- OpenCV 安装: 你需要正确安装 OpenCV 库。
- Tesseract OCR 安装:
- 你需要安装 Tesseract OCR 引擎。在 Ubuntu/Debian 上,可以使用:
sudo apt-get install tesseract-ocr sudo apt-get install libtesseract-dev sudo apt-get install libleptonica-dev - 你还需要下载 Tesseract 的语言数据文件(例如,用于英文识别的
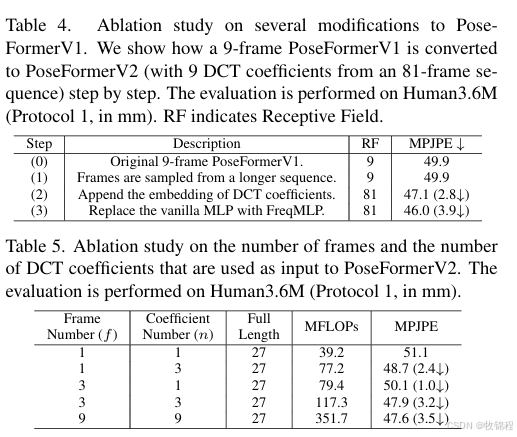
eng.traineddata)。通常这些文件需要放在一个名为tessdata的目录下,并且 Tesseract 需要知道这个目录的位置 (可以通过设置环境变量TESSDATA_PREFIX或在代码中指定)。
- 你需要安装 Tesseract OCR 引擎。在 Ubuntu/Debian 上,可以使用:
- 编译器: 你需要一个 C++ 编译器 (如 G++)。
代码结构:
- 包含头文件和命名空间。
- 主函数
main:- 加载图像。
- 预处理图像(灰度化、模糊、边缘检测)。
- 查找轮廓。
- 过滤轮廓以找到可能的车牌区域。
- 提取车牌 ROI (Region of Interest)。
- 对提取的 ROI 进行 OCR。
- 显示结果。
#include <opencv2/opencv.hpp>
#include <tesseract/baseapi.h> // Tesseract API
#include <leptonica/allheaders.h> // Leptonica (Tesseract 使用的图像库)
#include <iostream>
#include <vector>
#include <string>
// 使用标准命名空间
using namespace std;
using namespace cv;
// 函数:对车牌ROI进行OCR识别
string recognize_text_from_roi(Mat roi_image) {
if (roi_image.empty()) {
return "Error: ROI image is empty.";
}
// 将OpenCV Mat转换为Tesseract可以处理的Pix对象
// 首先确保图像是灰度图,如果不是,则转换
Mat gray_roi;
if (roi_image.channels() == 3) {
cvtColor(roi_image, gray_roi, COLOR_BGR2GRAY);
} else {
gray_roi = roi_image.clone();
}
// 可以选择进行二值化处理,有时能提高识别率
// threshold(gray_roi, gray_roi, 0, 255, THRESH_BINARY | THRESH_OTSU);
tesseract::TessBaseAPI *ocr = new tesseract::TessBaseAPI();
// 初始化Tesseract
// 参数1: tessdata路径,如果TESSDATA_PREFIX环境变量已设置,可以为NULL
// 参数2: 语言,例如 "eng" 代表英文,"chi_sim" 代表简体中文 (需要相应的traineddata文件)
// PSM_SINGLE_BLOCK: 假定图像是一个统一的文本块
if (ocr->Init(NULL, "eng", tesseract::OEM_LSTM_ONLY)) {
cerr << "Could not initialize tesseract." << endl;
delete ocr;
return "Error: Tesseract initialization failed.";
}
ocr->SetPageSegMode(tesseract::PSM_SINGLE_BLOCK); // 或 PSM_SINGLE_LINE, PSM_AUTO 等
// 设置图像
ocr->SetImage(gray_roi.data, gray_roi.cols, gray_roi.rows, gray_roi.channels(), gray_roi.step);
// 获取识别结果
char *outText = ocr->GetUTF8Text();
string recognized_text(outText);
// 清理
ocr->End();
delete ocr;
delete[] outText;
// 移除识别文本中的换行符和多余空格(简单处理)
recognized_text.erase(remove(recognized_text.begin(), recognized_text.end(), '\n'), recognized_text.end());
recognized_text.erase(remove(recognized_text.begin(), recognized_text.end(), '\r'), recognized_text.end());
// 也可以进一步去除空格等
return recognized_text;
}
int main(int argc, char** argv) {
// --- 1. 加载图像 ---
string image_path = "plate_image.png"; // 修改为你的车牌图片路径
if (argc > 1) {
image_path = argv[1];
}
Mat original_image = imread(image_path);
if (original_image.empty()) {
cout << "无法加载图像: " << image_path << endl;
return -1;
}
cout << "图像加载成功: " << image_path << endl;
Mat processed_image;
// --- 2. 预处理 ---
// 转换为灰度图
cvtColor(original_image, processed_image, COLOR_BGR2GRAY);
// 高斯模糊以减少噪声
GaussianBlur(processed_image, processed_image, Size(5, 5), 0);
// Canny边缘检测
Mat edges;
Canny(processed_image, edges, 50, 150); // 调整阈值以获得更好的边缘
// --- 3. 查找轮廓 ---
vector<vector<Point>> contours;
vector<Vec4i> hierarchy;
findContours(edges, contours, hierarchy, RETR_EXTERNAL, CHAIN_APPROX_SIMPLE); // RETR_TREE 可能会找到更多嵌套轮廓
Mat contours_display = original_image.clone(); // 用于显示轮廓和检测结果
cout << "找到 " << contours.size() << " 个轮廓。" << endl;
// --- 4. 过滤轮廓以找到可能的车牌区域 ---
vector<Rect> potential_plates_roi;
for (size_t i = 0; i < contours.size(); i++) {
// 计算轮廓的边界框
Rect bounding_rect = boundingRect(contours[i]);
// 过滤条件 (非常基础,需要根据实际情况调整)
// a. 宽高比 (例如,中国车牌标准宽高比约为 440/140 = 3.14)
float aspect_ratio = (float)bounding_rect.width / bounding_rect.height;
// b. 面积 (避免太小或太大的区域)
double area = contourArea(contours[i]);
double min_area = 800; // 最小面积阈值 (像素)
double max_area = 50000; // 最大面积阈值 (像素)
// c. 近似多边形顶点数 (车牌通常是矩形,4个顶点)
vector<Point> approx_poly;
approxPolyDP(contours[i], approx_poly, arcLength(contours[i], true) * 0.02, true);
// 简单的过滤逻辑
if (approx_poly.size() == 4 && // 近似为四边形
aspect_ratio > 2.0 && aspect_ratio < 5.5 && // 合理的宽高比
area > min_area && area < max_area) { // 合理的面积
// 绘制绿色矩形标记潜在车牌
rectangle(contours_display, bounding_rect, Scalar(0, 255, 0), 2);
potential_plates_roi.push_back(bounding_rect);
cout << "潜在车牌区域: x=" << bounding_rect.x << ", y=" << bounding_rect.y
<< ", w=" << bounding_rect.width << ", h=" << bounding_rect.height
<< ", AR=" << aspect_ratio << ", Area=" << area << endl;
}
}
if (potential_plates_roi.empty()) {
cout << "未找到潜在的车牌区域。" << endl;
} else {
cout << "找到 " << potential_plates_roi.size() << " 个潜在车牌区域。" << endl;
// 为了简单,我们只处理第一个找到的潜在车牌
// 在实际应用中,可能需要更复杂的逻辑来选择最佳车牌或处理多个车牌
// --- 5. 提取车牌 ROI 并进行 OCR ---
for (const auto& plate_rect : potential_plates_roi) {
Mat plate_roi_raw = original_image(plate_rect); // 从原始彩色图像中提取ROI
if (plate_roi_raw.empty()) {
cerr << "无法提取车牌ROI。" << endl;
continue;
}
// (可选) 对ROI进行一些额外的预处理,如调整大小,进一步去噪等
// Mat plate_roi_for_ocr = plate_roi_raw.clone();
// cvtColor(plate_roi_for_ocr, plate_roi_for_ocr, COLOR_BGR2GRAY);
// threshold(plate_roi_for_ocr, plate_roi_for_ocr, 0, 255, THRESH_BINARY_INV | THRESH_OTSU); // 反二值化+OTSU
cout << "\n对ROI进行OCR..." << endl;
string recognized_plate = recognize_text_from_roi(plate_roi_raw); // 直接传入彩色ROI,函数内部会转灰度
if (recognized_plate.rfind("Error:", 0) == 0) { // 检查是否以 "Error:" 开头
cerr << "OCR失败: " << recognized_plate << endl;
} else {
cout << "识别结果: " << recognized_plate << endl;
// 在图像上显示识别结果
putText(contours_display, recognized_plate, Point(plate_rect.x, plate_rect.y - 10),
FONT_HERSHEY_SIMPLEX, 0.9, Scalar(0, 0, 255), 2);
}
}
}
// --- 6. 显示结果 ---
imshow("原始图像", original_image);
imshow("边缘检测", edges);
imshow("检测到的车牌", contours_display);
waitKey(0); // 等待按键
destroyAllWindows();
return 0;
}
编译和运行
-
保存代码: 将上述代码保存为
lpr_simple.cpp。 -
准备图片: 准备一张名为
plate_image.png(或你在代码中指定的其他名称) 的车牌图片,并将其放在与lpr_simple.cpp相同的目录下。或者,你可以在运行时通过命令行参数传递图片路径。 -
编译:
打开终端,使用以下命令编译 (假设你使用的是 g++,并且 OpenCV 和 Tesseract 已正确安装):g++ lpr_simple.cpp -o lpr_simple $(pkg-config --cflags --libs opencv4 tesseract leptonica)- 注意:
opencv4可能需要根据你的 OpenCV 版本调整 (例如opencv或opencv3)。你可以通过运行pkg-config --libs opencv4来检查正确的链接标志。 - 如果
pkg-config找不到 tesseract 或 leptonica,你可能需要手动指定头文件和库路径。
- 注意:
-
运行:
./lpr_simple或者,如果你想指定图片:
./lpr_simple /path/to/your/image.jpg
代码解释
1. 包含头文件
#include <opencv2/opencv.hpp> // OpenCV 主要头文件
#include <tesseract/baseapi.h> // Tesseract C++ API
#include <leptonica/allheaders.h> // Leptonica (Tesseract 依赖的图像处理库)
#include <iostream> // 标准输入输出
#include <vector> // STL vector
#include <string> // STL string
2. recognize_text_from_roi 函数
这个函数负责对提取到的车牌候选区域 (ROI) 进行光学字符识别。
string recognize_text_from_roi(Mat roi_image) {
// ... (错误检查) ...
Mat gray_roi;
if (roi_image.channels() == 3) { // 如果是彩色图,转为灰度
cvtColor(roi_image, gray_roi, COLOR_BGR2GRAY);
} else {
gray_roi = roi_image.clone();
}
// 初始化 Tesseract API
tesseract::TessBaseAPI *ocr = new tesseract::TessBaseAPI();
// "eng" 表示英文,OEM_LSTM_ONLY 表示使用 LSTM OCR 引擎 (通常效果更好)
if (ocr->Init(NULL, "eng", tesseract::OEM_LSTM_ONLY)) {
// ... (错误处理) ...
}
// 设置页面分割模式,PSM_SINGLE_BLOCK 假设图像是一个统一的文本块
ocr->SetPageSegMode(tesseract::PSM_SINGLE_BLOCK);
// 将 OpenCV Mat 数据传递给 Tesseract
ocr->SetImage(gray_roi.data, gray_roi.cols, gray_roi.rows, gray_roi.channels(), gray_roi.step);
// 获取识别文本
char *outText = ocr->GetUTF8Text();
string recognized_text(outText);
// 清理资源
ocr->End();
delete ocr;
delete[] outText;
// 简单地移除换行符
recognized_text.erase(remove(recognized_text.begin(), recognized_text.end(), '\n'), recognized_text.end());
// ...
return recognized_text;
}
- Tesseract 初始化 (
ocr->Init):- 第一个参数是
tessdata目录的路径。如果设置为NULL或空字符串,Tesseract 会尝试从环境变量TESSDATA_PREFIX或默认安装路径查找。 - 第二个参数是语言代码 (例如, “eng” 表示英语, “chi_sim” 表示简体中文)。你需要确保相应的
.traineddata文件存在于tessdata目录中。 - 第三个参数是 OCR 引擎模式。
OEM_LSTM_ONLY通常提供较好的结果。
- 第一个参数是
- 页面分割模式 (
ocr->SetPageSegMode): 这告诉 Tesseract 如何解释图像中的文本布局。PSM_SINGLE_BLOCK适合单个文本块,对于裁剪出的车牌图像通常是合适的。其他模式如PSM_SINGLE_LINE(单行文本)也可能有用。
3. main 函数
-
加载图像 (
imread):Mat original_image = imread(image_path); if (original_image.empty()) { /* ... 错误处理 ... */ } -
图像预处理:
cvtColor(original_image, processed_image, COLOR_BGR2GRAY); // 转灰度 GaussianBlur(processed_image, processed_image, Size(5, 5), 0); // 高斯模糊 Canny(processed_image, edges, 50, 150); // Canny 边缘检测这些步骤有助于减少噪声,并突出图像中的边缘,为轮廓检测做准备。Canny 算法的两个阈值(50 和 150)可能需要根据输入图像的特性进行调整。
-
查找轮廓 (
findContours):vector<vector<Point>> contours; vector<Vec4i> hierarchy; findContours(edges, contours, hierarchy, RETR_EXTERNAL, CHAIN_APPROX_SIMPLE);RETR_EXTERNAL: 只检测最外层的轮廓。CHAIN_APPROX_SIMPLE: 压缩水平、垂直和对角线段,只保留其端点。
-
过滤轮廓:
这是车牌定位的核心步骤。循环遍历所有找到的轮廓,并根据一些基本几何特征进行过滤:for (size_t i = 0; i < contours.size(); i++) { Rect bounding_rect = boundingRect(contours[i]); // 获取边界框 float aspect_ratio = (float)bounding_rect.width / bounding_rect.height; // 计算宽高比 double area = contourArea(contours[i]); // 计算面积 vector<Point> approx_poly; // 对轮廓进行多边形逼近 approxPolyDP(contours[i], approx_poly, arcLength(contours[i], true) * 0.02, true); // 过滤条件 if (approx_poly.size() == 4 && // 顶点数接近4 (矩形) aspect_ratio > 2.0 && aspect_ratio < 5.5 && // 典型的车牌宽高比 area > min_area && area < max_area) { // 合理的面积范围 // ... 标记为潜在车牌 ... potential_plates_roi.push_back(bounding_rect); } }这些过滤条件(顶点数、宽高比、面积)是非常基础的,实际应用中可能需要更鲁棒的算法,例如结合颜色信息、字符的排布特征等。
-
提取 ROI 和 OCR:
如果找到了潜在的车牌区域,就从原始图像中提取该区域,并调用recognize_text_from_roi函数。for (const auto& plate_rect : potential_plates_roi) { Mat plate_roi_raw = original_image(plate_rect); // 从原图提取ROI // ... (错误检查) ... string recognized_plate = recognize_text_from_roi(plate_roi_raw); // ... (显示结果) ... } -
显示结果 (
imshow,waitKey):
显示原始图像、边缘图像以及带有标记和识别文本的图像。
局限性与改进方向
这个示例非常基础,其鲁棒性有限:
- 简单的轮廓过滤: 对于复杂背景、光照变化、车牌倾斜或部分遮挡的情况,效果可能不佳。
- 固定的阈值: Canny 边缘检测的阈值、面积和宽高比的过滤阈值是硬编码的,可能不适用于所有图像。
- OCR 准确性: Tesseract 的准确性受图像质量、字体、字符间距等多种因素影响。对 ROI 进行更精细的预处理(如二值化、去噪、倾斜校正、字符分割)可以提高识别率。
- 单车牌假设: 代码目前简单地处理找到的第一个(或所有)符合条件的区域。如果图像中有多个车牌或多个类似车牌的物体,可能需要更复杂的逻辑来选择。
- 语言和字符集: Tesseract 需要为特定语言和字符集进行配置。
可能的改进方向:
- 更高级的定位算法:
- 使用形态学操作(如开运算、闭运算、顶帽、黑帽)来增强车牌特征。
- 颜色分割:利用车牌颜色(如蓝色、黄色、绿色底板)进行初步筛选。
- 滑动窗口或基于 MSER (Maximally Stable Extremal Regions) 的方法。
- 训练一个目标检测模型 (如基于 Haar Cascades, HOG+SVM, 或深度学习的 Faster R-CNN, YOLO, SSD) 来专门检测车牌。
- 车牌倾斜校正: 检测车牌的四个角点,并进行透视变换将其校正为标准矩形。
- 字符分割: 在识别之前,将车牌上的字符分割成单个字符图像,然后对每个字符进行识别。这通常能提高复杂车牌的识别率。
- Tesseract 参数调优: 尝试不同的页面分割模式 (
SetPageSegMode) 和 OCR 引擎模式 (Init中的oem参数)。 - 训练自定义 Tesseract 模型: 对于特定字体或低质量图像,训练针对性的 Tesseract 模型可能会有显著提升。
- 后处理: 对 OCR 结果进行校验,例如根据车牌号码的语法规则(如特定位置是字母还是数字)进行修正。
这个简单的例子可以作为你学习和探索车牌识别的一个起点。祝你编码愉快!