- 把前面所设计好的搜索引擎引用进来开发一个简单的具体的视频搜索业务。
- 代码结构:
- handler目录:后端接口,负责接收请求并返回结果,不存在具体的搜索逻辑。
- video_search目录:具体的搜索逻辑存放在这,包括recaller召回(根据关键词或作者条件搜出一些候选集)和过滤(业务侧进行一些更加精细的过滤,如根据视频播放量区间)步骤。
- main:创建gin engine。
- test:一些单元测试。
- views:前端相关的HTML、CSS和JavaScript文件。
- video.proto文件:视频实体的定义,包括视频ID、title、publish_time、author、playback、like、coin、collection、share、tags等属性。
- model.go文件:基础的类的定义,搜索请求的定义,前端浏览器将参数传递给后端。
- build_index.go:读取原始CSV文件并构建索引,使用单机模式。
- 打开CSV文件并使用csv.NewReader解析文件内容。
- 读取每行数据,包括video_id、publish_time、author、title、playback、like、coin、collection、share等字段。
- 构造video结构体,并序列化为protobuf格式。
- 将document添加到正排索引和倒排索引中。
package demo
import (
"encoding/csv"
"github.com/gogo/protobuf/proto"
indexer "github.com/jmh000527/criker-search/index_service"
"github.com/jmh000527/criker-search/types"
"github.com/jmh000527/criker-search/utils"
farmhash "github.com/leemcloughlin/gofarmhash"
"io"
"os"
"strconv"
"strings"
"time"
)
// BuildIndexFromFile 将CSV文件中的视频信息写入索引。
//
// 参数:
// - csvFile: CSV文件的路径。
// - indexer: 索引接口,用于添加文档到索引中。
// - totalWorkers: 分布式环境中的总worker数量。如果是单机模式,设为0。
// - workerIndex: 当前worker的索引,从0开始编号。单机模式下不使用此参数。
//
// 返回值: 无返回值
// 注意事项: 如果使用分布式模式,每个worker只处理一部分数据。
func BuildIndexFromFile(csvFile string, indexer indexer.Indexer, totalWorkers, workerIndex int) {
file, err := os.Open(csvFile)
if err != nil {
utils.Log.Printf("打开CSV文件 %v 失败,错误: %v", csvFile, err)
return
}
defer file.Close()
location, _ := time.LoadLocation("Asia/Shanghai")
reader := csv.NewReader(file)
progress := 0
for {
// 读取CSV文件的一行
record, err := reader.Read()
if err != nil {
if err != io.EOF {
utils.Log.Printf("无法读取CSV文件: %v", err)
}
break
}
// 如果记录的字段少于10个,跳过该行
if len(record) < 10 {
continue
}
// 获取视频ID(业务侧ID)
docId := strings.TrimPrefix(record[0], "https://www.bilibili.com/video/")
// 在分布式模式下,每个worker只处理特定的视频数据
if totalWorkers > 0 && int(farmhash.Hash32WithSeed([]byte(docId), 0))%totalWorkers != workerIndex {
continue
}
// 构建BiliVideo实体
video := &BiliVideo{
Id: strings.TrimPrefix(record[0], "https://www.bilibili.com/video/"),
Title: record[1],
Author: record[3],
}
// 解析发布日期
if len(record[2]) > 4 {
t, err := time.ParseInLocation("2006/1/2 15:4", record[2], location)
if err != nil {
utils.Log.Printf("解析时间 %s 失败: %s", record[2], err)
} else {
video.PostTime = t.Unix()
}
}
// 解析视频的其他属性
n, _ := strconv.Atoi(record[4])
video.View = int32(n)
n, _ = strconv.Atoi(record[5])
video.Like = int32(n)
n, _ = strconv.Atoi(record[6])
video.Coin = int32(n)
n, _ = strconv.Atoi(record[7])
video.Favorite = int32(n)
n, _ = strconv.Atoi(record[8])
video.Share = int32(n)
// 解析关键字
keywords := strings.Split(record[9], ",")
if len(keywords) > 0 {
for _, word := range keywords {
word = strings.TrimSpace(word)
if len(word) > 0 {
video.Keywords = append(video.Keywords, strings.ToLower(word))
}
}
}
// 将视频信息添加到索引中
AddVideo2Index(video, indexer)
progress++
// 每处理100条记录,输出进度
if progress%100 == 0 {
utils.Log.Printf("索引进度: %d\n", progress)
}
}
utils.Log.Printf("索引构建完成,共添加了 %d 个文档", progress)
}
// AddVideo2Index 将视频信息添加或更新至索引。
//
// 参数:
// - video: 包含视频信息的BiliVideo对象。
// - indexer: 实现了IIndexer接口的索引器实例。
func AddVideo2Index(video *BiliVideo, indexer indexer.Indexer) {
// 构建Document对象,将视频ID赋值给文档ID
doc := types.Document{
Id: video.Id,
}
// 将BiliVideo对象序列化为字节数组
docBytes, err := proto.Marshal(video)
if err != nil {
utils.Log.Printf("序列化视频信息失败: %v", err)
return
}
doc.Bytes = docBytes
// 构建关键词列表
keywords := make([]*types.Keyword, 0, len(video.Keywords))
// 遍历视频关键词,将每个关键词添加到关键词列表中
for _, word := range video.Keywords {
keywords = append(keywords, &types.Keyword{
Field: "content",
Word: strings.ToLower(word),
})
}
if len(video.Author) > 0 {
keywords = append(keywords, &types.Keyword{
Field: "author",
Word: strings.ToLower(strings.TrimSpace(video.Author)),
})
}
doc.Keywords = keywords
// 计算视频的特征位
doc.BitsFeature = GetClassBits(video.Keywords)
// 将文档添加或更新到索引中
_, err = indexer.AddDoc(doc)
if err != nil {
utils.Log.Printf("无法添加文档, 错误: %v", err)
}
}

- proto.Marshal(video) 是将结构体 video 序列化为紧凑的 Protobuf 二进制格式,以存入搜索引擎的索引系统中。在高性能系统中,Protobuf 比 JSON 更节省空间、速度更快,能很好支持文档的持久化、传输和反序列化,是搜索系统常用的文档表示方式之一。
- 根据视频关键词生成bitset特征,用于视频类别的编码。
- 定义枚举类型表示不同的类别,如资讯、编程、科技等。
- 通过位运算将视频类别编码到bitset中。
- 可以将其他属性如是否付费、是否为新视频等也编码到bitset中。
package demo
import "golang.org/x/exp/slices"
// 视频类别枚举
const (
ZiXun = 1 << iota // 1 << 0
SheHui // 1 << 1
ReDian // 1 << 2
ShengHuo // 1 << 3
ZhiShi
HuanQiu
YouXi
ZongHe
RiChang
YingShi
DongHua
KeJi
YuLe
BianCheng
)
// GetClassBits 从Keywords中提取类型,用bits表示类别
func GetClassBits(keywords []string) uint64 {
var bits uint64
if slices.Contains(keywords, "资讯") {
bits |= ZiXun //属于哪个类别,就把对应的bit置为1。可能属于多个类别
}
if slices.Contains(keywords, "社会") {
bits |= SheHui
}
if slices.Contains(keywords, "热点") {
bits |= ReDian
}
if slices.Contains(keywords, "生活") {
bits |= ShengHuo
}
if slices.Contains(keywords, "知识") {
bits |= ZhiShi
}
if slices.Contains(keywords, "环球") {
bits |= HuanQiu
}
if slices.Contains(keywords, "游戏") {
bits |= YouXi
}
if slices.Contains(keywords, "综合") {
bits |= ZongHe
}
if slices.Contains(keywords, "日常") {
bits |= RiChang
}
if slices.Contains(keywords, "影视") {
bits |= YingShi
}
if slices.Contains(keywords, "科技") {
bits |= KeJi
}
if slices.Contains(keywords, "编程") {
bits |= BianCheng
}
return bits
}
- 项目目标是从CSV文件中导入原始数据到MySQL数据库。
- 实际情况下,公司数据存储在MySQL数据库中。
- 需要遍历大型MySQL表以插入数据。
show databases;
create database search;
create user 'tester' identified by '123456';
grant all on search.* to tester;
use search;
create table if not exists bili_video
(
id char(12) comment 'bili视频ID',
title varchar(250) not null comment '视频标题',
author varchar(60) not null comment '视频作者',
post_time datetime not null comment '视频发布时间',
keywords varchar(200) not null comment '标签关键词',
view int not null default 0 comment '播放量',
thumbs_up int not null default 0 comment '点赞量',
coin int not null default 0 comment '投币',
favorite int not null default 0 comment '收藏',
share int not null default 0 comment '分享',
primary key (id)
) default charset = utf8mb4 comment '抓取的bili视频信息';
- 创建MySQL数据库和表,表结构包括定长ID和其他字段。
- ID字段为主键,未建立索引,以简化数据导入过程。
- 为表添加注释,以便他人理解字段含义。
package sql
import (
"encoding/csv"
"errors"
"fmt"
"io"
"log"
"os"
"strconv"
"strings"
"time"
"github.com/go-sql-driver/mysql"
)
var loc *time.Location
const BatchSize = 300
// 适合使用init()的典型场景:全局变量的初始化放到init()里,且没有任何前提依赖
// 为什么不直接赋值呢?因为函数有两个返回值!
func init() {
var err error
loc, err = time.LoadLocation("Asia/Shanghai")
if err != nil {
panic(err)
}
}
type BiliVideo struct {
Id string //结构体里的驼峰转为蛇形,即mysql表里的列名
Title string
Author string
PostTime time.Time
Keywords string
View int
ThumbsUp int
Coin int
Favorite int
Share int
}
func (BiliVideo) TableName() string {
return "bili_video" // 指定表名
}
func parseFileLine(record []string) *BiliVideo {
video := &BiliVideo{
Title: record[1],
Author: record[3],
}
urlPaths := strings.Split(record[0], "/")
video.Id = urlPaths[len(urlPaths)-1]
if len(record[2]) > 4 {
t, err := time.ParseInLocation("2006/1/2 15:4", record[2], loc)
if err != nil {
log.Printf("parse time %s failed: %s", record[2], err)
} else {
video.PostTime = t
}
}
n, _ := strconv.Atoi(record[4])
video.View = n
n, _ = strconv.Atoi(record[5])
video.ThumbsUp = n
n, _ = strconv.Atoi(record[6])
video.Coin = n
n, _ = strconv.Atoi(record[7])
video.Favorite = n
n, _ = strconv.Atoi(record[8])
video.Share = n
video.Keywords = strings.ToLower(record[9]) // 转小写
return video
}
func readFile(csvFile string, ch chan<- *BiliVideo) {
file, err := os.Open(csvFile)
if err != nil {
log.Printf("open file %s failed: %s", csvFile, err)
return
}
defer file.Close()
reader := csv.NewReader(file) // 读取CSV文件
for {
record, err := reader.Read() // 读取CSV文件的一行,record是个切片
if err != nil {
if err != io.EOF {
log.Printf("read record failed: %s", err)
}
break
}
if len(record) < 10 { // 避免数组越界,发生panic
continue
}
video := parseFileLine(record)
ch <- video
}
close(ch) // 生产方结束后,一定要close channel
}
// DumpDataFromFile2DB1 逐行读取CSV文件,并逐条插入数据库,没有使用事务或批处理
func DumpDataFromFile2DB1(csvFile string) {
begin := time.Now()
defer func(begin time.Time) {
fmt.Printf("DumpDataFromFile2DB1 use time %d ms\n", time.Since(begin).Milliseconds())
}(begin)
ch := make(chan *BiliVideo, 200)
go readFile(csvFile, ch)
db := GetSearchDBConnection()
for {
video, ok := <-ch
if !ok {
break
}
err := db.Create(video).Error
checkErr(err)
}
}
// DumpDataFromFile2DB2 使用事务来批量插入数据,每插入BatchSize条数据就提交一次事务
func DumpDataFromFile2DB2(csvFile string) {
begin := time.Now()
defer func(begin time.Time) {
fmt.Printf("DumpDataFromFile2DB2 use time %d ms\n", time.Since(begin).Milliseconds())
}(begin)
ch := make(chan *BiliVideo, 200)
go readFile(csvFile, ch)
db := GetSearchDBConnection()
tx := db.Begin()
i := 0
for {
video, ok := <-ch
if !ok {
break
}
tx.Create(video) // 通过事务提交insert请求
i++
if i >= BatchSize {
err := tx.Commit().Error // 300次insert提交一次事务
checkErr(err)
tx = db.Begin() // 不能在一个事务上重复commit,需要新开一个事务
i = 0
}
}
err := tx.Commit().Error
checkErr(err)
}
// DumpDataFromFile2DB3 使用gorm提供的CreateInBatches进行批量插入,这通常比手动管理事务更高效。
func DumpDataFromFile2DB3(csvFile string) {
begin := time.Now()
defer func(begin time.Time) {
fmt.Printf("DumpDataFromFile2DB3 use time %d ms\n", time.Since(begin).Milliseconds())
}(begin)
ch := make(chan *BiliVideo, 200)
go readFile(csvFile, ch)
db := GetSearchDBConnection()
buffer := make([]*BiliVideo, 0, BatchSize)
for {
video, ok := <-ch
if !ok {
break
}
buffer = append(buffer, video)
if len(buffer) >= BatchSize {
err := db.CreateInBatches(buffer, BatchSize).Error // 300条数据批量insert
checkErr(err)
buffer = make([]*BiliVideo, 0, BatchSize)
}
}
err := db.CreateInBatches(buffer, BatchSize).Error
checkErr(err)
}
func checkErr(err error) {
// et := reflect.TypeOf(err).Elem()
// fmt.Println(et, et.PkgPath(), et.Name())
var sqlErr *mysql.MySQLError
if errors.As(err, &sqlErr) {
if sqlErr.Number != 1062 {
panic(err)
}
}
}
// ch chan<- BiliVideo
// 函数 ReadAllTable1 接收一个通道参数 ch,你只能往这个通道里发 BiliVideo 类型的值,不能从中读取。
// 这是一种权限控制(channel direction constraint),常用于并发编程中避免误用。
// ReadAllTable1 一条最简单的select读出全表
func ReadAllTable1(ch chan<- BiliVideo) {
begin := time.Now()
defer func(begin time.Time) {
fmt.Printf("ReadAllTable1 use time %d ms\n", time.Since(begin).Milliseconds())
}(begin)
db := GetSearchDBConnection()
var data []BiliVideo
// select * from bili_video; 绝对禁止这种写法,绝对是慢查询
if err := db.Select("*").Find(&data).Error; err != nil {
log.Printf("ReadAllTable1 failed: %s", err)
}
for _, data := range data {
ch <- data
}
log.Printf("ReadAllTable1 read %d records", len(data))
close(ch)
}
// ReadAllTable2 普通的分页查询遍历全表
func ReadAllTable2(ch chan<- BiliVideo) {
begin := time.Now()
defer func(begin time.Time) {
fmt.Printf("ReadAllTable2 use time %d ms\n", time.Since(begin).Milliseconds())
}(begin)
db := GetSearchDBConnection()
offset := 0
const BATCH = 500
for {
t0 := time.Now()
var data []BiliVideo
// select * from bili_video limit offset,BATCH; 实际上执行的是 limit 0,offset+BATCH, 然后截取了最后BATCH个,所以offset越大执行得越慢
if err := db.Select("*").Offset(offset).Limit(BATCH).Find(&data).Error; err != nil {
log.Printf("ReadAllTable2 failed: %s", err)
break
} else {
if len(data) == 0 {
break
}
for _, data := range data {
ch <- data
}
offset += len(data)
}
fmt.Printf("offset=%d use time %dms\n", offset, time.Since(t0).Milliseconds())
}
log.Printf("ReadAllTable2 read %d records", offset)
close(ch)
}
// ReadAllTable3 借助于主键的有序性,分区段遍历全表
func ReadAllTable3(ch chan<- BiliVideo) {
begin := time.Now()
defer func(begin time.Time) {
fmt.Printf("ReadAllTable3 use time %d ms\n", time.Since(begin).Milliseconds())
}(begin)
db := GetSearchDBConnection()
maxid := ""
const BATCH = 500
total := 0
for {
t0 := time.Now()
var data []BiliVideo
// select * from bili_video where id > maxid limit BATCH; 默认自带 order by id
if err := db.Select("*").Where("id>?", maxid).Limit(BATCH).Find(&data).Error; err != nil {
log.Printf("ReadAllTable2 failed: %s", err)
break
} else {
if len(data) == 0 {
break
}
for _, data := range data {
ch <- data
}
maxid = data[len(data)-1].Id //最后一个元素的id是最大的
total += len(data)
}
fmt.Printf("progress=%d use time %dms\n", total, time.Since(t0).Milliseconds())
}
log.Printf("ReadAllTable3 read %d records", total)
close(ch)
}
- 使用Go语言和csv库读取CSV文件。
- 将CSV文件中的每一行转换为结构体,以匹配MySQL表结构。
- 将读取的结构体数据放入channel中,以节省内存。
-
数据库写入策略:
- 方案一:逐条写入MySQL数据库,性能较低。
- 方案二:使用事务批量写入,提高写入效率。
- 方案三:使用批量创建函数(create in batches),相当于一条sql语句直接插入了多条记录,最快的数据写入方式。
-
测试三种写入方式的耗时,对比性能差异。
-
方案三(批量创建)最快,耗时仅3300毫秒。
-
忽略重复记录错误,确保数据导入的准确性。
-
介绍了三种遍历MySQL表的方法,包括将数据全部读出、分批读取和利用主键有序排列进行读取。
- 第一种方法:将整个表的数据全部读出,速度快但可能引发慢查询问题,不被数据库推荐。
- 第二种方法:通过limit和offset分批读取数据,但存在耗时逐渐增加的问题。
- 第三种方法:利用主键有序排列的特性,每次查询时限制ID大于上一次查询的最大ID,提高效率。
-
通过limit和offset分批读取数据时,耗时会逐渐增加,因为随着offset的增加,需要读取的行数越来越多。
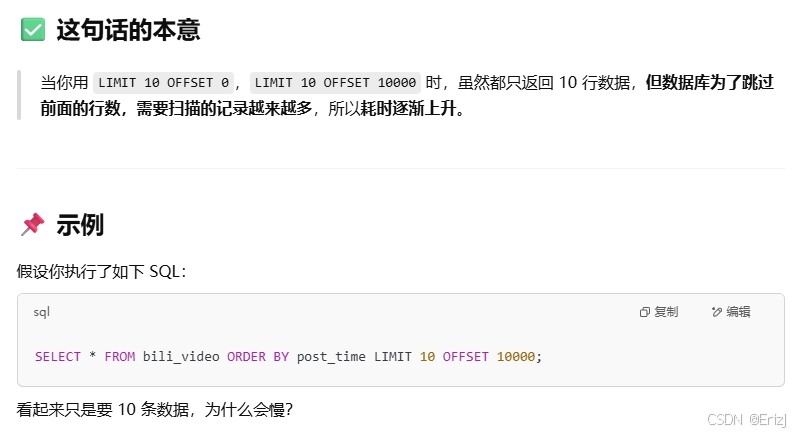

- 为了解决这个问题,可以采用固定offset为0,每次查询时限制ID大于上一次查询的最大ID的方式,这样每一次查询的offset都是0,避免耗时增加。
- 这种方式是非常可行的,而且是高性能分页的标准做法之一,尤其适用于 自增主键或唯一递增字段(如ID、时间戳) 的场景。
- 这种优化方法利用了主键有序排列的特性,确保每次查询都能快速获取数据。

- 为什么游标(游标是数据库中用来记录“当前读取进度”的一个指针)分页更快?
- id 是主键或有索引 → 数据库可快速定位位置(利用 B+ 树)。
- 不需要丢弃前面数据 → 扫描成本是 O(页大小),比如 100。
- 支持大数据量分页,哪怕你已经翻到了第 10 万页,也一样快。
package main
import (
"flag"
"github.com/jmh000527/criker-search/demo/handler"
"github.com/jmh000527/criker-search/index/kv_db"
"net/http"
"strconv"
"github.com/gin-gonic/gin"
"github.com/jmh000527/criker-search/utils"
)
var (
mode = flag.Int("mode", 1, "启动哪类服务。1-standalone web server, 2-grpc index server, 3-distributed web server")
rebuildIndex = flag.Bool("index", false, "server启动时是否需要重建索引")
port = flag.Int("port", 0, "server的工作端口")
dbPath = flag.String("dbPath", "", "正排索引数据的存放路径")
totalWorkers = flag.Int("totalWorkers", 0, "分布式环境中一共有几台index worker")
workerIndex = flag.Int("workerIndex", 0, "本机是第几台index worker(从0开始编号)")
)
var (
dbType = kv_db.BOLT // 正排索引使用哪种KV数据库
csvFile = utils.RootPath + "demo/data/bili_video.csv" // 原始的数据文件,由它来创建索引
etcdServers = []string{"127.0.0.1:2379"} // etcd集群的地址
)
// StartGin 启动 Gin Web 服务器
func StartGin() {
// 创建默认的 Gin 引擎
engine := gin.Default()
// 设置 Gin 运行模式为 Release 模式
gin.SetMode(gin.ReleaseMode)
// 设置静态文件路径
engine.Static("/js", "demo/views/js")
engine.Static("/css", "demo/views/css")
engine.Static("/img", "demo/views/img")
// 加载 HTML 文件
engine.LoadHTMLFiles("demo/views/search.html", "demo/views/up_search.html")
// 使用全局中间件
engine.Use(handler.GetUserInfo)
// 定义视频分类数组
// [...]string 是一种数组的简写声明方式,这个 [...] 的意思是:编译器自动根据初始化元素的个数推断数组的长度。
// [...]string{} 声明的是 数组(长度固定,值复制传递)。
// []string{} 声明的是 切片(长度可变,引用类型)。
classes := [...]string{
"资讯", "社会", "热点", "生活", "知识", "环球", "游戏", "综合", "日常", "影视", "科技", "编程",
}
// 设置路由和处理函数
engine.GET("/", func(ctx *gin.Context) {
ctx.HTML(http.StatusOK, "search.html", classes)
})
engine.GET("/up", func(ctx *gin.Context) {
ctx.HTML(http.StatusOK, "up_search.html", classes)
})
// 设置 POST 请求路由
engine.POST("/search", handler.SearchAll)
engine.POST("/up_search", handler.SearchByAuthor)
// 启动服务器,监听指定端口
engine.Run("127.0.0.1:" + strconv.Itoa(*port))
}
// main 程序入口函数
func main() {
flag.Parse()
switch *mode {
case 1, 3:
// 1:单机模式,索引功能嵌套在 Web 服务器内部。
// 3:分布式模式,Web 服务器内持有一个哨兵,通过哨兵访问各个 gRPC Index 服务器。
WebServerMain(*mode)
StartGin()
case 2:
// 2:以 gRPC 服务器的方式启动索引服务 IndexWorker
GrpcIndexerMain()
}
}
// go run ./demo/main -mode=1 -index=true -port=5678 -dbPath=data/local_db/video_bolt
// go run ./demo/main -mode=2 -index=true -port=5600 -dbPath=data/local_db/video_bolt -totalWorkers=2 -workerIndex=0
// go run ./demo/main -mode=2 -index=true -port=5601 -dbPath=data/local_db/video_bolt -totalWorkers=2 -workerIndex=1
// go run ./demo/main -mode=3 -index=true -port=5678
package main
import (
"github.com/jmh000527/criker-search/index_service"
"os"
"os/signal"
"syscall"
"github.com/jmh000527/criker-search/demo"
"github.com/jmh000527/criker-search/demo/handler"
)
// WebServerInit 初始化 Web 服务器,根据传入的模式选择不同的索引初始化方式
//
// mode: 初始化模式,1 表示单机索引,3 表示分布式索引
func WebServerInit(mode int) {
switch mode {
case 1:
// 模式 1:单机索引
// 创建一个新的索引器实例
standaloneIndexer := new(index_service.LocalIndexer)
// 初始化索引,参数为估计的文档数量,数据库类型,和数据库路径
if err := standaloneIndexer.Init(50000, dbType, *dbPath); err != nil {
// 初始化失败,终止程序并报告错误
panic(err)
}
if *rebuildIndex {
// 如果指定重建索引,从 CSV 文件重建索引
demo.BuildIndexFromFile(csvFile, standaloneIndexer, 0, 0)
} else {
// 否则从正排索引文件加载索引
standaloneIndexer.LoadFromIndexFile()
}
// 将索引器实例分配给处理程序,以便处理请求时使用
handler.Indexer = standaloneIndexer
case 3:
// 模式 3:分布式索引
// 创建一个新的 Sentinel 实例作为分布式索引器
handler.Indexer = index_service.NewSentinel(etcdServers)
default:
// 如果传入的模式无效,终止程序并报告错误
panic("invalid mode")
}
}
// WebServerTeardown 在收到终止信号时优雅地关闭Web服务器。
func WebServerTeardown() {
// 创建一个通道用于接收操作系统信号。
sigCh := make(chan os.Signal, 1)
// 当接收到中断(SIGINT)或终止(SIGTERM)信号时,通知该通道。
signal.Notify(sigCh, syscall.SIGINT, syscall.SIGTERM)
// 阻塞等待接收信号。
<-sigCh
// 当收到终止信号时关闭索引器,确保干净地关闭。
handler.Indexer.Close()
// 以状态码0退出程序,表示成功终止。
os.Exit(0)
}
// WebServerMain 启动 Web 服务器的主函数
func WebServerMain(mode int) {
// 异步执行服务器关闭处理
go WebServerTeardown()
// 初始化 Web 服务器
WebServerInit(mode)
}
package handler
import (
"context"
"github.com/gin-gonic/gin"
"github.com/jmh000527/criker-search/demo"
"github.com/jmh000527/criker-search/demo/video_search"
"github.com/jmh000527/criker-search/demo/video_search/common"
indexer "github.com/jmh000527/criker-search/index_service"
"github.com/jmh000527/criker-search/utils"
"net/http"
"strings"
)
var Indexer indexer.Indexer
// cleanKeywords 接收一个字符串切片,并返回一个清理后的字符串切片。
// 清理过程包括去除每个字符串的前后空白字符,将其转换为小写,并排除空字符串。
func cleanKeywords(words []string) []string {
// 创建一个新的字符串切片,用于存储清理后的关键词。初始容量设置为输入切片的长度。
keywords := make([]string, 0, len(words))
for _, w := range words {
// 去除字符串前后的空白字符,并将其转换为小写。
word := strings.TrimSpace(strings.ToLower(w))
// 如果字符串长度大于0(非空字符串),则将其添加到关键词切片中。
if len(word) > 0 {
keywords = append(keywords, word)
}
}
return keywords
}
Search 搜索接口
//func Search(ctx *gin.Context) {
// var request demo.SearchRequest
// if err := ctx.ShouldBindJSON(&request); err != nil {
// log.Printf("bind request parameter failed: %s", err)
// ctx.String(http.StatusBadRequest, "invalid json")
// return
// }
//
// keywords := cleanKeywords(request.Keywords)
// if len(keywords) == 0 && len(request.Author) == 0 {
// ctx.String(http.StatusBadRequest, "invalid keywords, keywords and author can not be empty both")
// return
// }
// // 构建搜索条件
// query := new(types.TermQuery)
// // 满足关键词
// if len(keywords) > 0 {
// for _, word := range keywords {
// query = query.And(types.NewTermQuery("content", word))
// }
// }
// // 满足作者
// if len(request.Author) > 0 {
// query = query.And(types.NewTermQuery("author", strings.ToLower(request.Author)))
// }
// // 满足类别
// orFlags := []uint64{demo.GetClassBits(request.Classes)}
// // 执行搜索
// docs := LocalIndexer.Search(query, 0, 0, orFlags)
// videos := make([]demo.BiliVideo, 0, len(docs))
// for _, doc := range docs {
// var video demo.BiliVideo
// if err := proto.Unmarshal(doc.Bytes, &video); err == nil {
// // 满足播放量的区间范围
// if video.View >= int32(request.ViewFrom) && (request.ViewTo <= 0 || video.View <= int32(request.ViewTo)) {
// videos = append(videos, video)
// }
// }
// }
// utils.Log.Printf("returning %d videos", len(videos))
// // 把搜索结果以json形式返回给前端
// ctx.JSON(http.StatusOK, videos)
//}
// SearchAll 处理全站视频搜索的请求。
//
// 参数:
// - ctx: gin.Context 对象,包含请求上下文和相关信息。
//
// 返回值:
// - 无: 直接在 HTTP 响应中返回结果。
func SearchAll(ctx *gin.Context) {
var request demo.SearchRequest
// 绑定请求参数
err := ctx.ShouldBindJSON(&request)
if err != nil {
utils.Log.Printf("绑定请求参数失败: %s", err)
ctx.String(http.StatusBadRequest, "无效的请求参数")
return
}
// 清理和验证关键词
request.Keywords = cleanKeywords(request.Keywords)
if len(request.Keywords) == 0 && len(request.Author) == 0 {
ctx.String(http.StatusBadRequest, "关键词和作者不能同时为空")
return
}
// 构建搜索上下文
searchCtx := &common.VideoSearchContext{
Ctx: context.Background(),
Request: &request,
Indexer: Indexer,
}
// 执行搜索
searcher := video_search.NewAllVideoSearcher()
videos := searcher.Search(searchCtx)
// 以 JSON 格式返回搜索结果
utils.Log.Printf("返回 %d 个文档", len(videos))
ctx.JSON(http.StatusOK, videos)
}
// SearchByAuthor 处理用户根据作者搜索自己的视频的请求。
//
// 参数:
// - ctx: gin.Context 对象,包含请求上下文和相关信息。
//
// 返回值:
// - 无: 直接在 HTTP 响应中返回结果。
func SearchByAuthor(ctx *gin.Context) {
var request demo.SearchRequest
// 绑定请求参数
err := ctx.ShouldBindJSON(&request)
if err != nil {
utils.Log.Printf("绑定请求参数失败: %s", err)
ctx.String(http.StatusBadRequest, "无效的请求参数")
return
}
// 清理和验证关键词
request.Keywords = cleanKeywords(request.Keywords)
if len(request.Keywords) == 0 {
ctx.String(http.StatusBadRequest, "关键词不能为空")
return
}
// 从 gin.Context 中获取用户名
userName, ok := ctx.Value("user_name").(string)
if !ok || len(userName) == 0 {
ctx.String(http.StatusBadRequest, "无法获取用户名")
return
}
// 构建搜索上下文
searchCtx := &common.VideoSearchContext{
Ctx: context.WithValue(context.Background(), common.UN("user_name"), userName), // 将 userName 放到 context 中
Request: &request,
Indexer: Indexer,
}
// 执行搜索
searcher := video_search.NewUpVideoSearcher()
videos := searcher.Search(searchCtx)
// 以 JSON 格式返回搜索结果
utils.Log.Printf("返回 %d 个文档", len(videos))
ctx.JSON(http.StatusOK, videos)
}
- 在web开发中实现个性化页面展示的需求,根据登录用户身份展示不同结果。
- 调用搜索接口,除了传常规的搜索关键词搜索条件之外,实际上也会向后端传递当前登录者的用户id,所以用户的身份信息就会成为一个非常通用的参数,可以放到http header里面,因为不管是get或者post,header都会被传递给后端。
// 使用全局中间件
engine.Use(handler.GetUserInfo)
// 全局中间件
// GetUserInfo 从请求头中获取用户信息并将其存储在 gin.Context 中。
func GetUserInfo(ctx *gin.Context) {
// 从请求头中获取UserName,并对其进行URL解码。
userName, err := url.QueryUnescape(ctx.Request.Header.Get("UserName"))
if err == nil {
// 如果解码成功,将UserName存储在 gin.Context 中,键名为"user_name"。
ctx.Set("user_name", userName)
}
}
- 这里更常见的用法是,后端的一些接口需要特殊的身份认证才可以调用,而不是每个人都可以随便调用,如何加一个简单的身份认证呢?
- 服务端可以约定好一个随机的字符串,允许谁调用,就把这个字符串当作密码一样给谁,在调用的时候就把这个字符串放到request中的http header里,服务端检查header里有没有这个key以及value是不是这个字符串,是则放行,不是直接拦截返回。
- 中间件可以拿到一些信息,把这些信息放到context里面去供后面的handler使用。
- 另一种情况是在中间件里面就把整个hadler链条阻断拦截了这次请求。
// 从 gin.Context 中获取用户名
userName, ok := ctx.Value("user_name").(string)
if !ok || len(userName) == 0 {
ctx.String(http.StatusBadRequest, "无法获取用户名")
return
}
package main
import (
"github.com/jmh000527/criker-search/demo"
"github.com/jmh000527/criker-search/index_service"
"github.com/jmh000527/criker-search/utils"
"google.golang.org/grpc"
"net"
"os"
"os/signal"
"strconv"
"syscall"
)
var service *index_service.IndexServiceWorker // IndexWorker 是一个 gRPC 服务器
// GrpcIndexerInit 初始化 gRPC 索引服务。
//
// 功能描述:
// - 监听指定的本地端口,启动 gRPC 服务器。
// - 初始化索引服务,如果需要重建索引则从 CSV 文件重建索引,否则从正排索引文件加载索引。
// - 注册 gRPC 服务实现并启动服务。
// - 向服务注册中心注册服务并周期性续期。
func GrpcIndexerInit() {
// 监听本地端口
listener, err := net.Listen("tcp", "127.0.0.1:"+strconv.Itoa(*port))
if err != nil {
utils.Log.Printf("监听端口失败: %v", err)
panic(err)
}
server := grpc.NewServer()
service = new(index_service.IndexServiceWorker)
// 初始化索引
err = service.Init(50000, dbType, *dbPath+"_part"+strconv.Itoa(*workerIndex))
if err != nil {
utils.Log.Printf("初始化索引失败: %v", err)
panic(err)
}
// 是否重建索引
if *rebuildIndex {
utils.Log.Printf("总工作节点数=%d, 当前工作节点索引=%d", *totalWorkers, *workerIndex)
// 重建索引
demo.BuildIndexFromFile(csvFile, service.Indexer, *totalWorkers, *workerIndex)
} else {
// 从正排索引文件加载
service.Indexer.LoadFromIndexFile()
}
// 注册服务实现
index_service.RegisterIndexServiceServer(server, service)
// 启动服务
utils.Log.Printf("在端口 %d 启动 gRPC 服务器", *port)
// 向注册中心注册服务并周期性续期
err = service.RegisterService(etcdServers, *port)
if err != nil {
utils.Log.Printf("注册服务失败: %v", err)
panic(err)
}
// 启动服务
err = server.Serve(listener)
if err != nil {
service.Close()
utils.Log.Printf("启动 gRPC 服务器失败,端口 %d,错误: %s", *port, err)
}
}
// GrpcIndexerTeardown 处理服务终止信号
func GrpcIndexerTeardown() {
sigCh := make(chan os.Signal, 1)
signal.Notify(sigCh, syscall.SIGINT, syscall.SIGTERM)
<-sigCh
service.Close() // 接收到终止信号时关闭索引
os.Exit(0) // 退出程序
}
// GrpcIndexerMain 启动 gRPC 服务并处理终止信号
func GrpcIndexerMain() {
go GrpcIndexerTeardown() // 启动协程处理终止信号
GrpcIndexerInit() // 初始化并启动 gRPC 服务
}
- 分布式索引的部署通过命令行参数进行,mode设置为2表示启动gRPC server。
- 需要先启动若干台的加gRPC servers(index workers),再启动web server。
- mode=2时,会进入GrpcIndexerMain()函数,启动加gRPC server并加载索引数据。
- gRPC server从CSV文件中加载索引数据,单机模式下需要读取全部数据,分布式模式下只加载部分数据。
- 通过total workers和current worker id两个参数告诉gRPC server总共有几台worker,当前worker是第几台。
- 根据视频ID经过farmHash处理后的值和total workers取模结果决定是否加载当前数据。
- 服务启动后永久运行,除非收到关闭信号。
- 关闭服务时会接收kill信号,并进行善后处理,如关闭数据库连接。
- mode=3时,web server命令非常简单,只初始化哨兵。
- web server在不同端口号上启动,与gRPC server使用不同端口。
- 搜索时会从每个gRPC server获取部分结果,合并后返回给前端。
- 当index worker关闭时,web server会监听到etcd事件,并重新同步。
- 当只剩一台gRPC server时,搜索结果减少。
- 再次启动gRPC server后,web server无需重启,直接从正排文件中加载索引。
- 全站视频搜索:用户可以指定作者进行搜索,搜索范围是全站视频。
- 后台搜索:默认搜索作者自己的视频,搜索范围是作者发布的视频。
- 区别:后台搜索不需要用户指定作者,因为默认就是作者本人。
- 搜索系统一般分为三大步:召回、过滤、排序。
- 召回:根据关键词从倒排链上召回候选集。
- 过滤:按照更精细化的条件进行过滤。
- 排序:对过滤后的结果进行排序。
- 代码复用:通过抽象出接口和抽象类,实现代码复用。
- videoSearcher类包含召回和过滤方法。
- 召回方法:实现recall接口,并行执行多个召回规则。
- 过滤方法:实现apply接口,串行执行多个过滤规则。
- Builder模式:支持不定参数传递,方便扩展。
- 并行召回:使用多个协程并行执行召回规则。
- 合并结果:将各个协程的召回结果合并。
- 使用channel处理并发写入:通过channel承接并发环境下的召回结果。
- 去重处理:使用map实现按视频ID过滤重复结果。
- 串行过滤:每个过滤规则串行执行。
- 应用过滤规则:从context中获取videos,判断是否符合过滤条件。
- 写回结果:将过滤后的结果写回到context中。
- 搜索函数核心三行代码:召回、过滤、获取结果。
- 记录耗时和召回结果数量:记录每一步的耗时和召回结果数量。
- 模板方法:通过接口和抽象类固定搜索流程,实现代码复用。
- 全站视频搜索器:使用keyword recall和view filter。
- 后台搜索器:使用keyword recall和view filter,但召回规则不同。
- keyword recall:根据关键词召回视频,可以并行执行多个规则。
- view filter:根据播放量过滤视频,串行执行过滤规则。
- 路由选择:根据请求路径选择全站搜索或后台搜索。
- 搜索器实例化:根据选择创建相应的searcher实例。
package video_search
import (
"github.com/jmh000527/criker-search/demo"
"github.com/jmh000527/criker-search/demo/video_search/common"
"github.com/jmh000527/criker-search/demo/video_search/filter"
"github.com/jmh000527/criker-search/demo/video_search/recaller"
"github.com/jmh000527/criker-search/utils"
"golang.org/x/exp/maps"
"reflect"
"sync"
"time"
)
// VideoSearcher 是视频搜索器的模板方法,负责组织召回器和过滤器。
type VideoSearcher struct {
Recallers []recaller.Recaller // 视频搜索结果召回器列表
Filters []filter.Filter // 视频搜索结果过滤器列表
}
// WithRecallers 向视频搜索器添加一个或多个视频搜索结果召回器。
func (vs *VideoSearcher) WithRecallers(recallers ...recaller.Recaller) {
vs.Recallers = append(vs.Recallers, recallers...)
}
// WithFilters 向视频搜索器添加一个或多个视频搜索结果过滤器。
func (vs *VideoSearcher) WithFilters(filters ...filter.Filter) {
vs.Filters = append(vs.Filters, filters...)
}
// Recall 执行视频搜索结果召回,调用各个召回器的 Recall 方法,并将结果合并到搜索上下文中。
func (vs *VideoSearcher) Recall(searchContext *common.VideoSearchContext) {
// 如果没有召回器,则直接返回
if len(vs.Recallers) == 0 {
return
}
// 用于收集召回的视频结果
collection := make(chan *demo.BiliVideo, 1000)
// 用于等待所有召回器完成
wg := sync.WaitGroup{}
wg.Add(len(vs.Recallers))
// 并发执行每个召回器的召回任务
for _, r := range vs.Recallers {
go func(recaller recaller.Recaller) {
defer wg.Done()
// 获取召回器的名称
rule := reflect.TypeOf(recaller).Elem().Name()
// 调用召回器的 Recall 方法,获取召回结果
result := recaller.Recall(searchContext)
utils.Log.Printf("召回 %d 个文档,使用规则 %s", len(result), rule)
// 将召回的视频结果发送到通道中
for _, video := range result {
collection <- video
}
}(r)
}
signalChan := make(chan struct{})
// 用于合并多路召回的视频结果
videoMap := make(map[string]*demo.BiliVideo, 1000)
// 启动一个 goroutine 用于收集召回结果,并将结果合并到搜索上下文中
go func() {
for {
video, ok := <-collection
if !ok {
break
}
videoMap[video.Id] = video
}
// 发送信号通知收集任务完成
signalChan <- struct{}{}
}()
// 等待所有召回任务完成
wg.Wait()
// 关闭结果通道
close(collection)
// 等待结果收集任务完成
<-signalChan
// 将结果 map 中的值转换为切片,更新搜索上下文中的视频列表
searchContext.Videos = maps.Values(videoMap)
}
// Filter 执行视频搜索结果过滤,调用各个过滤器的 Apply 方法,过滤搜索上下文中的视频。
//
// 参数:
// - searchContext: 包含搜索上下文信息的 VideoSearchContext 对象。该对象包含了召回的文档以及用于过滤的相关信息。
//
// 返回值:
// - 无。此方法会直接修改传入的 searchContext 对象,过滤掉不符合条件的视频。
func (vs *VideoSearcher) Filter(searchContext *common.VideoSearchContext) {
for _, f := range vs.Filters {
f.Apply(searchContext)
}
}
// Search 执行视频搜索,包含召回和过滤两个步骤。
//
// 参数:
// - searchContext: 包含搜索上下文信息的VideoSearchContext对象。
//
// 返回值:
// - []*demo.BiliVideo: 经过召回和过滤后的BiliVideo对象切片。
func (vs *VideoSearcher) Search(searchContext *common.VideoSearchContext) []*demo.BiliVideo {
t1 := time.Now()
// 执行召回操作
vs.Recall(searchContext)
t2 := time.Now()
utils.Log.Printf("召回 %d 个文档,用时 %d 毫秒", len(searchContext.Videos), t2.Sub(t1).Milliseconds())
// 执行过滤操作
vs.Filter(searchContext)
t3 := time.Now()
utils.Log.Printf("过滤后剩余 %d 个文档,用时 %d 毫秒", len(searchContext.Videos), t3.Sub(t2).Milliseconds())
return searchContext.Videos
}
package video_search
import (
"github.com/jmh000527/criker-search/demo/video_search/filter"
"github.com/jmh000527/criker-search/demo/video_search/recaller"
)
// AllVideoSearcher 是全站视频搜索器,继承自 VideoSearcher。
type AllVideoSearcher struct {
VideoSearcher
}
// NewAllVideoSearcher 创建一个新的全站视频搜索器。
func NewAllVideoSearcher() *AllVideoSearcher {
searcher := &AllVideoSearcher{}
searcher.WithRecallers(&recaller.KeywordRecaller{})
searcher.WithFilters(&filter.ViewFilter{})
return searcher
}
package video_search
import (
"github.com/jmh000527/criker-search/demo/video_search/filter"
"github.com/jmh000527/criker-search/demo/video_search/recaller"
)
// UpVideoSearcher 是 up 主视频搜索器,继承自 VideoSearcher。
type UpVideoSearcher struct {
VideoSearcher
}
// NewUpVideoSearcher 创建一个新的 up 主视频搜索器。
func NewUpVideoSearcher() *UpVideoSearcher {
searcher := &UpVideoSearcher{}
searcher.WithRecallers(&recaller.KeywordAuthorRecaller{})
searcher.WithFilters(&filter.ViewFilter{})
return searcher
}