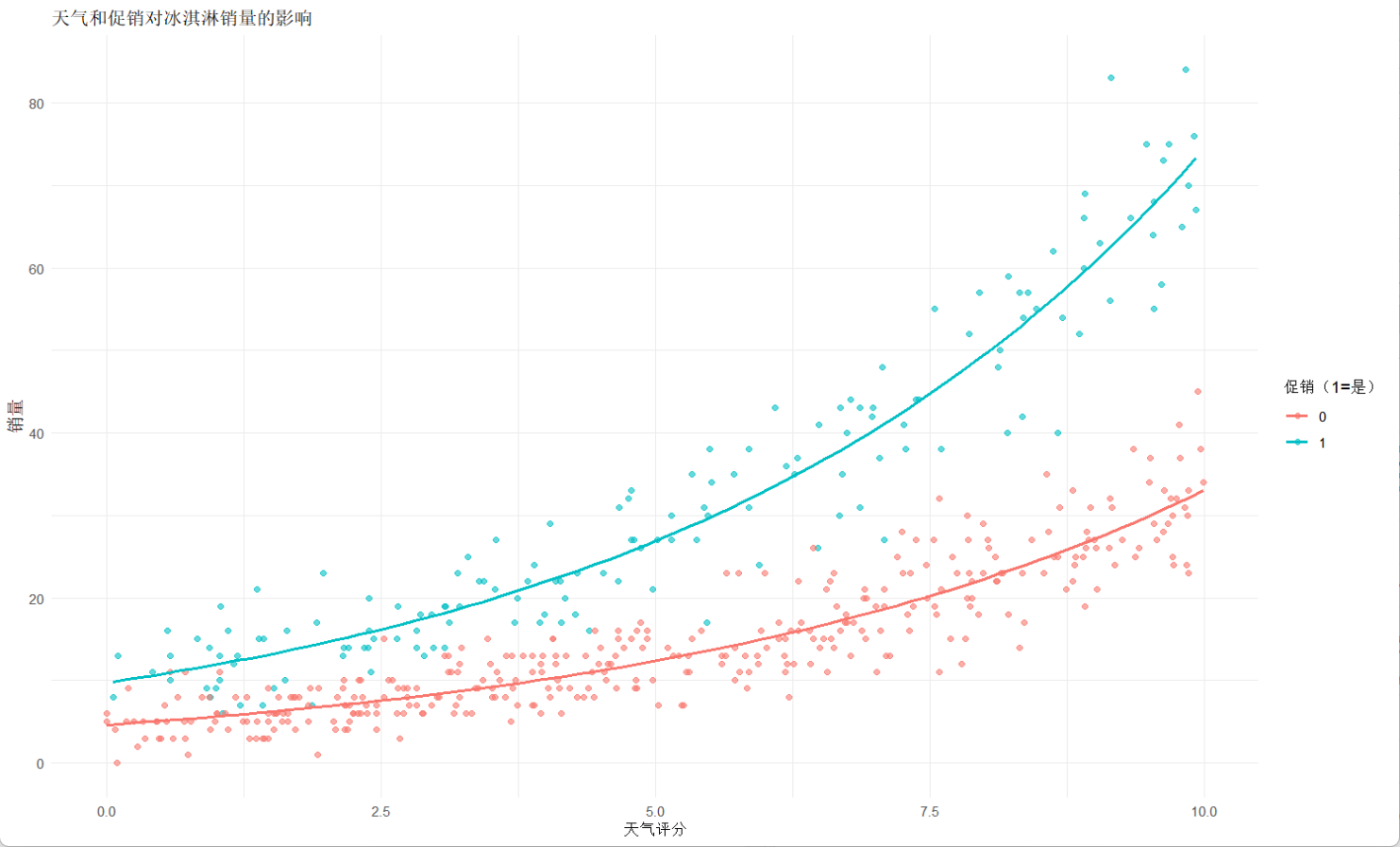
方法一:对列表的获取进行分页处理
实现方法:
前端请求(需要向后端传两个参数,pageIndex是获取第几页是从0开始,pageSize是这一页需要获取多少个数据)
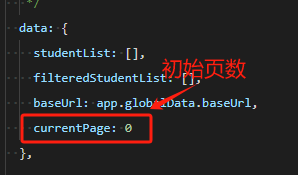
![]()
后端接口实现(因为这里是通过参数拼接请求的形式传数据,所以接口使用HttpGet进行获取)

当我们拿到这两个参数后需要使用sql语句去本地数据库进行分页取数据
![]()
代码如下:
var sqlStr = $"select * from UserInfo where UserType=1 ORDER BY UserInfoId OFFSET {pageIndex * pageSize} ROWS FETCH NEXT {pageSize} ROWS ONLY;";
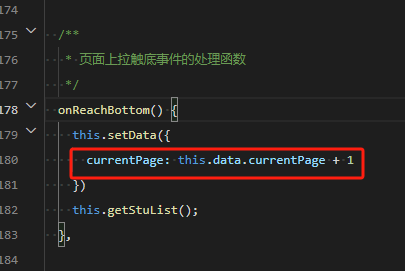
这里就将获取的数据进行返回就可以了,在返回后如果想加载下一页的数据。(这里使用了微信小程序上拉触底的事件)
直接找到上拉触底事件的生命周期,然后在其中先对当前页进行加1,在去请求获取数据的接口(获取的数据需要自己处理到当前的数据列表中,这样才不会丢失已存在的数据)
方法二:在保存数据时就对前端返回的二进制图片数据进行压缩处理(后端处理压缩,前端不太好实现)

在前端获取的数据流就是如上图所示传到后端的时候是使用string类型接收的
首先我们先去实现一个工具类:
/// <summary> /// 图片压缩工具类 /// </summary> public class ImageCompressor { public byte[] CompressImageFromBase64(string base64Data, long quality = 70L) { // 1. 去除Base64头(如"data:image/png;base64,") //var cleanBase64 = base64Data.Split(',')[1]; byte[] imageBytes = Convert.FromBase64String(base64Data); // 2. 加载图片并压缩 using (var msInput = new MemoryStream(imageBytes)) using (var image = Image.FromStream(msInput)) using (var msOutput = new MemoryStream()) { // 设置JPEG压缩质量(如果是PNG,调整格式) var encoderParams = new EncoderParameters(1); encoderParams.Param[0] = new EncoderParameter(Encoder.Quality, quality); // 获取JPEG编码器 var jpegEncoder = GetEncoder(ImageFormat.Jpeg); // 保存压缩后的图片 image.Save(msOutput, jpegEncoder, encoderParams); return msOutput.ToArray(); } } private ImageCodecInfo GetEncoder(ImageFormat format) { var codecs = ImageCodecInfo.GetImageDecoders(); foreach (var codec in codecs) { if (codec.FormatID == format.Guid) return codec; } return null; } }这个工具类可以将前端传的base64String类型的数据转为二进制数进行存储,并将文件压缩为原先百分之70(这样在获取的时候对图片精度要求不高的情况下是可以使用的)
方法三:对大文件进行分片存储

![[科研实践] VS Code (Copilot) + Overleaf (使用 Overleaf Workshop 插件)](https://i-blog.csdnimg.cn/direct/6d89edc06c1042ceacbf04fe3e7477e3.png)