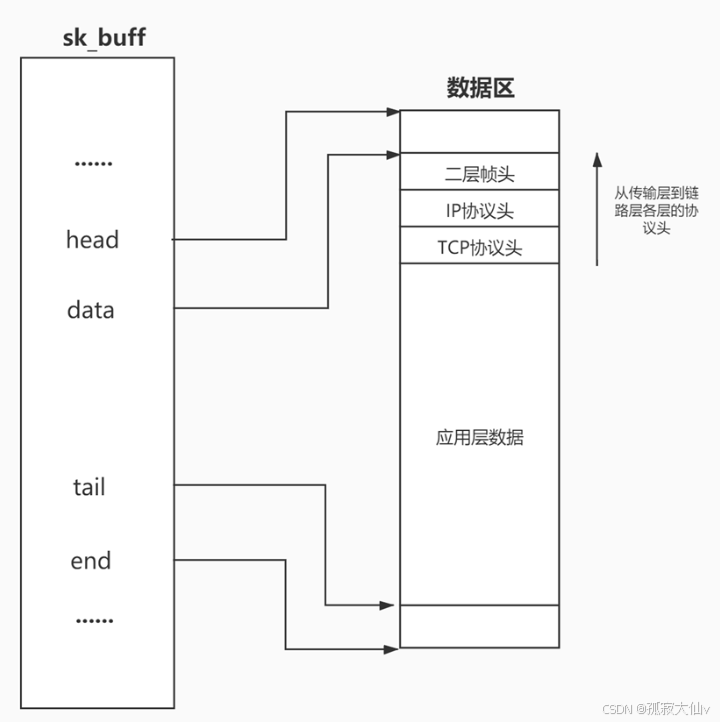
最近在学习数据库知识,发现 “数据库三范式” 这个概念特别重要,今天就来和大家分享一下我的理解,欢迎各位指正
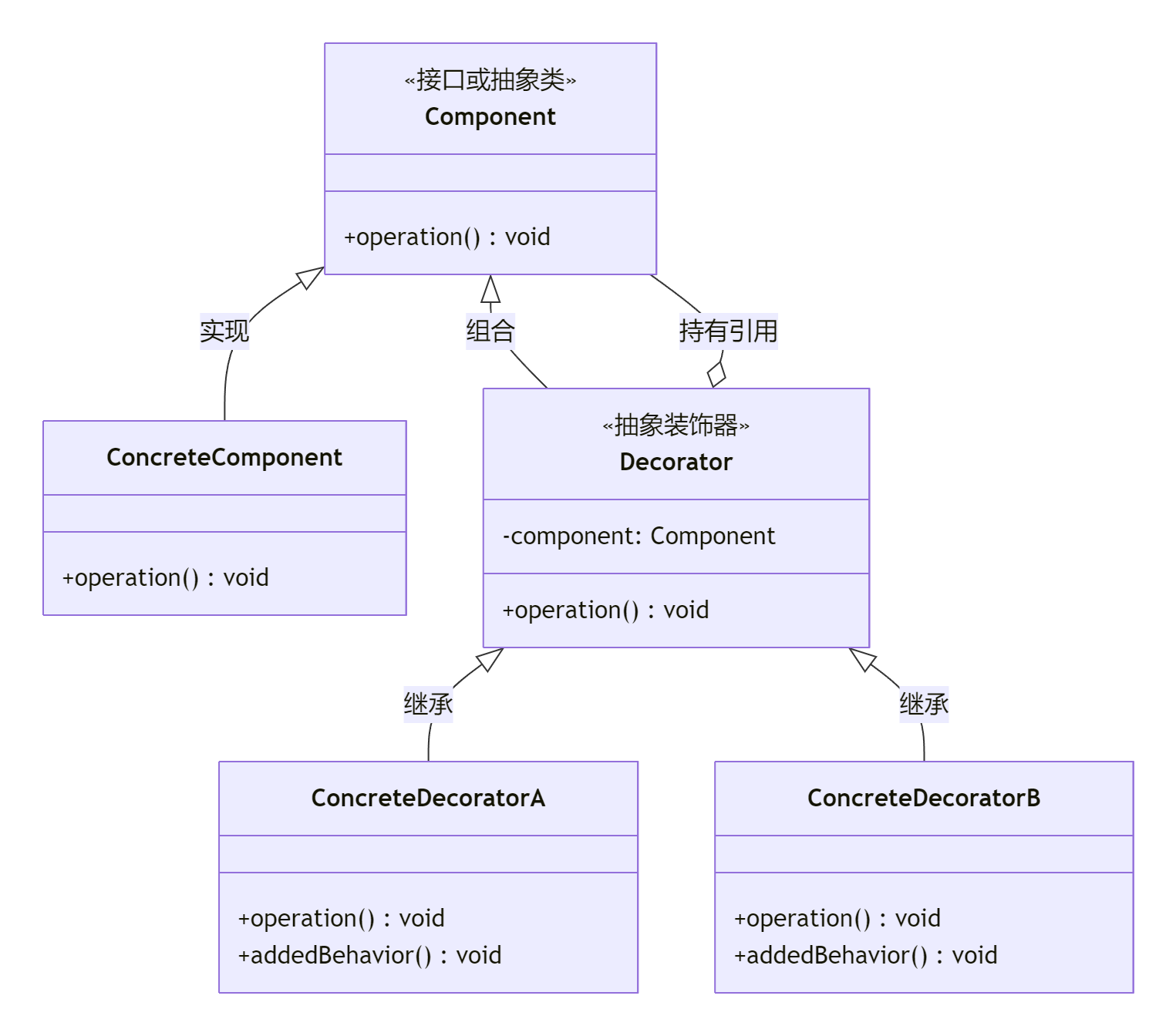
一、数据库三范式是什么?
数据库三范式是为了让数据库结构更合理、减少数据冗余、提高数据完整性的设计规则。
第一范式(1NF)就像我们整理东西时,把每个物品都放在不能再拆分的最小格子里。在数据库里,就是每个列都要是不可再分的最小单元格。比如说 “地址” 这个列,如果存的数据是 “黑龙江省哈尔滨市南岗区”,那最好拆分成 “省”“市”“区” 三个列,这样每个单元格的信息都是最基础、不能再分割的了。
第二范式(2NF)是在满足第一范式的基础上,所有非主键列都要依赖于主键列。主键就像是每个数据行的 “身份证号”,是唯一标识。比如学生成绩表,主键是 “学生 ID” 和 “课程 ID” 的组合,那 “成绩” 这个非主键列就完全依赖于这两个主键列,因为只有确定了是哪个学生、哪门课程,才能确定对应的成绩。
第三范式(3NF)是对第二范式的进一步补充,在满足第二范式的基础上,所有非主键列必须直接依赖于主键列。也就是说,非主键列之间不能存在传递依赖。比如在员工表中,有 “员工 ID”“部门 ID”“部门所在地”,“部门所在地” 是依赖于 “部门 ID”,而不是直接依赖 “员工 ID”,这种情况就不符合第三范式,应该把 “部门 ID” 和 “部门所在地” 单独拿出来建一个部门表,让数据结构更清晰。
但是实际工作中通常不会遵循三范式
虽然遵循三范式能减少数据冗余,让数据更完整、更规范,但在实际工作里,很多时候并不会严格遵循。因为严格遵循三范式后,会出现一个问题 —— 查询效率降低
这是因为遵循三范式后,数据被拆分到不同的表中,当我们需要获取某些信息时,就不得不进行联表查询。联表查询就是把多个表的数据按照一定条件关联起来,而这正是导致数据库性能降低的一个原因吧。
联表查询效率为啥低?
这就涉及到一个概念 —— 笛卡尔积。笛卡尔积就像是做排列组合游戏,假设有两个集合,集合 a 里有元素 x 和 y,集合 b 里有元素 1、2、3,那 a 和 b 的笛卡尔积就是 a*b={(x,1),(x,2),(x,3),(y,1),(y,2),(y,3)} 。放到数据库里,如果我们查询 a 表,本来只需要查询 2 条数据,但一旦产生笛卡尔积,就可能需要查询 6 条数据,数据量一大,查询的时间自然就变长了。
以上就是我对数据库三范式的学习心得啦,要是有理解不对的地方,欢迎大家在评论区指正,一起学习进步!