目录
通识
查询的基本语法
数据库(database)操作
表(table)的操作
表中列的操作
索引操作
表中行的操作
insert into语句
update语句
删除语句
select语句
表与表之间的关系
连接查询
子查询
视图
数据备份与还原
事务安全
触发器
通识
1.SQL 对大小写不敏感:SELECT 与 select 是相同的
2.分号是在数据库系统中分隔每条 SQL 语句的标准方法,这样就可以在对服务器的相同请求中执行一条以上的 SQL 语句,故在运行两条及以上SQL语句时需要在每条SQL语句末端添加分号。
3.SQL 使用单引号来环绕文本值(大部分数据库系统也接受双引号)。
4.约束类型:主键,非空,唯一,默认值,外键等
5.数据类型:整数,小数,字符串,日期,枚举等
查询的基本语法
| 语句 | 备注 |
| select | 投影数据表中的列,存储到一个结果集中 (distinct关键词用于返回唯一不同的值) |
| from | |
| where | 设置元组筛选条件,返回那些满足指定条件的记录 (运算符:=,<>,>,<,>=,<=,and,or,between,like,in,is,()) |
| group by | |
| having | |
| order by | 对结果集按照一列或者多列进行排序 (asc升序(默认),desc降序) |
| limit |
数据库(database)操作
#创建数据库:
create database 数据库名;
create database 数据库名 character set 字符集;
#创建之后修改数据库编码
alter database 数据库名 character set 字符集;
#查看所有的数据库:
show databases;
#查看某个数据库的定义的信息:
show create database 数据库名;
#删除数据库:
drop database 数据库名称;
#切换数据库:
use 数据库名;
#查看正使用的数据库
select database();表(table)的操作
#创建表:
create table 表名(
字段名 类型(长度) 约束,
字段名 类型(长度) 约束
);
#查看所有表:
show tables;
#查看表的结构:
1) desc 表名;
2) show columns from 表名;
#删除表:
drop table 表名;
#修改表名
rename table 表名 to 新表名;
#修改表达字符集:
alter table 表名 character set 字符集;表中列的操作
#添加列
1)添加一个字段
alter table 表名 add 列名 类型约束 (after 某个字段);
2)添加多个字段
alter table 表名 add (列名1 类型约束1,列名2 类型约束2)
#修改列的类型约束:
alter table 表名 modify 列名 类型约束
#修改列名
alter table 表名 change 列名 类型约束
#删除列
alter table 表名 drop 列名;索引操作
#已存在的表
#普通索引:
1)CREATE INDEX 索引名称 ON 表名(字段);
2)ALTER TABLE 表名 ADD INDEX 索引名称(字段);
#唯一索引:
CREATE UNIQUE INDEX 索引名称 ON 表名(字段)
#联合索引:
CREATE INDEX 索引名称 ON 表名(字段1,字段2...)
#删除索引
DROP INDEX 索引名称 ON 表名;表中行的操作
insert into语句
#第一种:不指定列名,插入的值要和列名一一对应 insert into table_name values (valuel1,valuel2,...); #第二种:指定列名,未被指定的列名值为空 insert into table_name(column1,column2,...) valuse (valuel1,valuel2,...); #IGNORE关键字会在发生主键冲突、唯一性冲突,直接忽略这条数据(不会报错)往下执行。 INSERT [IGNORE] INTO 表名 ......; #蠕虫复制:先从已用表中查出数据, 然后将查出的数据新增一遍 #可以迅速的让表中的数据膨胀到一定的数量级: 测试表的压力以及效率 Insert into 表名[(字段列表)] select 字段列表/* from 数据表名;update语句
#更新数据 UPDATE [IGNORE] 表名 SET 字段1=值1, 字段2=值2, ...... [WHERE 条件1 ......] [ORDER BY 排列的列 desc/asc] [LIMIT ......]; #如果这里有limit关键字,那么后面只能跟一个参数,即表示取前多少条数据, #UPDATE语句中的外/内连接 UPDATE 表1 [空/left/right/full] JOIN 表2 SET 字段1=值1, ... WHERE 条件;删除语句
#删除表数据,保留表的结构,数据库中该表还存在 DELETE [IGNORE] FROM 表名 [WHERE 条件1, 条件2, ...] [ORDER BY ...] [LIMIT ...]; #完全删除表,包括表结构,数据库就查不到这个表了 drop table 表名 #只能删除全表数据,会保留表结构,数据库中该表还存在 truncate table 表名select语句
#查询数据 Select [DISTINCT] [字段别名/*] from 表名(多表连接) [where条件子句] [group by子句] [having子句] [order by子句] [limit 子句];
表与表之间的关系
一对一
一对多
多对多
连接查询
内连接(左右表相同部分的交集)
1)join select * from A join B on A.id = B.id 2) inner join select * from A inner join B on A.id = B.id 3)逗号的连表方式就是内连接 select * from A , B where A.id = B.id外连接
如果右表有符合条件的记录就与左表连接。如果右表没有符合条件的记录,就用NULL与左表连接。
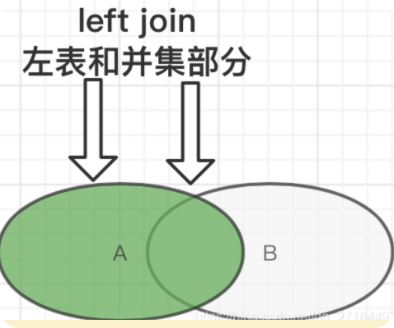
1) left/right join select * from A left join B on A.id = B.id 2) left/right outer join select * from A left outer join B on A.id = B.id自然连接 natural join
基于具有相同名称的列自动执行连接操作
笛卡尔连接 cross join
返回两个表中所有可能的行组合
子查询
类别
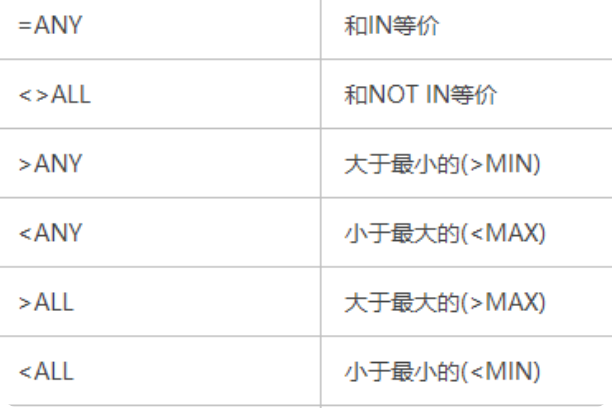
相关子查询:select 和 where语句后的子查询(效率低,不推荐使用但可以使用)
不相关子查询:from 语句后的子查询(√)
关键字
视图
定义
视图是一个虚拟表。它基于一个或多个底层基表(物理存在的表)或其他视图的 SQL 查询结果。视图本身不存储数据,它只是一个存储起来的 SELECT 语句。
特性
- 虚拟性: 数据是动态生成的,每次查询视图时,数据库引擎都会执行其定义的 SQL 语句去获取最新的基表数据。
- 可更新性 (并非所有视图都可更新): 在某些条件下,可以通过视图对基表进行
INSERT,UPDATE,DELETE操作。- 可嵌套: 视图可以基于其他视图定义(但要避免循环依赖)。视图 (
CREATE VIEW)视表的操作
#创建视图 CREATE VIEW 视图名 AS 查询语句; #查询视图:和查询普通表一样 #查看视图定义 SHOW CREATE VIEW 视图名; #修改视图 ALTER VIEW 视图名 AS 查询语句; #有则修改,无则创建 CREATE OR REPLACE VIEW 视图名 AS 查询语句; #删除视图:IF EXISTS 防止因视图不存在而报错。 DROP VIEW [IF EXISTS] view_name
数据备份与还原
- 数据表备份(表结构+表数据):数据表备份有前提条件: 根据不同的存储引擎有不同的区别
- 单表数据备份
- SQL备份:系统会对表结构以及数据进行处理,变成对应的SQL语句, 然后进行备份: 还原的时候只要执行SQL指令即可.(主要就是针对表结构)
- 增量备份(日志文件):指定时间段开始进行备份., 备份数据不会重复, 而且所有的操作都会备份(大项目都用增量备份)
事务安全
定义
- 事务: 一系列要发生的连续的操作(即一组SQL语句)
- 事务安全: 一种保护连续操作同时满足(实现)的一种机制
- 事务安全的意义: 保证数据操作的完整性
事务属性
- 原子性,一个事物中的所有操作要么全部完成,要么全部失败。事物执行后,不允许停留在中间某个状态。
- 一致性,不管在任何给定的时间,并发事务有多少,事务必须保证运行结果的一致性。事务可以并发执行,但是最终MySQL却串行执行。
- 隔离性,每个事务只能看到事务内的相关数据,别的事务的临时数据在当前事务是看不到的。隔离性要求事务不受其他并发事务的影响,在给定时间内,该事务是数据库运行的唯一事务。
- 持久性,事务一旦提交,结果便是永久性的。即便发生宕机,仍然可依靠事务日志完成数据持久化。
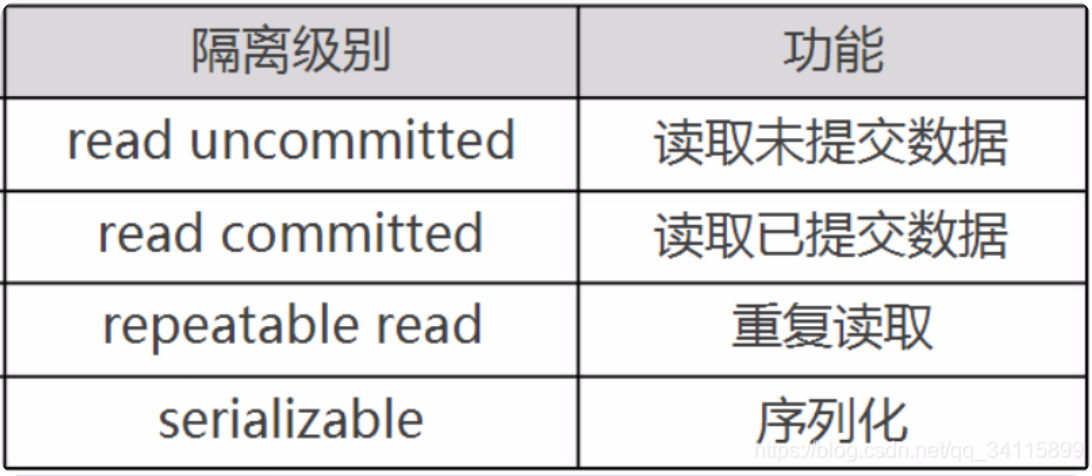
隔离级别
事务问题(隔离属性会引发的问题)
- 脏读:事务 A 读取了事务 B 当前更新的数据,但是事务 B 出现了回滚或未提交修改,事务 A 读到的数据就被称为 “脏数据”。通常情况下,使用 “脏数据” 会造成系统数据不一致,出现错误
- 不可重复读:事务 A 在执行过程中多次读取同一数据,但是事务 B 在事务 A 的读取过程中对数据做了多次修改并提交,则会导致事务 A 多次读取的数据不一致,进而无法做出准确性判断
- 幻读:事务 A 在执行过程中读取了一些数据,但是事务 B 随即插入了一些数据,那么,事务 A 重新读取时,发现多了一些原本不存在的数据,就像是幻觉一样,称之为幻读
事务操作-手动管理
开启事务:start transaction; 事务内容:SQL语句; 事务关闭:commit; 【事务回滚:rollback;】事务操作-自动管理
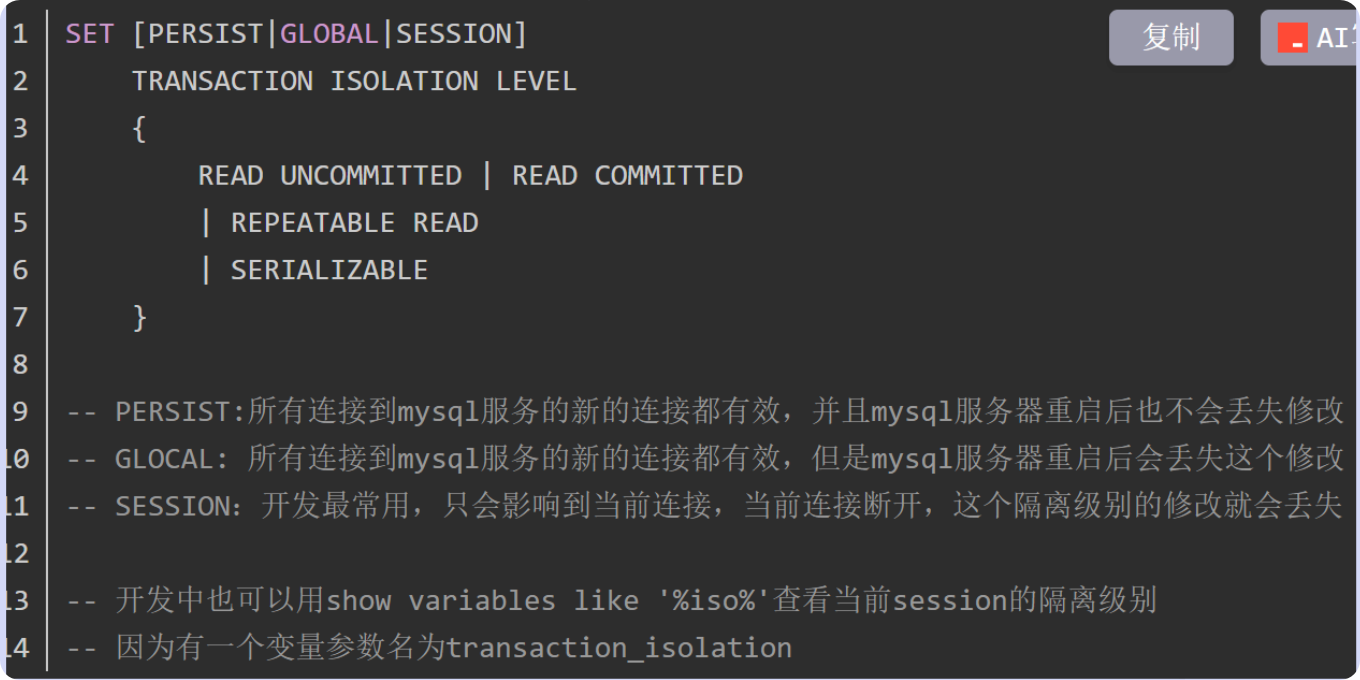
自动事务: 系统通过autocommit变量控制 查看是否开启:Show variables like ‘autocommit’; 开启自动提交: set autocommit = on/1;
触发器
定义
触发器 trigger:事先为某张表绑定好一段代码 ,当表中的某些内容发生改变的时候(增删改)系统会自动触发代码执行.
触发器: 事件类型, 触发时间, 触发对象
事件类型: 增删改, 三种类型insert,delete和update
创建触发器
#在mysql高级结构中: 没有大括号, 都是用对应的字符符号代替 -- 临时修改语句结束符 Delimiter 自定义符号 -- 后续代码中只有碰到自定义符号才算结束 Create trigger 触发器名字 触发时间 事件类型 on 表名 for each row Begin -- 代表左大括号: 开始 -- 里面就是触发器的内容: 每行内容都必须使用语句结束符: 分号 End -- 代表右带括号: 结束 自定义符号 -- 将临时修改修正过来查看触发器
#查看所有触发器或者模糊匹配 Show triggers [like ‘pattern’]; \g 的作用是分号和在sql语句中写’;’是等效的 \G 的作用是将查到的结构旋转90度变成纵向 #可以查看触发器创建语句 Show create trigger 触发器名字; #系统视图(Information_schema)的触发器的定义信息 Information_schema.triggers删除&修改
触发器不能修改,只能先删除,后新增. #删除 Drop trigger 触发器名字;
![[ Qt ] | QPushButton常见用法](https://i-blog.csdnimg.cn/direct/334f8a5a97c54445aae4804912a67fcf.png)