t:k_seq_lens:q_seq_lenv:v_head_dim = 128k:kv_lora_rank = 512h:n_heads = 128b:bsz由于第一项和第二项都有b,为简单起见,设为1
由于v与d值大小一样,因此计算结果与与第一次矩阵吸收一致。即在训练或prefill阶段,顺序1更优,在decode阶段,顺序2更优。
4.2 比较顺序2和顺序3
然后比较
FLOPs
order
2
\text{FLOPs}_{\text{order}_2}
FLOPsorder2和
FLOPs
order
3
\text{FLOPs}_{\text{order}_3}
FLOPsorder3,有:
FLOPs
order
2
−
FLOPs
order
3
=
2
h
v
k
(
b
s
−
e
)
+
2
b
h
s
e
(
v
−
k
)
\text{FLOPs}_{\text{order}_2}-\text{FLOPs}_{\text{order}_3}=2hvk(bs-e)+2bhse(v-k)
FLOPsorder2−FLOPsorder3=2hvk(bs−e)+2bhse(v−k)
其中:
e:dim = 7168b:bsz第一项的b无法作为因子提出,因此先不假定具体值
上式结果为 16777216 ( b s − 7168 ) − 704643072 b s = − 687865856 b s − 120259084288 16777216(bs-7168)-704643072bs=-687865856bs −120259084288 16777216(bs−7168)−704643072bs=−687865856bs−120259084288,可见仍然是顺序2的计算结果更优。
参考链接
- 训练模型算力的单位:FLOPs、FLOPS、Macs 与 估算模型(FC, CNN, LSTM, Transformers&&LLM)的FLOPs - 知乎
- llm 参数量-计算量-显存占用分析 - Zhang
- DeepSeek-V3 MLA 优化全攻略:从低秩压缩到权重吸收,揭秘高性能推理的优化之道 - 知乎