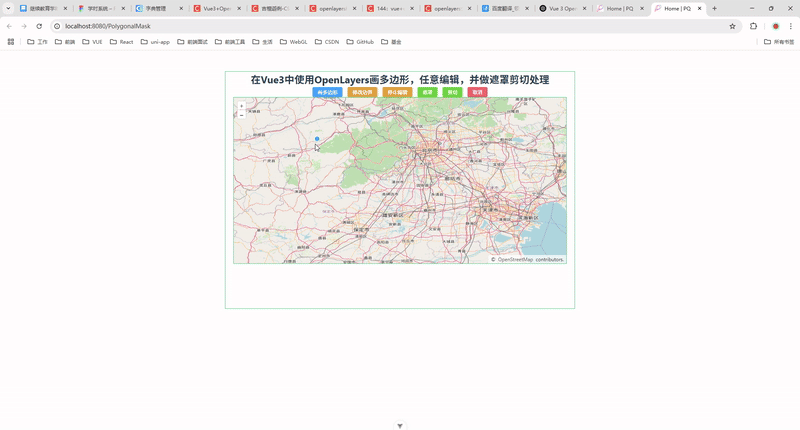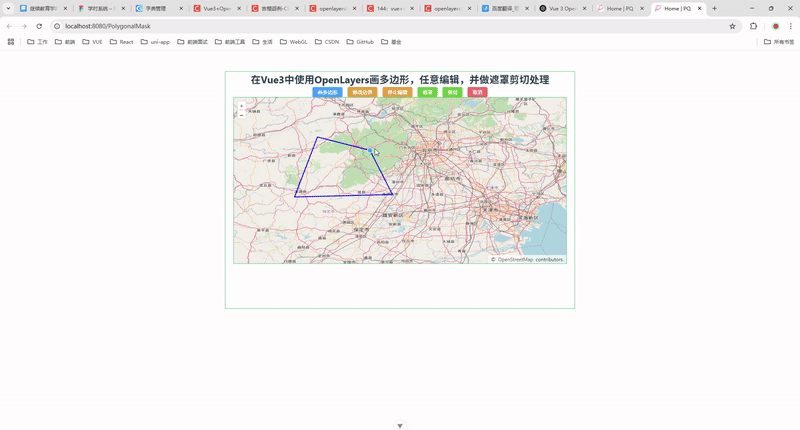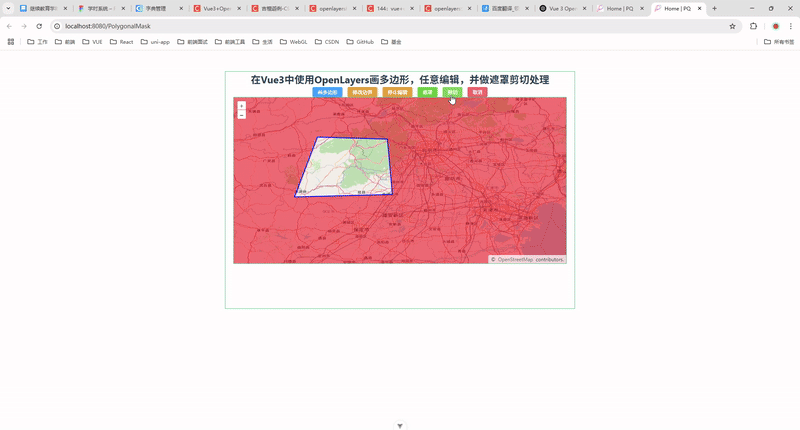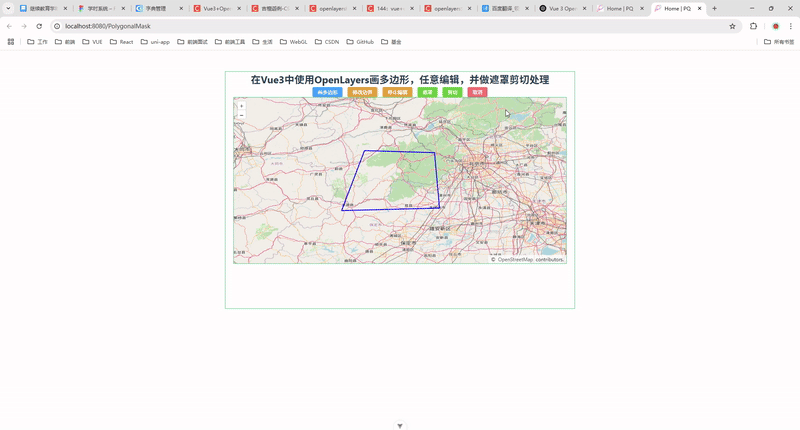
现代 CPU 中用于加速多级页表查找的Page‐Table Entry原理
摘要:以下从背景、结构、查找流程、一致性与性能影响等方面,详细介绍现代 CPU 中用于加速多级页表查找的 Page-Walk Cache(也称 Walker Cache 或 Page‐Table Entry Cache)。
1. 背景:为何需要 Page‐Walk Cache
-
多级页表查找成本高
以 x86-64 为例,4 级页表走完一次要依次访问 PML4、PDPT、PD、PT,每级都要一次内存读(若不命中 L1/L2/L3 缓存),最糟糕可能要 4 次 LLC Miss → DRAM 访问,延迟数百纳秒。 -
TLB 只能缓存最终映射
TLB(Translation Lookaside Buffer)存的是虚拟页→物理页的最终映射,一旦 TLB miss,仍需重新走页表。Page-Walk Cache 介于 TLB 与内存之间,缓存中间级页表项,减少每次 page-walk 的内存访问数。
2. Page-Walk Cache 的总体结构
- 独立或共享
- 有的 CPU 为每级页表各设一个小缓存(L0 for PML4E, L1 for PDPTE, L2 for PDE, L3 for PTE),也有合并成一个统一 Walker Cache。
- Entry 内容
- Tag:〈CR3 或 ASID/PCID, 虚拟页号中对应级别的索引位〉
- Data:对应级别的页表项完整 64 bit(含 PFN + control bits)。
- 容量与关联度
- 极小,一般几十到几百条;全相联或 4-way/8-way set-assoc;足够缓冲热点上下文,但远小于 TLB。
3. 查找与填充流程
-
TLB Miss → 触发 Walker
硬件页表行走器(Page‐Walker)启动,将 CR3(携带 ASID/PCID)与 VA 分解成 4 个 9-bit 索引字段。 -
各级查 Page-Walk Cache
对第一级(PML4)索引:- 在 PML4‐Cache 中查 Tag;
- Hit → 直接拿到对应 PML4E;
- Miss → 按常规:从内存(LLC)读取 PML4E 后填 Cache。
再对第二级(PDPT)、第三级(PD)、第四级(PT)重复相同动作。
-
汇聚获得最终 PTE
- 若中途某级 PDE.Mark-PS=1,且映射大页,则后续级别跳过;Walker Cache 同样可命中大页级别的 PDE entry。
- 最终得出 PTE,更新 TLB,并返回物理页基址。
4. 一致性与失效
-
软件修改页表
操作系统写入或无效化页表后,需执行invlpg或CR3重载,隐含触发 Walker Cache 对应条目失效。CPU 内部会:- 按 ASID/PCID 精确清除相关 Tag,或
- 在全局
CR3切换时一并失效。
-
Page-Walk Cache 可与 PCID 协同
支持 Process-Context ID (PCID) 时,Tag 包含 PCID,切换地址空间无需全表失效,只失效对应新 CR3/PCID 下不可见的条目。
5. 嵌套/二级页表(EPT/NPT)支持
在虚拟化场景中,需同时走 二级页表(Guest)和 一级页表(Host/EPT)。现代 CPU 会:
- 分阶段 Walker:先走 Guest 页表(用 Guest CR3),再走 Host EPT(用 EPTP),两套 Walker Cache 可复用;
- 双重 Tag:Tag 中加上两级 CR3/EPTP 标识,保证隔离。
6. 性能效果
- 减少内存访问次数
典型热点工作集下,Walker Cache 命中率可达 80–90%,平均每次 Page‐Walk 只需 1–2 次 LLC 访问,而非最差的 4 次。 - 降低延迟与功耗
减少 DRAM 访问,Page-Walk 延迟可从数百纳秒降到几十纳秒;同时降低系统总功耗。 - 提升 TLB miss 下的 IPC
对于大量随机地址访问(如数据库、VMware),Page-Walk Cache 极大提升穿页性能。
7. 硬件设计考量
- 容量 vs 并发
- 容量太小命中率低,太大又占硅片面积。常见设计:每级 32–128 条;4 级共 128–256 条。
- 关联度
- 全相联提高命中,硬件实现复杂;4-way set-assoc 更折中。
- 替换策略
- LRU 或近似 LRU;与 TLB 类似。
- 与缓存系统协同
- Walker Cache miss 后读内存,优先走 L1/L2/L3 Cache,若最终 LLC Miss 再到 DRAM。
小结
Page-Walk Cache 是现代 CPU 在 TLB miss 时,为缓存页表中间级别条目的专用小型高速缓存。它通过给每级页表查找加速,减少 Page-Walk 对内存的压力,显著降低 TLB miss 的延迟和功耗,对操作系统的页表结构透明、自动协同 PCID 与虚拟化二级页表,从而大幅提升系统的整体性能。
Page-Walk Cache的替换策略具体是如何实现的?
摘要:在硬件上,Page-Walk Cache(PWC)通常是一个小容量、多路组相联的缓存;其替换策略需要在极度受限的时序和面积下,既能提供较高命中率,又要保证硬件实现简单。主流做法是用 伪 LRU(Pseudo-LRU),具体流程如下。
1. 组织形式
假设 PWC 是一个 S-way 组相联缓存,共有 N 组(set),每组 S 条 entry,每条 entry 存储一个页表项和若干 tag 比特。
– S 常见取值:2, 4, 8。
– N 也不大,可能几十到上百。
每组都要维护一组替换状态位,用来选择下一次 miss 时的 victim way。
2. 伪-LRU (Tree-based PLRU)
最经典也最常见的是 树形 PLRU:
-
结构
– 对 S=4:使用 3 个二叉树节点位 b0,b1,b2。
• b0 根节点,控制左子树(ways 0–1) vs 右子树(ways 2–3)
• b1 左子树内部,控制 way 0 vs way 1
• b2 右子树内部,控制 way 2 vs way 3 -
选替换行(Victim Selection)
– 从根开始:若 b0==0 → 走左子树,否则走右;
– 在子树内部再按 b1/b2 决定更“冷”的那条路。 -
命中更新(MRU 更新)
– 若访问到 way k:
• 根节点 b0 = (k ∈ {0,1}) ? 1 : 0
• 如果 k ∈ 左子树,则 b1 = (k==0?1:0);如果 ∈ 右子树,则 b2 = (k==2?1:0)。 -
Miss 时:
– 用上面算法找出“最老”way 作替换;
– 用新的 tag + data 覆盖它;
– 把对应的 b0/b1/b2 更新成 MRU,与命中时相同。
这种做法只需要 S–1 位状态、硬件逻辑简单,能近似逼近 LRU。
3. 其他简化/优化策略
-
2-way:
– 只需 1 位 MRU bit,0/1 表示上次命中的是 way0 还是 way1,miss 时替换另一路。 -
8-way:
– 可用 7 位树型 PLRU(3 层)
– 或分成两级:先选出 “四路组” 再内部二分。 -
真 LRU(只对 very small S=2,4)
– 用 2-bit 或 4-entry 阶梯式计数器记录使用顺序。
– 面积和延迟稍大,一般只在关键路径足够宽松时采用。 -
“Insertion Policy” 调整
– MISS 时不总插入 MRU,可以插入到某中间位置 (e.g., “MRU-1”),以防热不热点数据迅速污染缓存。
– “Bypass” 流水线/预取产生的低重用数据,不分配到 PWC,保留空间给真正的页表热点。
4. 一致性与失效
- CR3/ASID 切换:PWC 的每条 entry tag 中带有地址空间 ID;CR3 切换会使得所有“前地址空间” entry 视为 miss,无需显式清空。
- 软件写页表:OS 在修改页表后执行
invlpg,微架构会检测到对应 Virtual‐Page tag 并失效相关 PWC entry(通过比对 CR3+VPN)。
5. 性能权衡
- 容量 vs 命中率:PWC 容量通常几百条即可将 Page-Walk 的内存访问次数从最坏 4 次下探至平均 1–2 次。
- 替换开销:树型 PLRU 的状态更新仅几路 MUX+D-FF,远低于“真 LRU”的多位加法/比较器。
- 侵入延迟:PWC 查找与更新与深度流水线并行,通常不影响 TLB-Miss 触发的页表行走器 (PTW) 的主时序。
小结
Page-Walk Cache 几乎通用地采用 树型 Pseudo-LRU 替换策略:
- 每组用 S−1 个位记录最近访问方向;
- 命中时更新这些位以标记 MRU 路径;
- Miss 时用它们快速定位“最冷”那一路进行替换。
这种策略硬件开销小、速度快,可在极短周期内完成替换决策,并且配合 ASID/PCID 等 tag 机制实现高效一致性管理。