随着人工智能的快速发展,尤其是在深度学习和强化学习领域,声学计算和人机交互进入前所未有的扩展和创新阶段。尽管传统声学方法取得了显著成功,但这些线性或准线性方法在实际环境中往往存在关键的不足,尤其在动态、复杂或混响环境中,远场语音处理、弱声信号检测和复杂的噪声抑制仍然是亟待解决的问题。
传统声学解决方案主要依赖于物理模型,如几何房间模型和线性波动方程,来描述声传播现象。然而,在实际场景中,声场常常违反线性和平稳性的假设,导致经典模型无法快速适应或准确处理高阶效应。
为了解决这些限制,声智科技(SoundAI Technology)的研究团队提出了一种创新的框架,将非线性声学计算与深度强化学习相结合,显著提升了复杂声学环境下的人机交互性能。论文发表在arXiv上,并同步公布全栈算法的测试数据,多项指标均处于业界领先水平。

论文题目:A Synergistic Framework of Nonlinear Acoustic Computing and Reinforcement Learning for Real-World Human-Robot Interaction
代码链接:https://github.com/soundai2016/nonlinear-acoustic-rl-hri
论文链接:https://arxiv.org/abs/2505.01998
核心技术解析
非线性声学建模是该系统的理论基础。与传统的线性声学模型不同,研究团队采用了更精确的 Westervelt方程 和 KZK (Khokhlov-Zabolotskaya-Kuznetsov)方程来描述声波传播。这些高阶偏微分方程能够捕捉真实环境中的多种非线性声学现象:
-
谐波生成:声波在传播过程中产生高频谐波成分
-
波形畸变:声波形状随传播距离发生改变
-
冲击波形成:高强度声波在非线性介质中的特殊传播特性
-
声饱和效应:声波振幅达到一定强度后出现的非线性衰减
这些方程在数学上可表示为:
Westervelt方程:
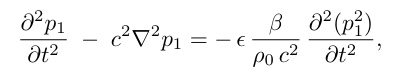
KZK方程:
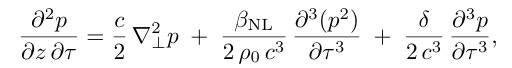
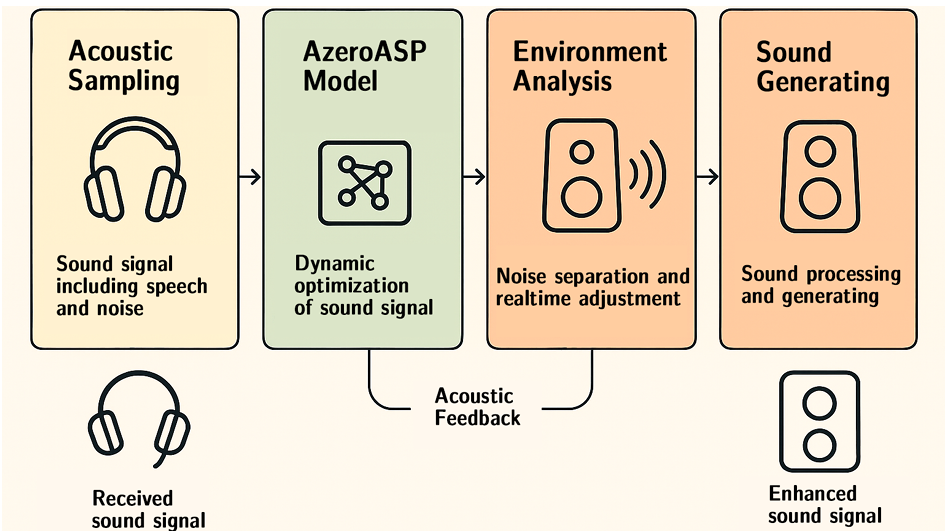
这些方程中的关键参数(如非线性系数α、吸收系数δ等)并非固定不变,而是通过强化学习系统进行动态优化调整。研究团队设计了一个基于近端策略优化(PPO)的强化学习框架,该系统通过持续与环境互动,学习如何根据实时声学条件调整模型参数和信号处理策略。
强化学习代理的决策过程可描述为:
-
状态(st):当前声学环境特征、模型参数估计和识别置信度
-
动作(at):对传播系数、滤波器增益和波束成形权重的增量调整
-
奖励(rt):综合考虑识别准确率、计算延迟和能耗的复合指标
这种动态调整机制使系统能够适应各种复杂多变的声学环境,包括:快速变化的噪声场景(如突然出现的机械噪声)、强混响环境(如大型会议室、地下停车场)、多说话人重叠对话场景、远场语音采集场景等等。
技术优势
1.卓越的噪声抑制能力
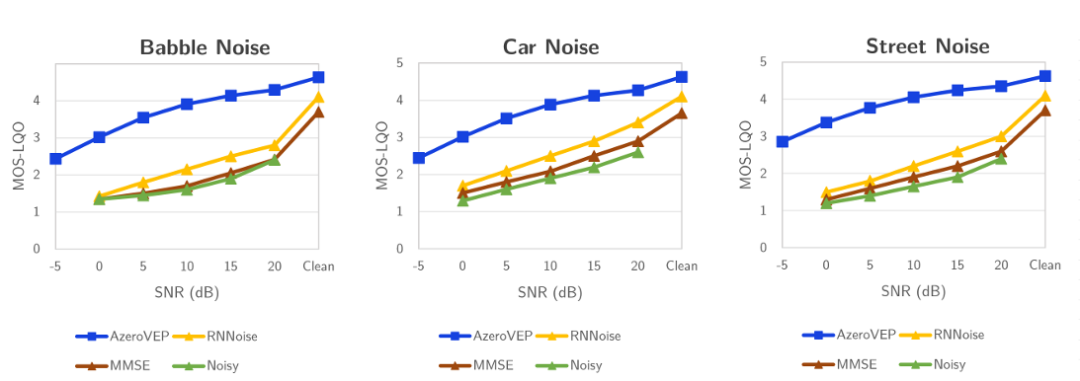
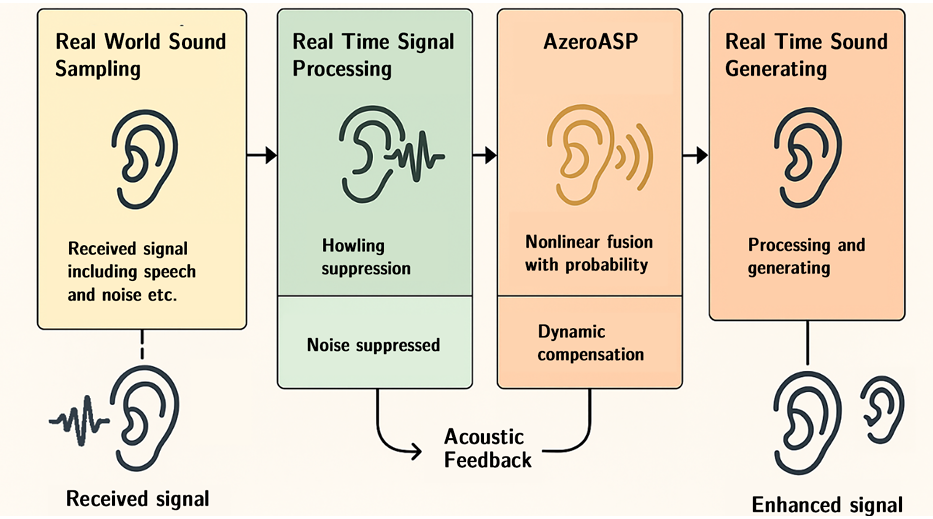
在噪声抑制方面,该系统提出的AzeroVEP(语音增强处理)算法在各类噪声环境下均表现出色。实验数据显示:在工业级高噪声环境(如100 dB)中,能将语音信噪比提升高达12 dB,远超传统方法(通常为8-10 dB)。在不同信噪比条件下都表现出色,低信噪比(如低于 0dB)时,仍可有效识别并保留关键语音内容;在Babble噪声(多人说话背景)下,MOS-LQO(语音质量客观评估)得分达到4.29(满分5分),远超RNNoise(2.8)和MMSE(2.4)等传统算法。

2.高精度语音识别与克隆
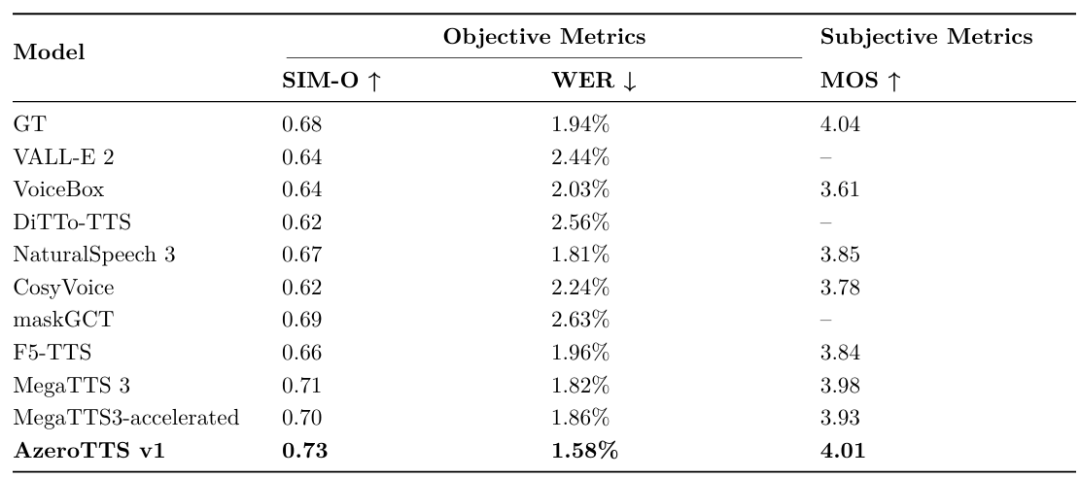
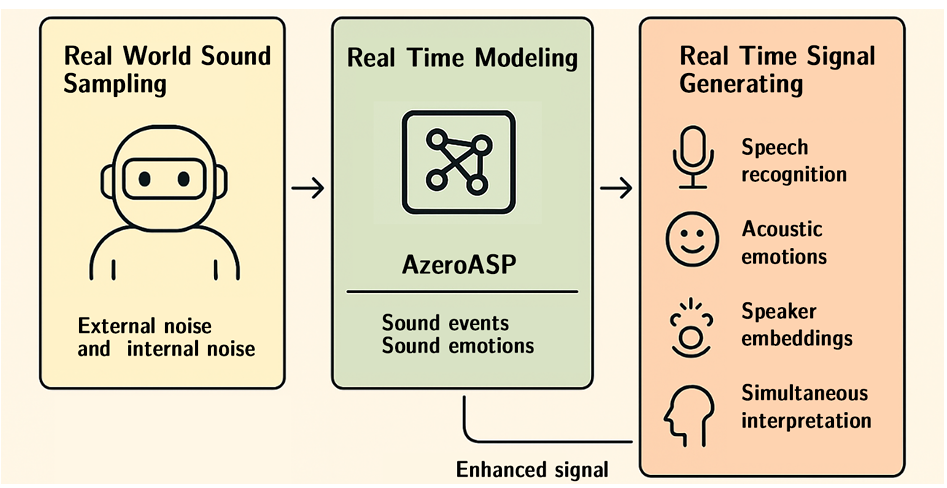
支持66种语言的实时交互,在中文和英语测试集(如AISHELL-1、Fleurs)上的词错误率(WER)分别低至1.63%和5.12%,优于Whisper等国际模型。此外,其语音克隆技术(AzeroTTS)仅需10秒即可生成高保真克隆声音,相似度(SIM-O)达0.73,接近人类录音水平。
3.低延迟与强适应性
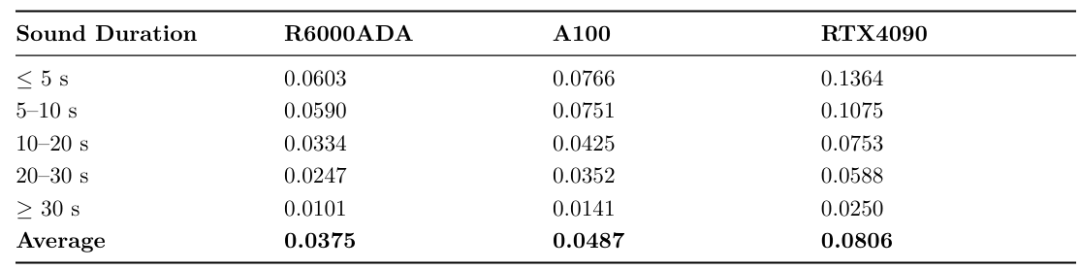
结合波束成形和残差网络优化,系统在边缘设备上的实时因子(RTF)低至0.0375,计算效率提升5倍。强化学习模块还能根据环境反馈(如突发噪声或多路径干扰)自动调整参数,无需人工干预。
4.高级情境理解能力
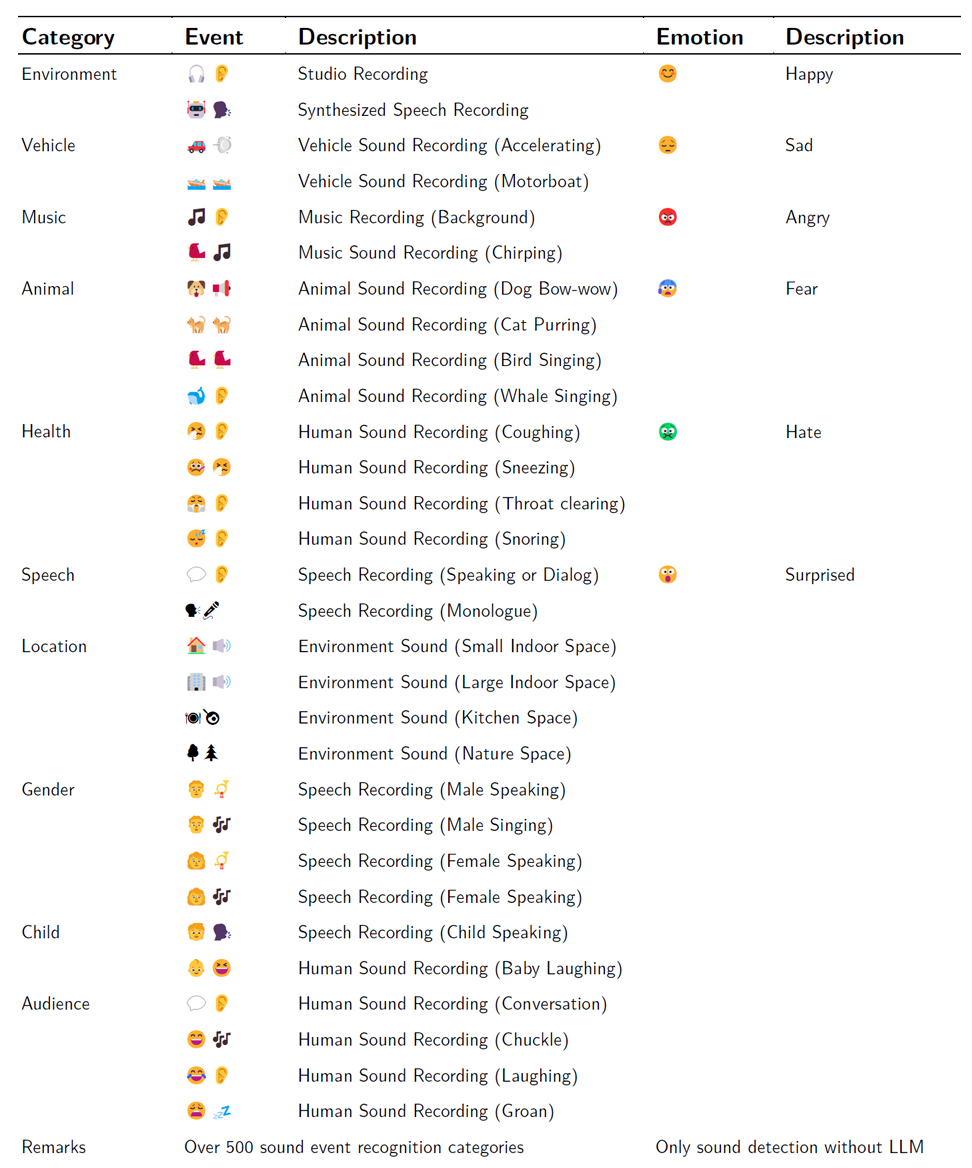
除了基本语音处理外,系统还具备先进的情境理解能力。在强噪声环境下,可准确区分多种声音情感及400+声学环境事件(如开门声、脚步声、警报声等),在不同应用场景中能深入理解用户意图,提供高质量的交互服务。
应用前景
这项融合了非线性声学计算和强化学习的技术,凭借其在复杂声学环境下的卓越性能,在多个领域展现出广泛且极具潜力的应用前景。
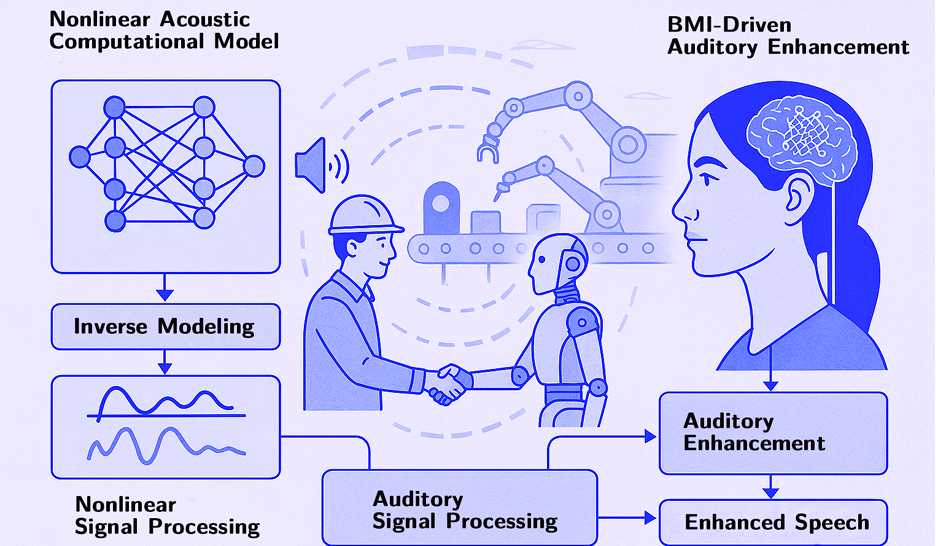
1.AI硬件领域
-
AI耳机和智能音箱:AI 耳机可利用先进声学模型和深度学习,根据环境噪声和用户生理 cues 自动优化音频播放,在嘈杂环境中精准定位目标语音,提升用户聆听体验。智能音箱能更准确识别语音指令、推断用户情感状态并相应调整播放内容,成为家庭环境中的智能助手。
-
AI麦克风和机器人听觉系统:AI 麦克风与机器人听觉系统结合深度学习与多语言语音识别,可在复杂声学环境中准确捕捉声音、识别指令并判断情感。在机器人领域,能提升机器人的情境感知和交互能力,使其成为真正的智能帮手。
2.医疗技术领域
-
AI助听器:实时适应环境和用户状态,智能调节输出参数,提升佩戴者的语音清晰度和舒适度,改善生活质量。
-
听力测试和脑机接口:AI 驱动的听力测试系统借助非线性声学计算评估耳道内声波传播,辅助医生更高效准确地诊断听力问题。脑机接口系统利用该技术将神经信号转化为更自然的语音输出,为神经系统疾病患者带来新希望。
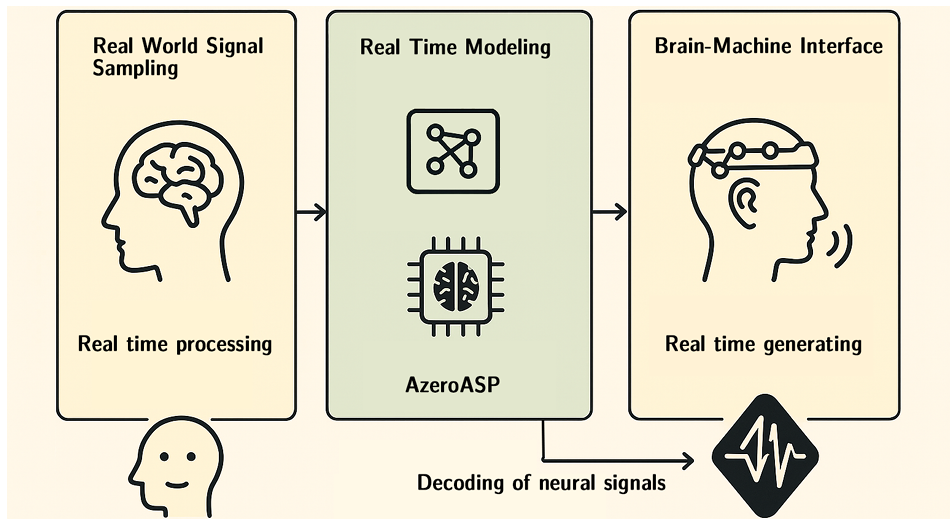
3.智能交通领域
在智能汽车中,该技术可实现车内噪声抑制、精准语音识别和情感感知。车辆能实时捕捉驾驶员语音指令,分析情感状态并做出响应,同时通过处理外部声学信号评估交通状况,提升驾驶安全性和舒适性。
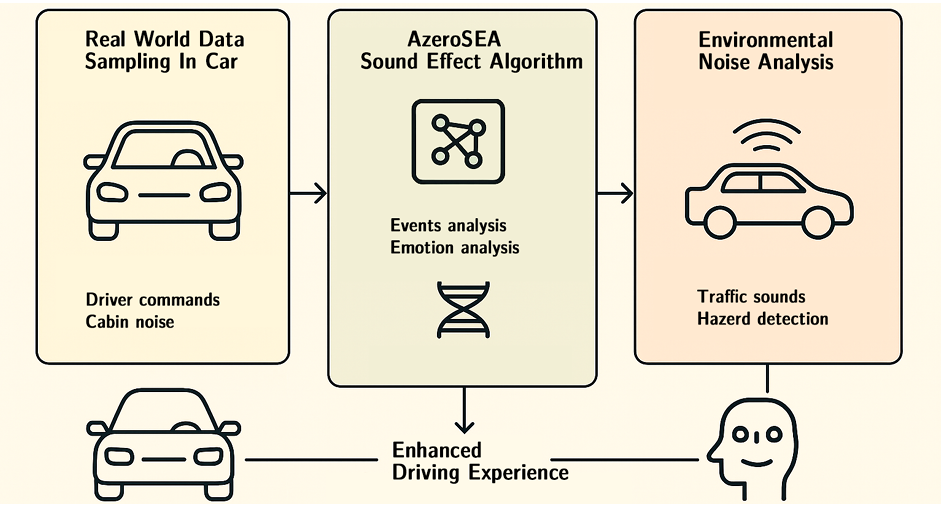
结 语
声智科技研发的非线性声学计算与强化学习融合框架,为解决复杂声学环境下的人机交互难题带来了创新性的突破。该技术借助非线性声学理论,有效捕捉高阶声学现象,结合强化学习实现实时参数优化,显著提升了系统在噪声抑制、语音识别、语音克隆等关键任务上的性能。大量实验表明,其性能远超传统线性方法和单纯的数据驱动模型,在工业、医疗、交通等多个领域展现出广阔的应用前景。
尽管目前的研究主要基于现有基准数据集,但这一技术已彰显出巨大潜力。未来,随着对真实世界数据的深入挖掘和应用,该技术将不断优化和拓展。通过融合更多模态的数据,它将更精准地理解和响应用户需求,进一步推动人机交互技术向智能化、个性化方向发展,为人们的生活和工作带来更多便利与创新。

![[Godot] 如何导出安卓 APK 并在手机上调试](https://i-blog.csdnimg.cn/direct/a86d24fe23b54595adcb25699745813f.png)