一、引言
深度学习是机器学习的一个分支,它通过构建多层神经网络来模拟人类大脑的信息处理方式,从而实现对复杂数据的自动特征提取和模式识别。近年来,深度学习在计算机视觉、自然语言处理、语音识别等领域取得了巨大的突破,引发了全球范围内的研究和应用热潮。
本文将从深度学习的基本概念出发,逐步深入到实际应用,并结合代码示例展示如何实现一个简单的深度学习模型。
二、深度学习基础
(一)神经网络的基本结构
神经网络由多个神经元组成,这些神经元通过权重连接在一起。一个典型的神经网络包括输入层、隐藏层和输出层。输入层接收外部数据,隐藏层对数据进行处理和特征提取,输出层则给出最终的预测结果。
(二)激活函数
激活函数是神经网络中的关键组件,它为神经网络引入非线性因素,使得模型能够学习复杂的函数映射关系。常见的激活函数包括 Sigmoid、ReLU(Rectified Linear Unit)和 Tanh 等。
(三)损失函数
损失函数用于衡量模型预测值与真实值之间的差异。常见的损失函数包括均方误差(MSE)和交叉熵损失(Cross-Entropy Loss)。
(四)优化算法
优化算法用于调整神经网络的权重,以最小化损失函数。常见的优化算法包括梯度下降(Gradient Descent)、随机梯度下降(SGD)、Adam 等。
三、深度学习框架
深度学习框架是用于构建和训练神经网络的工具,它提供了丰富的API和高效的计算能力。常见的深度学习框架包括 TensorFlow、PyTorch 和 Keras。
(一)TensorFlow
TensorFlow 是由谷歌开发的开源深度学习框架,它支持多种平台和语言,具有强大的计算能力和灵活的架构。
(二)PyTorch
PyTorch 是由 Facebook 开发的开源深度学习框架,它以动态计算图和易用性著称,适合于研究和开发。
(三)Keras
Keras 是一个高级深度学习框架,它提供了简洁的API和快速的开发体验,适合于快速原型设计和实验。
四、深度学习模型的实现
接下来,我们将通过一个简单的例子来展示如何使用 PyTorch 实现一个深度学习模型。我们将构建一个简单的神经网络,用于分类任务。
(一)数据准备
我们将使用经典的 MNIST 数据集,它包含手写数字的灰度图像,每个图像的大小为 28×28 像素。
Python
复制
import torch
from torchvision import datasets, transforms
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize((0.5,), (0.5,)) # 归一化
])
# 加载数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# 创建数据加载器
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=1000, shuffle=False)(二)模型定义
我们将构建一个包含两个隐藏层的简单神经网络。
Python
复制
import torch.nn as nn
import torch.nn.functional as F
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128) # 输入层到隐藏层1
self.fc2 = nn.Linear(128, 64) # 隐藏层1到隐藏层2
self.fc3 = nn.Linear(64, 10) # 隐藏层2到输出层
def forward(self, x):
x = x.view(-1, 28 * 28) # 将图像展平为一维向量
x = F.relu(self.fc1(x)) # 激活函数ReLU
x = F.relu(self.fc2(x))
x = self.fc3(x)
return F.log_softmax(x, dim=1) # 使用softmax进行分类
model = SimpleNet()(三)训练过程
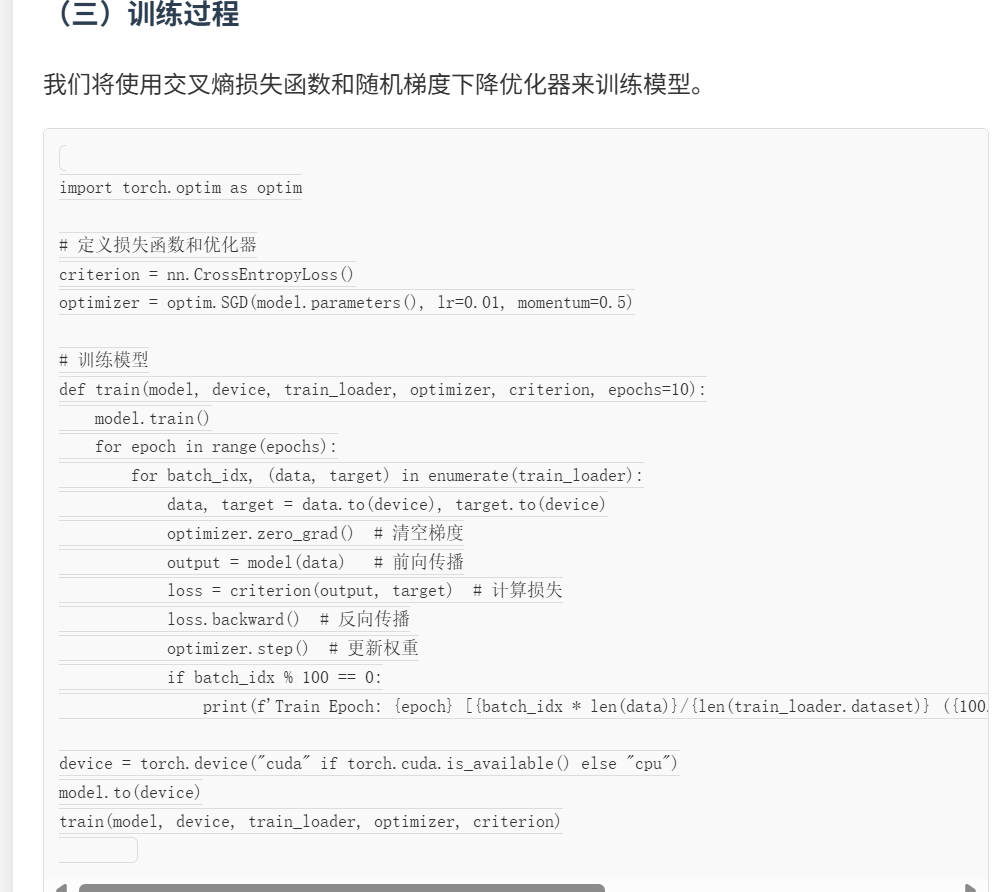
我们将使用交叉熵损失函数和随机梯度下降优化器来训练模型。
Python
复制
import torch.optim as optim
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# 训练模型
def train(model, device, train_loader, optimizer, criterion, epochs=10):
model.train()
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad() # 清空梯度
output = model(data) # 前向传播
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新权重
if batch_idx % 100 == 0:
print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} ({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
train(model, device, train_loader, optimizer, criterion)(四)模型评估
我们将使用测试集来评估模型的性能。
Python
复制
def test(model, device, test_loader, criterion):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item() # 累加损失
pred = output.argmax(dim=1, keepdim=True) # 获取预测结果
correct += pred.eq(target.view_as(pred)).sum().item() # 统计正确数量
test_loss /= len(test_loader.dataset)
print(f'Test set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({100. * correct / len(test_loader.dataset):.0f}%)')
test(model, device, test_loader, criterion)五、总结
本文从深度学习的基本概念出发,介绍了神经网络的结构、激活函数、损失函数和优化算法,并通过 PyTorch 框架实现了一个简单的神经网络模型。通过这个例子,我们可以看到深度学习的强大能力和易用性。未来,随着硬件技术的发展和算法的不断改进,深度学习将在更多领域发挥重要作用。