笔记整理:康家溱,东南大学在读硕士,研究方向为代码大语言模型
论文链接:https://aclanthology.org/2025.coling-main.267.pdf
发表会议:COLING 2025
1. 动机
近年来,随着大语言模型(LLM)展现出强大的推理能力,越来越多的专家学者利用大语言模型增强知识问答任务的可靠性。基于图谱的知识问答(KGQA)是指通过在图谱上执行逻辑形式(Logic Form)如SPARQL,S-Expression等生成用户需要的答案。
随着用户提问的复杂程度不断提升,大语言模型的推理能力涌现,以及上下文学习这种不需要训练的方式极大减小了开销,从而利用大语言模型生成逻辑形式完成复杂知识问答的形式备受青睐。
逻辑形式是连接自然语言问题与知识图谱的桥梁,由于预训练阶段接触到的逻辑形式较少,面对复杂查询如非单调推理,逻辑组合,数值计算等情况,直接生成LF(如SPARQL、S-Expression)容易出现语法错误,且复杂知识问答常常需要组合推理和数值计算等过程,这需要大模型逐步解析推理过程从而提高推理的透明度。
KoPL是一种符号化的逻辑形式,由模块化函数组成,每个函数有明确的输入/输出类型约束。同理,Python等语言同样通过函数组合完成任务,且遵守严格的语法和类型规则。由于知识导向的编程语言(KoPL)与通用编程语言(如Python)在结构上具有本质相似性,因此本文将逻辑形式(LF)生成任务重新定义为Python代码生成任务。
2. 贡献
(1)本文提出了CodeAlignKGQA框架,将KoPL生成任务对齐为Python代码生成任务,利用Code LLMs的模块化编程能力,增强了鲁棒性。
(2)本文提出了一种动态感知的方法,基于BFS和语义相似度提取问题的相关子图,作为代码生成的上下文约束,无需感知图谱全部信息。
(3)本文设计一种动态的纠错机制,通过检查生成代码的输入输出类型,指导LLM生成正确代码。
3. 方法
本文提出 CodeAlignKGQA 框架,通过将知识图谱问答中的逻辑形式生成任务重新定义为 Python代码生成任务,利用代码大语言模型的编程能力提升生成质量。其核心方法分为三步:
(1)知识感知的提示生成:动态提取问题相关的子图信息,包括实体,关系等,从而构建包含指令、函数定义和示例的提示。
(2)约束代码生成:通过引导代码大语言模型生成符合KoPL语法和子图类型约束的Python风格代码。
(3)动态自纠正:通过语法验证和程序结构检索修复错误代码,最终将生成的代码解析为KoPL并在知识图谱上执行。
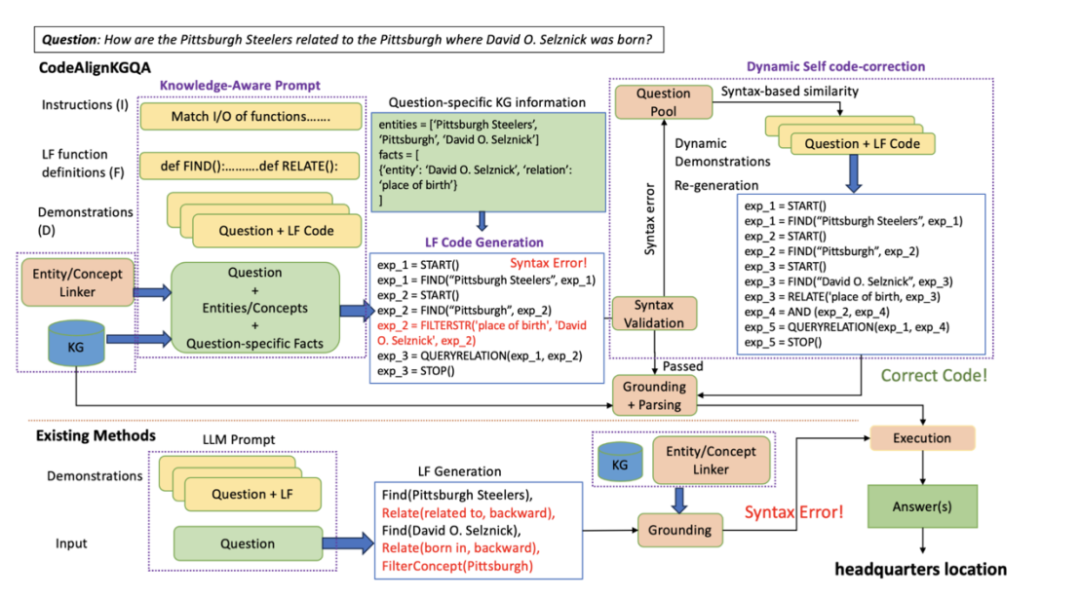
图1 模型框架图
3.1 知识感知的提示生成
子图提取:首先利用命名体识别(NER)对问题中的实体和关系进行过滤,掩码后生成n个候选,接着利用BERT进行编码,采用余弦相似度匹配KG中的关系或属性,得到初步子图,广度优先搜索(BFS)扩展该子图得到最终子图。
提示合成:预先明确代码生成规则,将KoPL的27种操作映射为Python函数,再人工从训练集数据中挑选少量样本,合成完整上下文。
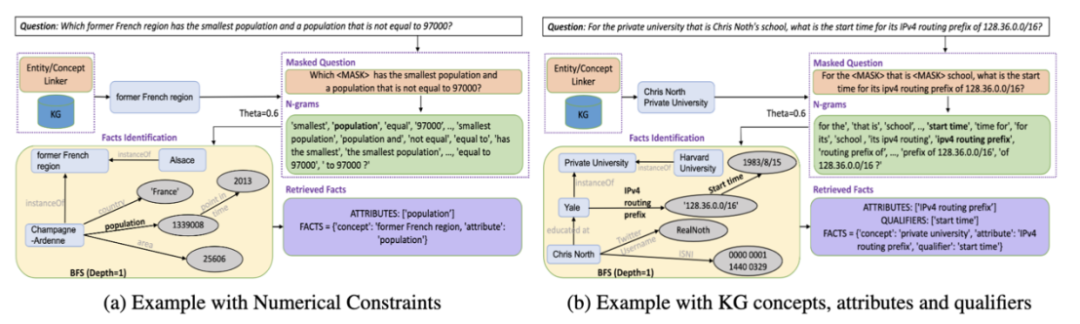
图2 复杂问题子图匹配
3.2 约束代码生成
通过将知识图谱的KoPL操作预定义为Python函数(如FIND()、RELATE()),并嵌入动态断言(assert)强制检查输入输出类型(如entities、int),引导LLM生成符合语法和语义规则的代码。生成时,要求模型分步输出Python风格的KoPL程序再通过解释运行代码和链式调用检查保证逻辑连贯,最终将代码解析为可执行的KoPL查询。
3.3 动态代码纠正
当生成的代码未通过语法检查或类型确认时,要求系统从预构建的函数覆盖池中检索与错误代码结构相似的Top-K正确示例(利用余弦相似度进行匹配),替换原提示中的少样本示例,并重新生成代码。
3.4 图谱映射执行
该过程首先对生成的代码中的文本输入(如实体名、关系名)进行语义链接,从知识图谱中通过向量相似度从KG中提取Top-10候选,再由LLM基于问题上下文选择最优项,按依赖关系排序执行步骤,最后将Python代码解析为标准KoPL程序,执行解析后的KoPL程序获得答案。
4. 实验
4.1 评测
本文选择了三个具有不同复杂程度的KGQA数据集进行评测,分别是KQA Pro,MetaQA和WebQSP。
其中KQA Pro包含94K训练集,11K测试集,最多可达10跳推理,涉及到组合推理、数值比较、多跳查询等复杂问题。MetaQA为电影领域多跳问答。WebQSP则是基于真实数据构建。
基准方法:本文对比了两类不同的基线方法,分别是全监督方法,和少样本方法进行对比,此外还对不同的代码大语言模型实现了消融实验。
表1说明了实验数据集的多样性和规模,为后续实验提供了有力支撑,同时也分析了利用大语言模型和现有SOTA基于符号化生成的性能差异。
表 1 分类性能表现

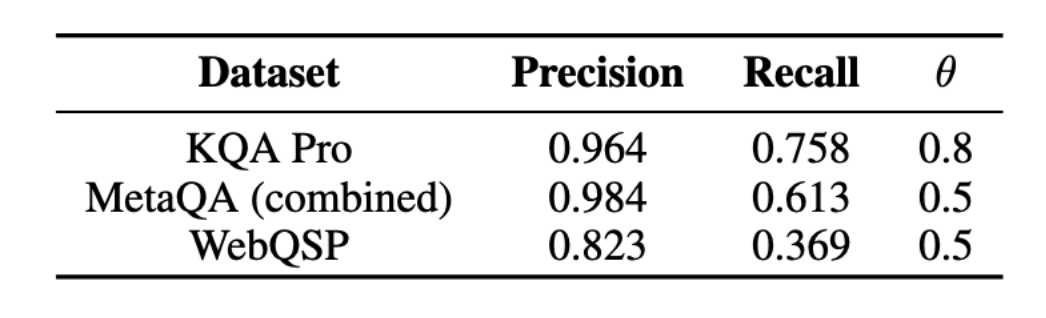
表2展示了KQA-Pro评测结果,从命中率来看,相比于全监督模式,CodeALignKGQA展现出极大潜力,但略逊于通过少样本的方式Gemini Pro 1.0的表现。从句法错误率角度(Syntax Error Rate (SER%))来看,该方案取得明显优势。
表 2 KQA Pro评测结果
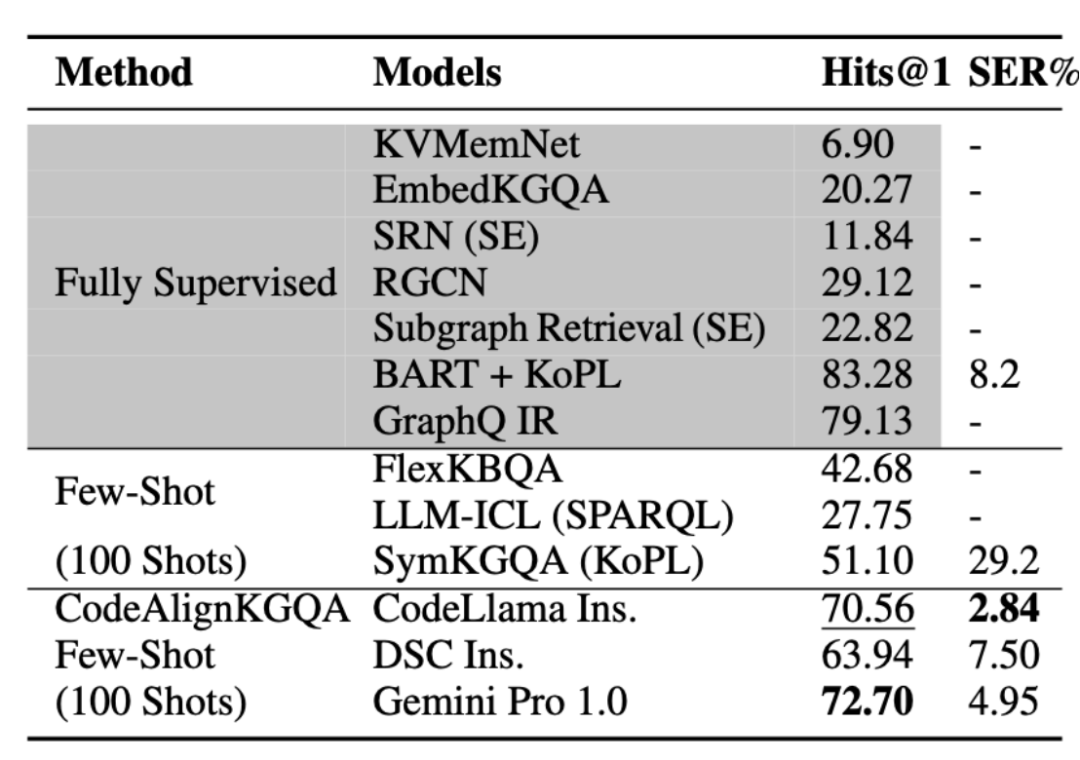
表3展示了MetaQA的评测结果,从命中率来看,模型在单跳推理和双跳推理任务上稳居第一,效果略强于Gemini Pro 1.0,在三跳推理任务上取得第二,效果略低于Gemini Pro 1.0。
表 3 MetaQA 评测结果
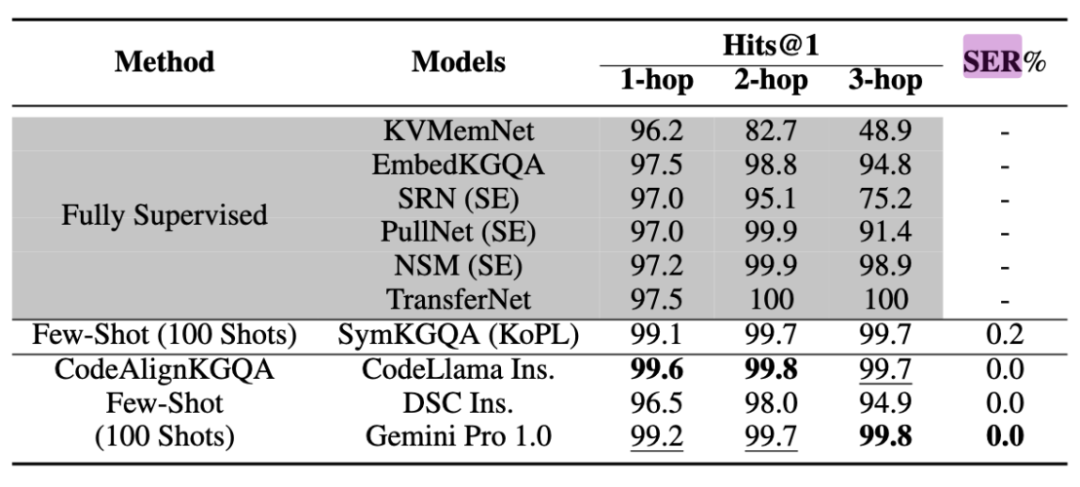
表4展示了WebQSP的评测结果,从WebQSP的结果来看,模型的F1指数位列第一,说明模型有着不错的精准度和召回率,且几乎未产生句法错误,这符合该方案的设计动机。
表 4 WebQSP 评测结果
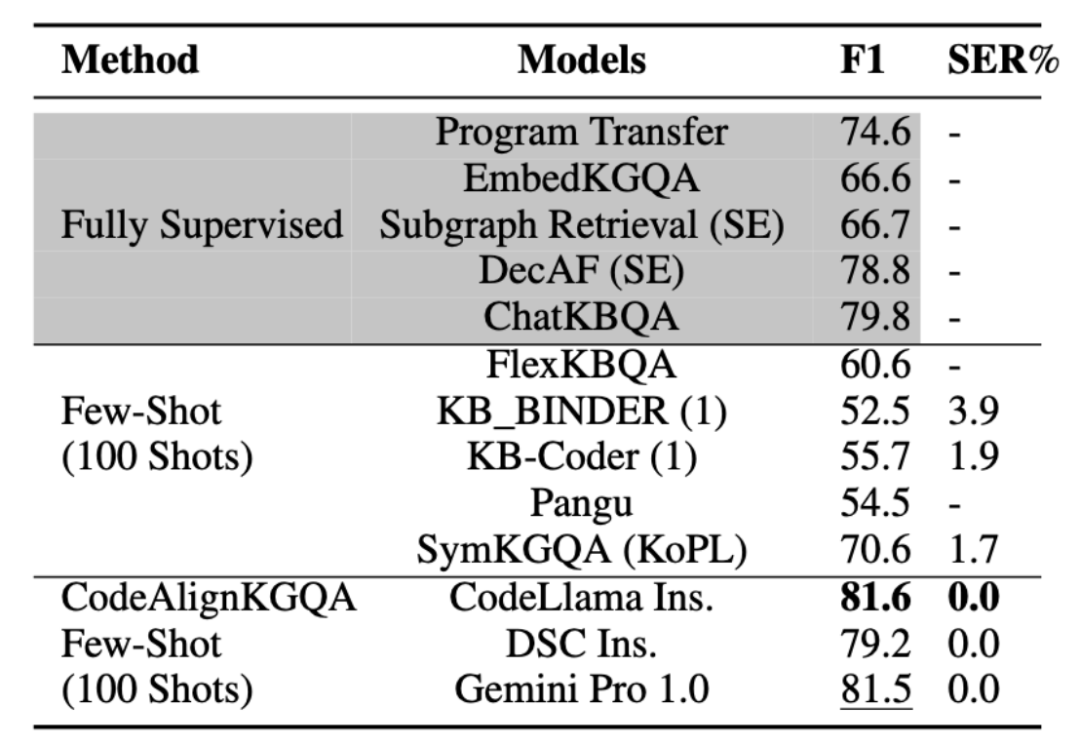
与GPT4的对比试验:
该实验对比了四个不同的LLM在三个数据集上实验效果,GPT-4仅在KQA Pro上表现最优,在其它两个数据集上表现逊色于CodeLlama Instruct和 Gemini Pro 1.0,可能由于GPT4具有更强的推理能力和丰富的通用知识,但在简单场景下,面对特定领域相关的知识问答场景无法充分发挥自身通用推理的能力,这也进一步表明更强的模型并不一定在所有场景下的表现都是最优的。
表 5 与GPT性能对比
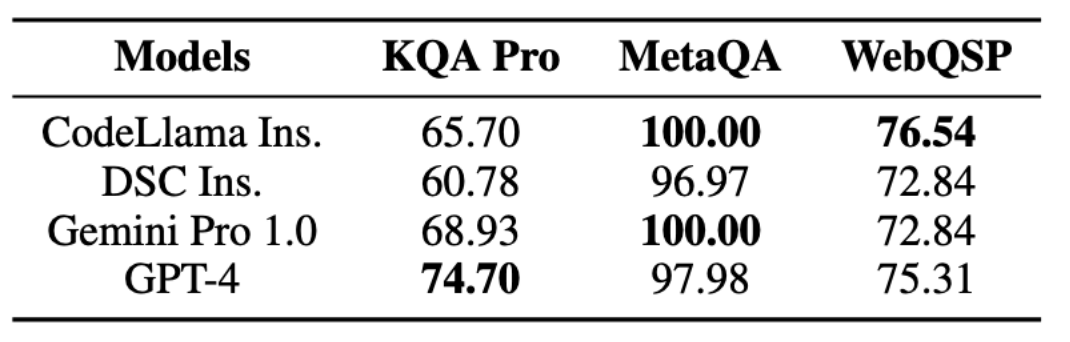
表6分析了该框架中知识感知模块的性能,通过设计不同的相似度阈值,可以看到该模块在三个数据集上的检索性能良好,这极大降低了输入的成本。
表 6 子图检索性能
由KQA-Pro和WebQSP的效果可推测,动态纠正对复杂查询至关重要,但对简单问题可省略以降低计算开销, 而图谱映射确保生成的代码语义可执行,缺失这一模块会导致性能崩溃。
表 7 消融实验结果

5. 总结
本文提出了CodeAlignKGQA框架,分析了逻辑形式(Logic Form)生成任务和代码生成任务的结构相似性,旨在利用代码大语言模型强大的编程能力提升生成质量,增强模型生成逻辑形式的稳定性和鲁棒性,减少句法错误率,从而更好的实现复杂知识问答任务的性能。
这一转变不仅仅适用于逻辑形式生成,近年来,越老越多学者尝试利用代码大语言模型的模块化编程能力,将传统非代码任务转换成代码生成任务,进一步提升效果。Li et al. (2023) 提出了CodeIE,巧妙的将传统的信息抽取任务如命名实体识别和关系抽取等,重新构建为代码生成任务。Puerto et al. (2024) 提出一种链式提示方法,将自然语言问题转换为代码,并直接使用生成的代码提示模型,无需外部代码执行。Wang et al. (2023) 将结构化预测任务, 如事件论元抽取, 转换为代码生成任务,使用 Python 类或函数来表示输出结构。
将结构化的信息生成的任务统一转化为代码生成任务,以编程语言的规则弥补纯文本生成的多样性。未来可探索更多领域的代码化对齐,同时考虑解决计算开销与领域适配的平衡问题。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。