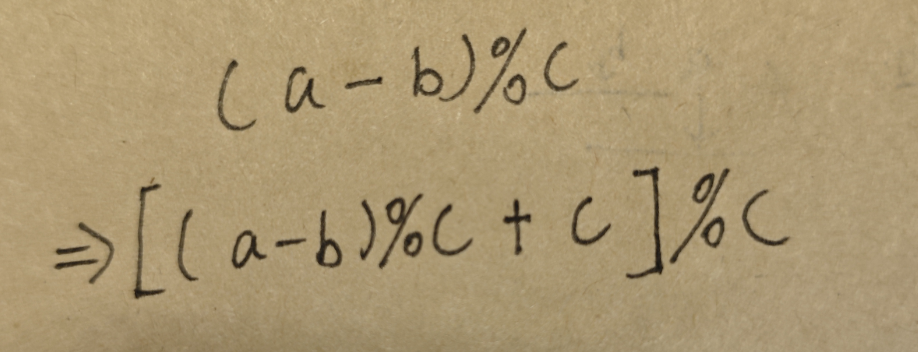下面将详细介绍如何基于 PyTorch 框架实现 OC-SORT(Observation-Centric SORT)算法。OC-SORT 是一种高性能的多目标跟踪算法,特别适用于复杂场景下的目标跟踪。我们将从算法原理到具体实现逐步展开。
1. 算法概述与核心原理
OC-SORT 在传统 SORT 算法的基础上,引入了三个关键创新点:
- 以观测为中心的在线平滑(OOS):解决长时间遮挡导致的轨迹漂移问题
- 以观测为中心的恢复(ORU):处理短期遮挡后的轨迹恢复
- 以观测为中心的动量(OCM):通过运动方向一致性优化数据关联
2. 环境准备与依赖安装
首先需要安装必要的依赖库:
pip install torch torchvision torchaudio # PyTorch基础库
pip install numpy scipy matplotlib # 科学计算与可视化
pip install opencv-python # 计算机视觉任务3. 核心模块实现
下面我们将实现 OC-SORT 的核心组件:
3.1 卡尔曼滤波器实现
import torch
import numpy as np
class KalmanFilter:
"""
卡尔曼滤波器实现,用于目标状态的预测和更新
状态向量: [x, y, a, h, vx, vy, va, vh]
其中(x,y)是边界框中心,a是宽高比,h是高度,vx,vy,va,vh是对应的速度
"""
def __init__(self):
# 状态转移矩阵 (8x8)
self.F = torch.eye(8, dtype=torch.float32)
dt = 1.0 # 时间间隔
self.F[:4, 4:] = torch.eye(4, dtype=torch.float32) * dt
# 观测矩阵 (4x8) - 只观测位置和宽高
self.H = torch.zeros((4, 8), dtype=torch.float32)
self.H[:4, :4] = torch.eye(4, dtype=torch.float32)
# 过程噪声协方差
self.Q = torch.eye(8, dtype=torch.float32)
self.Q[:4, :4] *= 0.01 # 位置噪声
self.Q[4:, 4:] *= 0.001 # 速度噪声
# 观测噪声协方差
self.R = torch.eye(4, dtype=torch.float32) * 0.01
def initiate(self, measurement):
"""
初始化轨迹状态
measurement: [x1, y1, x2, y2] 检测框坐标
"""
# 转换为 [x, y, a, h] 格式
x1, y1, x2, y2 = measurement
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
a = w / h
# 初始化状态向量 [x, y, a, h, vx, vy, va, vh]
mean = torch.tensor([cx, cy, a, h, 0, 0, 0, 0], dtype=torch.float32)
# 初始化协方差矩阵
covariance = torch.eye(8, dtype=torch.float32) * 1000.0
covariance[4:, 4:] *= 100.0
return mean, covariance
def predict(self, mean, covariance):
"""
预测下一时刻的状态
"""
# 状态预测
mean = torch.matmul(self.F, mean)
# 协方差预测
covariance = torch.matmul(torch.matmul(self.F, covariance), self.F.T) + self.Q
return mean, covariance
def project(self, mean, covariance):
"""
将状态向量投影到观测空间
"""
# 计算观测预测
projected_mean = torch.matmul(self.H, mean)
# 计算观测协方差
projected_covariance = torch.matmul(torch.matmul(self.H, covariance), self.H.T) + self.R
return projected_mean, projected_covariance
def update(self, mean, covariance, measurement):
"""
基于观测更新状态估计
"""
# 计算卡尔曼增益
projected_mean, projected_covariance = self.project(mean, covariance)
chol_factor, lower = torch.linalg.cholesky_ex(projected_covariance)
kalman_gain = torch.cholesky_solve(
torch.matmul(covariance, self.H.T), chol_factor, upper=not lower
).T
# 计算状态更新
innovation = measurement - projected_mean
new_mean = mean + torch.matmul(innovation, kalman_gain.T)
# 计算更新后的协方差
I = torch.eye(mean.size(0), dtype=torch.float32)
new_covariance = torch.matmul(I - torch.matmul(kalman_gain, self.H), covariance)
return new_mean, new_covariance3.2 轨迹管理类
class TrackState:
"""轨迹状态枚举类"""
Tentative = 1 # 暂定状态
Confirmed = 2 # 确认状态
Deleted = 3 # 已删除状态
class Track:
"""
单个目标轨迹管理类
"""
def __init__(self, mean, covariance, track_id, n_init, max_age,
feature=None, oc_sort_config=None):
self.mean = mean # 状态向量
self.covariance = covariance # 协方差矩阵
self.track_id = track_id # 轨迹ID
self.hits = 1 # 命中次数
self.age = 1 # 轨迹存在时间
self.state = TrackState.Tentative # 初始状态为暂定
self.n_init = n_init # 确认轨迹所需的连续命中次数
self.max_age = max_age # 最大未命中次数
# 轨迹历史
self.history = [mean.clone()]
self.observations = [] # 观测历史
self.features = [] # 特征历史
if feature is not None:
self.features.append(feature)
# OC-SORT特定配置
self.oc_sort_config = oc_sort_config or {
'momentum': 0.2, # 运动方向一致性权重
'deltat': 3, # 计算运动方向的时间窗口
'asso_func': 'iou', # 关联函数类型
'inertia': 0.2 # 运动惯性权重
}
# 运动方向相关
self.velocity = None # 当前速度向量
self.direction = None # 当前运动方向
def predict(self, kf):
"""
使用卡尔曼滤波器预测下一时刻状态
"""
self.mean, self.covariance = kf.predict(self.mean, self.covariance)
self.history.append(self.mean.clone())
self.age += 1
# 更新运动方向
self._update_direction()
def update(self, kf, detection, feature=None):
"""
根据检测结果更新轨迹
"""
self.mean, self.covariance = kf.update(self.mean, self.covariance, detection)
self.history.append(self.mean.clone())
self.observations.append(detection.clone())
self.hits += 1
if feature is not None:
self.features.append(feature)
# 更新状态
if self.state == TrackState.Tentative and self.hits >= self.n_init:
self.state = TrackState.Confirmed
# 更新运动方向
self._update_direction()
def mark_missed(self):
"""
标记轨迹未匹配到检测
"""
if self.state == TrackState.Tentative:
self.state = TrackState.Deleted
elif self.age > self.max_age:
self.state = TrackState.Deleted
def is_tentative(self):
return self.state == TrackState.Tentative
def is_confirmed(self):
return self.state == TrackState.Confirmed
def is_deleted(self):
return self.state == TrackState.Deleted
def to_tlbr(self):
"""
将状态向量转换为边界框格式 [x1, y1, x2, y2]
"""
ret = self.mean.clone()
w = ret[2] * ret[3] # 宽 = 宽高比 * 高
h = ret[3] # 高
ret[0] = ret[0] - w / 2 # x1 = x - w/2
ret[1] = ret[1] - h / 2 # y1 = y - h/2
ret[2] = ret[0] + w # x2 = x1 + w
ret[3] = ret[1] + h # y2 = y1 + h
return ret[:4]
def _update_direction(self):
"""
更新轨迹运动方向
"""
if len(self.history) < self.oc_sort_config['deltat'] + 1:
return
# 计算当前位置与deltat帧前位置的差
current_pos = self.history[-1][:2]
prev_pos = self.history[-self.oc_sort_config['deltat'] - 1][:2]
direction = current_pos - prev_pos
# 归一化方向向量
norm = torch.norm(direction)
if norm > 1e-6:
self.direction = direction / norm
# 计算速度 (位置变化/时间)
self.velocity = direction / self.oc_sort_config['deltat']
3.3 数据关联模块
def iou_batch(bboxes1, bboxes2):
"""
计算两组边界框之间的IoU矩阵
bboxes1: [N, 4] 格式为 [x1, y1, x2, y2]
bboxes2: [M, 4] 格式为 [x1, y1, x2, y2]
返回: [N, M] IoU矩阵
"""
# 扩展维度以广播计算
bboxes1 = bboxes1.unsqueeze(1) # [N, 1, 4]
bboxes2 = bboxes2.unsqueeze(0) # [1, M, 4]
# 计算交集区域
inter_min = torch.max(bboxes1[..., :2], bboxes2[..., :2]) # [N, M, 2]
inter_max = torch.min(bboxes1[..., 2:], bboxes2[..., 2:]) # [N, M, 2]
inter_wh = torch.clamp(inter_max - inter_min, min=0) # [N, M, 2]
inter_area = inter_wh[..., 0] * inter_wh[..., 1] # [N, M]
# 计算各自的面积
area1 = (bboxes1[..., 2] - bboxes1[..., 0]) * \
(bboxes1[..., 3] - bboxes1[..., 1]) # [N, 1]
area2 = (bboxes2[..., 2] - bboxes2[..., 0]) * \
(bboxes2[..., 3] - bboxes2[..., 1]) # [1, M]
# 计算并集面积
union_area = area1 + area2 - inter_area # [N, M]
# 计算IoU
iou = inter_area / torch.clamp(union_area, min=1e-6) # [N, M]
return iou
def linear_assignment(cost_matrix, thresh):
"""
匈牙利算法解决最优分配问题
"""
if cost_matrix.size(0) == 0 or cost_matrix.size(1) == 0:
return np.empty((0, 2), dtype=int), tuple(range(cost_matrix.size(0))), tuple(range(cost_matrix.size(1)))
cost_matrix = cost_matrix.cpu().numpy()
row_ind, col_ind = linear_sum_assignment(cost_matrix)
matches, unmatched_a, unmatched_b = [], [], []
for i in range(len(row_ind)):
if cost_matrix[row_ind[i], col_ind[i]] > thresh:
unmatched_a.append(row_ind[i])
unmatched_b.append(col_ind[i])
else:
matches.append([row_ind[i], col_ind[i]])
if len(matches) == 0:
matches = np.empty((0, 2), dtype=int)
else:
matches = np.array(matches)
if len(unmatched_a) == 0:
unmatched_a = tuple()
else:
unmatched_a = tuple(unmatched_a)
if len(unmatched_b) == 0:
unmatched_b = tuple()
else:
unmatched_b = tuple(unmatched_b)
return matches, unmatched_a, unmatched_b
def associate_detections_to_tracks(detections, tracks, iou_threshold=0.3,
velocities=None, previous_obs=None, vdc_weight=0.2):
"""
将检测结果与轨迹进行关联
"""
if len(tracks) == 0:
return np.empty((0, 2), dtype=int), np.arange(len(detections)), np.empty((0,), dtype=int)
# 计算IoU矩阵
iou_matrix = iou_batch(detections, torch.stack([t.to_tlbr() for t in tracks]))
# 如果提供了速度信息,则计算运动方向一致性
if velocities is not None and previous_obs is not None and vdc_weight > 0:
# 计算当前检测与历史观测之间的方向
detection_centers = (detections[:, :2] + detections[:, 2:]) / 2
prev_obs_centers = previous_obs[:, :2]
# 计算方向向量
directions = detection_centers - prev_obs_centers
norms = torch.norm(directions, dim=1, keepdim=True)
directions = directions / torch.clamp(norms, min=1e-6)
# 计算方向一致性代价
velocity_cost = torch.zeros_like(iou_matrix)
for i in range(len(detections)):
for j in range(len(tracks)):
if tracks[j].direction is not None:
# 计算方向余弦相似度 (值越大越相似)
cos_sim = torch.dot(directions[i], tracks[j].direction)
# 转换为代价 (值越小越相似)
velocity_cost[i, j] = 1.0 - cos_sim
# 合并IoU和方向一致性代价
cost_matrix = (1 - vdc_weight) * (1 - iou_matrix) + vdc_weight * velocity_cost
else:
# 仅使用IoU作为代价
cost_matrix = 1 - iou_matrix
# 设置阈值并进行匈牙利算法分配
matches, unmatched_dets, unmatched_tracks = linear_assignment(cost_matrix, thresh=1 - iou_threshold)
return matches, unmatched_dets, unmatched_tracks
3.4 OC-SORT 主类实现
class OCSORT:
"""
OC-SORT算法实现
"""
def __init__(self, det_thresh=0.4, max_age=30, min_hits=3,
iou_threshold=0.3, delta_t=3, asso_func="iou", inertia=0.2,
use_byte=False):
self.det_thresh = det_thresh
self.max_age = max_age
self.min_hits = min_hits
self.iou_threshold = iou_threshold
self.delta_t = delta_t
self.asso_func = asso_func
self.inertia = inertia
self.use_byte = use_byte
self.kf = KalmanFilter()
self.tracks = []
self._next_id = 1
# 存储上一帧的观测结果,用于计算运动方向
self.previous_obs = {}
def update(self, dets, scores, classes=None, features=None):
"""
更新跟踪结果
dets: 检测框 [N, 4],格式为 [x1, y1, x2, y2]
scores: 置信度 [N]
classes: 类别 [N] (可选)
features: 特征 [N, feature_dim] (可选)
"""
# 过滤低分检测
valid_indices = scores > self.det_thresh
dets = dets[valid_indices]
scores = scores[valid_indices]
if classes is not None:
classes = classes[valid_indices]
if features is not None:
features = features[valid_indices]
# 提取当前帧的检测中心
current_obs = {}
# 预测轨迹
for track in self.tracks:
track.predict(self.kf)
# 第一阶段关联:IoU匹配
if len(dets) > 0 and len(self.tracks) > 0:
# 准备用于关联的轨迹信息
track_indices = [i for i, track in enumerate(self.tracks) if track.is_confirmed()]
confirmed_tracks = [self.tracks[i] for i in track_indices]
# 提取上一帧的观测结果用于运动方向计算
velocities = torch.zeros((len(confirmed_tracks), 2), dtype=torch.float32)
previous_obs = torch.zeros((len(confirmed_tracks), 4), dtype=torch.float32)
has_velocity = [False] * len(confirmed_tracks)
for i, track in enumerate(confirmed_tracks):
if track.track_id in self.previous_obs and track.velocity is not None:
velocities[i] = track.velocity
previous_obs[i] = self.previous_obs[track.track_id]
has_velocity[i] = True
# 关联检测与轨迹
matches, unmatched_dets, unmatched_tracks = associate_detections_to_tracks(
dets, [self.tracks[i] for i in track_indices],
iou_threshold=self.iou_threshold,
velocities=velocities if any(has_velocity) else None,
previous_obs=previous_obs if any(has_velocity) else None,
vdc_weight=self.inertia
)
# 转换为全局轨迹索引
matches = [(track_indices[i], j) for i, j in matches]
unmatched_tracks = [track_indices[i] for i in unmatched_tracks]
# 更新匹配的轨迹
for track_idx, det_idx in matches:
self.tracks[track_idx].update(
self.kf, dets[det_idx], features[det_idx] if features is not None else None
)
# 记录当前观测
current_obs[self.tracks[track_idx].track_id] = dets[det_idx]
else:
matches = []
unmatched_dets = list(range(len(dets)))
unmatched_tracks = list(range(len(self.tracks)))
# 处理未匹配的检测
for det_idx in unmatched_dets:
mean, covariance = self.kf.initiate(dets[det_idx])
self.tracks.append(Track(
mean, covariance, self._next_id, self.min_hits, self.max_age,
features[det_idx] if features is not None else None,
oc_sort_config={
'momentum': self.inertia,
'deltat': self.delta_t,
'asso_func': self.asso_func,
'inertia': self.inertia
}
))
self._next_id += 1
# 记录当前观测
current_obs[self.tracks[-1].track_id] = dets[det_idx]
# 处理未匹配的轨迹
for track_idx in unmatched_tracks:
self.tracks[track_idx].mark_missed()
# 应用以观测为中心的恢复机制 (ORU)
if self.use_byte and len(unmatched_tracks) > 0 and len(unmatched_dets) > 0:
# 提取未匹配的轨迹和检测
tracks = [self.tracks[i] for i in unmatched_tracks if not self.tracks[i].is_tentative()]
detections = dets[unmatched_dets]
detection_features = features[unmatched_dets] if features is not None else None
if len(tracks) > 0 and len(detections) > 0:
# 计算外观相似度 (这里简化处理,实际应用中可使用更复杂的ReID模型)
if detection_features is not None:
track_features = [torch.cat(t.features[-3:]) if len(t.features) > 0 else torch.zeros_like(detection_features[0]) for t in tracks]
track_features = torch.stack(track_features)
# 计算余弦相似度
sim_matrix = torch.matmul(detection_features, track_features.T)
# 关联
matches_oru, unmatched_dets_oru, unmatched_tracks_oru = linear_assignment(
1 - sim_matrix, thresh=0.7 # 外观相似度阈值
)
# 更新匹配的轨迹
for i, j in matches_oru:
track_idx = unmatched_tracks[unmatched_tracks_oru[j]]
det_idx = unmatched_dets[unmatched_dets_oru[i]]
self.tracks[track_idx].update(
self.kf, dets[det_idx], features[det_idx] if features is not None else None
)
# 记录当前观测
current_obs[self.tracks[track_idx].track_id] = dets[det_idx]
# 移除已删除的轨迹
self.tracks = [t for t in self.tracks if not t.is_deleted()]
# 更新上一帧观测结果
self.previous_obs = current_obs
# 输出确认的轨迹和暂定轨迹
output_results = []
for track in self.tracks:
if track.is_confirmed() or (track.is_tentative() and track.hits >= 1):
bbox = track.to_tlbr()
track_id = track.track_id
output_results.append({
'bbox': bbox.cpu().numpy(),
'track_id': track_id,
'score': scores.max().item() if len(scores) > 0 else 1.0,
'class': classes[0].item() if classes is not None and len(classes) > 0 else 0
})
return output_results
4. 使用示例
下面是一个简单的使用示例,展示如何将 OC-SORT 集成到目标检测流程中:
import cv2
import torch
# 假设这是你的目标检测模型
def detect_objects(frame):
"""返回检测框、置信度和类别"""
# 这里应该是实际的目标检测代码
# 简化示例,随机生成一些检测结果
num_detections = torch.randint(3, 10, (1,)).item()
detections = torch.rand(num_detections, 4) * torch.tensor([frame.shape[1], frame.shape[0], frame.shape[1], frame.shape[0]])
scores = torch.rand(num_detections)
classes = torch.zeros(num_detections, dtype=torch.long) # 假设所有类别都是0
# 确保检测框格式正确 [x1, y1, x2, y2]
detections[:, 2:] += detections[:, :2]
return detections, scores, classes
# 初始化OC-SORT跟踪器
tracker = OCSORT(det_thresh=0.5, max_age=30, min_hits=3,
iou_threshold=0.3, delta_t=3, inertia=0.2)
# 打开视频文件或摄像头
cap = cv2.VideoCapture(0) # 0表示默认摄像头
while True:
ret, frame = cap.read()
if not ret:
break
# 转换为PyTorch张量
frame_tensor = torch.from_numpy(frame).permute(2, 0, 1).float() / 255.0
# 目标检测
detections, scores, classes = detect_objects(frame)
# 多目标跟踪
tracks = tracker.update(detections, scores, classes)
# 可视化结果
for track in tracks:
bbox = track['bbox'].astype(int)
track_id = track['track_id']
cls = track['class']
# 绘制边界框
cv2.rectangle(frame, (bbox[0], bbox[1]), (bbox[2], bbox[3]), (0, 255, 0), 2)
# 绘制跟踪ID和类别
cv2.putText(frame, f"ID: {track_id} Cls: {cls}", (bbox[0], bbox[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# 显示结果
cv2.imshow('OC-SORT Tracking', frame)
# 按ESC键退出
if cv2.waitKey(1) == 27:
break
cap.release()
cv2.destroyAllWindows()5. 参数调优建议
OC-SORT 有几个关键参数会影响跟踪性能,建议根据实际场景调整:
- 检测阈值 (det_thresh):默认 0.4,值越高过滤掉的低置信度检测越多
- 最大未匹配帧数 (max_age):默认 30,值越大允许目标长时间遮挡后重新关联
- 确认轨迹所需命中次数 (min_hits):默认 3,值越小轨迹确认越快但可能不稳定
- IoU 阈值 (iou_threshold):默认 0.3,值越高关联越严格
- 运动惯性权重 (inertia):默认 0.2,控制运动方向一致性在关联中的重要性
6. 性能优化建议
- 使用更高效的目标检测器(如 YOLOv5/YOLOv8)
- 考虑使用轻量级 ReID 模型增强外观匹配能力
- 对于实时性要求高的场景,可降低 delta_t 参数值
- 在嵌入式设备上部署时,考虑使用模型量化和剪枝技术
通过以上步骤,在 PyTorch 框架下实现一个完整的 OC-SORT 多目标跟踪系统,适用于各种复杂场景下的目标跟踪任务。