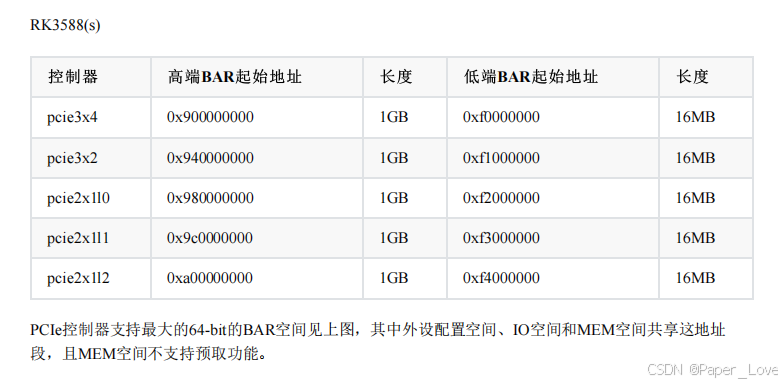
前言
本文总结了SQLite数据库的核心操作要点:1. 基础语法:SQL语句不区分大小写,多语句需用分号分隔,支持多种注释方式2. 表操作:包括创建表(定义主键、非空约束等)、插入/更新/删除数据、添加/修改/删除列3. 查询进阶:JOIN连接的四种方式(内/左/右/全连接)、UNION组合查询、子查询嵌套4. 性能优化:索引的创建与管理,视图的创建与应用5. 高级功能:分组排序(GROUP BY)、条件筛选(HAVING)、开窗函数等6. 实战示例:包含第N高数据查询、连续出现N次记录查询等典型场景解决方案
一、SQL 语法要点
SQL 语句不区分大小写 ,但是数据库表名、列名和值是否区分,依赖于具体的 DBMS 以及配置。例如:SELECT 与 select 、Select 是相同的。
多条 SQL 语句必须以分号(;)分隔 。
处理 SQL 语句时, 所有空格都被忽略 。SQL 语句可以写成一行,也可以分写为多行。
二、计算机处理顺序
select
from
where (列名=条件)
group by
order by 条件(按条件分组),聚合语句(函数)
- SQL 支持三种注释
## 注释1
-- 注释2
/* 注释3 */三、操作
1.创建表
create table 表名(
主键名 类型 primary key
第二列名 类型 (text) not null(不为空),
第三列名 类型 (text) not null(不为空),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP -- 默认值为当前时间;
);
id是主键,代表每个用户的唯一标识。username和email是用户的基本信息,不能为空且邮箱唯一。created_at会自动记录每条记录创建的时间。
des ‘表1’
可以先看下表的情况。
2. 向 user 表插入数据
insert into 表1(字段1,字段2)
values
(1,2,3);
(1,3,4);
(2,4,5);
3.查询数据
4.更新数据
update 表1 set 修改的字段名 =要修改值 where 条件=‘ ’;
更新 Bob 的年龄:
UPDATE user SET age = 32 WHERE username = 'Bob'
5.删除数据
delect from 表名 where 字段=‘ ’
DELETE FROM user WHERE username = 'Charlie';6.删除所有数据(清空表):
DELETE FROM user;7.连接表
join的四种写法:
- inner join,取交集
- left join,右表中没有的数据用null填充
- right jion,左表中没有的数据用null填充
- full join,取并集

笛卡尔积:2个矩阵相乘,数据最多的表作为行数。
- 如果一个 JOIN 至少有一个公共字段并且它们之间存在关系,则该 JOIN 可以在两个或多个表上工作。
- 连接用于连接多个表,使用 JOIN 关键字,并且条件语句使用 ON 而不是 WHERE。
SELECT column_name(s)
FROM table1 INNER JOIN table2
ON table1.column_name = table2.column_name;
将玩家表和装备表合并,以下两种方法都可以。
select * from player(形成左表)
right join 右表
on 表1.字段名=表2.字段
select * from 左表,右表
where 表1.字段min = 表2.字段
SELECT customers.cust_id, orders.order_num
FROM customers RIGHT JOIN orders
ON customers.cust_id = orders.cust_id;select 表1.字段1,表1.字段2
from 表1 inner join 表2
条件:on 表1.字段1 = 表2.字段2
8.索引——提高查询效率
更新一个包含索引的表需要比更新一个没有索引的表花费更多的时间,这是由于索引本身也需要更新。因此,理想的做法是仅仅在常常被搜索的列(以及表)上面创建索引。
创建:
create index 索引名称 on 表名(字段)
查询索引:
show index from 表名
删除索引
drop index 索引名称 on 表名
增加索引
alter table 表名 add index 索引名称 (需要添加索引的字段)
9.修改列
添加列
- ALTER TABLE userADD age int(3);
删除列
- ALTER TABLE userDROP COLUMN age;
修改列
- ALTER TABLE `user`MODIFY COLUMN age tinyint;
10.修改主键
添加主键
- ALTER TABLE userADD PRIMARY KEY (id);
删除主键
- ALTER TABLE userDROP PRIMARY KEY;
(二)视图(VIEW)
1.定义
视图是基于 SQL 语句的结果集的可视化的表。
视图是虚拟的表,本身不包含数据,也就不能对其进行索引操作。对视图的操作和对普通表的操作一样。
2.作用
简化复杂的 SQL 操作,比如复杂的联结;
只使用实际表的一部分数据;
通过只给用户访问视图的权限,保证数据的安全性;
更改数据格式和表示。
3.创建视图
CREATE VIEW 视图名称(例如,top_10_user_view) AS
SELECT id, username
FROM user
WHERE id < 10;
4.删除视图
DROP VIEW top_10_user_view;
(三)组合(UNION)
1.定义
UNION 运算符将两个或更多查询的结果组合起来,并生成一个结果集,其中包含来自 UNION 中参与查询的提取行。
UNION 用于组合两个或多个 SELECT 查询的结果。其基本语法如下:
SELECT column1, column2, ...
FROM table1
UNION
SELECT column1, column2, ...
FROM table2;2.关键点:
-
列的数量和数据类型必须匹配:
-
每个
SELECT查询必须返回相同数量的列,并且对应列的数据类型必须兼容。 -
例如,如果第一个查询返回两个列(
INT和VARCHAR),第二个查询也必须返回两个列,且数据类型分别为INT和VARCHAR。
-
-
自动去除重复行:
-
默认情况下,
UNION会自动去除重复的行。如果你希望保留重复的行,可以使用UNION ALL。
-
-
列名和排序:
-
结果集中的列名将由第一个
SELECT查询中的列名决定。 -
如果需要对最终结果进行排序,可以在最后一个查询后使用
ORDER BY。
-
3.UNION 的示例
假设我们有两个表:Customers 和 Suppliers,它们的结构如下:
Customers 表
| cust_id | cust_name | cust_address |
|---|---|---|
| 1 | Alice | 123 Main St |
| 2 | Bob | 456 Elm St |
| 3 | Charlie | 789 Oak St |
Suppliers 表
| supp_id | supp_name | supp_address |
|---|---|---|
| 1 | Supplier A | 101 Pine St |
| 2 | Supplier B | 202 Maple St |
| 3 | Supplier C | 303 Birch St |
示例 1:
使用 UNION 合并两个表
假设我们想列出所有客户和供应商的名称和地址:
SELECT cust_name AS name, cust_address AS address
FROM Customers
UNION
SELECT supp_name AS name, supp_address AS address
FROM Suppliers;查询结果:
| name | address |
|---|---|
| Alice | 123 Main St |
| Bob | 456 Elm St |
| Charlie | 789 Oak St |
| Supplier A | 101 Pine St |
| Supplier B | 202 Maple St |
| Supplier C | 303 Birch St |
UNION ALL
如果你希望保留重复的行,可以使用 UNION ALL。UNION ALL 不会自动去除重复行,而是将两个查询的结果直接合并。
示例 2:使用 UNION ALL
假设 Customers 表和 Suppliers 表中有重复的名称和地址:
SELECT cust_name AS name, cust_address AS address
FROM Customers
UNION ALL
SELECT supp_name AS name, supp_address AS address
FROM Suppliers;如果 Customers 和 Suppliers 表中有重复的行,UNION ALL 会将它们全部保留。
四、ORDER BY 和 UNION
1.定义
ORDER BY 可以在 UNION 查询的最后使用,对整个结果集进行排序。
示例 3:使用 ORDER BY
sql复制
SELECT cust_name AS name, cust_address AS address
FROM Customers
UNION
SELECT supp_name AS name, supp_address AS address
FROM Suppliers
ORDER BY name;查询结果:
| name | address |
|---|---|
| Alice | 123 Main St |
| Bob | 456 Elm St |
| Charlie | 789 Oak St |
| Supplier A | 101 Pine St |
| Supplier B | 202 Maple St |
| Supplier C | 303 Birch St |
2.注意事项
-
列的数量和数据类型:
-
每个
SELECT查询必须返回相同数量的列,并且对应列的数据类型必须兼容。 -
如果列的数量或数据类型不匹配,SQL 会报错。
-
-
去除重复行:
-
默认情况下,
UNION会去除重复行。 -
如果需要保留重复行,使用
UNION ALL。
-
-
性能:
-
UNION默认会去除重复行,这可能会导致额外的性能开销,尤其是在处理大量数据时。 -
如果你确定数据中没有重复行,或者你希望保留重复行,建议使用
UNION ALL。
-
-
排序:
-
ORDER BY只能出现在最后一个查询中,用于对整个结果集进行排序。
-
示例 4:从同一个表中提取不同条件的数据
假设你想列出所有年龄大于20岁的客户和所有年龄小于20岁的客户:
SELECT cust_name, cust_age
FROM Customers
WHERE cust_age > 20
UNION
SELECT cust_name, cust_age
FROM Customers
WHERE cust_age < 20;示例 5:从不同表中提取数据
假设你想列出所有客户的名称和地址,以及所有供应商的名称和地址:
SELECT cust_name AS name, cust_address AS address
FROM Customers
UNION
SELECT supp_name AS name, supp_address AS address
FROM Suppliers;3.分组排序
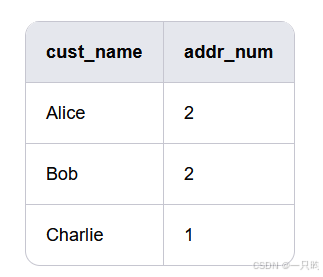
统计每个用户的地址数量

分组
SELECT cust_name, COUNT(cust_address) AS addr_num
FROM Customers GROUP BY cust_name;
分组后排序
SELECT cust_name, COUNT(cust_address) AS addr_num
FROM Customers GROUP BY cust_name
ORDER BY cust_name DESC;
HAVING
HAVING 用于对汇总的 GROUP BY 结果进行过滤。
HAVING 要求存在一个 GROUP BY 子句。
WHERE 和 HAVING 可以在相同的查询中。
开窗函数+over

三、子查询
1.定义
嵌套在较大查询中的 SQL 查询。子查询也称为内部查询或内部选择,而包含子查询的语句也称为外部查询或外部选择。
2.用法
子查询可以嵌套在 SELECT,INSERT,UPDATE 或 DELETE 语句内或另一个子查询中。
子查询通常会在另一个 SELECT 语句的 WHERE 子句中添加。
您可以使用比较运算符,如 >,<,或 =。比较运算符也可以是多行运算符,如 IN,ANY 或 ALL。
子查询必须被圆括号 () 括起来。
内部查询首先在其父查询之前执行,以便可以将内部查询的结果传递给外部查询。
————————————————
原文链接:https://blog.csdn.net/heshihu2019/article/details/132864791
3.limit取数据
取第2条数据
- limit 1 ,1 跳过1条取1条
- limit 1 offset 1 从第1条(不包括)开始取出第2条。
5.判断null-ifnull函数
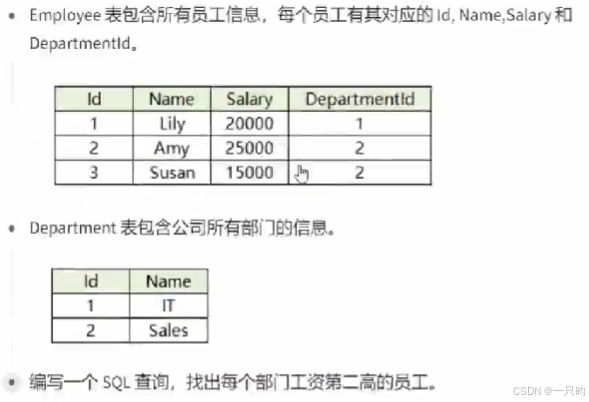
SELECT
e.Name AS EmployeeName,
e.Salary,
d.Name AS DepartmentName
FROM
Employee e
JOIN
Department d ON e.DepartmentId = d.Id
WHERE
e.Salary = (
SELECT
DISTINCT Salary
FROM
Employee
WHERE
DepartmentId = e.DepartmentId
ORDER BY
Salary DESC
LIMIT 1 OFFSET 1
);三、子查询
子查询是 嵌套在较大查询中的 SQL 查询。子查询也称为内部查询或内部选择,而包含子查询的语句也称为外部查询或外部选择。
子查询可以嵌套在 SELECT,INSERT,UPDATE 或 DELETE 语句内或另一个子查询中。
子查询通常会在另一个 SELECT 语句的 WHERE 子句中添加。
- 使用比较运算符,如 >,<,或 =。
- 比较运算符也可以是多行运算符,如 IN,ANY 或 ALL。
- 子查询必须被圆括号 () 括起来。
内部查询首先在其父查询之前执行,以便可以将内部查询的结果传递给外部查询。
SELECT 语句中的 WHERE 子句
SELECT * FROM Customers
WHERE cust_name = 'Kids Place';
UPDATE 语句中的 WHERE 子句
UPDATE Customers
SET cust_name = 'Jack Jones'
WHERE cust_name = 'Kids Place';
DELETE 语句中的 WHERE 子句
DELETE FROM Customers
WHERE cust_name = 'Kids Place';
IN 和 BETWEEN
IN 操作符在 WHERE 子句中使用,作用是在指定的几个特定值中任选一个值。
BETWEEN 操作符在 WHERE 子句中使用,作用是选取介于某个范围内的值。
IN 示例
SELECT *
FROM products
WHERE vend_id IN ('DLL01', 'BRS01');
BETWEEN 示例
SELECT *
FROM products
WHERE prod_price BETWEEN 3 AND 5;(3-5)
SELECT *
FROM (SELECT column_name FROM table_name WHERE condition) AS subquery
JOIN table_name ON subquery.column_name = table_name.column_name;
这个查询将子查询的结果作为一个临时表,然后与 table_name 进行连接。
(一)真题
1.查询不在表里的数据
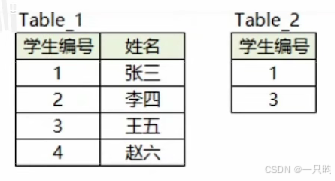
select table_1.姓名
from table_1 a left.jion table_2
on table_1.学生编号=table_2.学生编号
where table_2.学生编号 is null;2.查找第n高的数据
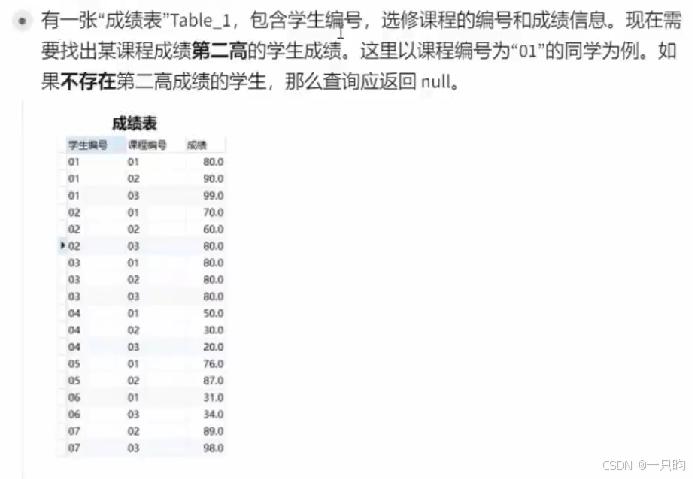
- 考虑:去重distanct;
- 如果不存在,返回null. ifnull(null,返回值)
select 学生编号 from table_1
ifnull(
select distant 成绩
from table_1
where 课程编号 ="01"
order by 成绩,desc
limit 1,1/limit 1 offset 1),
null)as "01课程第2高";3.分组排序
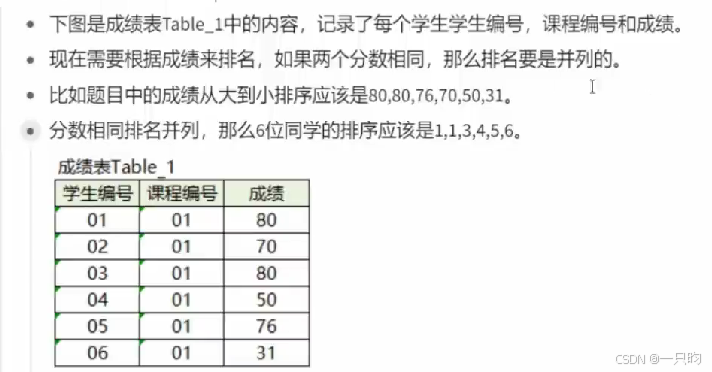
rank开窗函数
PARTITION BY:指定按照哪个字段进行分组。ORDER BY:指定按照哪个字段进行排序。
select *,
rank() over ( order by 成绩,desc) as “排名”
from table_1;4.连续出现N类

SELECT column1, column2, ...
FROM table_name
WHERE condition
GROUP BY column1, column2, ...;
GROUP BY 子句在 SQL 中用于将结果集的行分组,以便可以对每个组执行聚合函数(如 COUNT()、SUM()、AVG()、MAX()、MIN() 等)。这通常用于生成汇总或摘要数据。
select 成绩
from
select(成绩,row number()over (
select
from
Left join
on table1.coloum=table2.coloum
where
分组:group by table.id
筛选分组后的结果:having count(distinct 字段)>30;(二)基本语法
SELECT column1, column2, ...
FROM table_name
WHERE condition
GROUP BY column1, column2, ...;
column1, column2, ...是你想要分组的列。
table_name是查询的表。
condition是可选的,用于筛选记录。
(三)使用场景
-
生成汇总数据:当你想要对某个列进行汇总统计时,比如计算每个部门的员工数量。
-
与聚合函数一起使用:
GROUP BY通常与聚合函数一起使用,以计算每个组的统计数据。
示例 1:计算每个部门的员工数量
假设有一个 employees 表,包含 department_id 和 employee_name 列。
SELECT department_id, COUNT(employee_name) AS num_employees
FROM employees
GROUP BY department_id;这个查询将返回每个部门的员工数量。
示例 2:计算每个部门的平均工资
假设 employees 表还包含 salary 列。
SELECT department_id, AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id;这个查询将返回每个部门的平均工资。
示例 3:使用多列进行分组
SELECT department_id, job_title, COUNT(employee_name) AS num_employees
FROM employees
GROUP BY department_id, job_title;这个查询将返回每个部门中每个职位的员工数量。
3.注意事项
-
列的选择:在
SELECT列表中,所有非聚合列都必须包含在GROUP BY子句中。如果你在SELECT列表中包含了非聚合列,那么这些列也必须出现在GROUP BY子句中。 -
聚合函数:
GROUP BY通常与聚合函数一起使用,以计算每个组的统计数据。 -
排序:
ORDER BY子句通常用于对GROUP BY的结果进行排序,但排序的列可以是GROUP BY子句中的列,也可以是聚合函数的结果。 -
空值:在分组时,如果分组列中有空值,那么这些空值将被单独分为一个组。
GROUP BY与HAVING的区别
WHERE子句用于在分组之前筛选行。
HAVING子句用于在分组之后筛选组。HAVING通常与聚合函数一起使用,用于筛选满足特定条件的组。
示例 4:使用 HAVING 筛选组
SELECT department_id, AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
HAVING AVG(salary) > 50000;这个查询将返回平均工资超过 50000 的部门。