1. 数据爬取
我们将爬取的1G文件都保存到all_m_files目录下
查看原始数据文件数量:
find /root/all_m_files -type f | wc -l
2. 数据预处理
仅保留UTF-8 格式文件,且所有保留的代码文件长度必须大于20行
import os
import pandas as pd
def try_read_file(file_path):
for encoding in ['utf-8']:
try:
with open(file_path, "r", encoding=encoding) as f:
return f.read().strip()
except Exception:
continue
print(f"读取文件出错: {file_path},所有常用编码均失败")
return None
def collect_m_files(dir_path, min_length=20):
"""收集所有.m文件及其内容,返回列表"""
data_list = []
for root, _, files in os.walk(dir_path):
for file in files:
if file.endswith(".m") and not file.startswith('.'):
file_path = os.path.join(root, file)
content = try_read_file(file_path)
if content and len(content) >= min_length:
data_list.append({"filename": os.path.relpath(file_path, dir_path), "content": content})
return data_list
def save_to_csv(data_list, output_csv_path):
"""保存数据到CSV"""
df = pd.DataFrame(data_list)
print(f"共收集到 {len(df)} 个文件,正在保存到 {output_csv_path}")
df.to_csv(output_csv_path, index=False, encoding="utf-8")
print("保存完成!")
def main():
# 直接指定路径
input_dir = "/root/all_m_files"
output_csv = "/root/2-数据预处理/data.csv"
min_length = 20
data_list = collect_m_files(input_dir, min_length)
save_to_csv(data_list, output_csv)
if __name__ == "__main__":
main()
3. 数据质量评测
import random
import argparse
import os
from tqdm import tqdm
import pandas as pd
def del_strip_explain(content):
new_content = []
for c in content:
c = c.strip()
if c.startswith("%"):
continue
new_content.append(c)
return new_content
def read_data(args):
# fils = os.listdir(args.dir_path)
# contents = []
# files = []
# # encodings_list = ["utf-8","gbk","gbk2312"]
# for fil in fils:
# try:
# with open(os.path.join(args.dir_path,fil) ,encoding="utf-8") as f:
# data = f.read()
# except :
# try:
# with open(os.path.join(args.dir_path,fil), encoding="gbk") as f:
# data = f.read()
# except:
# continue
# contents.append(data.split("\n"))
# files.append(fil)
# return files,contents
df = pd.read_csv(args.dir_path)
return df["filename"].tolist(),df["content"].tolist()
# 文件长度
def get_score1(file,content):
# 10 30
# 10-30 60
# 30-100 100
# 100-300 80
# 300+ 70
content = del_strip_explain(content)
if isinstance(content, str):
content = content.split("\n")
elif isinstance(content, list):
pass # 已经是列表
else:
content = []
num = len(content)
if num<=10:
# print(f"{file}文件长度得分:30 ")
return 30
if 10<num<=30:
# print(f"{file}文件长度得分:60 ")
return 60
if 30<num<=100:
# print(f"{file}文件长度得分:100 ")
return 100
if 100<num<=300:
# print(f"{file}文件长度得分:80 ")
return 80
# print(f"{file}文件长度得分:70 ")
return 70
# 代码重复率
def get_score2(file,content):
content = del_strip_explain(content)
if isinstance(content, str):
content = content.split("\n")
elif isinstance(content, list):
pass # 已经是列表
else:
content = []
set_content = set(content)
if set_content:
return round(len(set_content) / len(content) * 100,2)
else:
return 0
# 关键词得分
def get_score3(file,content):
return min(len(set(" ".join(content).split(" ")) & keywords) * 15 ,100)
# 有效代码得分
def get_score4(file, content): # 有效代码得分
content2 = del_strip_explain(content)
content3 = del_print(content2)
if not content: # 防止除零
return 0
return round(len(content3) / len(content) * 100, 2)
# 多样性得分
def get_score5(file, content):
lens_ = [len(i) for i in content]
new_l = []
t = []
for i in range(len(lens_)):
if (i + 1) % 100 == 0:
new_l.append(t)
t = []
else:
t.append(lens_[i])
else:
if t:
new_l.append(t)
scores = []
for l in new_l:
if len(l) == 0:
continue
scores.append(len(set(l)) / len(l))
if not scores:
return 0 # 防止除零
return round(sum(scores) / len(scores) * 100, 2)
def del_print(content):
new_content = []
for c in content:
if "$display" in c:
continue
new_content.append(c)
return new_content
def get_score(files_list,contents_list):
file_info = "\n".join(files_list[:5])
print(f"前5个文件名:{file_info}")
print("*"*30)
all_scores = []
scores_desc = ["文件长度得分","代码重复率得分","关键词得分","有效代码得分","多样性得分"]
score1_list = []
score2_list = []
score3_list = []
score4_list = []
score5_list = []
for file,content in tqdm(zip(files_list,contents_list),total=len(files_list )):
if isinstance(content, str):
content = content.split("\n")
else:
content = []
scores_list = [get_score1,get_score2,get_score3,get_score4,get_score5]
scores_weight = [ 1,1,1 ,1 ,1]
scores = [ i(file,content) for i in scores_list]
score1_list.append(scores[0])
score2_list.append(scores[1])
score3_list.append(scores[2])
score4_list.append(scores[3])
score5_list.append(scores[4])
info = f"{file} :{sum(scores)/len(scores_list):.2f}\n每项得分:{ scores}"
print(info+"\n")
scores = sum([ s*w for s,w in zip(scores,scores_weight) ]) / sum(scores_weight)
# print("*"*10)
all_scores.append( round(scores,3) )
print(f"所有文件总分为:{ round(sum(all_scores)/len(files_list),3)}",len(all_scores) )
df = pd.DataFrame({"filename":files_list,"总分":all_scores,"文件长度得分":score1_list,"代码重复率得分":score2_list,"关键词得分":score3_list,"有效代码得分":score4_list,"多样性得分":score5_list})
df.to_csv("3-数据评分系统/score.csv",index=False,encoding="utf-8")
return scores
def get_keywords(path):
with open(path,encoding="utf-8") as f:
return f.read().split("\n")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--dir_path', type=str ,required=False,default="/root/2-数据预处理/data.csv", help='文件夹路径')
args = parser.parse_args()
keywords = set(get_keywords("/root/3-数据评分系统/keywords.txt"))
get_score(*read_data(args))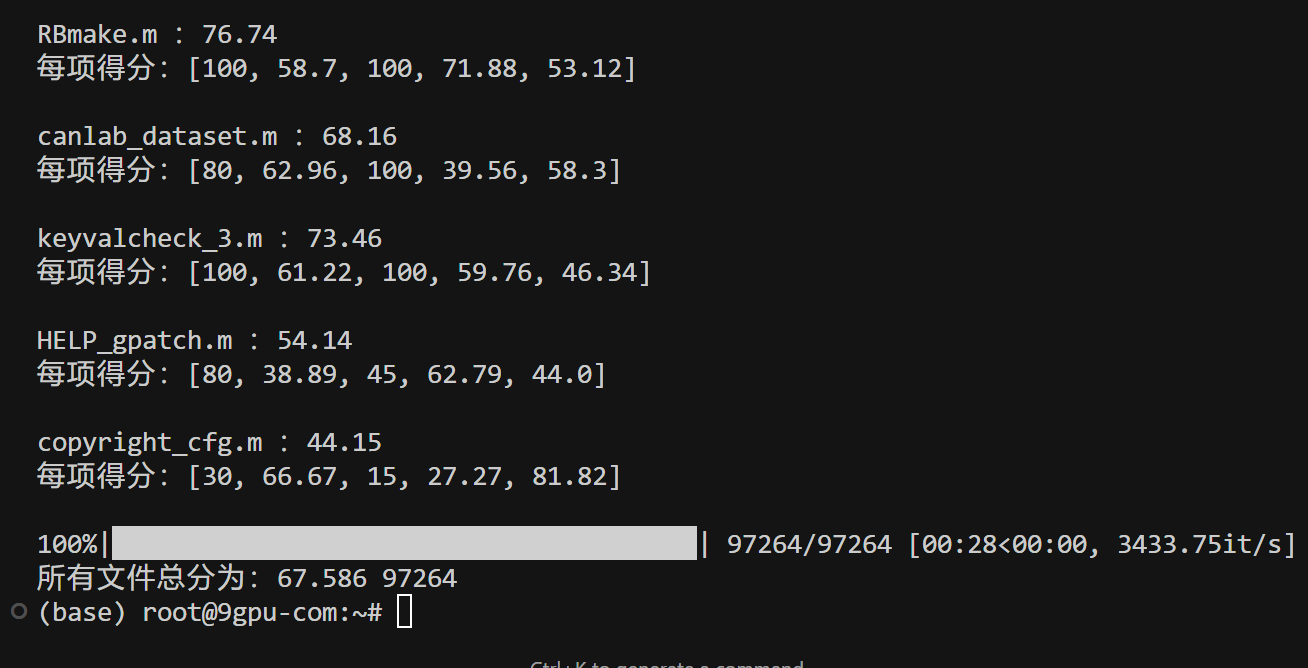
4. 基于分数段筛选数据并抽样
使用jupyter进行评分后的数据质量分析
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei'] # 如果系统中安装了 "SimHei" 字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示为方块的问题df = pd.read_csv('D:/score.csv')plt.figure(figsize=(8, 6))
sns.histplot(df['总分'], bins=20, kde=True)
plt.title('总分分布')
plt.xlabel('总分')
plt.ylabel('频率')
plt.show()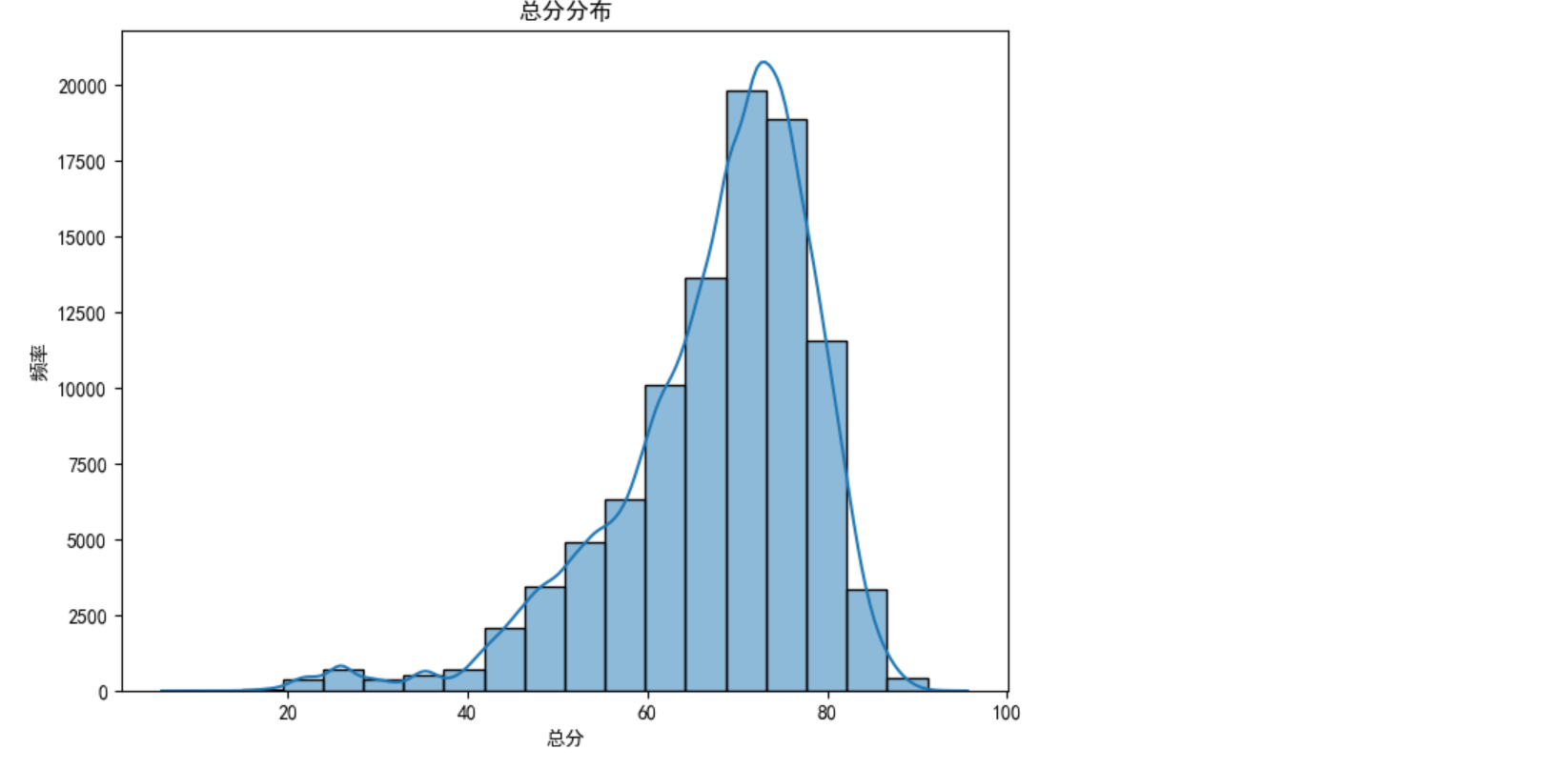
# 找出得分最高和最低的文件
max_score = df.loc[df['总分'].idxmax()]
min_score = df.loc[df['总分'].idxmin()]
print('得分最高的文件:')
print(max_score)
print('得分最低的文件:')
print(min_score)
# 分析特定范围内的文件,比如得分大于70的文件
s = 70
high_score_files = df[df['总分'] > s]
print(f'得分大于{s}的文件数量:', len(high_score_files))
print(high_score_files) 
# 统计各个分数段的比例和数量
bins = [0, 50, 60, 70, 80, 90, 100]
labels = ['0-50', '51-60', '61-70', '70-80', '80-90', '90-100']
df['分数段'] = pd.cut(df['总分'], bins=bins, labels=labels, right=False)
count_series = df['分数段'].value_counts(sort=False)
percentage_series = df['分数段'].value_counts(normalize=True, sort=False) * 100
# 输出统计信息
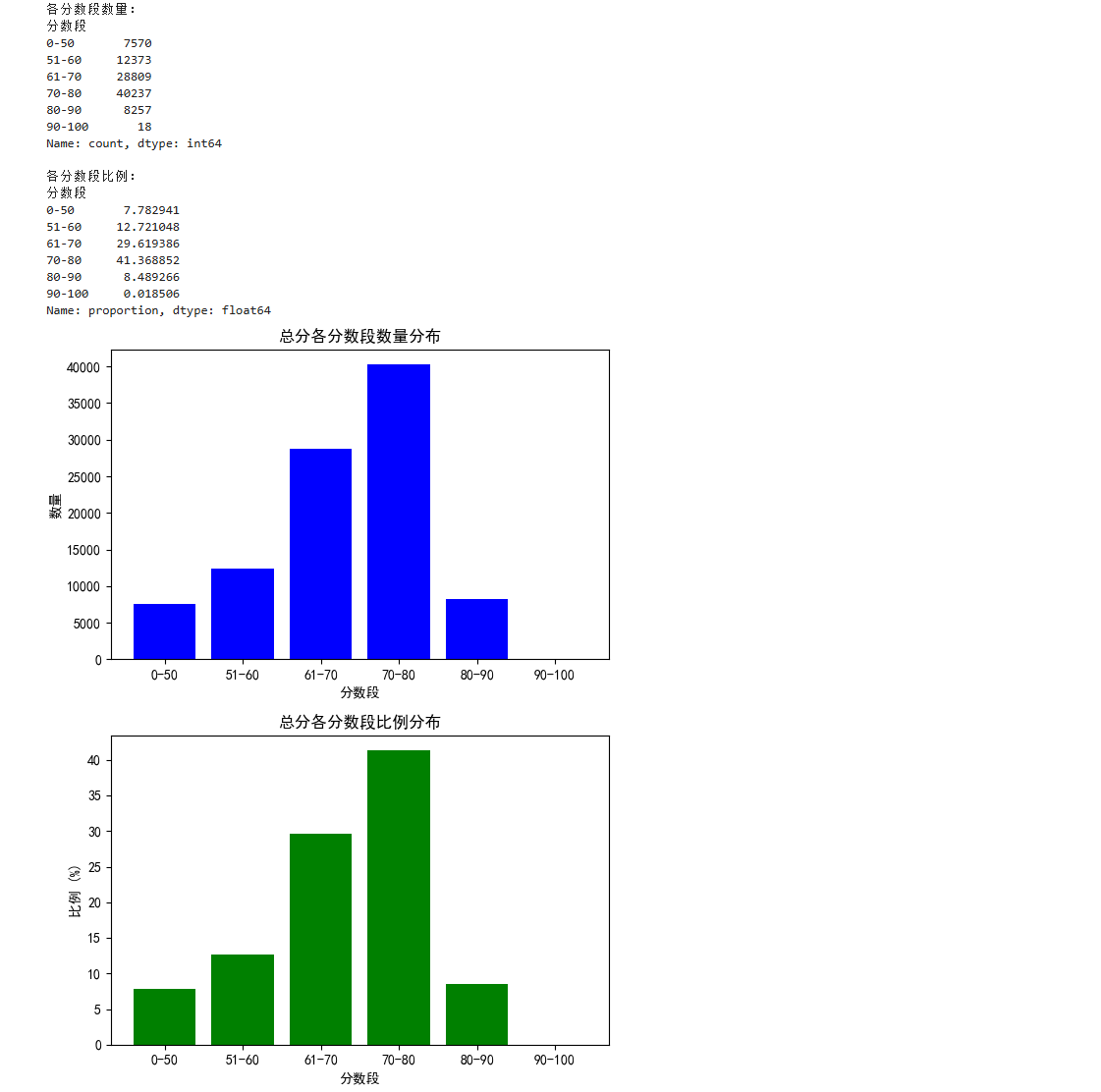
print("各分数段数量:")
print(count_series)
print("\n各分数段比例:")
print(percentage_series)
# 绘制柱状图
fig, ax = plt.subplots(2, 1, figsize=(6, 8))
# 数量分布图
ax[0].bar(count_series.index.astype(str), count_series.values, color='blue')
ax[0].set_title('总分各分数段数量分布')
ax[0].set_xlabel('分数段')
ax[0].set_ylabel('数量')
# 比例分布图
ax[1].bar(percentage_series.index.astype(str), percentage_series.values, color='green')
ax[1].set_title('总分各分数段比例分布')
ax[1].set_xlabel('分数段')
ax[1].set_ylabel('比例 (%)')
# 显示图表
plt.tight_layout()
plt.show() 
# 筛选出80-90分数段的数据
df_80_90 = df[(df['总分'] >= 80)]
# 筛选出71-80分数段的数据
df_70_80 = df[(df['总分'] >= 70)]
# 筛选出61-70分数段的数据,并保留50%
rate1 = 0.3
df_61_70 = df[(df['总分'] >= 61) & (df['总分'] < 70)]
df_61_70_sample = df_61_70.sample(frac=rate1, random_state=42)
# 筛选出51-60分数段的数据,并保留25%
rate2 = 0.25
df_51_60 = df[(df['总分'] >= 51) & (df['总分'] <= 60)]
df_51_60_sample = df_51_60.sample(frac=rate2, random_state=42)
# 筛选出0-50分数段的数据,并保留5%
rate2 = 0.01
df_51_60 = df[(df['总分'] >= 51) & (df['总分'] <= 60)]
df_51_60_sample = df_51_60.sample(frac=rate2, random_state=42)
# 合并筛选后的数据
final_df = pd.concat([df_80_90, df_70_80, df_61_70_sample, df_51_60_sample])
# 重置索引并丢弃旧的索引
final_df.reset_index(drop=True, inplace=True)
final_df.index.name="file_index"
# 将结果保存到新的CSV文件
final_df.to_csv("D:/filtered_file.csv", index=True)
print(len(final_df))根据不同分数段保留不同比例的数据样本。结果保存到 D:/filtered_file.csv 文件中
![]()
5. 为筛选后的文件添加内容字段
import pandas as pd
import os
# 读取 filtered_file.csv
filtered_path = '/root/4-分析和筛选/filtered_file.csv'
data_dir = '/root/all_m_files'
df = pd.read_csv(filtered_path)
def read_file_content(filename):
file_path = os.path.join(data_dir, filename)
if os.path.exists(file_path):
try:
with open(file_path, 'r', encoding='utf-8', errors='ignore') as f:
return f.read()
except Exception as e:
return f'[ERROR: {e}]'
else:
return '[FILE NOT FOUND]'
# 新增 content 字段
df['content'] = df['filename'].apply(read_file_content)
# 保存新文件
df.to_csv('/root/5-通过文件进行筛选/filtered_file_with_content.csv', index=False)
6. 文件内容切分与JSON格式转换
将CSV文件中每个文件的内容切分成多个较小的代码块(chunks),并将结果保存为JSON格式。下
对上一步得到的文件进行切分
import os
import json
import pandas as pd
from tqdm import tqdm
import random
def split_file(lines):
language = "matlab"
total_lines = len(lines)
start = 0
chunks = []
while start + min_lines < total_lines:
# 随机生成小文件的行数,范围是10到30
lines_in_chunk = random.randint(min_lines, max_lines)
end = min(start + lines_in_chunk, total_lines)
chunk = "\n".join(lines[start:end])
chunks.append(chunk)
start = end + window # 设定下一个间隔10行后的起点
return chunks, language
if __name__ == "__main__":
random.seed(415)
# 从CSV文件读取数据
df = pd.read_csv("/root/5-通过文件进行筛选/filtered_file_with_content.csv")
max_lines = 50
min_lines = 20
window = 40
chunk_ids = 0
result = []
for _, row in tqdm(df.iterrows()):
# 假设CSV中有content列,包含文件内容,并按行分割
content = row["content"].splitlines() if isinstance(row["content"], str) else []
chunks, language = split_file(content) # 切分获取case
if chunks and language:
for chunk_content in chunks:
json_record = {
"file_index": row.get("file_index", chunk_ids),
"file_name": row.get("filename", ""),
# "chunk_id":chunk_ids,
"language": language,
"content": chunk_content
}
result.append(json_record)
chunk_ids += 1
with open('/root/6-数据切分/split_result.json', 'w', encoding="utf-8") as outfile:
json.dump(result, outfile, ensure_ascii=False, indent=4)
print(len(df), "个文件切分为:", chunk_ids)
切分后结果保存在新的json文件中
7. 代码块质量评估与重复率计算
import os
import json
from tqdm import tqdm
import random
import re
import pandas as pd
def split_string(s):
# pattern = r'[A-Za-z]+|\d+|[^A-Za-z0-9\s]'
tokens = split_pattern.findall( s)
return tokens
def get_score2(content): # 代码重复率
sp_content = split_string(content)
set_content = set(sp_content)
try:
return round( len(set_content) / len(sp_content) * 100,2)
except:
return 0
if __name__ == "__main__":
split_pattern = re.compile(r'[A-Za-z]+|\d|[^A-Za-z0-9\s]')
with open("/root/6-数据切分/split_result.json",encoding="utf-8") as f:
files_info = json.load(f)
for idx,file in tqdm(enumerate(files_info),total=len(files_info)):
content = file["content"]
score = get_score2(content)
del file["content"]
file["score"] = score
file["content"] = content
files_info[idx] = file
df = pd.DataFrame(files_info)
df.to_csv("/root/7-数据块的质量评测/chunk_scores.csv",index=False)
chunk_scores.csv 文件保存的是经过质量评估后的代码块(chunks)信息,包含每个代码块的元数据和计算得到的质量评分。
文件包含的主要字段
-
file_index
-
原始文件的索引ID,用于追踪代码块来源
-
-
file_name
-
原始文件名,标识代码块来自哪个源文件
-
-
language
-
代码语言类型(当前代码固定为"matlab")
-
-
score
-
核心指标:代码重复率评分(0-100)
-
计算方式:
(唯一token数量 / 总token数量) * 100 -
值越高表示代码重复率越低,独特性越高
-
值越低表示代码重复率越高,可能包含大量重复模式
-
-
-
content
-
代码块的实际内容(20-50行不等的代码片段)
-
数据示例(假设结构)
| file_index | file_name | language | score | content |
|---|---|---|---|---|
| 1 | example1.m | matlab | 78.50 | function y = foo(x)...end |
| 2 | example1.m | matlab | 65.20 | for i=1:10...end |
| 3 | utils.m | matlab | 92.30 | % 独特的功能实现代码... |
8. 代码块筛选
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei'] # 如果系统中安装了 "SimHei" 字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示为方块的问题df = pd.read_csv('D:/chunk_scores.csv')# 统计各个分数段的比例和数量
bins = [0, 2,5,8, 10,15, 20,25, 40,100]
labels = ['0-2', '2-5','5-8', '8-10', '10-15','15-20','20-25','25-40', '40-100']
df['分数段'] = pd.cut(df['score'], bins=bins, labels=labels, right=False)
count_series = df['分数段'].value_counts(sort=False)
percentage_series = df['分数段'].value_counts(normalize=True, sort=False)
# 输出统计信息
print("各分数段数量:")
print(count_series)
print("\n各分数段比例:")
print(percentage_series)
# 绘制柱状图
fig, ax = plt.subplots(2, 1, figsize=(6, 8))
# 数量分布图
ax[0].bar(count_series.index.astype(str), count_series.values, color='blue')
ax[0].set_title('文件总得分各分数段数量分布')
ax[0].set_xlabel('分数段')
ax[0].set_ylabel('数量')
# 比例分布图
ax[1].bar(percentage_series.index.astype(str), percentage_series.values, color='green')
ax[1].set_title('文件总得分各分数段比例分布')
ax[1].set_xlabel('分数段')
ax[1].set_ylabel('比例 (%)')
# 显示图表
plt.tight_layout()
plt.show() 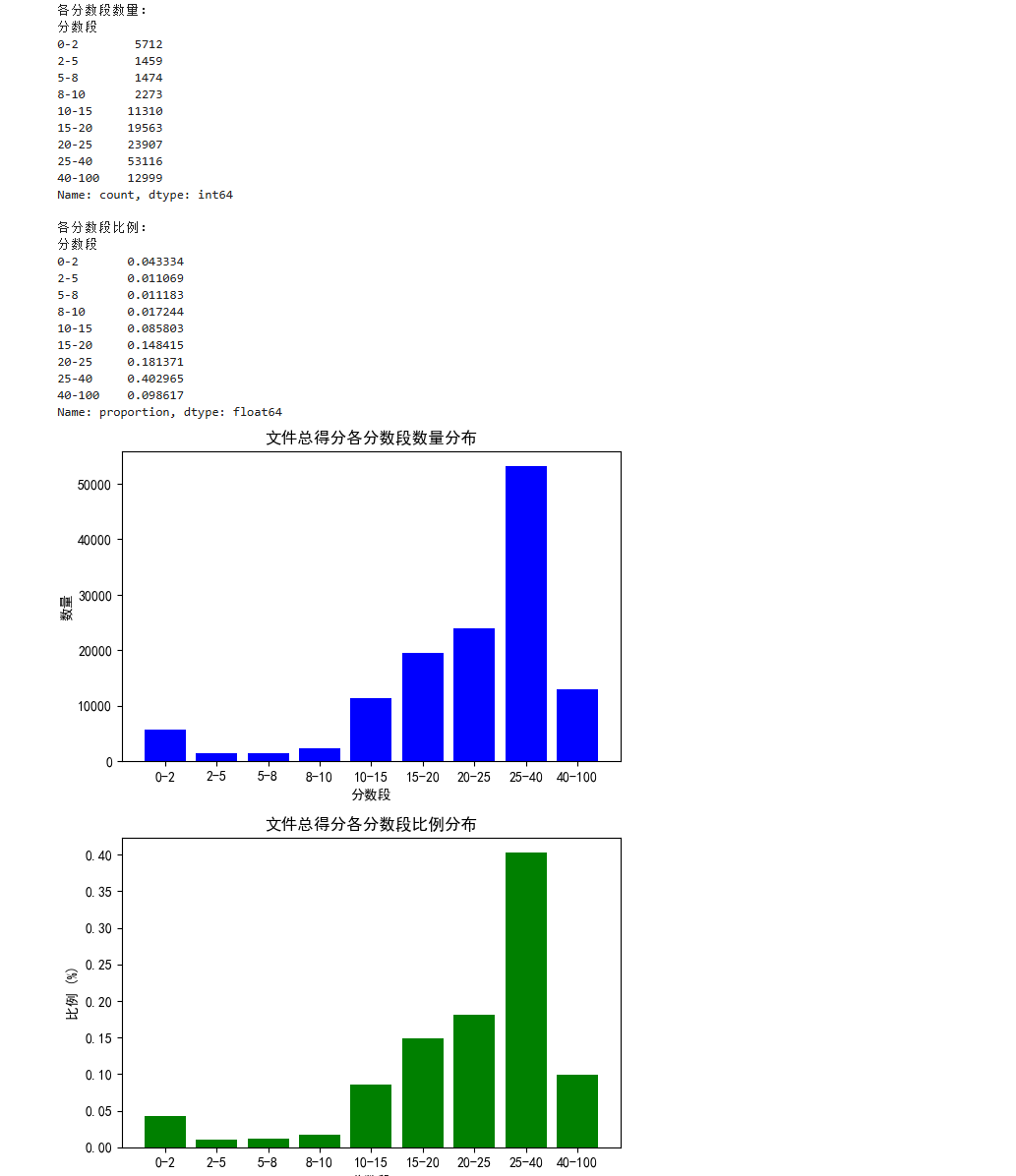
# 筛选出15分数以上的数据
rage0 = 1.0
df_4 = df[(df['score'] >= 40)]
df_4 = df_4.sample(frac=rage0, random_state=42)
# 筛选出10-15分数段的数据,并保留70%
rage1 = 0.9
df_3_4 = df[(df['score'] >= 25) & (df['score'] < 40)]
df_3_4 = df_3_4.sample(frac=rage1, random_state=42)
# 筛选出8-10分数段的数据,并保留60%
rate2 = 0.8
df_2_3 = df[(df['score'] >=20) & (df['score'] < 25)]
df_2_3 = df_2_3.sample(frac=rate2, random_state=42)
# 筛选出5-8分数段的数据,并保留30%
rate3 = 0.5
df_1_2 = df[(df['score'] >= 15) & (df['score'] < 20)]
df_1_2 = df_1_2.sample(frac=rate3, random_state=42)
# 筛选出1-15分数段的数据,并保留30%
rate4 = 0.1
df_0_1 = df[(df['score'] >= 1) & (df['score'] < 15)]
df_0_1 = df_0_1.sample(frac=rate4, random_state=42)
# 合并筛选后的数据
final_df = pd.concat([df_4, df_3_4, df_2_3,df_1_2,df_0_1])
del final_df["分数段"]
final_df["chunk_id"] = [i for i in range(len(final_df))]
columns = ['chunk_id'] + [col for col in final_df.columns if col != 'chunk_id']
final_df = final_df[columns]
# final_df.index.name = 'chunk_id'
# # # 将结果保存到新的CSV文件
# # final_df.to_csv("chunk_scores_result.csv", index=True)
final_df.to_json("D:/chunk_scores_result.json", orient="records", indent=4, force_ascii=False)
print( len(df), "---->" ,len(final_df))![]()
9. 训练集和测试集数据制作
确保在上一文件夹目录下有待处理的json文件
安装 tree_sitter_languages 包
pip install tree_sitter_languagesimport os
import fire
import glob
import gzip
import random
import concurrent.futures
from typing import *
from tqdm.auto import tqdm
from infilling import InFilling
import json
from tqdm import tqdm
from transformers import AutoTokenizer
def stream_jsonl(filename: str):
"""
Parses each jsonl line and yields it as a dictionary
"""
if filename.endswith(".gz"):
with open(filename, "rb") as gzfp:
with gzip.open(gzfp, "rt") as fp:
for line in fp:
# if any(not x.isspace() for x in line):
yield json.loads(line)
else:
with open(filename, "r",encoding="utf-8") as fp:
datas = json.load(fp)
print(len(datas))
try :
for data in datas:
yield data
except:
yield None
def choose_mode(modes, weights):
return random.choices(modes, weights, k=1)[0]
def get_all_file_paths(directory):
file_paths = [] # List to store file paths
for root, directories, files in os.walk(directory):
for filename in files:
# Join the two strings to form the full filepath.
filepath = os.path.join(root, filename)
if filepath.endswith(".json"):
file_paths.append(filepath) # Add it to the list.
return file_paths
def process(obj):
chosen_mode = choose_mode(modes, weights)
results = InFilling(obj['content'], obj['language'], chosen_mode,times[chosen_mode])
if len(results) == 0:
return []
contents = []
for prefix,middle,suffix in results:
# print(chosen_mode)
content = {
"chunk_id":obj["chunk_id"],
"file_index":obj["file_index"],
"file_name":obj["file_name"],
"score":obj["score"],
"language": obj['language'],
"prefix": prefix,
"middle": middle,
"suffix": suffix,
"mode":chosen_mode
}
contents.append(content)
return contents
def process_file(file_path):
global split_dir, strategy
print(f"Processing {file_path}")
name = os.path.basename(file_path)
save_name = os.path.join(split_dir, f"{name}")
with open(save_name, "w",encoding="utf-8") as f_out:
data = stream_jsonl(file_path)
for d in data:
if d:
# result = json.dumps( process(d),ensure_ascii=False)
results = process(d)
if len(results) != 0:
for result in results:
result = json.dumps(result,ensure_ascii=False)
f_out.write(result + "\n")
def main(num_workers: int = 1):
global data_dir,split_dir,strategy
data_list = get_all_file_paths(data_dir)
print(data_list)
with concurrent.futures.ThreadPoolExecutor(max_workers=num_workers) as executor:
# 使用list comprehension来启动每个线程并获取结果
results = [result for result in executor.map(process_file, data_list)] # data_list每个元素做process_file
def split_train_test():
train_file = "/root/9-训练集和测试集数据制作/train.json"
test_file = "/root/9-训练集和测试集数据制作/test.json"
if not os.path.exists(result_dir):
os.makedirs(result_dir)
files = os.listdir(split_dir)
tokenizer = AutoTokenizer.from_pretrained("/root/9-训练集和测试集数据制作/tokenizer_file", trust_remote_code=True)
all_data = []
for split_file in files:
split_file = os.path.join(split_dir, split_file)
with open(split_file, encoding="utf-8") as f:
all_data += f.readlines()
random.shuffle(all_data)
new_data = []
for data in tqdm(all_data[:]):
# if len(data)<200:
# continue
data = json.loads(data)
prefix = data["prefix"]
middle = data["middle"]
suffix = data["suffix"]
t1, t2, t3 = tokenizer.batch_encode_plus([prefix, middle, suffix], add_special_tokens=False)["input_ids"]
l1, l2, l3 = len(t1), len(t2), len(t3)
i = 0
while len(t1) + len(t2) + len(t3) > 1000: # 2048+512
if i >= 10:
i = -999
break
if len(t3) >= len(t1):
t3 = t3[: len(t3) // 2]
else:
t1 = t1[len(t1) //2 :]
i += 1
if i == -999:
continue
if len(t1) != l1:
data["prefix"] = tokenizer.decode(t1)
if len(t3) != l3:
data["suffix"] = tokenizer.decode(t3)
data["prefix"] = data["prefix"].strip("\n")
data["suffix"] = data["suffix"].strip("\n")
data["middle"] = data["middle"].strip("\n")
# print(data["middle"])
# print("*"*100)
new_data.append(data)
# if len(new_data)>1000:
# break
test_data = new_data[:int(len(new_data) * test_rate)]
train_data = new_data[int(len(new_data) * test_rate):]
with open(os.path.join(result_dir,train_file), "w", encoding="utf-8") as f1:
json.dump(train_data,f1,ensure_ascii=False,indent=4)
with open(os.path.join(result_dir,test_file), "w", encoding="utf-8") as f2:
json.dump(test_data,f2,ensure_ascii=False,indent=4)
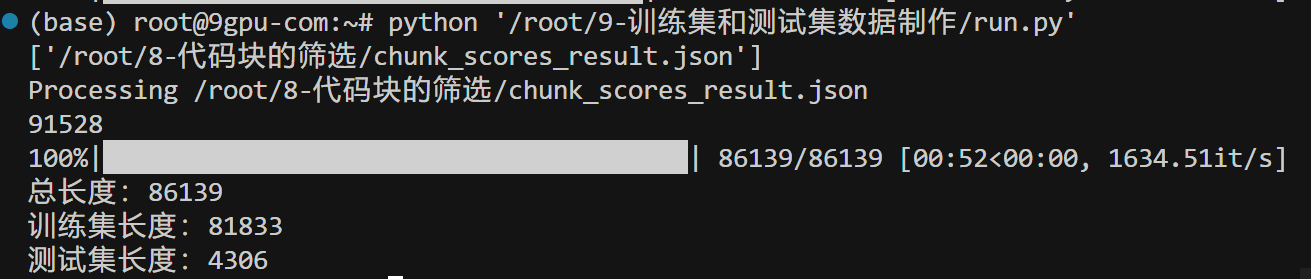
print(f"总长度:{len(all_data)}")
print(f"训练集长度:{len(train_data)}")
print(f"测试集长度:{len(test_data)}")
get_sameples()
def get_sameples():
f2 = open(os.path.join(result_dir,"samples.txt"), "w", encoding="utf-8")
with open(os.path.join(result_dir, "train.json"), "r", encoding="utf-8") as f:
all_data = json.loads(f.read())
for data in all_data[:200]:
f2.write("*" * 200 + "\n")
# data = eval(data)
f2.write("*" * 30 + "prefix:" + "*" * 30 + "\n")
f2.write(data["prefix"] + "\n")
f2.write("*" * 30 + "middle:" + str(len(data["middle"])) + f" mode:{data['mode']}" + "*" * 30 + '\n')
f2.write(data["middle"] + "\n")
f2.write("*" * 30 + "suffix:" + "*" * 30 + "\n")
f2.write(data["suffix"] + '\n')
f2.close()
if __name__ == "__main__":
data_dir = "/root/8-代码块的筛选"
split_dir = "/root/9-训练集和测试集数据制作/split_temp"
strategy = 0
result_dir = "/root/9-训练集和测试集数据制作/split_result"
if os.path.exists(result_dir) == False:
os.mkdir(result_dir)
test_rate = 0.05
random.seed(824)
if not os.path.exists(split_dir):
os.makedirs(split_dir)
modes = [0,1,2,3,4,5,6]
times = [1, 1, 1, 1, 1, 1,0]
if strategy == 0:
weights = [1, 0, 1, 1, 1, 1,0]
fire.Fire(main)
else:
all_weights = [
[1, 0, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0],
[0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 1]
]
for i in range(len(modes)):
weights = all_weights[i]
fire.Fire(main)
split_train_test()
# modes 提供切分的模式,无需修改
# weights 每种模式的权重
# times 选中每种模式,生成的样例数量
# mode0 : 简单的按照长度切分,有可能切开某一个单词
# mode1 : 按照函数块、循环块切分
# mode2 : 按照单行切分
# mode3 : 按照括号切分
# mode4 : 按照多行切分
# mode5 : 没有suffix的切分
# mode6 : 没有prefix
10. 格式微调及转换
# prompt = '<|fim_prefix|>' + prefix_code + '<|fim_suffix|>' + suffix_code + '<|fim_middle|>'
import json
def trans_data(path,save_path):
with open(path,encoding="utf-8") as f:
data = json.load(f)
result = []
for d in data:
prefix_code = d["prefix"]
suffix_code = d["suffix"]
middle_code = d["middle"]
prompt = '<|fim_prefix|>' + prefix_code + '<|fim_suffix|>' + suffix_code + '<|fim_middle|>'
result.append({"instruction": prompt,
"input": "",
"output": middle_code,
"chunk_id": d["chunk_id"],
"file_index": d["file_index"],
"file_name": d["file_name"],
"score": d["score"],
"mode": d["mode"],
})
with open(save_path,"w",encoding="utf-8")as f:
f.write(json.dumps(result,indent=4,ensure_ascii=False))
trans_data("/root/9-训练集和测试集数据制作/split_result/train.json","code_train.json")
trans_data("/root/9-训练集和测试集数据制作/split_result/test.json","code_test.json")
# trans_data("label.json","label2.json")